Implement the dynamic rendering service
Here is awesome article written by the Google search team: https://developers.google.com/search/docs/advanced/javascript/dynamic-rendering
To put it simply:
Dynamic rendering means switching between client-side rendered and pre-rendered content for specific user agents.
As the article suggests, we use Rendertron to implement our dynamic rendering service called Prerender.
In this article, I am going to introduce how we implement the dynamic rendering service and the problems we encountered.
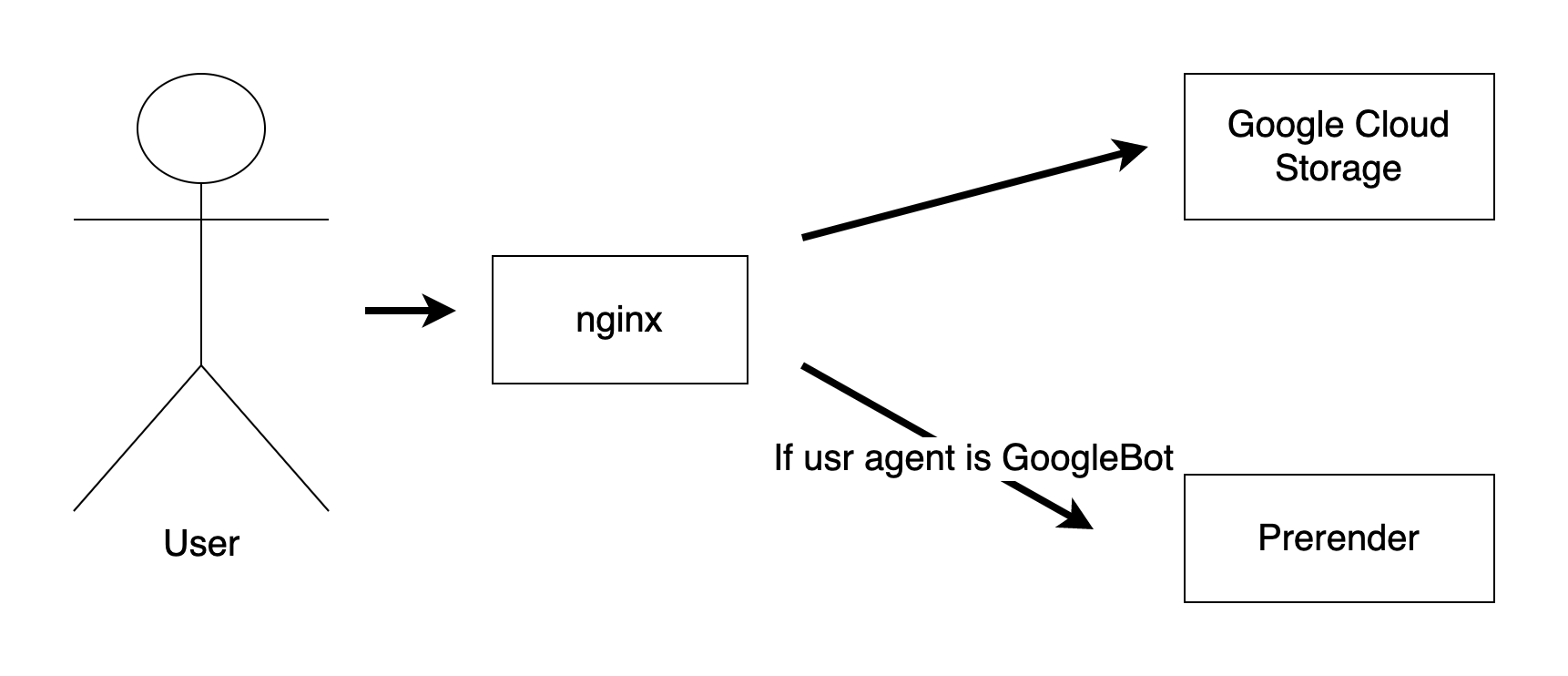
Conditionally switch upstream by user agent

We use nginx as the reverse proxy to two upstreams
Google Cloud Storage (main website’s assets)
Prerender (for the web crawler)
We can distribute the request by user agent from http header.
At first, determine $is_bot value by user agent http header.
To avoid an infinite loop, we attach from_prerender cookie while the prerender visits the page.
For the raw file, proxy to GCS as usual.
map $http_user_agent $is_bot {
default 1;
~*.*Googlebot\/.* 1;
...
}
map $uri $is_raw_file {
default 0;
"~(^.+\.[a-zA-Z0-9]+$)" 1;
}
map $is_bot$from_prerender$is_raw_file $to_prerender {
default 0;
100 1;
}If the requirements are met, we proxy the request to Prerender service, otherwise to GCS.
location / {
if ($to_prerender = 1) {
proxy_pass $PRERENDER_URI;
}
proxy_pass $GCS_URI;
}Customize status code for Prerender
You could customize the status code by adding a meta tag.
<meta name="render:status_code" content="404" />In our case, we don’t want to see the sold out or suspended item appear on the search result page.
Rate limiting
One of the important things is to decide the Request Per Second of your website. Usually, we scale out the application automatically. However, for serving web crawlers, it’s not a good idea. If Prerender handles too many requests, its latency becomes very long and sometimes returns an empty response. It makes a worse effect for SEO than returning a 5xx response. For example, if we aim for 100 RPS and we have 50 pods running nginx within the cluster, each pod should deal with 100/50 = 2 requests per second.
Set the limit_req_zone and limit_req_key within Prerender proxy:
limit_req_zone $limit_req_key zone=prerender:10m rate=8r/s;
if ($to_prerender = 1) {
set $limit_req_key "prerender";
proxy_pass $PRERENDER_URI;
}Now if the RPS exceeds the limit, it will get a 503 http response.
Load testing
It’s important to know how much of the resource is required for the application. APIs on the development environment can’t serve required RPS. In order to do the load testing, we mock these API responses. To mock API responses, we created a proxy server for API requests, and recorded the combinations of each API request and response. Next, we created a mock server to return API responses referring to the recorded combinations of each API request and response. After the series of load testing, we found that to serve 1 RPS consumes around 4 CPU cores. So we set the pod’s CPU limit to 8 cores, then it requires 100 * 4 / 8 = 50 pods to serve 100 RPS.
Rendertron doesn’t support graceful shutdown
Even if we limit the requests, it still costs a lot. Therefore, we adopted the preemptible node pool to save on costs. To use the preemptible node pool, the application should be able to gracefully shutdown itself within 25 seconds. However, rendertron doesn’t support the graceful shutdown. After it receives a SIGTERM signal it ignores it and continues running.
Here is an easy and viable solution. Preemptible node pool reclaim is similar to pod get deleted behavior. Soon after node reclaim, a pod no longer receives traffic. We assure all the prerender requests don’t exceed 25 seconds. When the node is reclaimed, Prerender sleeps enough time to finish the request sent before the node reclaim, no modification required on the codebase.
spec:
lifecycle:
preStop:
exec:
# prerender is configured to ignore the SIGTERM signal
# In case SIGTERM affect the application, sleep until receiving the SIGKILL
command: ["/bin/sleep", "25"]
# We are using preemptible nodes, terminationGracePeriodSeconds should be less than 25 seconds
# https://cloud.google.com/kubernetes-engine/docs/how-to/preemptible-vms
terminationGracePeriodSeconds: 25Memory leak of puppeteer
After we served the prerender service for a while, we found out the memory usage slowly increased over time until hitting the limit. Because Rendertron uses puppeteer to render the page, the decent way is to dive into puppeteer’s codebase to find out the root cause. Since we could do the graceful shutdown by sleeping, we decided to use the cron job which periodically rolls out the deployment until it hits the memory limit.
Undocument behavior with service worker
Rendertron has a known issue to return 400 if service worker is registered. Eventually, we follow this pull request to use the Incognito context, though it will cost more resources. Besides, return 404 for the prerender’s request to sw.js file.
map $uri $request_sw {
default 0;
~*/sw.js 1;
}
map $request_sw$from_prerender $sw_to_prerender {
default 0;
11 1;
}
if ($sw_to_dynamic_render = 1) {
return 404;
}Improve performance by blocking unnecessary requests
For example, to exclude Google Tag Manager from prerender requests,configure the restricted URL pattern on config.json:
{
"restrictedUrlPattern": "(www\\.googletagmanager\\.com)",
}Puppeteer document of aborting non-essential requests
Alternative solution for dynamic rendering
As we have gone this far with rendertron, we have done many workarounds to make it stable. There is another solution called prerender. If you are considering implementing the dynamic rendering service, it might also be a good candidate.



