
株式会社メルカリのPlatform Enablerチームで新卒エンジニアとして働くTianchen Wang (@Amadeus)です。今回は、Large Language Model (LLM)を利用してフリマアプリ「メルカリ」の次世代インシデント対応を構築した事例を共有します。
今日の急速に進化する技術環境において、堅牢なオンコール体制を維持することは、サービスの継続性を確保するために重要です。インシデントは避けられないものですが、迅速に対応し解決する能力は、お客さまに安心・安全の体験を提供するために不可欠です。これは、メルカリのすべてのSite Reliability Engineer(SRE)と従業員が共有する目標です。
この記事では、Platform Enablerチームが生成AIを活用して開発したオンコールバディであるIBIS (Incident Buddy & Insight System) の紹介をします。IBISは、エンジニアのインシデント解決を迅速化し、MTTR(Mean Time to Recovery)を短縮することで、組織やエンジニアが負担するオンコール対応コストを削減することを目的として設計されています。
課題の認識と解決のモチベーション
メルカリでは、お客さまが安心・安全に製品を利用できることがすべての従業員によって共有される優先の目標およびビジョンです。このために、異なる部門が協力し、オンコールチームを設立しました。毎週、オンコールメンバーには多くのアラートが発生し、その多くは実際にお客さまに影響を与えたインシデントとして扱われます。これらのインシデントはお客さま体験の悪化をもたらすため、インシデントが回復するまでの平均時間(MTTR)を短くすることが被害を最小化する上で重要です。
さらに、オンコールメンバーはこれらのインシデントに対処するために多大な時間を割かなければならず、新しい機能を開発するために利用できる時間が間接的に削減され、ビジネス目標の達成能力に影響を及ぼします。
結果として、インシデント発生時にMTTRを短縮し、オンコールメンバーへの負担を軽減することが、プラットフォームチームにとって重要な課題となっていますが、Large Language Model (LLM)の登場により、これらのインシデント対応を自動化することが可能な解決策として浮上しました。
深掘り:IBISのアーキテクチャ
インシデント対応システム「IBIS」のアーキテクチャを詳しく見ていきましょう。
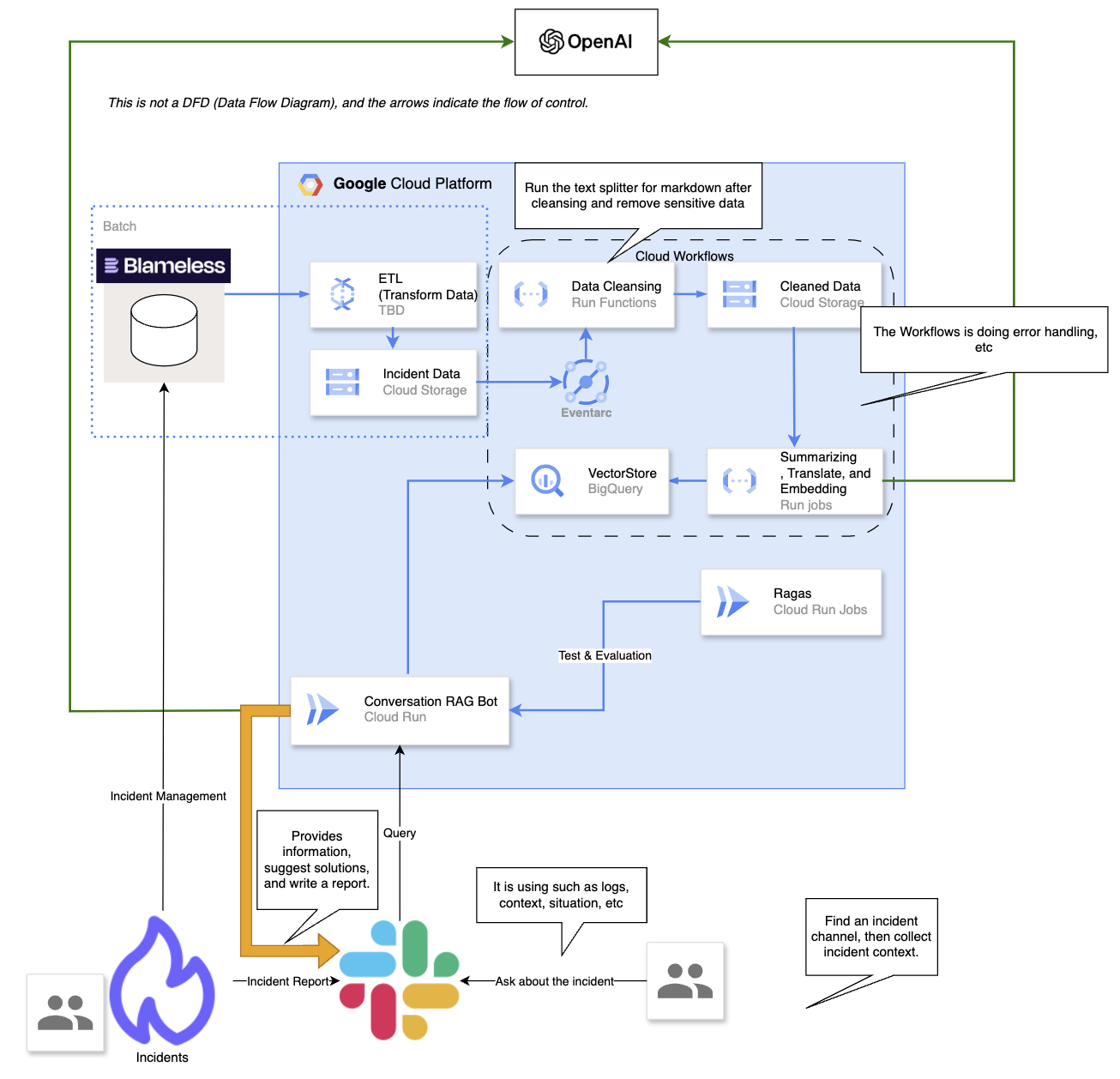
図1. IBISのアーキテクチャ
高レベルの視点から、過去のインシデントについての振り返りレポート情報をインシデント管理ツールBlamelessから抽出します。これらのレポートには、暫定措置、根本原因、障害による損害などのデータが含まれています。これらのデータはクレンジング、翻訳、および要約のプロセスを受けます。その後、OpenAIの埋め込みモデルを使用して、これらのデータソースからベクターを作成します。
ユーザーが自然言語でSlackボットに質問を投げかけると、これらのクエリもベクターに変換されます。その後、会話コンポーネントが質問に関連するベクター埋め込みを検索し、関連する言語構造を整理してユーザーに応答を形成します。
アーキテクチャ全体を「データの前処理」と「会話機能」の2つの主要コンポーネントに分けて詳しく説明します。
データの前処理
以下はIBISがインシデントデータを前処理する方法です。
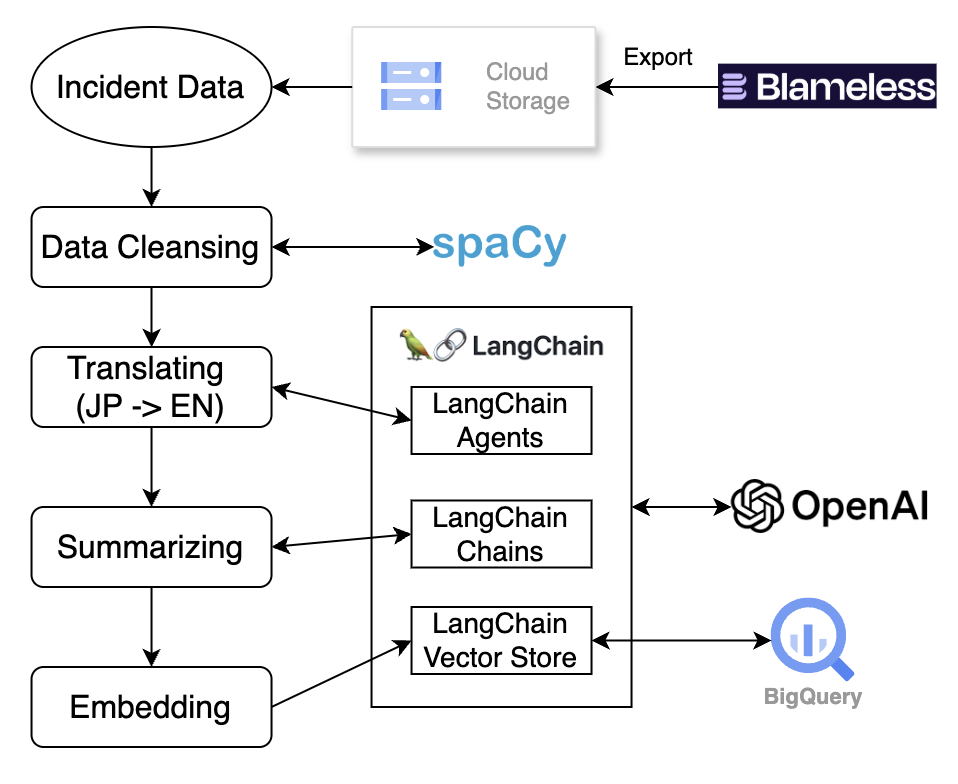
図2. IBISのデータ処理プロセス
データ抽出
Blamelessには各インシデントのプロセス詳細、インシデントSlackチャンネルからのチャットログ、振り返りおよびフォローアップアクションなど重要なインシデント関連情報が含まれています。Google Cloud Schedulerを活用し、Blamelessの外部APIから最新のインシデントレポートを定期的にGoogle Cloud Storageバケットにエクスポートします。このプロセスはサーバーレスの原則に基づいて設計され、Google Cloud Run Jobs内で実行されます。
データクレンジング
Blamelessから取得したデータを無差別にLarge Language Model (LLM)に送信することはできません。それは、データに多数のテンプレートが含まれており、ベクター検索(コサイン類似度)の精度に大きく影響を与える可能性があるだけでなく、膨大な量の個人識別情報(PII)が含まれているためでもあります。潜在的な情報漏洩のリスクを軽減し、生成される結果の精度を高めるため、データクレンジングは必要なプロセスです。
データからテンプレートを除去するため、データがMarkdown形式であることを利用し、LangChainが提供するMarkdown Splitter機能を使って関連するセクションを抽出します。PIIに関しては、種類が多いため、SpaCy NLPモデルを使用してトークン化し、語の種類に基づいて潜在的に存在するPIIを削除します。
データクレンジングコンポーネントはGoogle Cloud Run Functionsで実行されます。このステージ以降は、Google Cloud Workflowを使用してシステム全体を管理します。Google Cloud Storage Bucketに新しいファイルが追加されると、Eventarcが自動的に新しいワークフローをトリガーします。このワークフローはHTTPを使用してデータクレンジング用のCloud Run Functionを起動し、完了するとプロセスの次のステージに進みます。クラウドワークフローを導入することで、ETLプロセス全体のコードメンテナンスが容易になります。
翻訳、要約、エンベディング
クリーンになったデータはプロセスの次の段階に進みます。データクレンジングのおかげで、LLMモデルを利用して、データをよりスマートに処理することができます。メルカリでは、インシデントレポートが日本語と英語で書かれているため、これらのレポートを英語に翻訳することは、検索精度を向上させるために重要なステップです。翻訳ステップをGPT-4oベースのLangChainに依頼しています。また、多くのレポートが長文であるため、内容の要約もベクター検索精度を向上させるために重要です。GPT-4oがデータの要約を支援します。最後に、翻訳された要約済みのデータはエンベディングを経て、ベクターデータベースに格納されます。
翻訳、要約およびエンベディングプロセスはGoogle Cloud Run Jobsで実行されます。データクレンジングが完了すると、Cloud WorkflowがCloud Run Jobを自動的にトリガーします。図2に示されているように、エンベディングされたデータはLangChainが提供するBigQueryベクターストアパッケージを使用して、BigQueryテーブルに格納されます。
会話機能
Slackベースの会話機能はIBISのコア機能です。私たちの設計では、ユーザーはSlackでボットに言及することで、自然言語でIBISに直接質問を投げかけることができます。この機能を実現するために、Slackからのリクエストを常時受信し、ベクターデータベースに基づいて応答を生成できるサーバーが必要です。
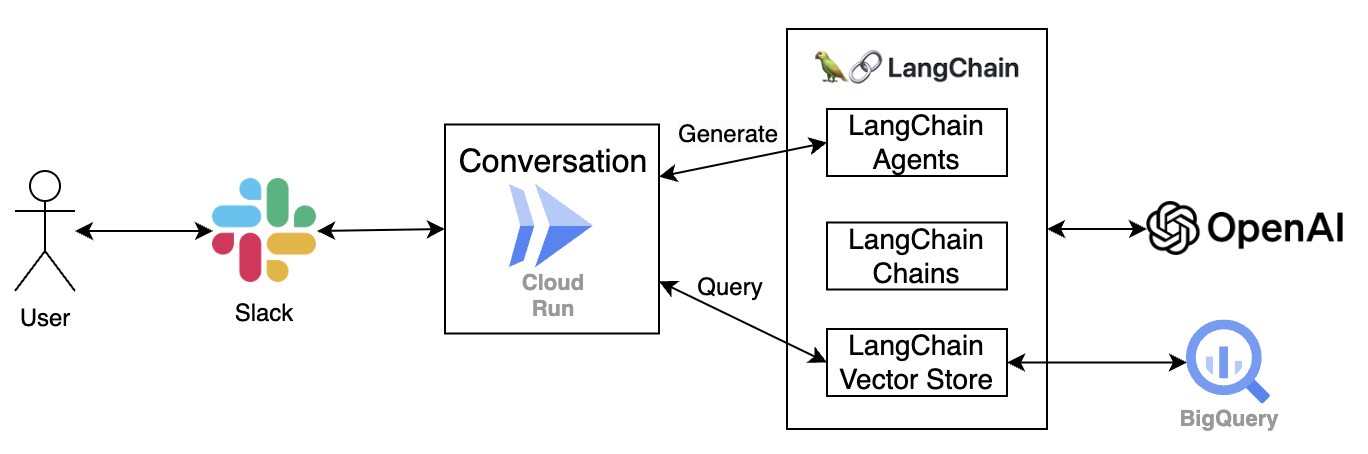
図3. IBISの会話システム
図3に示すように、このサーバーはGoogle Cloud Run Service上に構築されています。ベクターDBとして機能するBigQueryから関連情報を取得し、それをLLMモデルに送信して応答を生成します。
クエリの処理に加えて、会話コンポーネントは、短期記憶などの他の機能もサポートしており、インタラクティブな体験を向上させます。
短期記憶
エンジニアがインシデントの理解を時間とともに深めることを考慮し、同一スレッド内で記憶機能を取り入れることは、インシデントの解決策を提供するIBISの能力を強化するために重要です。図4に示されているように、LangChainのメモリ機能を使用して、同じチャンネルからのユーザーのクエリとLLMの応答を保存します。同じチャンネルで追加のクエリが投げかけられる場合、スレッド内の以前の会話がLLMに送信される入力の一部として付加されます。
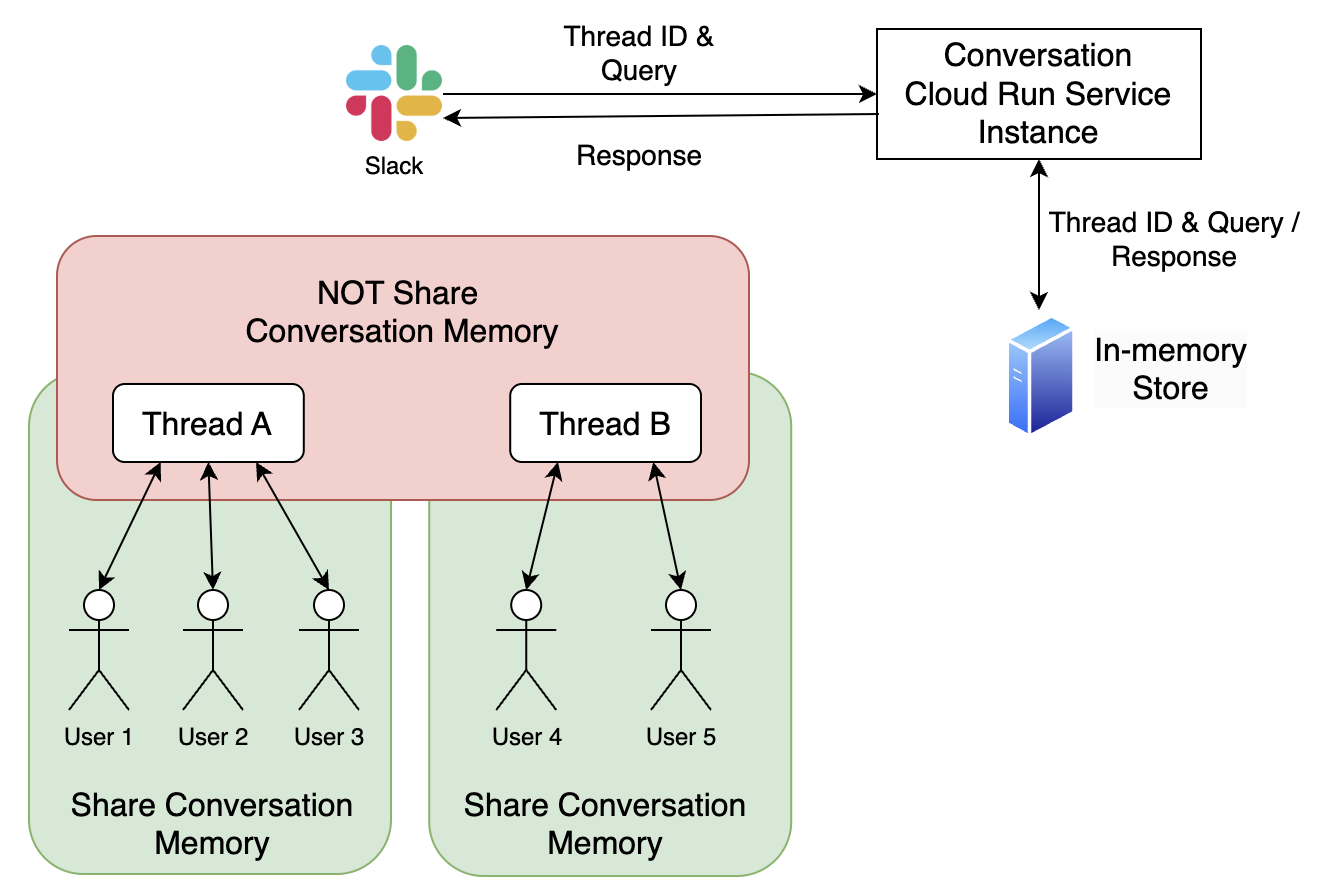
図4. 短期記憶の設計
このストレージソリューションは、メモリをCloud Run Serviceインスタンスのメモリ内に配置するため、新しいバージョンのIBISを再デプロイしてCloud Run Serviceを更新すると、メモリが消失します。詳細については、LangChainのメモリドキュメントを参照してください。
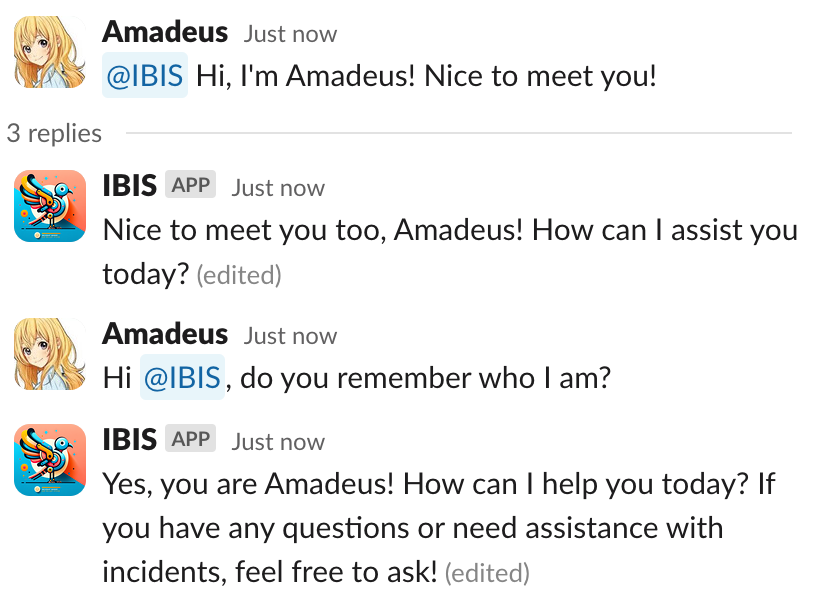
図5. 短期記憶のケース
インスタンスをアクティブに保つ
短期記憶機能のメモリデータが現在インスタンスに保存されているため、コールドスタート時にメモリが失われないようにこのインスタンスをアクティブに保つ必要があります。これを達成するために、このドキュメントのガイダンスに基づいた戦略を実施しました。Cloud Run Serviceインスタンスに定期的にアップタイムチェックを送信して、アクティブな状態を維持します。このアプローチはシンプルで、コストも最小限です。また、このサービスのスケールアップを制限し、インスタンスの最大数と最小数の両方を1に設定しました。
今後の展望
-
正確にユーザーフィードバックを収集することが主要な目標の一つです。自動評価のためのヒューマン・イン・ザ・ループアプローチを採用し、ユーザーの調査応答をデータポイントとして収集し、IBISを継続的に改善する計画です。
-
従来の言及ベースのクエリ方法からSlackフォームベースの質問アプローチに移行する予定です。この変更は、ユーザーのクエリを精緻化することにより、応答の精度を向上させることを目的としています。
-
社内ツールの継続更新を考慮し、会社のドキュメントに基づいてLLMモデルをfine-tuningする計画です。これにより、モデルが最新で関連性のある回答を提供することを確実にします。
まとめ
このプロジェクトは2024年12月末に初期バージョンをリリースしました。このブログを書いている時点までで(2025年1月)、IBISはメルカリのインシデント対応用のいくつかのslackチャンネルで使用可能になりました。このツールを利用するユーザーの数は増え続けているので、継続的にユーザーフィードバックを収集し、回復までの平均時間(MTTR)への影響を監視していきます。
さいごに
現在、株式会社メルカリでは学生インターン・新卒エンジニアを積極的に募集しています。ぜひJob Descriptionをご覧ください。




