
こんにちは。メルカリのSite Reliability Engineer (SRE)の@yakenjiです。
この記事は、Mercari Advent Calendar 2024 の2日目の記事です。
私たちメルカリのSREは、コアプロダクトであるフリマアプリ「メルカリ」の信頼性を維持・向上させるために、プロダクトのAvailability(可用性)とLatency(性能)を測定しています。また、それらに対してService Level Objective(SLO)を設定した上で、SLOを満たしているかや、一時的な障害などによりAvailabilityとLatencyが悪化していないかの監視を行っています。
その方法としてCritical User Journey (CUJ)に基づいたSLOを運用しています。今回、このSLOを見直し、以下を実現するSLOの再定義に取り組みました。
- CUJの定義の明確化
- 各CUJに対して1対1となるSLIの定義
- 各CUJとSLOのメンテナンスの自動化
- 障害時の各CUJの挙動のダッシュボードによる可視化
本取り組みによりSLOのメンテナンスにかかる時間を99%削減するとともに、障害検知後に影響範囲の特定にかかる時間をゼロにすることを実現しました。
本記事では、上記の取り組みである User Journey SLO について、見直しするに至った背景と上記4項目の詳細、特にE2E Testを用いた自動化によるSLOの継続的最新化とその活用の取り組みを共有します。
現状の課題意識
本題に入る前に、メルカリにおける2種類のSLOと現状の課題意識を共有します。この章を通じて、なぜ私たちがUser Journey SLOの取り組みを始めたのか、何を目指したのかを知っていただけたら幸いです。
マイクロサービスごとのSLOとその課題
メルカリでは、バックエンドにマイクロサービスアーキテクチャを採用しています。例えば、ユーザー情報はユーザーサービス、商品情報はアイテムサービスというように、あるドメインごとにマイクロサービスとして独立しています(上記は一例であり実際とは異なります)。各サービスには必ずオーナーとなるチームが存在し、独立して開発・運用を行っています。各チームは自らの管理するサービスにSLOを設定したうえで、その目標を下回らないように開発フローを回すことが義務付けられています。また、このSLOをベースとしたモニターを作成することで、開発チームは管理するサービスの障害をアラートとして受け取り障害対応も行います。
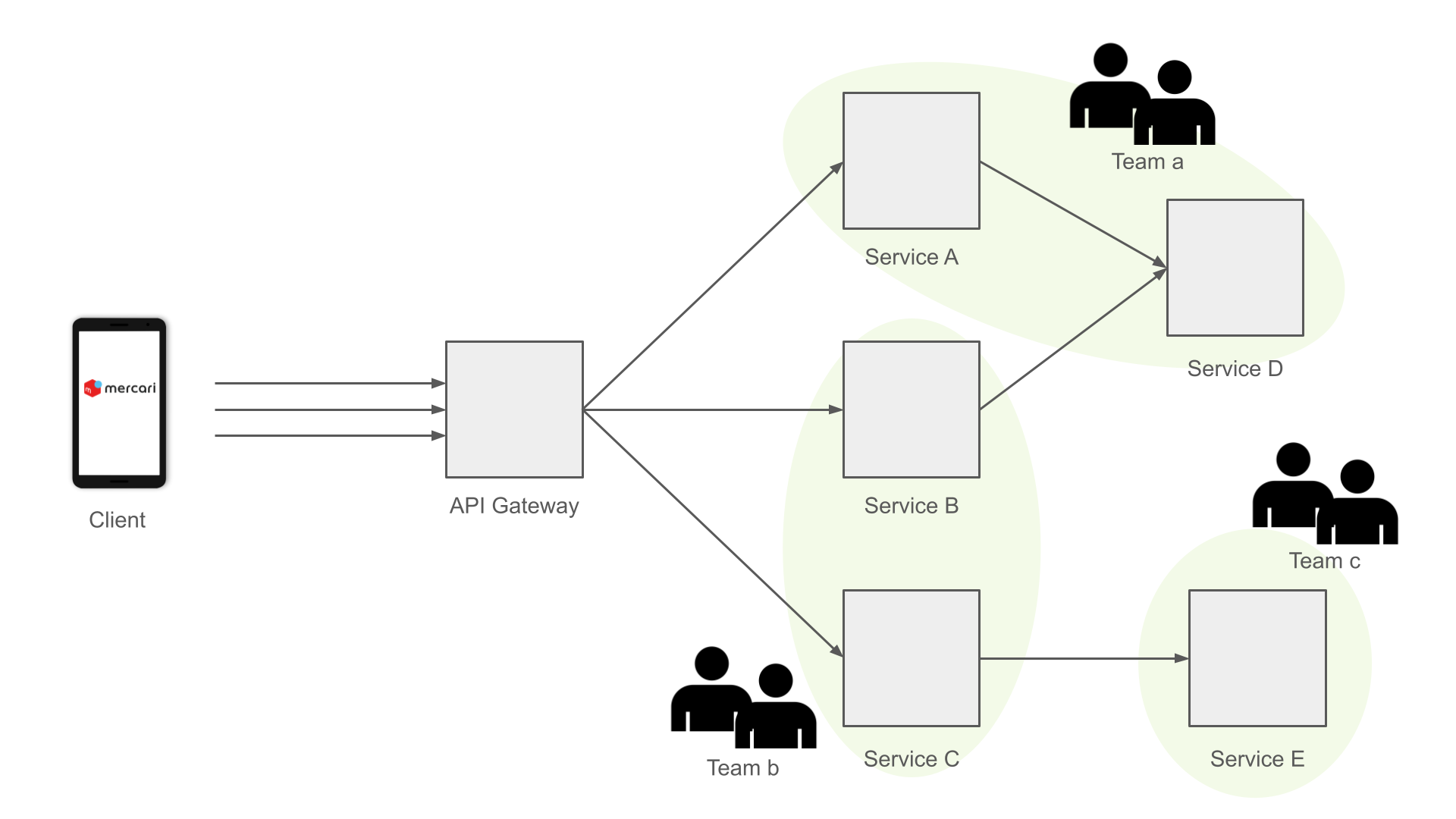
開発チームがマイクロサービスごとに独立した開発・運用を行う上で、サービスごとのSLOを定義することは必要なアプローチと言えます。一方でサービスごとのSLOだけではいくつかの課題があります。その一つが、お客さま視点でのメルカリというプロダクトの信頼性を評価することが難しいということです。
各マイクロサービスはあるドメインの機能のみを扱うサービスです。お客さまが自身のアカウントの”ユーザー情報を編集する”ようなドメインに閉じたシナリオを想定した場合、関係するサービスはユーザーサービスだけで済むでしょう。この場合、”ユーザー情報を編集する” SLOの達成度合いはユーザーサービスのそれを用いることができるかもしれません。一方で、”購入された商品を発送する”のようなシナリオの場合、関係するサービスは複数にわたります。この場合には各サービスの達成度合いを単純に用いることはできません。
さらに、あるシナリオを想定した場合に実際に使用されるAPIは各サービスのごく一部でしかありませんし、サービスの開発チームはどのAPIがどのシナリオ・ページで使用されているか完全に把握することも困難です(APIは基本的に汎用的なものを用意し各ページで同じものを使用します)。反対にフロントエンドの開発者も、どのサービスにアクセスするかを厳密に意識することは通常ありません。

以上の背景から、マイクロサービスごとのSLOだけでは”購入された商品を発送できるかどうか”のようなお客さまが実際に感じる信頼性を評価できません。例えば上記の例でサービスA/B/CそれぞれのAvailabilityはSLOを満たしていたとしても、お客さま目線でのAvailabilityは想定よりも低いということが考えられます。また、障害対応の観点から見てみると、あるサービスAのアラートがトリガーされても、実際のお客さまに対してどのような影響が出ているのかを判断することもできません。これは障害の優先度の判断や、影響したお客さまへの対応時に問題になります。
SREにおけるSLO
上記の課題を解決するため、SREでは以前よりマイクロサービスごとのSLO以外の独自のSLOとして、Critical User Journey (CUJ)に基づいた私たちのプロダクトであるフリマサービス全体のモニタリングを行ってきました(CUJとはお客さまがプロダクトを利用する際に頻繁に行われる一連のシナリオのうち特に重要なものを指します)。 一方で、以下のような課題もありました。
- 定義が不明瞭:
CUJの定義・CUJに関連するAPIの根拠などが記録されておらず、新たにCUJを追加することやメンテナンスが難しい - CUJに対して1対多のSLOが存在:
関連APIのSLOを直接モニタリングしているため、関連APIが複数の場合に複数のSLOが存在し、お客さまが感じる信頼性の評価が難しい - Updateが困難:
機能開発により関連APIは高頻度に変化し続けるが、人力での調査が必要なためメンテナンスコストが高く、最新の状態を維持できない - SLOが悪化した場合の挙動が不明:
課題1・2と関連してSLOが未達となった場合に、お客さまにどのような影響が出るのかが明確化されていないため、対応の優先度の意思決定やSRE以外が使用することが難しい
特に課題3から、2021年ごろに設定してから十分なメンテナンスをすることができず、モニタリング対象のAPIの過不足がある可能性がありました。また、SRE以外も有効に使用することでメルカリ全体の信頼性向上やインシデント対応の改善に繋げることも背景として1から再構築することを決めました。
User Journey SLOの概略
まず、課題1の”定義が不明瞭”な点と課題2の”CUJに対して1対多のSLOが存在”する点に関連して、User Journey SLOにおいてどのようにCUJを定義・管理したか、どのようなSevice Level Indicaor (SLI)を定義したかを紹介します。
Critical User Journey (CUJ)の定義
User Journey SLOではこれまでのCUJを踏襲し、粒度を商品出品・商品購入・商品検索のように定めました。具体的な各CUJについても再検討を行い、大小含めて約40のCUJを定義しました。課題1を改善するため、すべてのCUJを画面操作とそれによる画面遷移という形で定義し、以下のような遷移図としてドキュメント化しました。さらに、各画面でAvailableな状態も定義し、それを満たしている場合をそのCUJがAvailable・満たしていない場合はUnavailableとしました(基本的に各CUJのコア機能が提供できればAvailableとし、サジェストなど動作しなくてもコア機能に影響しないサブ機能の動作は無視することにしています)。

SLIの決定
課題2を改善するため、定義したCUJを基に、各CUJのAvailablityとLatencyのSLIがそれぞれ1対1になるようなSLIを定義します。SLIはあくまでObservebilityツールで取得可能なメトリクスなどを使用して測定する必要があります。メルカリではBFFなどを用いたお客さまの1操作 = 単一のAPIコールのような構成ではなく、基本的に1操作で複数のAPIコールが発生します。
CUJの各画面が成功したかどうか直接的に測定できれば良いですが、現在そのような仕組みを持っていません。新たな仕組みを導入し直接的な測定を行うことも考えられますが、約40のCUJを全てカバーしつつ、iOS・Android・Web全てのクライアントでアプリを改修することは、とてもエンジニアリングコストが高く現実的ではありません。また、APMツールのRealtime User Monitoring (RUM)から取得することも検討しましたが、サンプリングレートやコスト、実現性の観点から現時点ではこれも困難と判断しました。
そこで、CUJの間に実行されるAPIを関連するAPIとして、そのAPIの成功率などのメトリクスを使用します。ただし、各操作で発生するAPIコールの中には(1) 失敗したらCUJがUnavailableになるもの、(2)失敗してもCUJがAvailableになるものの2つに大別できます。User Journey SLOではSLIをより正確かつロバストなものにするため、(1)に該当するAPIのみを”クリティカルな API”と定義しSLIの計算に使用することにしました。

クリティカルなAPIのメトリクスを使用して、以下の式でCUJのAvailability・LatencyのSLIをそれぞれ一意に定まるように定義しました。
- Availability:
複数のクリティカルなAPIの成功率の乗算をCUJの成功率とする
クリティカルなAPI A,Bの成功率を SA, SB とするとCUJの成功率 SCUJ は以下で計算
SCUJ = SA × SB - Latency:
複数のクリティカルなAPIの目標レスポンスタイムの達成率のうち最も低い達成率をCUJの達成率とする
クリティカルなAPI A,Bの目標達成率を AA, AB とするとCUJの成功率 ACUJ は以下で計算
ACUJ = min(AA, AB)
クリティカルなAPIの抽出
上記をSLIとして使用するためには、各CUJごとにクリティカルなAPIを抽出する必要があります。コードの静的解析などの方法も考えられますが、現実的に実現できるか等を勘案した結果、実際のアプリケーションを用いる形で以下の手順で抽出を行いました。
- 開発アプリケーションと開発環境の中間にプロキシを設置した上でCUJに基いてアプリを実際に操作、実行されたAPIを記録
- プロキシで各APIのレスポンスが500エラーを返すように障害注入を設定してアプリを再度操作、CUJの基準を用いてAvailableかどうかを検証
※クライアントとしては、メルカリのクライアントとして最も使用されているiOS版メルカリを使用しました。

通常クライアントアプリ-サーバー間の通信は暗号化されています。今回は暗号化された状態でも通信の確認とレスポンスの書き換えが可能なプロキシを選定しました。Webインターフェースを通じたインタラクティブな操作ができること、アドオンを開発することで必要な機能を追加できる点から、OSSの mitmproxy を採用しました。
これらの取り組みにより障害検知はCUJとともに通知されるため、障害検知後の影響範囲の特定にかかる時間がゼロになり、対応優先度の決定を瞬時に行うことを実現します。
iOS E2E Testを用いた継続的最新化と可視化
次に、課題3である”Updateが困難”なことを改善するE2E Testを用いたクリティカルなAPIを最新に維持する方法と、課題4である”SLOが悪化した場合の挙動が不明”な点を改善する障害時のアプリの挙動を可視化する方法を紹介します。
自動化の必要性
メルカリのiOSアプリは1ヶ月に複数回リリースされています。また、トランクベース開発 によりフィーチャーフラグを使用してアプリのアップデートなしで新機能のリリースを行うことも可能です。これら全てのアプリの変更をSREが把握することは困難です。また、手動では高頻度のクリティカルなAPIの調査も困難です。結果として知らない間にクリティカルなAPIが変わり、必要なAPIをモニタリングできなかったり、不必要なAPIを過剰にモニタリングしてしまう事態につながります。そのため、アプリの変更に追従してクリティカルなAPIを定期的に更新するためには更新プロセスの自動化が必要です。
iOS E2E Testを用いた自動化
メルカリでは既にXCTestフレームワークを用いてiOSアプリのE2Eテストを自動化しています。この既存資産を活用してクリティカルなAPIの抽出を自動化することにしました。
具体的にはまず、XCTestでCUJをテストケースとしてシミュレータで実行可能とします。さらにこのテストケースに対して、CUJで定義したAvailableな状態かを検証するアサーションを追加します。これによりXCTestで実行したCUJがAvailableな状態だったかどうかを自動で判別可能な仕組みが整いました。また、テストケースはアプリと同じリポジトリでバージョン管理されます。
XCTestとは別に、前章で用いたプロキシに対して”プロキシで記録したAPIリストの取得”と”任意のAPIに対する障害注入”を操作API経由で実行可能にするアドオンを開発しました。このアドオンにより、XCTestのテストケースやスクリプトからプロキシの操作が可能になりました。

上記のXCTestの実行とアドオン経由でのプロキシの操作をスクリプト化することによって、前章で示したクリティカルなAPIの抽出を自動で実行します。同時に、実行されたAPIがクリティカルなAPIかどうかの結果と障害注入時のアプリのスクリーンショットをそれぞれBigQueryとGoogle Cloud Strage (GCS)に記録します。
BigQueryに記録したテスト結果はIDで管理し前回実行時との差分を比較できるようになっています。また、APMに作成するSLO・Monitor・Dashboardの定義はUser Journey SLO用に開発したTerraform moduleを用いて行います。これによりクリティカルなAPIを定義するだけで、差分の適用や新しいCUJの追加を行うことが可能になりました。
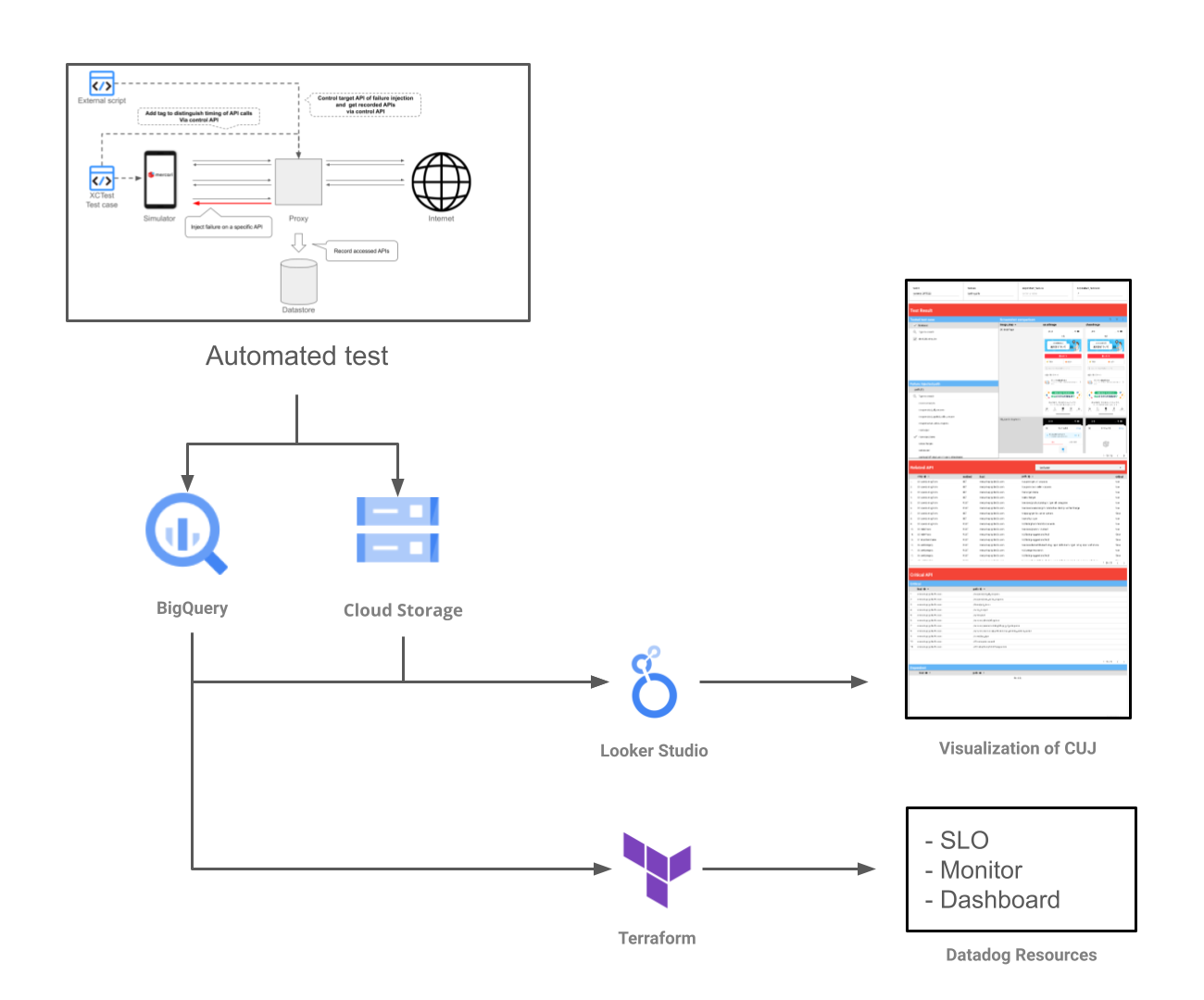
上記の自動化により以下を実現しました。
- コードメンテナンス以外の作業をほぼ全て自動化
- テストケースとアプリの変更を同一のリポジトリでバージョン管理
- テスト結果をID管理し差分を効率的にAPMに反映
最終的なテストケース数は約40のCUJに対して約60となりました。手動実行では困難な数のテストケースを自動化により効率的に運用することに成功しました。また、約60のテストケースを手動で実行してSLOのメンテナンスを行った場合に比べて、自動化によりメンテナンスにかかる時間を99%削減しました。
ダッシュボードによる結果の可視化
User Journey SLOの最終的に目指す姿の一つは、SRE以外も障害対応やお客さま対応で使用できるようにすることです。そのためには、最新のクリティカルAPIや障害発生時のCUJの挙動を誰もがアクセスできる形とすることが必要です。そこで、Looker Studioでこれらの結果を可視化し、各CUJのAPIコール一覧、APIの障害発生時にアプリのどの画面で失敗するかをスクリーンショットで可視化しました。

現状と今後
前章までの活動でUser Jouney SLOに対して以下を実現しました。
- CUJの定義の明確化
- 各CUJに対して1対1となるSLIの定義
- 各CUJとSLOのメンテナンスの自動化
- 障害時の各CUJの挙動のダッシュボードによる可視化
その結果として、約40のCUJと約60のテストケースに対してSLOの運用を行っています。現状はSRE内で試験活用中の段階です。現時点でも新しいSLOの導入により、以下の項目の向上を体感しています。
- 障害発生検知の速度・精度
- 障害影響範囲把握の精度
- 障害原因特定の速度
- 品質可視化の精度
数値的には以下の効果を実現しました。
- 障害検知後の影響範囲の特定にかかる時間がゼロ
- SLOのメンテナンスにかかる時間を99%削減
この現状を踏まえて今後はSRE以外での活用を進め、以下の取り組みを行っていく予定です。
- 社内の障害基準としての活用
- お客さま対応での活用
おわりに
本記事ではメルカリのCUJに基づいたSLO運用について、SLI・SLOの詳細やiOS E2E Testを使用した継続的な最新化の取り組みについて紹介しました。SLI・SLOの運用に取り組む方々に何かの参考になれば幸いです。
明日の記事は….rina….さんです。引き続きお楽しみください。




