The sixth day’s post of Mercari Advent Calendar 2019 is brought to you by Darren.
Hi! I’m Darren, a software engineer at Mercari. As a member of the Data Platform Team, I have the privilege of working with all levels of our technical stack, from the native apps, to high-throughput low-latency backend services, through massively distributed data pipelines, and into the heart of our machine learning models. Over a series of posts, I’m going to talk about this end-to-end ecosystem and how we solve some large-scale technical challenges. But today, I want to talk about plankton.
*Record scratch*
“Did he say plankton? Is that a new Jupyter add-on?”
Let’s take a step back.
Everyone has heard the common refrain “data is the new oil”. We hear it everywhere from tech conferences to the mainstream media. But this metaphor actually suffers quite a bit.
What is oil anyway? Well, around 1.5 billion years ago, the world ran pip install photosynthetic-eukaryotes. These simple organisms ruled the seas for a billion years, and eventually evolved into the tiny and diverse sea organisms known as plankton. Those plankton died and fell to the bottom of the ocean, and over millions of years of time and pressure, they turned into the hydrocarbon reserves that we know as “oil” (Sorry, elementary school kids everywhere. It wasn’t really dinosaurs that turned into oil; it was mostly algae and zooplankton). Modern humans extract that oil out of the ground and burn it to release energy that powers much of our world.
When people say “data is the new oil”, they mean that just like oil, there is a huge amount of stored potential value in data, and we just need to “extract” the value in order to power the information economy in the same way that we extract oil and feed it into industrial machines. But the similarities end there.
In fact, data is nothing like oil. We don’t need to search for data like we prospect for oil, because data is something that we as engineers directly generate. In fact, the world is overrun with data, much of it is not very valuable, and the amount of data being created each year is growing exponentially!
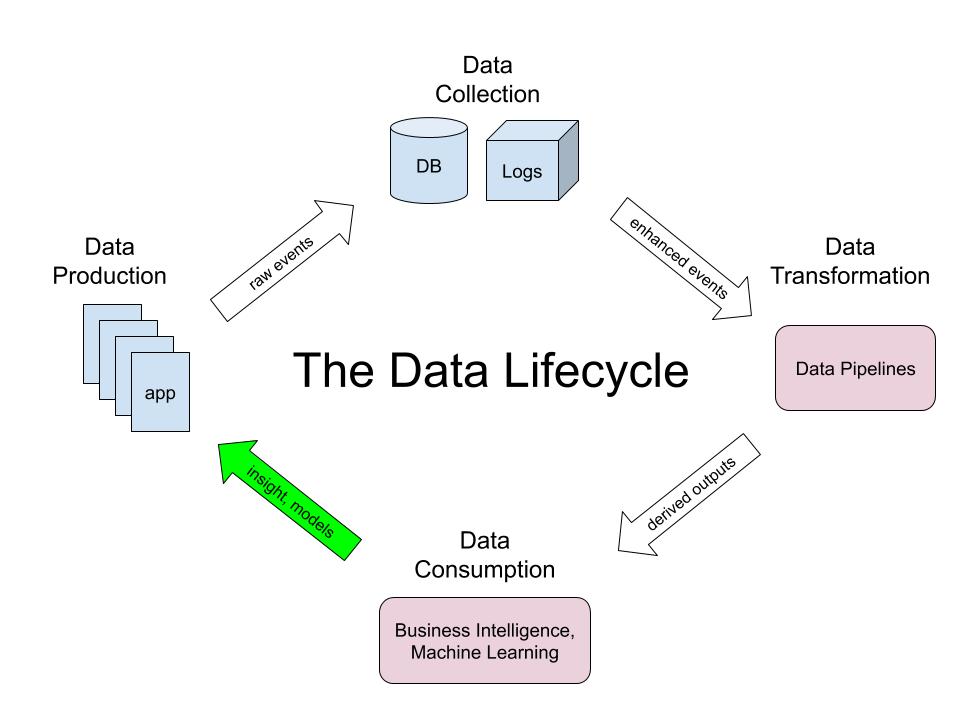
So what does this mean for data? I like to simplify how we think about data into the following lifecycle:

Starting on the left, we have the app, in our case the used goods marketplace Mercari. In the “Data Production” step, millions of users using our app generate what are known as client events (e.g., tapping a button to purchase an item), which flow to our backend servers in the “Data Collection” step. Since we’re an e-commerce platform, we store transactions in a relational database, but we also generate many logs about non-transactional events. All of that data is filtered and annotated, and it then flows to the “Data Transformation” step, where we use tools such as Apache Beam and Cloud Dataflow to process this raw data into more useful derived outputs. These outputs are then used as the input for the “Data Consumption” step, which comprises analytics and machine learning. But the most important step is the arrow from “Data Consumption” back to “Data Production”. The point of this data lifecycle, after all, is to improve the app, so if the learnings don’t flow back into the product, then we might as well have stopped after the transaction step and eaten a plankton sandwich.
In future posts, we’ll dive into the technical details of each of these steps, including how we work with data schemas, how we create efficient data pipelines for quickly processing large amounts of data, how we connect our machine learning infrastructure with the rest of our data ecosystem, and more. Stay tuned ;).
Happy holidays from Mercari Engineering!
Tomorrow’s blog – the 7th in the Advent Calendar – will be written by @jollyjoester. Hope you are looking forward to it!




