こんにちは。株式会社メルペイSREチームの@kekeです。
Merpay Advent Calendar の9日目の記事です。
本記事ではスケーラブルなDatadogモニタリングシステムをTerraformによって実現した方法を紹介します。
はじめに
すでに多くの発表があるのでご存知の方も多いのではないかと思いますが、メルペイではマイクロサービスアーキテクチャを採用しています。

各マイクロサービスのデベロッパーは責任を持ってそれぞれのサービスを開発・運用しています。
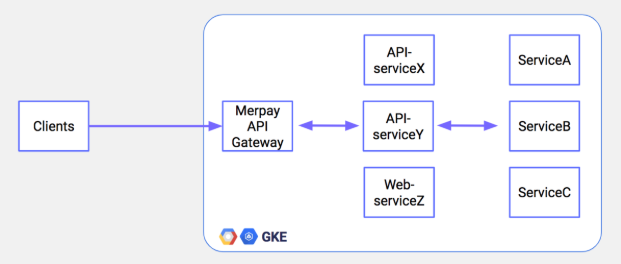
SRE(Site Reliability Engineering)チームはシステムの信頼性を失うことなく高い開発速度を実現できるような仕組みづくりに取り組み、それをデベロッパーに提供しています。メルペイという金融事業の、高い信頼性の実現のためにサービスを横断的にモニタリングをしています。可視化のためのダッシュボードにはDatadogを使っています。一つのダッシュボードの例ですが、以下のようにサービスごとにグラフがあります。

メルペイSREチームでは毎日このような横断的なダッシュボードを全員でみる時間を取っています。
日常的にみることによって機械的なアラートでは気づけない異常検知をできるようにしています。
しかし、横断的にモニタリングをしているため、マイクロサービスが増える度に監視しないといけない対象が増えます。Datadogダッシュボードを追加したり、アラートを追加したり監視するための準備も多く必要になっていました。
Terraform管理前
Datadog Web UI上でグラフを作成していました。
グラフの追加だけでなく、監視したいメトリクスの変更や必要なくなったグラフの削除などもUI上で行っていました。
しかし、このような運用はいくつかの問題点がありました。
- ダッシュボード上でよく分からない変更がある(Web UIからの変更ではHistoryは残らないため誰が何のために変更したのか分からない)
- サービスや対象によって監視をするメトリクスが疎らになっている
- ダッシュボード自体のバックアップがない(もしダッシュボードを誰かが誤って消してしまうと1から作り直す必要がある)
- サービスが増加すると、新たにグラフを誰かが設定をしないといけない
これからマイクロサービスがさらに増えたりすることを考えると、より問題になること自明でした。そのため今回はInfrastructure as Code(以下、IaC)の理念のもとにTerraform化を行い、モニタリングシステム自体のスケーラビリティの獲得を試みました。
ゴール
メルペイSREとして以下のようなゴールを持って取り組みました。
- サービスが増加しても小さな労力でモニタリングダッシュボードを作成することができる状態になること
- どのようなモニタリングが行われているかWebUIだけではなく、ソースコードによって知ることができ、変更をGitHubで追えるような状況になること
- 各マイクロサービスのモニタリング対象を疎らなく、信頼性の最低限を担保するためのモニタリングシステムを構築すること
これらのゴールはSREの理念に基づいています。
SREはすべてを監視する必要はなく、最低限の信頼性を担保できるようなモニタリングの仕組みづくりをすることが重要です。各マイクロサービスの共通的な監視対象を絞り、SREが基盤として監視していき、デベロッパーはその基盤から外れるものを主に監視します。今回はSREが主にみる共通的な監視対象をTerraform化しました。

そのことによって、デベロッパーの負荷が軽減されるとともに、新しくマイクロサービスが追加することになっても他のサービスと同等の信頼性を実現するためのハードルが低くなります。

またデベロッパーは開発に時間を割けるようになります。SREは監視を均質化することができ、メルペイのサービス全体での開発速度を高めながらも信頼性の土台を作ることができます。
Terraform化のプロセス
実際にどのようにTerraform管理をすることができるのかを紹介します。
1. Terraformerによって既存のダッシュボードをimportする
Terraformerという、既存のリソースをimportしてtfファイルを作成してくれるツールを使いました。
Datadogダッシュボードにとどまらず、既に作成されてある色んなリソースをTerraform管理するための手助けをしてくれるものです。
今回のダッシュボードの場合だとダッシュボードIDを指定してimportしました。
DATADOG_API_KEY="xxx" DATADOG_APP_KEY="xxx" terraformer import datadog --resources=dashboard --filter=datadog_dashboard=<DATADOG_DASHBOARD_ID>
Terraformerによってimportをするとtfファイルを作成してくれます。
TerraformのDynamic Blockに書き直す
Terraform 0.12からDynamic Blockという繰り返し定義が必要なBlockを繰り返しfor-loop文のように書くことができる機能が追加されました。
これによって例えばDatadogダッシュボードのTerraform resourceを簡略化することができます。
Dynamic Blockを使わなかったときは以下のようなものになっています。
resource “datadog_dashboard” “xxx_dashboard” {
widget {
… service-1のグラフ
}
widget {
...service-2のグラフ
}
…
widget {
...service-100のグラフ
}
}
それをこの機能を使うことによって以下のように書き換えることができます。
resource “datadog_dasboard” “xxx_dasboard” {
dynamic widget {
for_each = var.services
content {
group_definition {
widget {
...service-nのグラフ
}
}
}
}
この参照しているvariableにサービス一覧があります。
variable “services” {
default = [{
name = “serivce-1”
}{
name = “service-2”
}
…
{
name = “service-100”
}]
}
共通化できるものはDynamic Blockのcontent内に定義しました。
terraform applyをするフローはGithub Actionsによって作りました。
ポイント
Dynamic Blockの機能をつかう場合は、以下のような注意点が必要です。
- メトリクスの記述にばらつきがないようすること
- 例えば tagにserviceとservice_idとばらつきがある場合は、共通化できない
- はじめからtagのkeyを統一することが大事
- ソースコード通りimportができなくなることに留意すること
- tfファイルが評価されるときにDynamic Blockが展開されるためTerraformerのような実機(=Datadog APIやGCP API)の状態を読んでtfファイルを生成するようなツールでは展開後のものを生成することを念頭に置く
- つまりIaCで管理しているのはDynamic Blockが展開前なので、terraformer importしてソースコードレベルで差分ができてしまう
Terraform管理後
Terraform管理を始めて以下のようなメリットがありました。
1. マイクロサービスの増減に対してDashboardが同期しやすくなった
マイクロサービスが増えてもSREがみるDatadog Dashboardの管理が簡単になりました。
例えば、サービスが1つ増えたとしても単純な3行を追加するだけです。
+{ + name = “service-101” + }
これによって、先程の図にもあったように他のサービスと同じようなグラフがダッシュボードが追加されます。
マイクロサービスが無くなったときもも然りです。
2. 変更点がわかりやすくなった
ソースコードによって管理しはじめたため、何故ダッシュボードが変更されているのかを共有できるようになりました。
GitHubのPull Requestでレビューもしているので、より確かに変更できました。

3. 変更を簡単にできるようになった
Dynamic Blockをつかっているおかげで「全サービスのXメトリクスからYメトリクスに監視対象を変更したい」といったことでもBlockの中身を数行書き換えると反映させることができます。たとえ、いくらサービスがあっても負荷は変わらないです。
4. ダッシュボードのバックアップがある安心感が芽生えた
今回のTerraform管理による副産物ですが、バックアップができたことが思ったよりも恩恵が大きかったです。意図せず消してしまっても慌てずに済むようになりました。潜在的なリスクがなくなりました。
やはり、何ごともバックアップが必要です。
振り返って
この取り組み自体は複雑ではなく、Terraform 0.12に導入された機能のおかげもあってすぐに実現できました。
簡単ではあったものの、私にとって「SREとは何をすべきか」という問いに小さな答えをくれるような取り組みでした。
Terraform管理以前は、監視のスケーラビリティやクオリティに問題がありました。
これをソフトウェア的問題と捉え、Terraformによって解決をすることに決めましたが2つの大きな壁がありました。
- Infrastracture as Code(IaC)の理念によりUI上から変更ができなくなることが良いのかという点
- どこまでをSREとして監視に注力をするのか境界を決めなければいけない点
前者に対してはソフトなIaCにすることにしました。基本的にはソースコードで管理をするものの、差分を検知する仕組みを作って(Github ActionsによるTerraformのCI)強制力の強いものにはしませんでした。特に、対象がダッシュボードなので変更されも大きな問題はないこととダッシュボード自体UIでぽちぽち変更するような特性を持つものだからです。それによってダッシュボードのDXを大きく損なうことなく、同時に宣言的に管理ができています。一応、差分をチェックするBotもいます。例えば4つ目のダッシュボードがUI上で変更されたことがわかるので、気づいた時にImportするかダッシュボードを元に戻しています。

後者については監視する対象が横断的にサービスをまたぐため、共通部分を対象にしてサービス全体の信頼性の獲得・維持という本来の目標を決めました。SREとしては何もかも監視をする必要はなく、サービスの最低限の信頼性の担保にフォーカスすることによって 監視のしすぎを防げ、無駄な労力を避けることができます。
SREとしてスケーラブルなモニタリングシステムをTerraform管理というソフトウェア的ソリューションで作ることができたのは良かったのではないかと思います。
最後に
今回の「Datadog Monitor at Scale w/ Terrafrom」に限らず、メルペイのミッションの実現のために様々なチャレンジしています。SREチームは、メルペイのサービスにおけるパフォーマンスや信頼性、スケーラビリティを向上させるためのソフトウェアの開発・運用を行います。もし興味があればご検討ください。
apply.workable.com]
最後までありがとうございました。
明日のMerpay Advent Calendar 執筆担当はBackend Engineer の @execjosh さんです。引き続きお楽しみください。