
こんにちは、メルカリのAI/LLMチームで機械学習エンジニアをしているarr0wとshoです!
本テックブログでは、Vision-Language Modelの一つであるSigLIP [1]を、メルカリの商品データ(Image-Text Pairs)でファインチューニングし、メルカリの商品画像Embeddingの性能を大幅に改善したプロジェクトについて紹介します。
今回作成したSigLIPの性能を評価するために、商品詳細ページの「見た目が近い商品」のレコメンド機能でA/Bテストを実施しました。

この「見た目が近い商品」のレコメンド機能は、社内ではSimilar Looksと呼ばれています。作成したモデルをSimilar Looksの類似画像検索に適用し、既存モデルとの比較のためのA/Bテストを行いました。
そして、その結果として、主要なKPIにおいて以下のような顕著な改善が確認できました。
- 「見た目が近い商品」のタップ率が1.5倍に増加
- 商品詳細ページ経由の購入数が+14%増加
A/Bテストを経て、モデルの有効性が確認できたため、今回作成したモデルによるレコメンドは無事採用され、100%リリースに至りました。以降の章では、商品データを用いたSigLIPのファインチューニングやそのオフライン評価、本番デプロイのためのシステム設計など、本プロジェクトの技術的詳細について説明していきます。
商品データを用いたSigLIPのファインチューニング
画像Embedding
画像Embeddingは、画像内の物体やその色、種類といった特徴を数値ベクトルとして表現する技術の総称です。近年、推薦や検索など、さまざまなアプリケーションで使用されています。
メルカリ内でもその重要性は日々増しており、類似商品レコメンド、商品検索、不正出品の検出といった多様な文脈で画像Embeddingが使用されています。
本プロジェクトにてメルカリのAI/LLMチームでは、Vision-Language ModelであるSigLIPを用いて、商品画像のEmbeddingを改善する取り組みを行いました。
SigLIP
近年、CLIP [3]やALIGN [4]などのように、大規模かつノイズの多い画像およびテキストがペアになったデータセット(e.g. WebLI [5])を用いたContrasive Learningで事前学習されたモデルは、ゼロショット分類や検索といった様々なタスクにおいて高い性能を発揮していることが知られています。
SigLIPは、ICCV 2023で発表された論文で紹介されたVision-Language Modelです。SigLIPは、CLIPで使用されている従来のSoftmax Lossを、Sigmoid Lossに置き換えて事前学習を実施しています。この変更はLossの計算方法を変えるだけのシンプルなものですが、著者たちは、ImageNet [6]を使用した画像分類タスクを含む複数のベンチマークで、SigLIPは既存手法と比べてパフォーマンスが大幅に向上したと報告しています。
それでは、ここで、後述するメルカリの商品データを用いたSigLIPのファインチューニングのために実装したLoss関数の実装を見てみましょう。
def sigmoid_loss(
image_embeds: torch.Tensor,
text_embeds: torch.Tensor,
temperature: torch.Tensor,
bias: torch.Tensor,
device: torch.device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
):
logits = image_embeds @ text_embeds.T * temperature + bias
num_logits = logits.shape[1]
batch_size = image_embeds.shape[0]
labels = -torch.ones(
(num_logits, num_logits), device=device, dtype=image_embeds.dtype
)
labels = 2 * torch.eye(num_logits, device=device, dtype=image_embeds.dtype) + labels
loss = -F.logsigmoid(labels * logits).sum() / batch_size
return lossなお、今回のプロジェクトでは、SigLIPのベースモデルとしてgoogle/siglip-base-patch16-256-multilingualを使用しました。このモデルは多言語のWebLIデータセットで訓練されており、対応言語にメルカリのサービスで主に使用されている日本語も含まれているためです。
商品データを用いたファインチューニング
この章から、メルカリの実データを用いたSigLIPのファインチューニングの実験環境および設定について紹介します。
今回の実験では、過去に出品された商品から、ランダムに抽出した約100万件のメルカリの商品データを使用して、SigLIPのファインチューニングを実施しました。SigLIPへの入力データは、商品タイトル(Text)と商品画像(Image)を用いました。これらはいずれもメルカリ上のお客さまが出品時に作成したものです。
訓練用のコードはPyTorchとTransformersライブラリを使用して実装しました。さらに、今回は使用したデータセットは、Google Cloud Storage上で管理しており、その規模も大きかったため、データ読み込みプロセスを最適化するためにWebDatasetを活用し、大量の学習データを効率的に扱えるようにしました。なお、WebDatasetの理解には公式ドキュメントに加え、こちらの記事が大変参考になりました。
モデルの訓練は1台のL4 GPUを使用して実施しました。訓練パイプラインの構築には、Vertex AI Custom Trainingを活用しています。さらに、メルカリは、Weights & Biases(wandb)のエンタープライズ版を契約しているため、実験のモニタリングには、そちらを活用しました。プロジェクトのタイムライン上、ML実験に割くことができる期間には制約がありましたが、初期にこれらの訓練パイプラインに投資をしたことで、結果として試行錯誤の回数を増やすことができたように感じています。
オフライン評価
A/Bテストを実施する前に、既存の「見た目が近い商品」レコメンドのユーザの行動ログを使用してオフライン評価を行いました。Similar Looksは、元々、学習済みのMobileNet [2](google/mobilenet_v2_1.4_224)から得られるImage EmbeddingをPCAで128次元に圧縮したEmbeddingを用いていました。オフライン評価では、10000件の行動ログ(セッション)を利用しました。
行動ログの具体例を以下に示します。query_item_idに商品詳細ページに表示されているクエリ画像となる商品のID、similar_item_idに「見た目が近い商品」セクションに表示された商品のID、clickedにその商品を見たかどうかのフラグが格納されています。
session_id | query_item_id | similar_item_id | clicked |
----------------|----------------|-----------------|---------|
0003e191… | m826773… | m634631… | 0 |
0003e191… | m826773… | m659824… | 1 |
0003e191… | m826773… | m742172… | 1 |
0003e191… | m826773… | m839148… | 0 |
0003e191… | m826773… | m758586… | 0 |
0003e191… | m826773… | m808515… | 1 |
...評価は画像検索タスクとして定式化し、ユーザーのクリックを正例(label:1)として扱いました。パフォーマンスの評価には、nDCG@k(k=5)とprecision@k(k=1,3)を評価指標として使用しました。
これにより、ユーザーの嗜好に合致した形で類似した画像をランク付けするモデルの能力を定量的に評価することができました。
評価にあたっては、比較のために「ランダム推薦」と「現在使われているMobileNetベースの画像検索」2つのベースラインとしました。
以下がオフライン評価の結果になります。
| 手法 | nDCG@5 | Precision@1 | Precision@3 |
|---|---|---|---|
| Random | 0.525 | 0.256 | 0.501 |
| MobileNet | 0.607 | 0.356 | 0.601 |
| SigLIP + PCA | 0.647 | 0.406 | 0.658 |
| SigLIP | 0.662 | 0.412 | 0.660 |
評価結果から、メルカリの商品データでファインチューニングしたSigLIPのImage Encoderから得られた画像Embeddingによる画像検索は、PCAによって768次元から128次元に圧縮された場合でも、MobileNetベースの画像検索を一貫して上回るということがわかりました。これは、あくまでオフライン評価上は「見た目が近い商品」のレコメンドにおいて、我々が構築したSigLIPモデルが優れたパフォーマンスを示したと言えます。
定量評価だけでなく、目視による定性評価も実施しました。約10万件の商品画像のEmbeddingが格納されたベクターストアをFAISSを用いて作成し、複数の商品で画像検索を行った結果を、以下のようにスプレッドシートにまとめ、目視でチェックしました。

以上のオフライン評価結果から、メルカリの商品データでファインチューニングしたSigLIPのImage Encoderを用いた「見た目が近い商品」レコメンドは、定量的・定性的どちらにも既存のモデルを上回ることが明確に示されました。そのため、作成したモデルを使用してA/Bテストを実施することを決定しました。
次の章では、このモデルを本番環境にデプロイするためのシステム設計について説明します。
システム構成
End-to-End Architecture
個々のコンポーネントの詳細に入る前に、アーキテクチャの全体像を以下に示します:
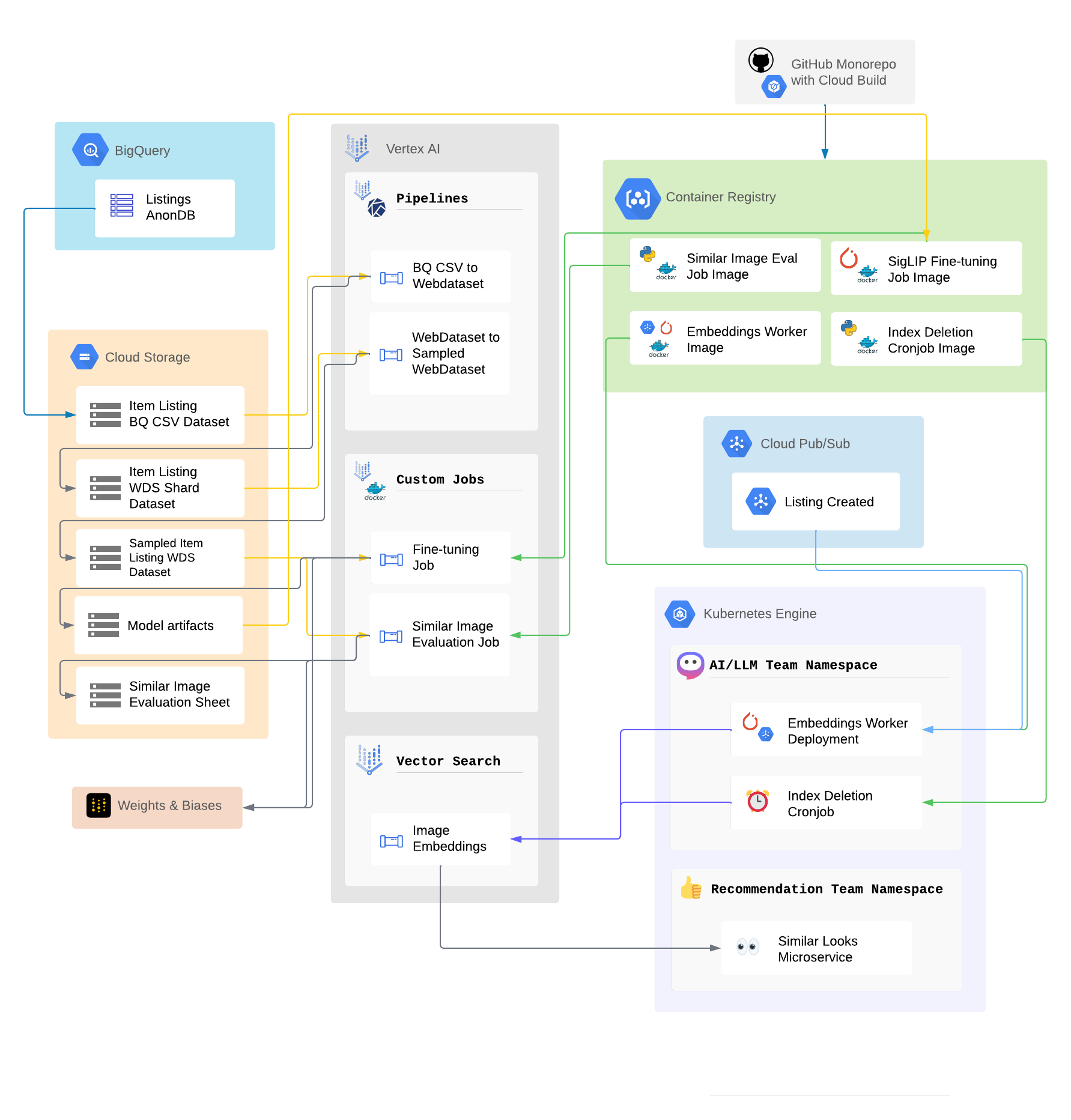
上図では、メルカリ本体のプラットフォームからSigLIPモデルがホスティングされたマイクロサービスへのデータの流れと、Embeddingがどのように効率的に保存され、取得されるかを示しています。これは初期バージョンですが、このモジュール化された設計により、スケーラビリティと柔軟性を確保しています。
Google Container Registry
モデルのデプロイはGoogle Container Registry(GCR)を通じて管理され、マイクロサービスのDockerイメージがここに保存されています。Dockerイメージは、GitHubリポジトリからGoogle Cloud Buildを使用したCI/CDパイプラインを介して、継続的にビルドされGCRにプッシュされます。
GCRを活用することで、Google Kubernetes Engine(GKE)上のデプロイメントが常に最新のコードバージョンに基づいて行われ、本番環境で稼働しているサービスへのシームレスなアップデートを実現しています。
Google Pub/Sub
リアルタイムのデータストリームを処理するために、Google Pub/Subを利用しています。メルカリでは、お客さまによって新しく出品が作成されると、新規出品用ののPub/Subのtopicに、Pub/Sub メッセージがpublishされます。推薦や検索をはじめとする関連マイクロサービスがこのtopicをsubscribeすることで、新しい出品に対して、動的に対応できるシステムを実現しています。
今回も同様に、新規出品により発火するEventをSubscribeするWorkerを定義しました(Embedding Worker)。これにより、新しい出品が発生したら、Embeddings Workerが起動します。そこで、新規商品の画像Embeddingを算出し、ベクターデータベースに追加します。この非同期なシステムにより、メルカリの出品量に応じて効果的にスケールすることが可能になっています。
Google Kubernetes Engine
システムを構成する主要なマイクロサービスはGoogle Kubernetes Engine(GKE)でデプロイされています。GKEは、本取り組みのアーキテクチャにおける以下の主要サービスをホストしています:
Embeddings Worker
Embeddings Workerは、Pub/Subの新規出品トピックをSubscribeする重要なサービスです。新規出品の発生ごとに、以下の処理を行います:
- 出品された商品に対応する画像をストレージから取得
- ファインチューニングしたSigLIPモデルを使用して、画像をEmbeddingに変換
- 類似度検索のレイテンシ改善とストレージコスト削減のため、PCAにより次元を削減(768 dim → 128 dim)
- EmbeddingをVertex AI Vector Searchに保存
このプロセスにより、効率的な類似画像検索が可能になります。各Embeddingは画像の視覚的内容を表現しているため、メルカリのプラットフォーム全体で視覚的に類似した出品を容易に比較・検索することができます。
Index Cleanup Cron Job
メルカリでは多くのお客さまに利用されており、頻繁に新しい商品が出品され、既存の出品が売れたり、削除されたりします。
そのため、現在出品中の商品のみを表示し「見た目が近い商品」レコメンドの体験を向上するために、削除あるいは売却済みとなった商品を適宜Vector Storeから削除し、最新の状態に保つ必要がありました。これを実現するために、Index Cleanup Cron Jobを実装しました。
Cronで定期実行されるこのジョブは、Vertex AI Vector Searchから古くなった出品や売却済みの出品に対応するEmbeddingを削除します。
現在はこのBatchで定期実行する方針で体験を大きく損ねず動作していますが、さらなる効率化を図るため、Embedding管理のリアルタイム更新についても、現在検討しています。
Similar Looks Microservice & Caching
Similar Looks Microserviceは、画像類似性機能の中核となるものです。このサービスは、商品IDを入力として受け取り、対応する画像EmbeddingをVertex AI Vector Searchから取得し、最近傍探索を実行してマーケットプレイス内の類似商品を見つけます。
レイテンシを削減するために、このマイクロサービスにもキャッシュ機構を実装しています。これにより、お客さまが類似商品を閲覧する際に素早いレスポンスを提供し、スムーズなユーザー体験を確保しています。
Vertex AI Vector Search
Embeddingの保存と検索には、Vertex AI Vector Searchを使用しています。これはスケーラブルなVector Databaseで、類似したEmbeddingを効率的に検索することができます。メルカリ内の各商品画像は、SigLIPにより、ベクトルに変換され、そのベクトルはVertex AI内で商品IDごとに索引されます。
Vertex AIの最近傍探索アルゴリズムは非常に高速であり、データベース内に数千万件程度の膨大なEmbeddingがある場合でも、視覚的に類似した商品を高速に検索することが可能です。
TensorRTを用いたモデルの最適化
ファインチューニングしたSigLIPモデルのパフォーマンスを最適化し、毎秒生成される大量の出品を高速に処理するため、モデルをPyTorchからNVIDIAの高性能深層学習推論ライブラリであるTensorRTに変換しました。この変換により、推論時間が約5倍高速化されました。
TensorRTについて
TensorRTはニューラルネットワーク内の操作を、NVIDIA GPU上で効率的に推論できるように、最適化された行列演算のシーケンスに変換します。具体的には、性能を保った上でのモデルの重みのFP16やINT8といった少ない桁数への変換(Precision Calibration)や深層学習モデルを構成する層の融合(Layer Fusion)などの処理を行います。
SigLIPのような大規模モデルをメルカリのような高RPSなサービスにリリースする上で、この改善は非常に重要でした。毎秒大量の商品が出品される中、推論時間を数百ミリ秒から数十ミリ秒程度に削減できたことで、新規出品のほぼすべての商品画像を瞬時にベクトル化し、Similar Looks Componentsが使用するVertex AI Vector Searchのインデックスに登録できるようになりました。
Next Steps
現在のアーキテクチャは安定しており、スケーラブルですが、私たちは以下のような改善点があると考えており、日々開発に取り組んでいます。
Vector Storeのリアルタイム更新
既に述べたとおり、現在、Index Cleanup Cron Jobが定期的にVertex AI Vector Searchから古くなったEmbeddingを削除しています。しかし、商品が削除されたり売却されたりした時点で即座にEmbeddingを更新するような、よりリアルタイムな方法への移行を計画しています。これにより、Cron Jobによる削除の必要性がなくなり、インデックスが常に最新の状態に保たれることが保証されます。
Triton Inference Server
モデル推論をより効率的に処理するため、Triton Inference Serverの使用も検討しています。Tritonは、異なるフレームワーク(例:TensorRT、PyTorch、TensorFlow)の複数のモデルを単一の環境にデプロイすることができます。推論処理をEmbeddings WorkerからTritonに移行することで、モデルの実行をワーカーのロジックから分離し、推論パフォーマンスのスケーリングと最適化においてより大きな柔軟性を得ることができます。
SigLIPモデルを活用した新機能
最後に、ファインチューニングしたSigLIPモデルを活用した新機能の開発に取り組んでいます。「見た目が近い商品」のレコメンドに限らず、開発したSigLIPモデルはたくさんの可能性を秘めていると我々は考えています。このモデルを活用したユーザー体験を向上させる計画は、他にもあるので、今後のメルカリのアップデートにご期待ください 😉
おわりに
今回、メルカリが自社で保有する商品データを用いて、Vision-Language ModelのSigLIPをファインチューニングし、高性能なImage Embedding Modelを構築し、「見た目が近い商品」機能の改善を行いました。
オフライン評価において、ファインチューニングしたSigLIPによる「見た目が近い商品」レコメンドは既存のモデルよりも高い性能を示しました。そのため、A/Bテストを実施したところ、ビジネスKPIにおいても大幅な改善が確認されました。
本ブログの内容がVision-Language Modelのファインチューニングや評価、深層学習モデルの実サービスへのデプロイ等に興味がある皆さまのお役に立てば幸いです。
メルカリでは、プロダクト改善を通して大きなインパクトを生み出すことに意欲的なSoftware Engineerを募集しています。興味ある方は是非ご応募ください。
参考文献
[1] Sigmoid Loss for Language Image Pre-Training, 2023
[2] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications, 2017
[3] Learning Transferable Visual Models From Natural Language Supervision, 2021
[4] Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision, 2021
[5] PaLI: A Jointly-Scaled Multilingual Language-Image Model, 2022
[6] ImageNet: A Large-Scale Hierarchical Image Database, 2009




