This article is part of the Developer Productivity Engineering Camp blog series, brought to you by Yohei Kanemaru from the Network team.
At Mercari, we’ve been using a multi-tenant Kubernetes cluster that runs 300+ microservices for various products such as Mercari JP, Merpay, NFT, and so on. In this kind of situation, it’s essential to have a clear network separation between tenants to enhance network security while effectively managing network policies applied to each tenant. We leverage Hierarchical Namespace Controller (HNC) to group and deliver network policies to tackle this problem. Along with it, we abstract network policies instead of directly exposing raw YAML-based manifests for better usability and verifiability.
This post outlines how we implemented these mechanisms to ensure tenant isolation in our multi-tenant Kubernetes cluster.
Challenges on using NetworkPolicy for tenant isolation on a multi-tenant Kubernetes cluster
When operating a multi-tenant Kubernetes cluster, isolating tenants from each other is essential to minimize the damage occurring when a workload on the cluster is unexpectedly compromised. Although workloads themselves have application-layer authentication and authorization mechanisms to defend themselves against network threats, it’s a good idea to isolate them on the network layer in favor of the Defense in Depth principle while flexibly controlling tenant-to-tenant communications where necessary. Configuring Network Policies in Kubernetes is a good approach for that.
In our cluster, each microservice (or "service") is considered an atomic tenant, and they each own a dedicated namespace managed by a product team. In general, each service is designated to serve a particular product operated by an internal company. For example, Merpay Inc., one of the member companies of Mercari Group, operates Merpay, the product for payment experiences, and some services running on the cluster serve it. We can group these atomic tenants into another large upper-layer virtual tenant, calling it a Virtual Company (VC).
Typically, each VC has different security policies and compliance regulations. As the platform team that manages the platform, including the cluster, we want to ensure that all services comply with a security baseline and product-specific requirements. On the other hand, it’s not realistic that the platform team reviews and configures all Network Policies applied to services.
The challenging goals
So, now we face two challenges in terms of managing Network Policies on the multi-tenant Kubernetes cluster:
- We want to efficiently maintain Network Policies applied to a group of tenants rather than spreading them to individual tenants
- We want to delegate configuring Network Policies to product teams as much as possible for better flexibility while ensuring security compliance and a good developer experience
The diagram illustrates the desired state of policy management.

Network Policies isolate all service namespaces by default; they deny communication with any other services (technically namespaces) regardless of the opposite’s affiliation. A product team can configure Network Policies to grant their service access to other services belonging to the same VC (“VC-local Policies” in the diagram). In contrast, the platform team is responsible for controlling communications crossing the boundary of the internal company (“VC-to-VC Policies in the diagram).
Note: The diagram is just for illustration purposes and doesn’t reflect actual traffic flow and points of policy enforcement.
Leveraging Hierarchical Namespace Controller for efficient policy management
As explained in the previous section, each service has its namespace, enabling us to put namespaces into a group based on their associated product or Virtual Company (VC). Hierarchical Namespace Controller (HNC) is a great solution to make it happen. Using it, we can create additional namespaces under a namespace. In other words, a parent namespace can have children; it forms a tree of namespaces that expresses relationships between namespaces. More than only constructing a group, namespaces in HNC also inherit Kubernetes objects from their ancestors. Therefore, by applying an object to a namespace, HNC propagates it to all namespaces in its subtree.
We’ve already introduced HNC to group services namespaces based on their product team to maintain RBAC configurations such as Roles and Role Bindings. We added a new namespace layer that denotes VC and set them as the ascendant of product teams’ namespaces.

Of course, company namespaces will be created automatically without product teams knowing it. As introduced in the previous post, we’ve been utilizing a Terraform module named microservice-team-kit (team-kit) that abstracts team-related resources. Since the team-kit knows which VC the product team belongs to through its metadata, the platform ensures that a company namespace, which is ascendant of the team namespace, is created by using the information fed into the kit.
HNC and Network Policies in practice
We assume that we defined namespace hierarchy as illustrated in the tree diagram above. kubectl hns tree command outputs the hierarchy with pretty text diagram below:
$ kubectl hns tree company-x company-y
company-x
├── team-a
│ ├── service-1
│ └── service-2
└── team-b
└── service-3
company-y
└── team-c
├── service-4
└── service-5Now, we want to permit access from any services under company-x to service-5 in company-y as an exceptional VC-to-VC policy. Instead of creating a NetworkPolicy object to all namespaces under company-x one by one, the platform team places it on namespace company-x.
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-from-company-x-to-service-5
namespace: company-x
spec:
egress:
- to:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: service-5
podSelector: {}
policyTypes:
- EgressBy default, HNC doesn’t propagate NetworkPolicy objects. Don’t forget to enable it by editing the HNCConfiguration object. (This is a CustomResourceDefinition installed by HNC)
apiVersion: hnc.x-k8s.io/v1alpha2
kind: HNCConfiguration
metadata:
name: config
spec:
resources:
- group: networking.k8s.io
mode: Propagate
resource: networkpoliciesImmediately after placing the NetworkPolicy object, HNC delightfully propagates the object to descendant namespaces, and the identical object will virtually appear on them.
$ kubectl get networkpolicy allow-from-company-x-to-service-5 -n service-1
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
labels:
app.kubernetes.io/managed-by: hnc.x-k8s.io
hnc.x-k8s.io/inherited-from: company-x
name: allow-from-company-x-to-service-5
namespace: service-1
spec:
egress:
- to:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: service-5
podSelector: {}
policyTypes:
- EgressWhen a new service namespace gets spawned under company-x, HNC automatically pushes the NetworkPolicy into the namespace. Furthermore, as the platform team, we don’t have to touch service namespaces directly. It ensures clear boundaries of accountability in managing resources under a service namespace governed by a product team.
Abstracting Network Policies for policy enforcement
But wait, there’s another concern here.
HNC propagates NetworkPolicy objects to descendant namespaces. If there are two or more NetworkPolicy objects, including native ones and propagated ones, on a service namespace, they will be mixed as per the usual Kubernetes behavior. Now, we face two problems in terms of policy enforcement:
- Even though NetworkPolicy, by nature, can permit traffic flows and implicitly deny the rest of them, it cannot explicitly deny traffic flows
- NetworkPolicy doesn’t have a concept of priority between policies; it just evaluates the union of policies
Let’s say the platform team created a NewtorkPolicy object on namespace company-x, aimed to permit access to service-5 and deny access to any other services, and HNC propagated it to namespace service-1. What if the product team created a NetworkPolicy object that allows any traffic flows on namespace service-1?
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-from-company-x-to-service-5
namespace: company-x
spec:
egress:
# I don’t want to permit access to anything other than service-5!
- to:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: service-5
podSelector: {}
policyTypes:
- Egresskind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-from-service-1-to-any
namespace: service-1
spec:
egress:
- {}
podSelector: {}
policyTypes:
- EgressDespite the platform team’s intention, Kubernetes will pass any traffic from service-1. In other words, the former NetworkPolicy object itself cannot dispute the other object that violates the original intent.
Let’s abstract Network Policies!
To solve the problem, we must inspect Network Policies created on service namespaces and reject ones that violate the companies’ borders. There are some solutions to enforce rules to Kubernetes manifests, such as OPA Gatekeeper backed by Rego. However, pragmatically, it’s not easy to apply it for Network Policies because of their bold ability to express a single intent in various ways.
Now, it’s time to use the power of abstraction again, as we did for creating company namespaces. As introduced in the previous post, we’ve been utilizing a Terraform module named microservice-starter-kit (starter-kit) that abstracts service-related resources. We’ve extended its interface to list namespaces that the service communicates with.
module "service-1" {
source = "microservice-service-kit/vX.Y.Z.tar.gz"
service_name = "service-1"
service_team = "team-1"
service_company = "company-x"
network = {
security = {
enable_network_policy = true
namespaces = ["service-2", "service-3"]
}
}
}The starter-kit accordingly generates corresponding Network Policies that permit access. It also ensures that these namespaces belong to the same Virtual Company (VC) as the service. If they reside in the other VC, the starter-kit won’t grant the service access to them. By making the interface simple, we, as the platform team, could quickly implement the validation logic. More than just bringing the benefit to the platform team, it reduces the chances of assembling a raw YAML manifest file as a product team. Furthermore, it allows us to precisely separate the policy’s intent (i.e., list of namespaces needed to communicate maintained on starter-kit) and implementation (i.e., Network Policies instantiated on Kubernetes) as a side benefit.
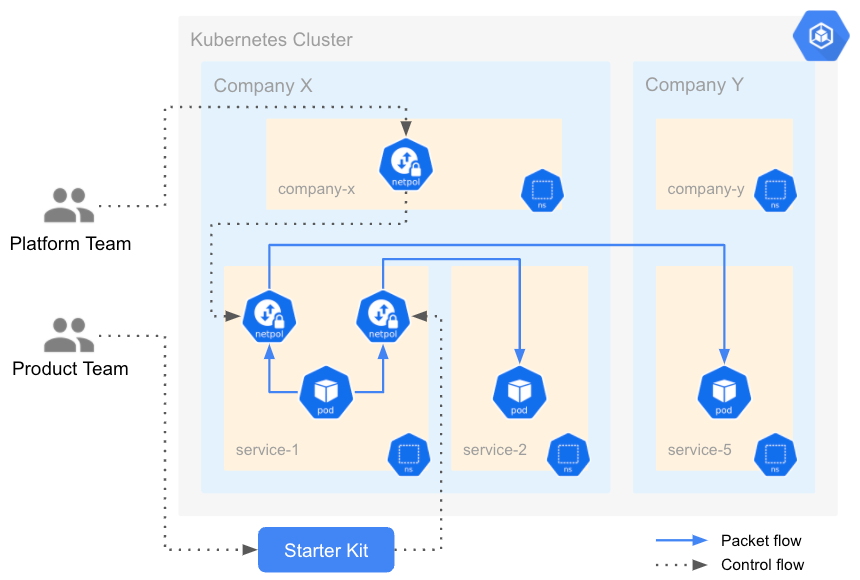
The diagram below outlines how HNC and the abstraction work together.
The gray dotted lines represent control flow, and the solid blue lines represent packet flow. The platform team creates Network Policies on the company namespace, and HNC propagates them to the service namespaces. These Network Policies will eventually be applied to packets going to the other company’s namespace. On the other hand, the product team generates Network Policies through starter-kit; which will be applied to packets going to the same company’s namespace at the end.
Wrap up
This article introduced how we leverage Hierarchical Namespace Controller (HNC) and abstract Network Policies to ensure network isolation on the multi-tenant Kubernetes cluster.
Although we’ve overcome the original challenges, we are still in the middle of tackling other obstacles. Especially, observability of network policies is what we are willing to resolve. It’s not easy to safely promote a new security mechanism without in-depth network visibility in an online production environment where many workloads are deployed (i.e., brownfield). We use Google Kubernetes Engine (GKE) to provision our Kubernetes cluster, and it offers Dataplane V2, which brings some attractive mechanisms for network observability backed by Cilium. However, we haven’t enabled it with our cluster due to some blockers.
Nevertheless, we will continue to harden our platform from various aspects while delivering a good developer experience. The Network team drives many other exciting projects, and you can find them in the recent blog post. If you are interested in our initiatives, please consider applying for these positions: