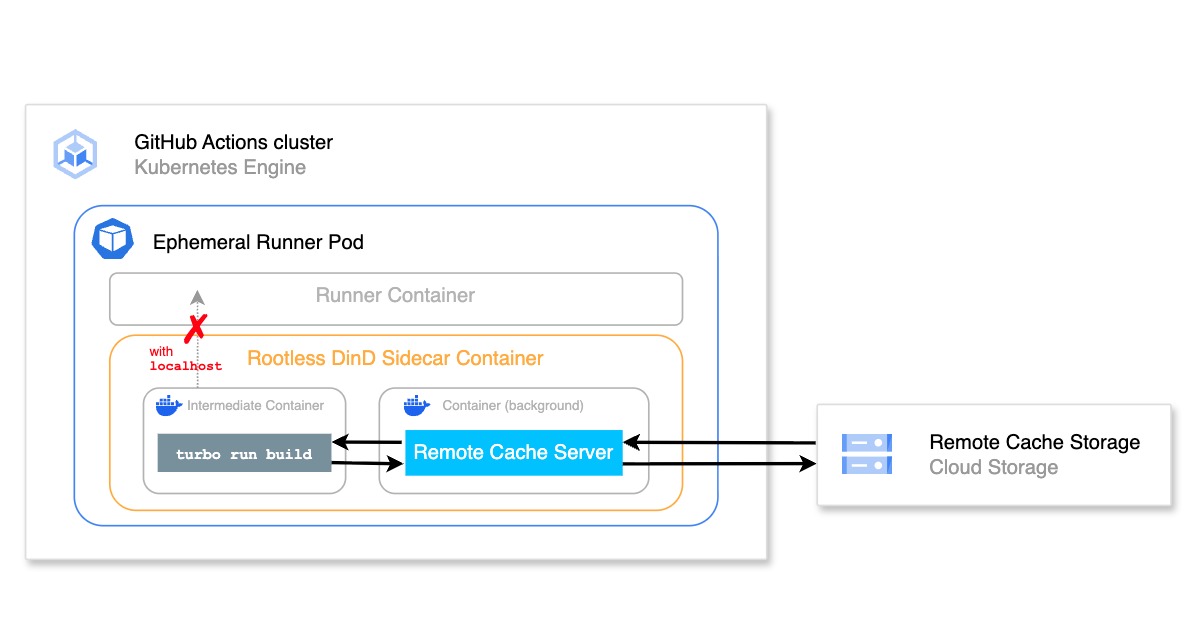
* This article is a translation of the Japanese article written on September 9, 2021.
Hello! I’m @tjun, an Engineering Manager for Merpay SRE. This article is for day 1 of Merpay Tech Openness Month 2021. I spoke previously about the SRE Team at SRE Next, but couldn’t find a good opportunity to talk about what’s happened since then, so I decided to write a blog article instead. We’re still not 100% there as a team, but I hope this article will serve as a reference for anyone who might create an SRE team in the future.
Introduction
What is SRE?
How SRE works will likely vary by organization or system scale, architecture, or the services being handled. There are several SRE books that you could refer to. However, something like Google’s methods aren’t necessarily going to work well in your company unless some changes are made. You need to take its foundational concept and culture into consideration as you apply actual methods in a way that matches your own organization.
I’m often asked what SRE is or how SRE engineers differ from infrastructure engineers. The role of an SRE is sometimes defined as resolving operational issues through software engineering. Personally, I prefer to think of it as creating a balance between reliability and velocity, as introduced in The SRE I Aspire to Be. As the name implies, SRE is a team that creates reliability.
However, if all you pursue is reliability, your goal will tend to shift toward controlling releases and then preventing releases (and therefore preventing failure) as much as possible. In order to make a service a success, we need to provide new functionality that customers can make use of and be satisfied with. With that mind, I think that an organization’s SRE goal should be to determine the right balance between reliability/velocity and work to achieve that balance.
Toward that end, I believe that this role requires both writing code and communicating with organizations. This type of work sees a wide range of practices being developed, such as reaching consensus on the target level of reliability as determined in Service Level Objectives (SLO) and error budgets, arranging incident response and observability to reduce error budget costs, establishing systems to allow for canary releases and chaos engineering to allow for minor failures, and increasing productivity through automation.
If we think of reliability as a feature, then that would be a very important function for Merpay, which is a financial service. In order to provide users with greater value, we need to create a good balance between reliability and service growth. I believe that this is an important role for SRE. At the same time, SRE’s other role should be to increase satisfaction for both service users and developers.
Merpay SRE operating environment
There are several unique characteristics of the operating environment used by the Merpay SRE Team.
- There are more than 60 microservices in the microservices architecture. Microservices are operated by developers, while SRE provides support and is responsible for operation of the shared infrastructure.
- The Mercari Group uses a shared microservices infrastructure called Microservices Platform, and the Microservices Platform Team builds and operates elements including the Kubernetes cluster and CI/CD pipeline.
- Merpay is a financial service, so reliability is extremely important.
Therefore, services are not operated by SRE alone, but in collaboration with developers and other teams such as the Microservices Platform Team.
Team formation and changes
I’ll give a brief explanation of what the SRE team and I have been doing since I joined the team. A rough timeline is shown below.
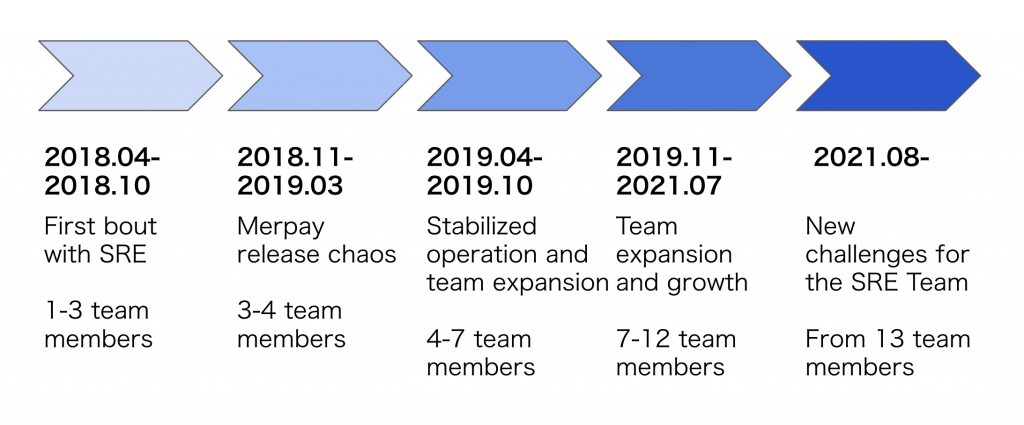
- April to October 2018: The beginning of the SRE Team
- We caught up with Microservices Platform and designed/built infrastructures.
- At this time, we were less of a team and more of a collection of individual SREs, with each member focused on what needed to be done to release the service.
- November 2018 to March 2019: Merpay release chaos
- We ran into various issues leading up to releasing Merpay in February 2019, and work didn’t slow down for a while, even after release.
- There were all kinds of problems before and after release, so this was a very tough time with one member being on-call and another being half on-call to support.
- April to June 2019: Start of operation
- New members were able to catch up, and we reached a point where four people could be placed on-call.
- Second half of 2019: Team expansion (from 4 to 7 members)
- We began preparing some documents and started to feel like a team for the first time.
- 13-member team as of August 2021
As described above, each individual SRE engineer initially would do whatever was required on the infrastructure (GCP, Kubernetes, etc.) to release the service. After releasing the service, we kept daily operations going while gradually expanding the organization, and finally started functioning as an actual team.
Team evolution and expansion
The SRE Team continued to change as we added new members and made improvements. Read on for more details
Our workload decreased
SRE work is required for various operations before and after service release, and we were dealing with a high operational load. Although increasing the size of the team definitely helped, we were able to really improve our workload by eliminating unnecessary alerts, automating or creating tools for operations, and building systems that could be run by developers. For example, we were able to reduce the amount of SRE database operations by around 60% over half a year.
We shared knowledge
We had already begun taking knowledge held exclusively by specific members and sharing it throughout the team. Of course, documentation was key to that, but we also established an on-call shadowing system, where someone who is already on-call would teach a new member how to respond to requests from developers and handle alerts. They would work as a pair and share knowledge.
We implemented several means for sharing information between people on-call. For example, when on-call, people could check the Datadog dashboard beforehand and share concerns with the team during daily morning meetings. We also created an on-call note in Google Docs for entering daily alerts, and held weekly team meetings for people on-call to share information on incidents that occurred that week.
The team started to behave more proactively
For a while after releasing Merpay, a lot of our work was reactive and taken from a short-term perspective as we were busy with immediate work that needed to get done, such as responding to developer requests, handling operations and alerts/incidents, and supporting the release of new features. However, we began to work more proactively, in advance of future issues. This is because the size of the SRE Team increased, the amount of SRE operation work decreased due to automation and systemization, and the number of alerts dropped due to increases in microservice quality. For example, we made progress in actively reducing the number of alerts (rather than simply responding to them), and instead of manually adjusting the number of databases, we developed systems that could do this automatically.
Embedded SRE
Embedded SRE involves joining a team developing a feature, and engaging as a member of that team in work related to service reliability. Prior to engaging in embedded SRE, we would work in a way that takes a wide view of an entire microservice, and either focus on common service issues or handle issues brought up by developers. For the last six months, some of our SRE members have been working as embedded SREs in development teams. They communicate with developers, determine issues with individual teams or microservices, and have begun working on issues that would otherwise be difficult for developers to solve on their own.
We used to be so busy with daily operations and handling immediate issues. Since then, we’ve made various improvements and now have begun thinking about the future.
What I accomplished as an SRE Engineering Manager
For tomorrow’s Merpay Tech Openness Month 2021 article (9/2), yoichi will write about the role of an Engineering Manager (EM) at Merpay, so please give that a read if interested. I described in the previous sections how our team changed over time. My work as an SRE EM also changed. When there were four or fewer members on the team, 95% of my time was spent on either actual SRE or Tech Lead work. We had our hands full with work leading up to service release and with initial service operations, so my role was to assign priorities and take the initiative. As the team gradually expanded, my role changed and I began delegating work. As of the date of this article (September 1, 2021), we now have three EMs on the SRE Team, and my role now includes managing these managers.
In Merpay, SRE EMs serve as EMs for the SRE Team, but also design and implement service operations for all of Merpay. I was involved in the following types of work, leading up to service release.
Designing an on-call system
Merpay uses a microservices architecture composed now of more than 60 microservices. Engineer teams are responsible for developing and operating multiple microservices, so it’s not only the SREs that receive alerts while on-call. Therefore, we needed to determine what system to use for the organization and what rules to use as a foundation for doing on-call work. For example, in determining what system to use, we consulted with both HR and labor departments and decided on a one-week rotation with at least three people. We also had to determine how to handle work on weekends and late at night. We referred to articles such as How we do on-call at Monzo in investigating and designing a cooperative on-call system for developers and SREs.
Improving incident handling procedures
When an SRE or developer is on-call and receives an alert, they need to determine the cause and scope. If the alert is serious enough to impact customers, it’s handled as an incident, and we need to notify customers or contact partners. We worked to determine standards, escalation methods, and incident report templates to determine when an alert needs to be escalated and handled as an incident.
Evangelizing SLO (Service Level Objective)
We need to consider the proper balance between pursuing reliability as a financial service and providing/adding functions for use as a smartphone payment service. We therefore had to set standards to determine whether to issue an alert and respond or to let it go. We decided that we would need to speak with people other than SREs (developers and Product Managers [PM]) about the concept of SLO, and determine SLOs for each microservice. We worked to evangelize SLO by writing documents and presenting them during internal all-hands events. I think we were able to raise some amount of awareness on this topic.
Formulating release/operation rules
We have set several rules on safely releasing and operating services. For example, products/services can only be released from Monday through Thursday until 18:00, and release requires approval from a manager (to prevent a single engineer from releasing something alone). We also needed some rules for operation. For example, we created an operation tool which requires a query review for access to a production database. SREs normally do not have access to production databases, so we also created a tool to provide these privileges only when needed and approved.
Reference:
- gchammer, a tool for reviewing and executing Spanner queries | Mercari Engineering
- Qray, a tool for providing SREs with temporary privileges to production environments | Mercari Engineering
The future of the SRE Team
The Merpay SRE Team has gradually improved over time. However, there are still plenty of things we’d like to try. We aim to continue to provide a highly reliable financial service to customers using Merpay, for developers and SREs to work together to engage in sound operations, and to focus on developing new features.
Following are some examples of the direction I’d like us to head in:
- Reliable and scalable infrastructure
- Provide service infrastructure that is robust even against external factors such as rapidly increasing cloud and external system failures/requests
- Build infrastructure that can provide reliability for financial services
- Develop microservices reliability
- Increase activities to improve microservice reliability as embedded SRE
- Make SLO actionable: Standardize operations using SLOs
- Production-ready guardrail: Create systems to ensure high reliability prior to releasing microservices
- Improve developer productivity
- Make on-call healthy: Ensure that the on-call system is simple and can be operated under a lower load
- Learn from incidents: Always learn from failures and continue to improve, so that the same failure does not occur again
- Operation automation: Automate and code operations as much as possible
I’d like us to take on more SRE projects than ever before, and to improve reliability and productivity while designing and implementing projects. Mercoin, Inc. was established in April 2021 as a Mercari subsidiary, in order to plan and develop services related to crypto-assets and blockchains. Several members of Merpay SRE have been assigned to Mercoin, where they are currently investigating and designing infrastructures.
This field will continue to require a high level of reliability, and we will need to expand the team in order to contribute to services and organizations as Merpay/Mercoin SRE. We’re currently hiring both members and managers for Merpay/Mercoin SRE. If you’re interested in these roles, please feel free to contact us. I’ve placed links to our careers page at the end of the article. We also conduct casual interviews for people who just want to hear more.
Merpay/Mercoin SRE positions currently open:
Articles and videos used for reference in writing this article