Hi there. I’m @sanposhiho, working in the Platform Infra team in Mercari, and also I’m a SIG-Scheduling reviewer in Kubernetes community.
I joined KubeCon + CloudNative North America 2022 as a speaker and gave a talk “SIG-Scheduling Deep Dive” along with other SIG-Scheduling maintainers. This blog post is going to summarize this session.
You can see the session video and the slide on the following links!

Note that at the time of writing this article, Kubernetes v1.25 is the latest and v1.26 isn’t released. I’m going to explain some features which will be introduced in v1.26 in this article, but the specification or release schedule may get changed.
Please refer to the actual documentation or CHANGELOG when you’d like to use those features.
What’s the Kubernetes Scheduler?
Scheduler decides which Node a newly created Pod will run on. It checks several scheduling constraints, the current allocatable resource on each Node…etc and then decide the best Node for a Pod.
So, scheduler implements a lot of scheduling related features in it, such as NodeAffinity, PodAffinity, Pod Topology Spread…etc.
Scheduler is composed of a lot of plugins, and each plugin runs more than one extension point in the Scheduling Framework.
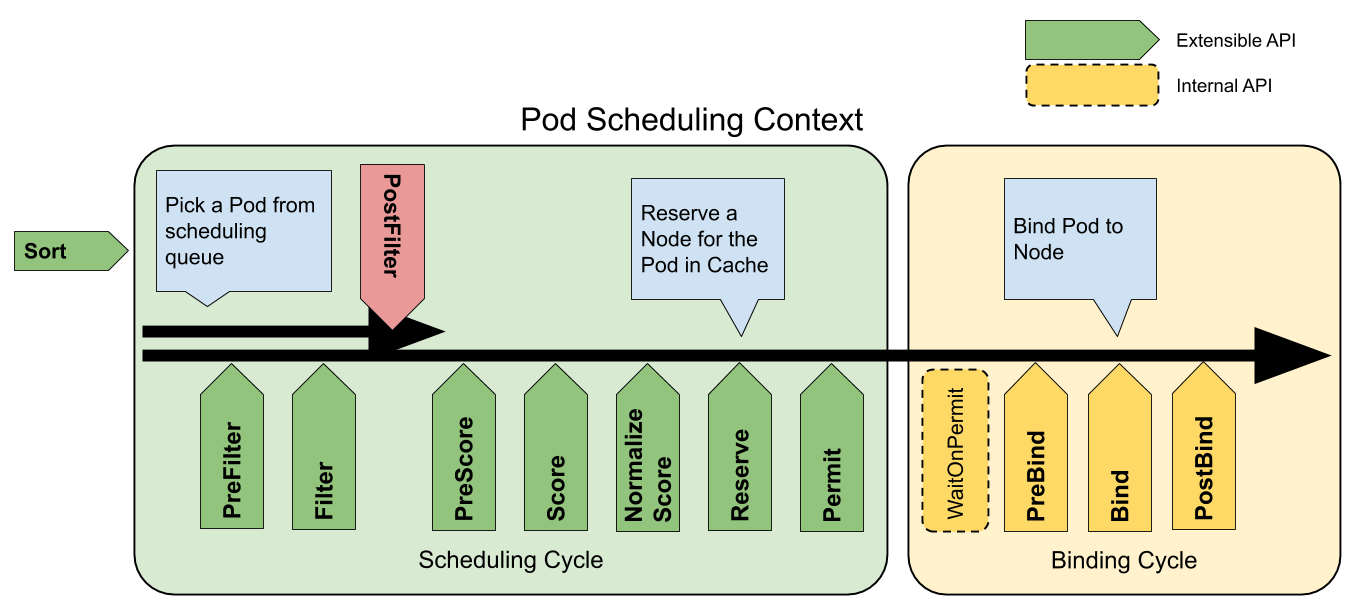
Mainly, two extension points affect the decision of Node, Filter and Score.
- Filter: filter out Nodes which cannot run a Pod. If more than one Filter plugin returns non-success status on the Node, then that Node will be filtered out.
- Score: score all remaining Nodes.
For example, requiredDuringSchedulingIgnoredDuringExecution in NodeAffinity is a hard requirement and Scheduler must follow that requirement. So, all Nodes which don’t fit it are filtered out by NodeAffinity plugin in the Filter extension point.
preferredDuringSchedulingIgnoredDuringExecution in NodeAffinity is a soft requirement, and Scheduler prefers Nodes that match it. Therefore, NodeAffinity plugin gives high scores to all Nodes that match it in the Score extension point. Note that in some cases, if other Score plugins give low scores on Nodes which NodeAffinity plugin prefers, a Pod may go to a Node that doesn’t match NodeAffinity.
Here, I just introduced a high-level overview of the scheduler. If you want to learn more about it, then I’d recommend you watch the session Tutorial: Unleash the Full Potential Of Kubernetes Scheduler: Configuration, Extension And Operation In Production.
KEP-2891: Simplified Scheduler Config
KEP-2891: Simplified Scheduler Config
Scheduler has the component config called KubeSchedulerConfiguration.
Scheduler Configuration | Kubernetes
You can define which plugins you want to enable in your scheduler like this.
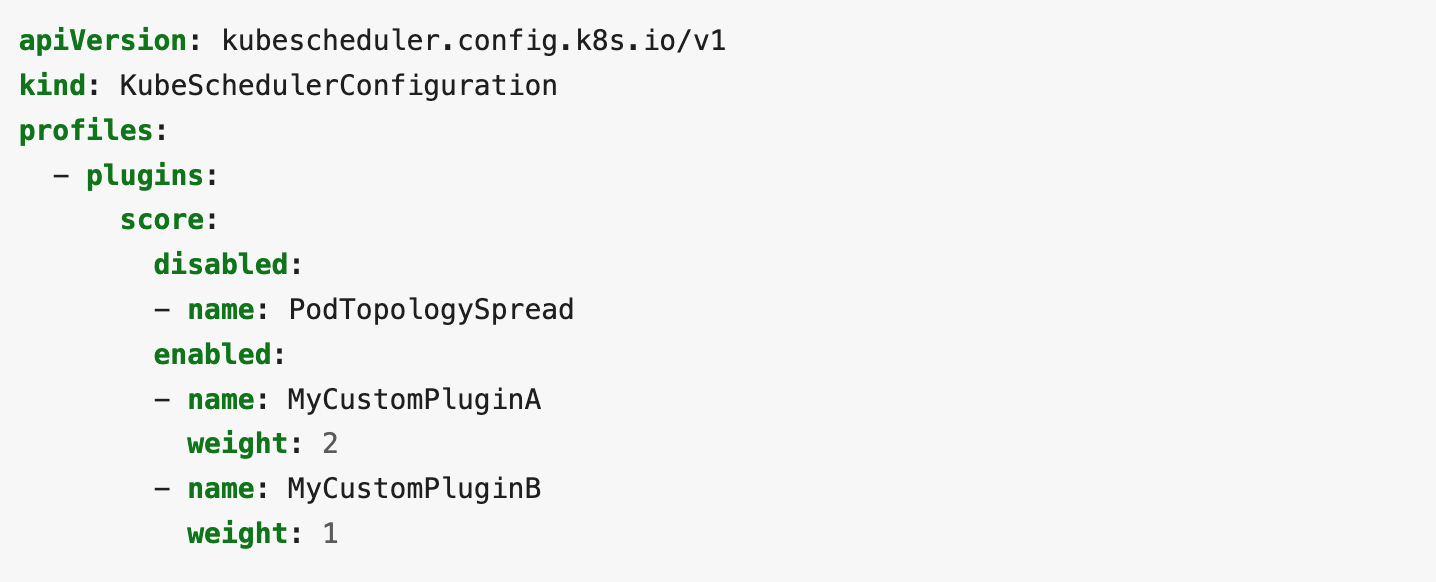
In the past, you needed to specify the plugin in all extension points that the plugin runs.
Actually, it’s kind of troublesome because the plugin may change the behavior and the extension points it runs on. You need to care about where the plugins run when they introduce a new plugin or update already-using plugins in your scheduler.
To deal with this problem, we introduced a new field called multiPoint in Kubernetes v1.23.

When you specify a plugin in multiPoint, then that plugin gets enabled in all extension points that it can run on.
WIP: KEP-3521: Pod Scheduling Readiness
KEP-3521: Pod Scheduling Readiness
This KEP includes two notable changes.
- Add
.spec.schedulingGatesfield on Pod. - Add a new extension point called PreEnqueue to Scheduling Framework.
This feature will be introduced in v1.26 as an alpha feature.
Add .spec.schedulingGates field on Pod
The current Scheduler puts all newly created Pod into the scheduling queue and starts to schedule a newly created Pod soon. However, some other controllers may know a Pod isn’t ready to get scheduled, for example, when a Pod is managed under some custom resource.
Having Pods that never get scheduled results in wasted time for the scheduler to run the scheduling loop for that Pod, and then affect badly on the overall scheduling throughput.
.spec.schedulingGates represents if a Pod is ready for scheduling. If it’s empty, then the scheduler regards a Pod as scheduling ready and starts to schedule it.
Add a new extension point called PreEnqueue to Scheduling Framework.
PreEnqueue is a new extension point which is called prior to adding Pods to activeQ.
The .spec.schedulingGates feature is implemented as a PreEnqueue plugin and, of course, any other plugins can implement PreEnqueue extension point if they’d like.
KEP-3022: min domains in Pod Topology Spread
KEP-3022: min domains in Pod Topology Spread
It adds a new field minDomains to TopologySpreadConstraints. It literally means the minimum number of domains. It was introduced in v1.24 as an alpha feature, and then graduated as a beta feature in v1.25.
Before introducing minDomains, Pod Topology Spread only had the way to control the degree to which Pods may be unevenly distributed. (maxSkew field)
minDomains is useful for cases like when you want to force spreading Pods over a minimum number of domains and, if there aren’t enough domains already present, make the cluster-autoscaler provision them.
Note that it can be used only with DoNotSchedule.
Let’s see an example to understand it. Let’s say you have the deployment with 2 replicas, which has the following topologySpreadConstraints.
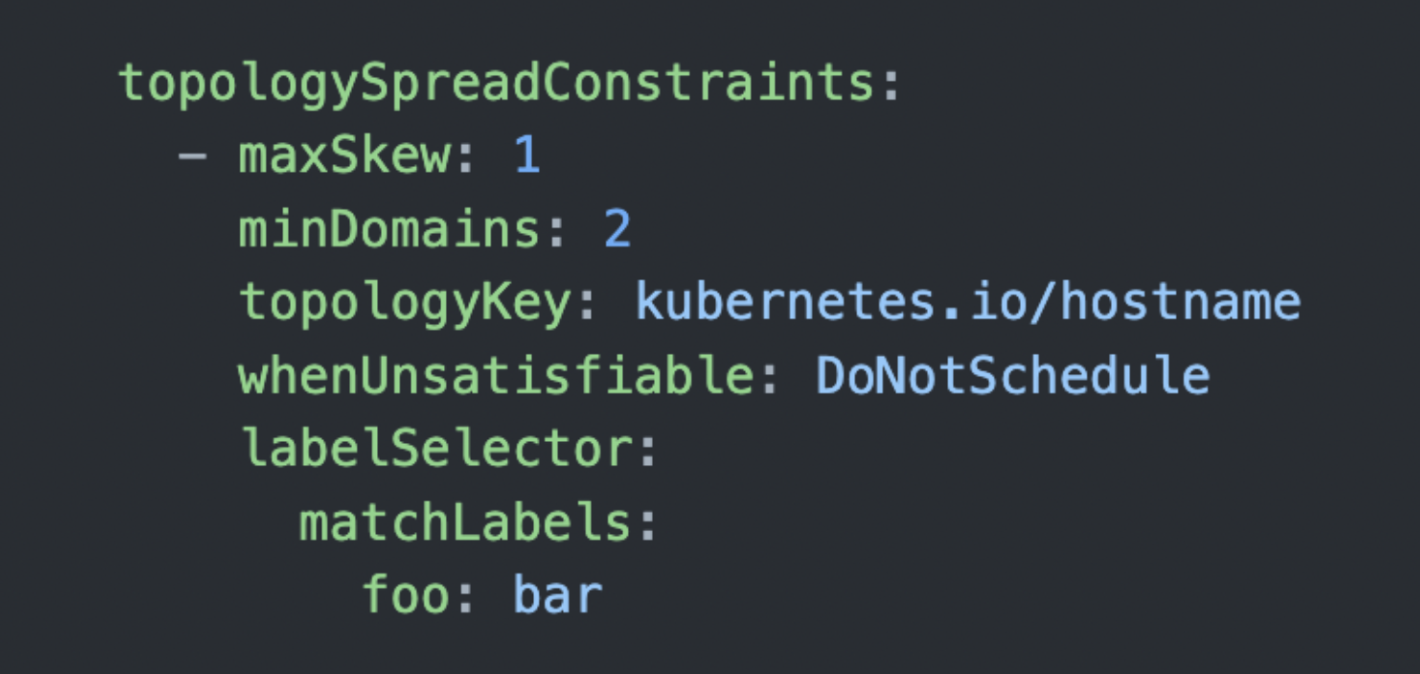
Here topologyKey is specified as kubernetes.io/hostname, so the Pod Topology Spread regards one Node as one domain.
In other words, topologySpreadConstraints says that “place Pods that match the labelSelector in two or more Nodes as evenly as possible.”
Then, what if when only one Node in the cluster? In this case, Pod cannot satisfy the minDomains constraint. Therefore, the first Pod gets successfully scheduled, but the next one gets unschedulable status.
Then, Cluster Autoscaler notices one Pod gets stacked in unschedulable status and creates a new Node to schedule it.
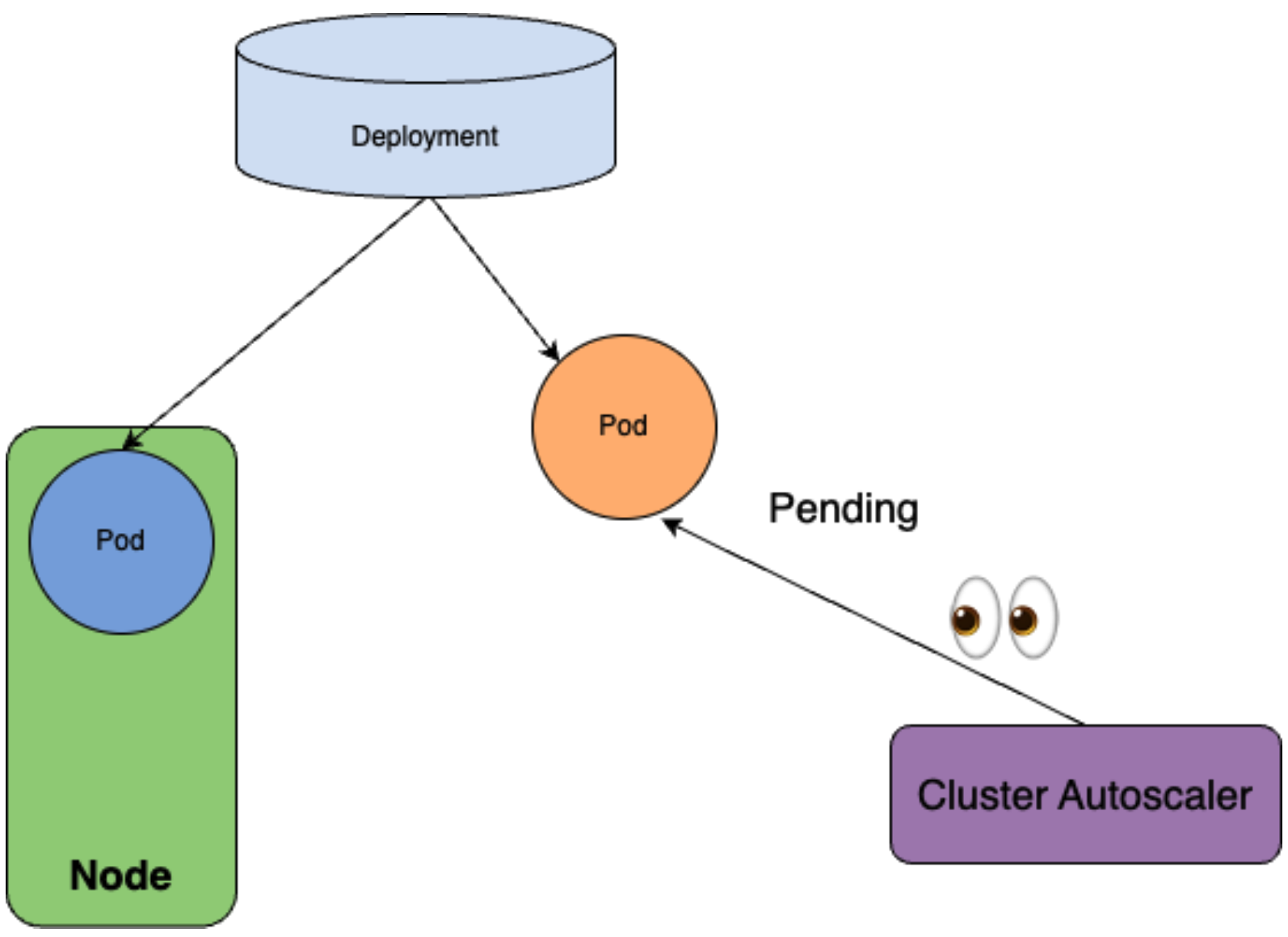
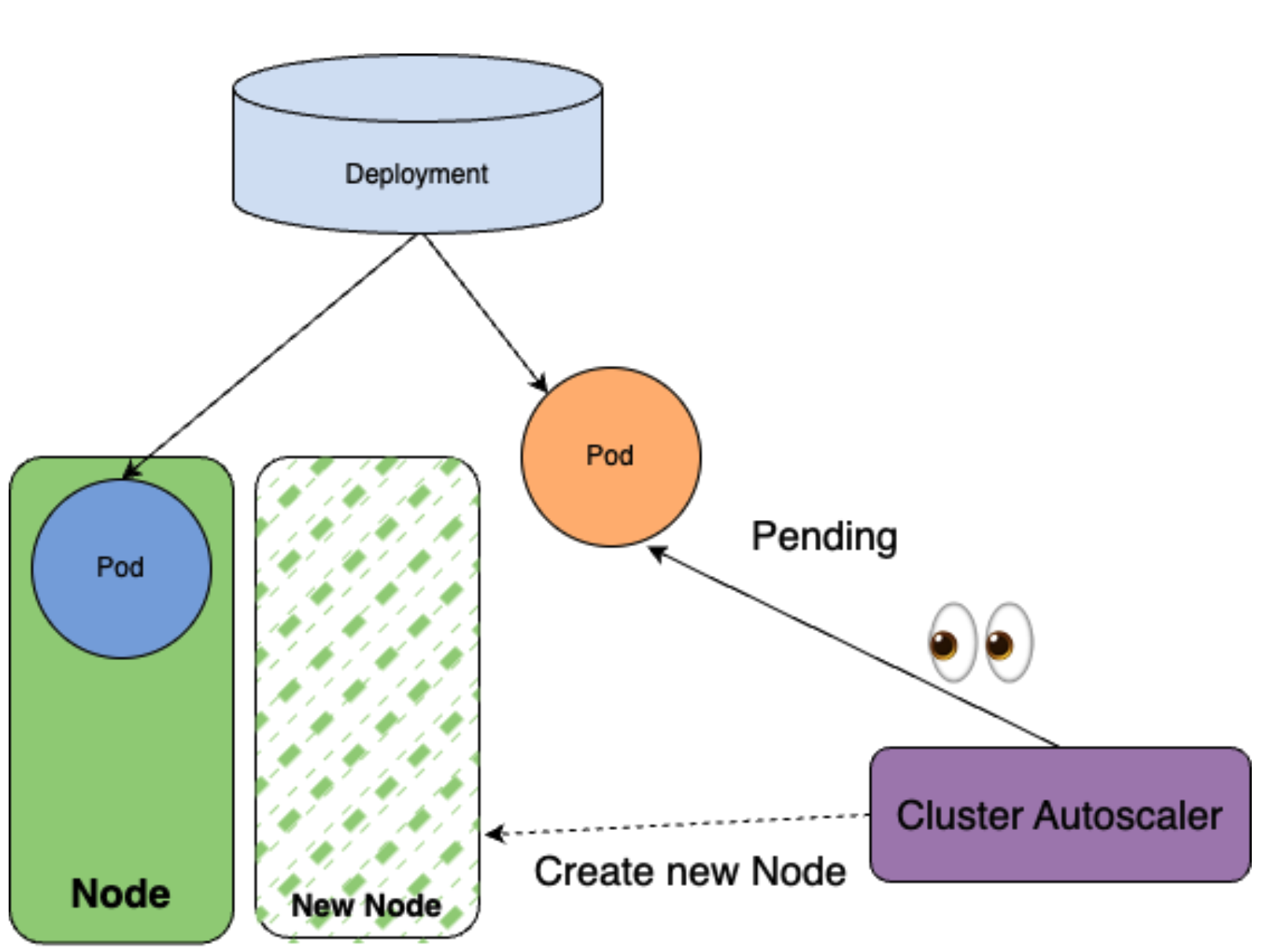
Then, the second replica gets successfully scheduled.
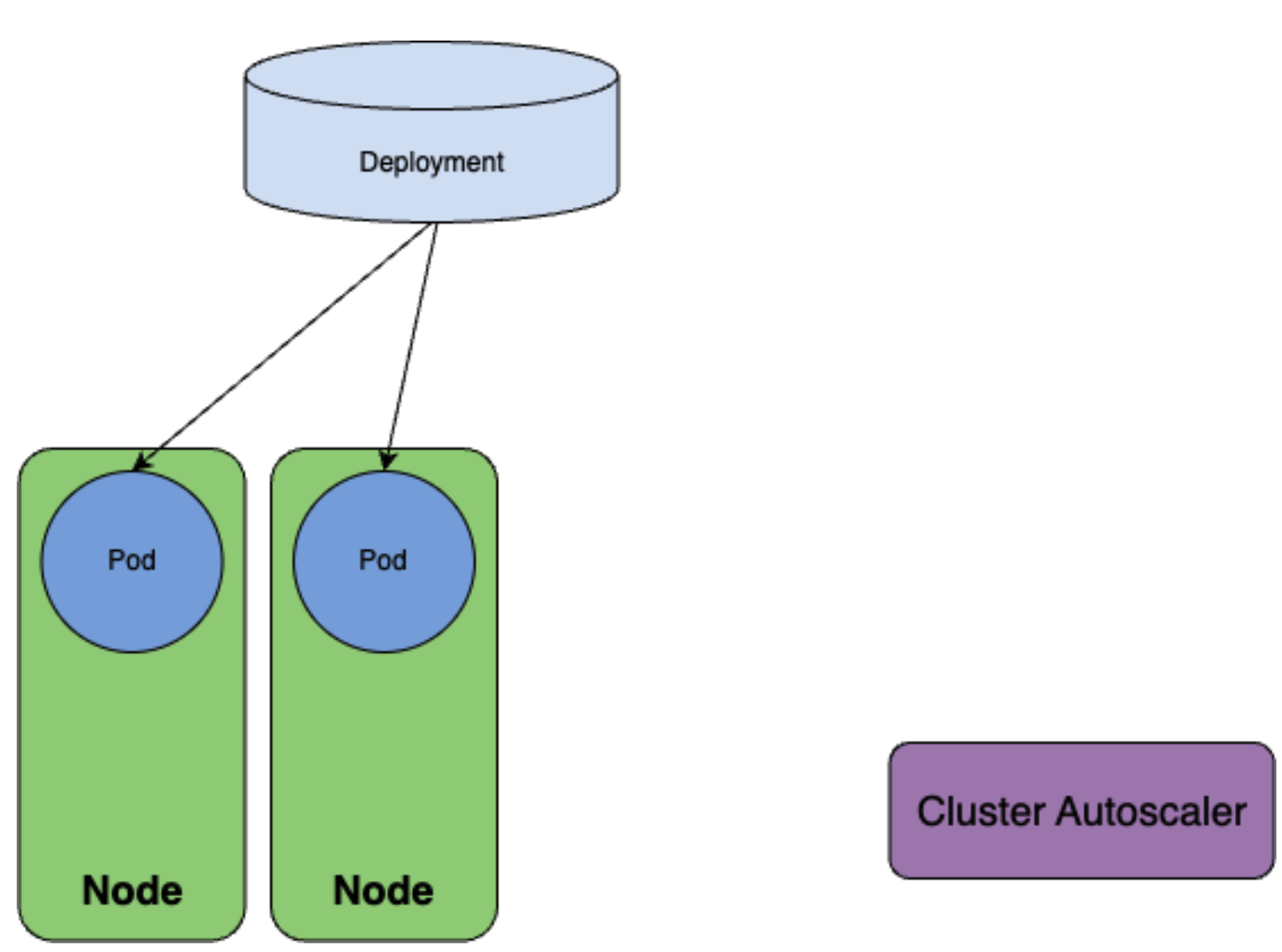
As a result, you can achieve Pods that spread over two Nodes as defined in topologySpreadConstraints.
Let’s take a deeper look at this feature from the implementation aspect of Pod Topology Spread.
Pod Topology Spread filters Nodes based on maxSkew by performing the following calculation.
('existing matching num' + 'if self-match (1 or 0)' - 'global min matching num') <= 'maxSkew'existing matching numdenotes the number of current existing matching Pods on the domain.if self-matchdenotes if the labels of Pod match with the selector of the constraint.global min matching numdenotes the minimum number of matching Pods.
Simply put, Pod Topology Spread checks if a Pod does not violate maxSkew when it is placed on this Node by this calculation.
Also, we can define which kind of Nodes will be the target of Pod Topology Spread by nodeAffinityPolicy and nodeTaintsPolicy which will be described in the next section.
Let’s say, for example, that you want to spread pods across multiple zones (zone1, zone2, and zone3) using Pod Topology Spread. However, what happens if there is no Node in zone 3 that is the target of Pod Topology Spread? In this case, Pod Topology Spread cannot notice the existence of the domain itself. In the above formula, zone3 is not taken into account when calculating the global min matching num.
In other words, Pod Topology Spread cannot notice the existence of zone 3 and tries to spread pods only in zone 1 and zone 2.
From an implementation point of view, minDomains can be described as a feature to "make Pod Topology Spread aware of domains that actually exist but are not visible for it". And, in the case of a situation that violates minDomains, Pod Topology Spread will set 0 to the global min matching num.
In the example, let’s say we set 3 to minDomains, Pod Topology Spread currently only notices zone 1 and zone 2, so the global min matching num will always be considered 0. Pods will be scheduled to zone 1 and zone 2 as long as they do not violate maxSkew, but since the global min matching num is 0, Pod Topology Spread will reject all Nodes in zone 1 and zone 2 at some points. Let’s say maxSkew is 1, then once a pod is placed in zone 1 and zone 2, the other pods will become unschedulable.
Cluster Autoscaler internally simulates the scheduler’s scheduling and creates a new Node which unschedulable Pods can be scheduled on. So, in this example, it will add a Node in zone3 that is eligible for Pod Topology Spread.
I hope this example has helped you understand that minDomains is a strong friend when you want to spread pods across multiple domains through Pod Topology Spread and make them really resilient to failures.
In fact, since Mercari is built on a cluster on multiple zones, if we can enforce a situation where all microservices put pods in multiple zones by minDomains, it will make Mercari more resilient to zone failures.
KEP-3094: Take taints/tolerations into consideration when calculating PodTopologySpread skew
KEP-3094: Take taints/tolerations into consideration when calculating PodTopologySpread skew
It adds new fields nodeAffinityPolicy and nodeTaintPolicy. It’s now served as an alpha feature, and we plan to graduate it to beta in v1.26.
nodeAffinityPolicy and nodeTaintPolicy are the options to specify whether to take nodeAffinity and taints/tolerations into consideration when Pod Topology Spread calculates the skew.
The problem behind it was that it always didn’t take Node taints into consideration and it sometimes resulted in unexpected behavior. Let’s see an example.
Let’s say you have topologySpreadConstraints like the following, and one Node has a untolerated taints.
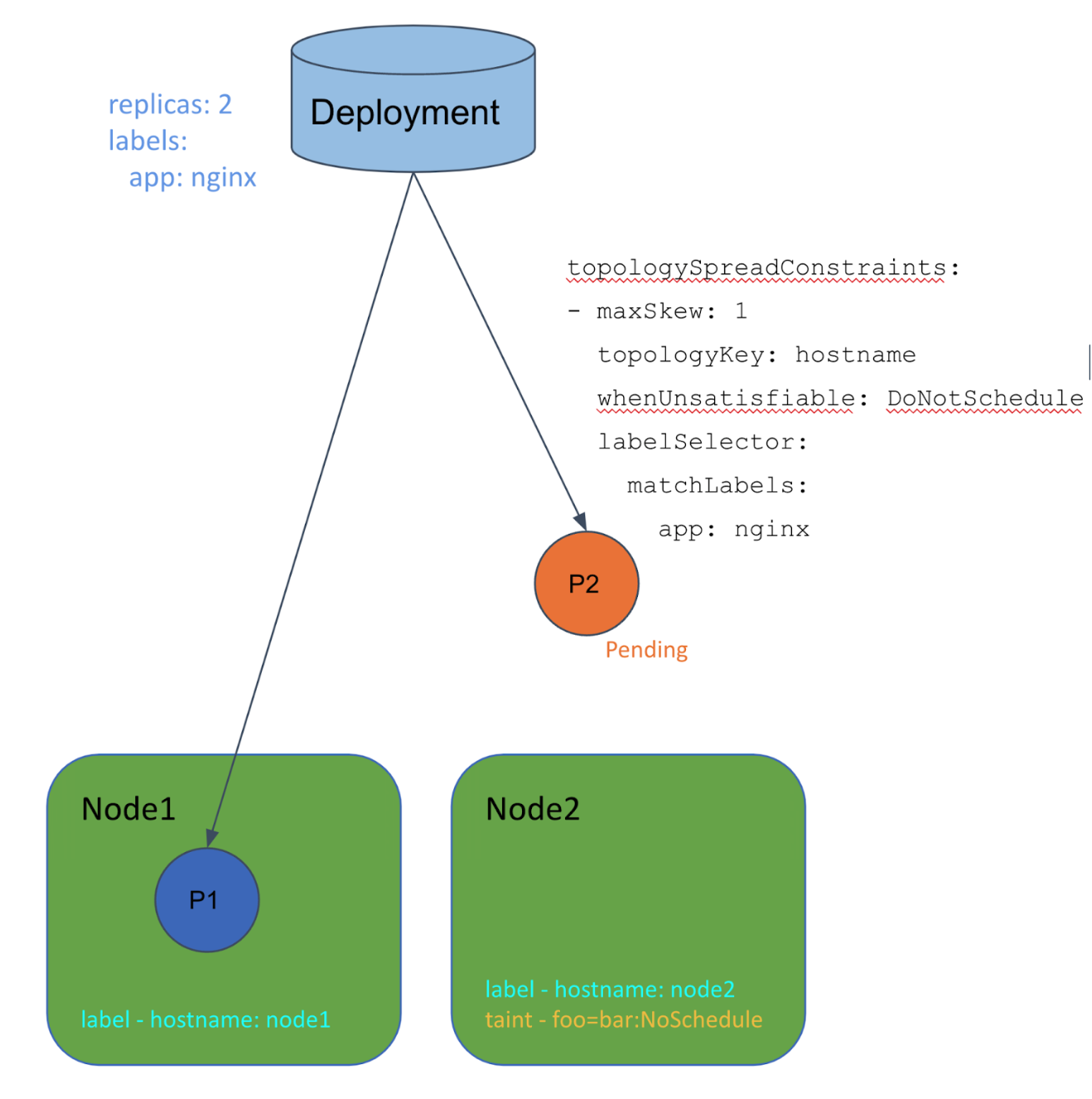
The scheduler takes both Nodes into consideration, but it doesn’t care about the taints.
In this case, the first Pod can go to Node1. However, the second one will be Pending since Node2 has the taint regardless of the Pod Topology Spread wanting to schedule it on Node2.
By setting Honor to nodeTaintsPolicy, the scheduler ignores tainted Nodes and we can avoid the problem.
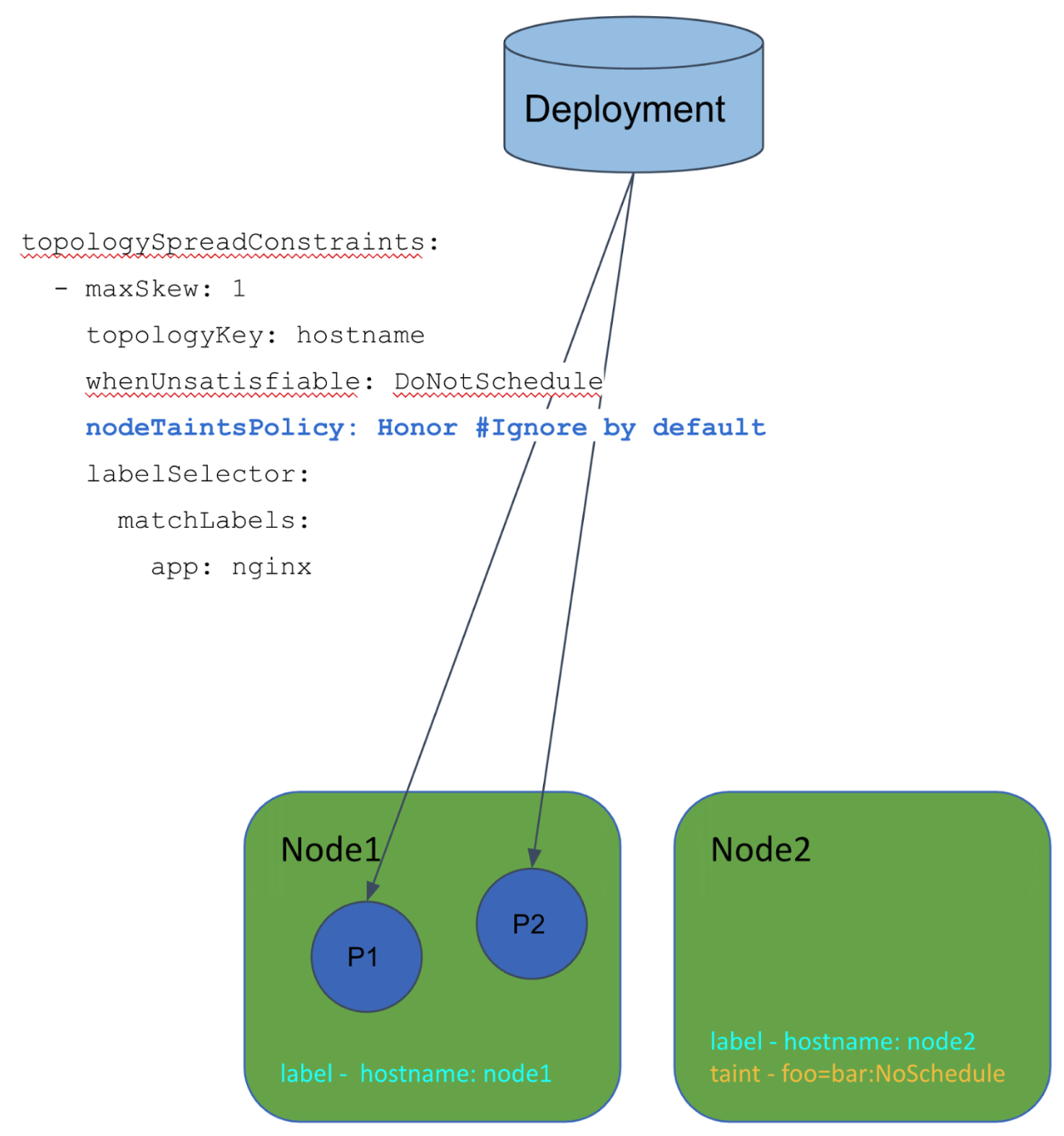
KEP-3243: Respect PodTopologySpread after rolling upgrades
KEP-3243: Respect PodTopologySpread after rolling upgrades
This adds a new field matchLabelKeys to Topology Spread. It’s now an alpha feature.
The problem behind it was that the topology spread takes old replicas into consideration during rolling upgrades. This may end up in the unbalanced topologies because all old replicas are, of course, removed after rolling upgrades.
matchLabelKeys will solve this issue. The topology spread constraint uses those keys to look up label values from the incoming pod; and those key-value labels are ANDed with labelSelector to identify the group of existing pods over which the spreading skew will be calculated.
So, by setting pod-template-hash in this matchLabelKeys, the scheduler takes only Pods with the same pod-template-hash into considerations, which means only new replicas will be considered during rolling upgrade.
Worth noting features/fixes
Above are the feature changes listed in KEP, but there are a few more interesting updates related to the Scheduler so I’ll share them from here.
Performance improvement on DaemonSet Pod’s scheduling latency
Update PreFilter interface to return a PreFilterResult #108648
This Pull Request contains two changes.
The first one; it changes PreFilter plugins to return PreFilterResult. PreFilterResult contains the set of nodes that should be considered downstream extension points. It contributes to reducing wasted calculations in the downstream plugins.
The second one; it changes NodeAffinity PreFilter to return appropriate PreFilterResult.
DaemonSet is actually using NodeAffinity to schedule each Pod on a specific Node. And, if NodeAffinity has such a hard constraint, then it can return PreFilterResult that includes only one Node.
Then, as described, all other downstream plugins evaluate only one Node and the scheduling latency for DaemonSet Pod got much improved.
Fix memory leak on kube-scheduler preemption
Fix memory leak on kube-scheduler preemption #111773
The scheduler had the long-live context which was alive during the scheduler running.
Then, mistakenly, the scheduler created a child context by context.WithCancel(ctx) from that long-live context, and it didn’t get canceled.
As you can see in the following doc, if you don’t call cancel, then a child context doesn’t get canceled and it doesn’t get GC-ed until the parent context is canceled. This means that the parent context is going to live forever until the scheduler itself stops.
Calling the CancelFunc cancels the child and its children, removes the parent’s reference to the child, and stops any associated timers. Failing to call the CancelFunc leaks the child and its children until the parent is canceled or the timer fires.
https://pkg.go.dev/context
This patch was introduced in other versions as well, and we refactored the scheduler’s internal structure to prevent such a problem from happening in the future.
fix(scheduler): split scheduleOne into two functions for schedulingCycle and bindingCycle #111775
Flush internal unschedulablePods pool every 5m (from 60s)
Set PodMaxUnschedulableQDuration as 5 min #108761
In the SchedulingQueue, we have two queues and one Pod pool; activeQ, backoffQ, and Unschedulable Pod pool.
If a Pod gets unschedulable status, then Scheduler moves a Pod to Unschedulable Pod pool.
Scheduler will move Pods in Unschedulable Pod pool to activeQ/backoffQ when something happens that may allow a Pod to become schedulable. (like new Node created, Node updated…etc)
Another way for Pods to leave the Unschedulable Pod pool is flushing; Scheduler flush the Unschedulable Pod pool every certain minute so that Pods can fairly get the opportunity to get scheduled. But, we’re not sure if it really helps some Pods, we’re wondering if event-based moving should be enough and if we could remove this flushing.
This PR changes the interval of flushing from 60s to 5m and we hope we can remove the flushing completely in the future.
Component Config in kube-scheduler is stable now
Graduate component config to stable in kube-scheduler #110534
As I said, Scheduler has a component config KubeSchedulerConfiguration and it reached v1.
The legacy scheduler policy config is removed in v1.23
remove scheduler policy config #105424
The legacy scheduler policy config is removed completely, and you should move to KubeSchedulerConfiguration if you’re still using it.
Kube-scheduler-simulator
From here, I would introduce sub projects from SIG/Scheduling.
The first one is kube-scheduler-simulator.
kubernetes-sigs/kube-scheduler-simulator
Nowadays, the scheduler is configurable/extendable in multiple ways. But checking the scheduling decision in detail is kind of hard. Checking each plugin’s decision requires increasing the log level, and it also requires strong permission on your cluster.
The simulator helps you check/evaluate the scheduler’s behavior easily, which doesn’t even require you to prepare the Kubernetes cluster and you only need to run the simulator binary. (+ simulator-web client if you’d like to use it)
It’s still a young project, and it hasn’t even reached its first release.
It has own kube-apiserver in it, and you can do anything by communicating with it like in a real cluster.
Then, when you create Pods in the simulator, the details of a scheduling result, such as scores and filtering results, will be added to Pod’s annotation like magic.
The simulator also has a web client and you can check the results easily like this. (You don’t necessarily need to use Web UI because Pod annotation has all scheduling results displayed in the Web UI.)
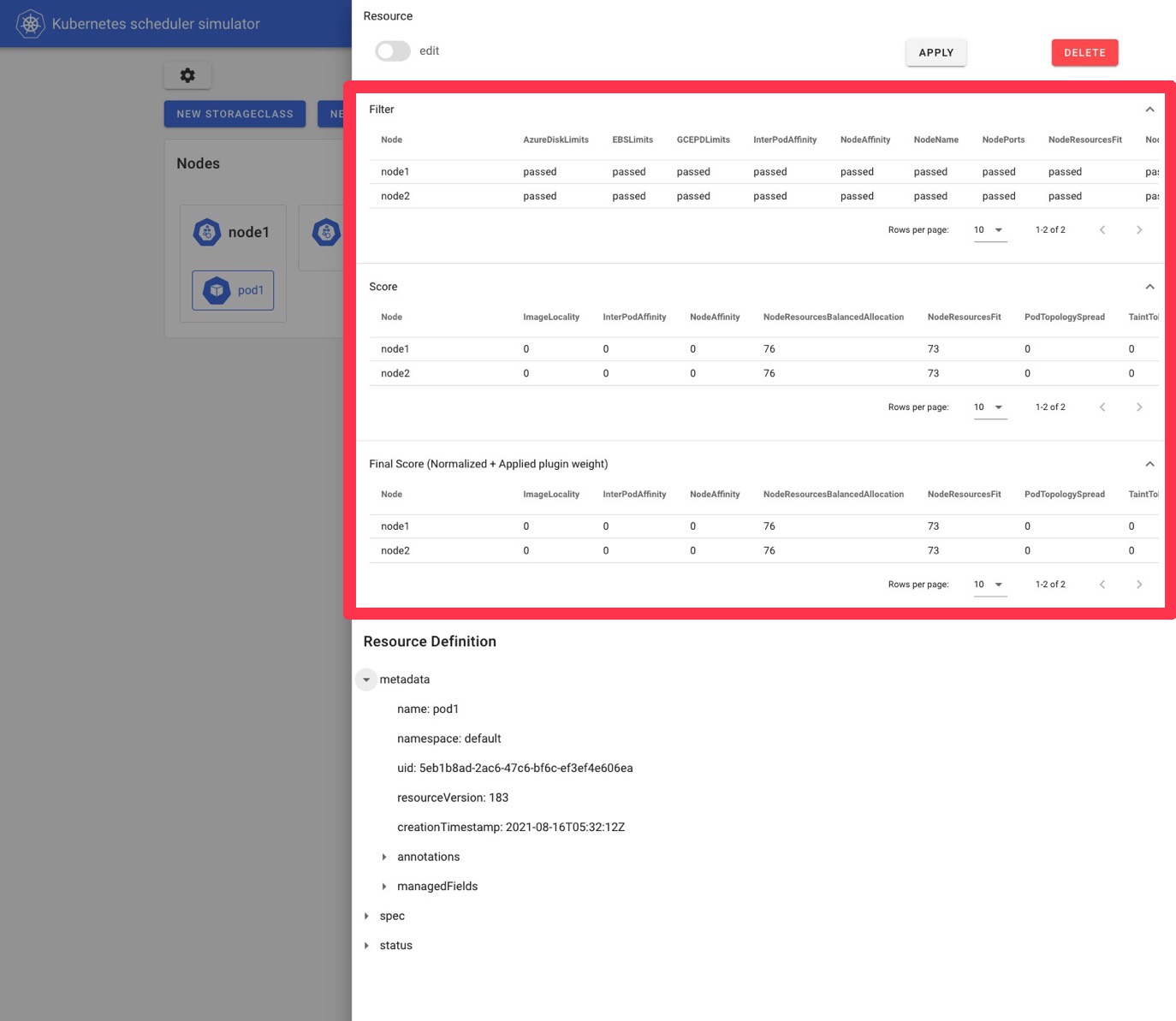
Now, we are developing to reach its first release (v0.1.0) and also, we’re discussing a new feature scenario-based simulation.
Kueue
Kueue stands for Kubernetes-native Job Queueing.
It’s also a newer project of a job queueing controller designed to manage batch jobs as a single unit.
It has these core features:
- Quota management: It controls who can use what kind of resources and the limitation of the usage.
- Fair sharing of resources between tenants: To maximize the usage of resources, any unused quota assigned to inactive tenants should be allowed to be shared fairly between active tenants.
- Flexible placement of jobs across different resource types based on availability: You can have various resources such as different architectures (GPU or CPU models) and different provisioning modes (spot vs on-demand).
- Different queueing strategies:
- StrictFIFO: Simply First In First Out.
- BestEffortFIFO: Basically FIFO, but if older workloads can’t be admitted, it will not block newer workloads that can be admitted.
You can see its concepts and APIs here.
https://github.com/kubernetes-sigs/kueue/tree/main/docs/concepts
Also, the community published a blog post to introduce Kueue, which you can also refer to know more about it.
https://kubernetes.io/blog/2022/10/04/introducing-kueue/
Descheduler
Scheduler only checks the cluster’s situation and decides the best Node for Pods at that time. But, Kubernetes cluster changes from moment to moment.
Then, here is Descheduler; it checks the latest cluster’s state, and evicts Pods running in
non-appropriate Nodes. It expects that replicaset or something creates Pods again and Scheduler schedules those Pods on the best Nodes.
You can configure which Pods are eligible for descheduling by DeschedulerPolicy.
That’s it about the overview of Descheduler. Let’s see the latest updates from here.
Descheduler Framework Proposal #753
It’s a big internal architecture change that proposed changing each policy to a plugin like Scheduling Framework and make Descheduler pluggable and easy to expand.
feat(leaderelection): impl leader election for HA Deployment #722
It’s a leader election feature for High Availability.
Limit the maximum number of pods to be evicted per Namespace #656
Descheduler has a policy maxNoOfPodsToEvictPerNode, which defines the maximum number of Pods to get evicted per Node.
This Pull Request introduced maxNoOfPodsToEvictPerNamespace which defines the same one per Namespace.
Kwok (Kubernetes WithOut Kubelet)
This is a quite new project. It can create fake Nodes and fake Pods behaving like real Nodes and Pods.
Its strength is that you don’t need to start real Nodes or Pods to check the behaviors of Scheduler, Cluster Autoscaler, or any controllers.
Scheduler-plugins
kubernetes-sigs/scheduler-plugins
Some Scheduler’s plugins like NodeAffinity, PodAffinity, etc exist by default inside the scheduler.
However you can also implement your own scheduler plugins to satisfy your own use cases.
The scheduler-plugins repository contains plugins that are maintained by the community, but are not integrated into the upstream scheduler by default.
If you find a feature you want but does not exist in the scheduler, take a look in this repository and you may find something that fits your requirements, or you may find an idea that will help you solve your problem.
Wrap-up
This completes all the explanations of what was presented during the session. From here, I would like to give a light summary, including a few personal thoughts.
First, regarding the changes in the upstream Scheduler, you probably thought there are so many things introduced in Pod Topology Spread. The NodeAffinityPolicy, NodeTaintsPolicy, and MatchLabelKeys are definitely necessary to correct the unpleasant behaviors of Pod Topology Spread. You must consider using them when using Pod Topology Spread in your workloads.
Among other changes, I personally see great potential in the PreEnqueue plugin extension point introduced with SchedulingGates. Until now, it has not been possible for plugins to control the behavior of Scheduling Queues in detail, so I expect the PreEnqueue plugin extension points makes it possible to improve scheduler performance by adding some plugins specific logic.
Among the Sub Projects, Kueue is probably the most interesting one for me at the moment.
There have been several projects to use Kubernetes in clusters for batch jobs, such as machine learning, and it is interesting to see how Scheduler can be extended to schedule batch jobs efficiently.
To try to support such batch workloads as a Kubernetes community, [wg-batch](https://github.com/kubernetes/community/blob/62b16d1aafdd744708c2f5243f 90e858806bff95/wg-batch/README.md) was born and Kueue is being developed by them.
Currently, v0.2.X is the latest at the time of writing, and although it is still a young project, I look forward to future developments, how the project goes, and the future brought by them!
Kubernetes contributor award
It’s honored to receive the Kubernetes contributor award from the community. It’s a pleasure to work with the SIG-Scheduling members and I greatly appreciate all help from everyone 🙂
https://www.kubernetes.dev/community/awards/2022/#scheduling
Wow, I got Kubernetes contributor award this year!
I'm beyond honored to receive it! Thanks #KubeCon pic.twitter.com/L8ikZU58SQ— さんぽし/sanposhiho (@sanpo_shiho) October 25, 2022




