
Merpay & Mercoin Tech Fest 2023 は、事業との関わりから技術への興味を深め、プロダクトやサービスを支えるエンジニアリングを知ることができるお祭りで、2023年8月22日(火)からの3日間、開催しました。セッションでは、事業を支える組織・技術・課題などへの試行錯誤やアプローチを紹介していきました。
この記事は、「発生可能な取引の属性データを用いた素早い不正検知」の書き起こしです。
@Liu:みなさん、こんにちは。本日のプレゼンテーションにお越しいただきましてありがとうございます。

本題に入る前に、簡単に自己紹介をさせてください。私は2019年10月に機械学習エンジニアとしてメルカリに入社し、不正防止システムの開発に関わっています。

@Li:私は@Liです。私は2017年4月にヤフー株式会社に入社し、ソフトウェアエンジニアとして働いていました。2019年1月からは機械学習エンジニアに軸足を移し、2021年9月にはメルカリに入社しました。現在は機械学習プラットフォームの構築に関わり、最近ではFeature StoreやGraphDBなどの技術開発に取り組んでいます。

@Liu:ここでは、不正防止モデルとテクニックをご紹介しております。関心がある方はブログの記事をご覧ください。
参考記事
不正検知システムに機械学習を導入してコストマネジメントを実現した話
ML technique used to detect ChargeBack in Merpay
つながりをデータから解き明かしたい ~ 複雑ネットワークの世界とそれを活用した不正検知の紹介

そしてここにいくつかの過去のイベントがございます。
参考資料
Using Feature Store and Vertex Pipelines in Fraud Prevention System
Feature StoreとVertex AIを使った機械学習基盤の実現
グラフ理論と不正対策〜つながりをデータから解き明かしたい

それではプレゼンテーションの主要なポイントに注目をしたいと思います。主に5つをカバーします。

まず最初に背景について説明します。私たちの不正検知の戦略は、大きく二つに分けられます。事後検知と即時検知です。
事後の検知とは、不正な取引が行われた後に発覚し、商品の配送を停止するなどの措置を取り、不正の被害を防止することです。すでに配送完了とされている商品もあるため、不正を見逃す可能性があると言われています。
一方、即時検知は取引の進行中に検知する方法であり、不正行為が発生した場合には素早く対処することができます。応答時間は0.1秒の場合もあります。

即時の不正検知を実現するためには二つの重要な要素があります。
まず、TnSのバックエンドチームが提供するJudgeサービスがあります。このサービスは超高速な不正防止システムであり、低遅延の設計がなされています。
次に、機械学習チームが開発した不正関連の機械学習ソリューションがあります。このソリューションは、潜在的なリスクランクを1分から1日の単位で算出し、Judgeサービスに提供します。機械学習ソリューションとJudgeサービスの不正防止システムを組み合わせることで、私たちはさまざまな不正取引をニアリアルタイム(Near-Realtime)で検知し、防止することが可能になります。
参考記事:「0.1秒でも遅ければ、お客さまを守れない」不正検知領域に挑むメルペイのエンジニアが日々感じる“奥深さ

このような背景を踏まえて2つ目のアジェンダに移りたいと思います。

これは不正検知をニアリアルタイムに加速するためのメカニズムです。取引が完了する前に潜在的な取引のリスクランクを算出し、提供することで、プロアクティブなアプローチで不正リスクを低減することができます。

これを実現するための鍵は、取引が発生したり完了したりする前に存在している属性データを活用することです。
このデータには、アイテム情報や、セラー情報、バイヤー情報などの重要な詳細が含まれています。これらの情報は、潜在的な取引のリスクを評価するために必要です。このデータを分析することで、不正取引の可能性を予測し、事前に対策をとることができます。
これによって私たちの不正検知システムをプロアクティブで効率的に改善しています。そして全てのお客さまに安全な体験を提供することを保証しています。

私たちの仕組みは主に3つのステップで構成されています。まず、機械学習モデルを活用して、属性データに基づいて潜在的な取引のリスクランクを計算します。その後、潜在的なリスクランクは計算が完了するとJudgeサービスに送られ、不正判定に使われます。

Judgeサービスは、継続的に進行中の取引をリアルタイムでチェックし、送られたリスクランクを使って潜在的な不正取引を特定します。このプロセスにより、私たちは不正取引が被害をもたらす前に発見し防止できるようになります。

私たちのMLソリューションでは、元々バッチ予測を行いましたが、この方法には一つの課題がありました。バッチ予測する前に取引が終了してしまった場合、検知が取引の終了後になり、防止対策に手遅れが生じる可能性があります。

この課題を解決するためには、取引が終了する前に潜在的なリスクランクを計算し、Judgeサービスに送信する必要があります。つまり、既存のバッチ予測では手遅れになる取引を検知するために、不正検知プロセスを加速する必要がありました。それには、バッチ予測よりも早い検知方法が必要でした。

不正検知プロセスを加速するために、私たちは既存のバッチソリューションにストリームソリューションを導入して、ニアリアルタイムの検知を実現しました。この新しいソリューションでは、Feast Online StoreとStream予測システムを作り、利用しています。これによってデータ処理と予測をニアリアルタイムで行い、より効率良く不正検知を行うことができます。

プレゼンテーションの三つ目の要素・システムアーキテクチャに進みたいと思います。

システムアーキテクチャは、さまざまなコンポーネントを統合し、スムーズで効率的な検知プロセスを保証しています。
アーキテクチャは、四つのパートで作られております。

まず、Feature Storeですが、これについては次のパートで@Liから紹介されます。そして次がバッチシステムで、Vertex Pipelinesを使用して実行されています。ストリームシステムではマイクロサービスを活用して、ニアリアルタイムの処理を行っております。
そして、Publish APIを使って最終的な計算結果をJudgeサービスに送ります。このアーキテクチャにより私たちは潜在的な取引のリスクランクを予測・計算し、提供することができます。

バッチシステムは、大規模なデータ処理やモデル予測する上で重要な役割を担っており、膨大な過去データをもとに効率的にリスクを計算することができます。

バッチの実行管理はCloud Schedulerによって行われています。これにより1日または1時間単位で予測をスケジュールし、トリガーすることができます。また、データ処理とモデル予測にはVertex Pipelinesが使用されています。
データは、SpannerとBigQuery上で保存・管理されています。

次がStream Systemです。

Stream Systemは、3つのマイクロサービスから成り立ちます。まず、複数のサブスクライバーを持つワークロードサービスです。次に、特徴量の取得と挿入を担当するAPIサービスであるFeature Serverがあります。そして最後に、ML予測やロジック処理を行うサービスがあります。特徴量データと予測結果などはSpannerを用いて保存と管理がされています。

こちらはマイクロサービスが連携・動作しているフローを示したシーケンス図です。

Publish APIは、潜在的なリスクランクの計算結果をJudgeサービスに送信する役割を担っています。Outboxに保存されているリスクランク情報は、Publish APIにリクエストしてPublishします。

こちらはOutboxに格納されているデータフォーマットです。中には、Pub/Subに必要な情報が含まれています。また、Publishされたかどうかを判定するフラグ情報や、「この時間までレコードを送信しないように」指示するschedule TIMESTAMPも含まれています。

Publish APIは、Cloud Runにデプロイされ、以下のように使われています。
Publish APIは計算された潜在的なリスクランクをPub/SubのMessageとしてJudgeサービスに送信します。
バッチシステムからの計算結果は、Outboxに定期的に蓄積されます。Cloud schedulerは1分ごとにPublish APIがJudgeサービスに対してOutboxのデータをPublishするようトリガーします。Stream Systemの計算結果は、専用のPub/SubからPublishされます。Publish APIは送られた計算結果をSubscribeし、JudgeサービスにPublishします。

こちらでは、Public APIの仕組みを示しています。興味のある方はぜひご覧ください。
私からのメッセージは以上になります。ありがとうございました。

@Li:それでは、続いてFeature Storeについて説明します。

Feature Store (FEAST) は主にデータの入力部分を担当しています。特徴量テーブルの管理やモデルのトレーニング、予測に必要なデータを提供します。データはBigQueryとSpannerに保存されており、モデルのトレーニングやバッチ予測用のデータはOffline Store (BigQuery)から、オンライン予測用のデータはOnline Store (Spanner)から提供されます。

先ほど不正検知のためのストリーム予測が紹介されましたが、ニアリアルタイムでの不正検知を実現するためには、推論だけでなく、特徴量の取得もニアリアルタイムかつ低遅延で提供する必要があります。そのために、私たちはFeast Online Storeを導入しました。

まず、Feature Storeがどのような役割を果たすのか、簡単に紹介させてください。
この図は、Feature Storeのない典型的なMLインフラの一部を示しています。Feature Storeがないと、データソースへの接続やデータ処理のコードなど、同じコードが複数のトレーニングジョブ間で重複してしまい、冗長になります。また、特徴量の処理フローはトレーニングとサービングのプロセスに埋め込まれているため、特徴量の再利用が容易ではありません。
そのため、データサイエンティストはモデルを構築する際、データストアにアクセスするための低レベなコードを書く必要があり、データエンジニアリングのスキルが求められます。
参照:https://www.hopsworks.ai/post/feature-store-the-missing-data-layer-in-ml-pipelines

この図は、Feature Store導入後の概要を示しています。Feature Storeを使用することで、データソースとモデルの間の特徴量を一元的に管理し、全ての特徴量を一箇所に保存・管理し、異なるモデル間で再利用することができます。
データサイエンティストは簡単に特徴量を検索し、それらを使用してモデルを構築することができます。一方、MLエンジニアはモデルの管理に集中することができ、データエンジニアは特徴量の作成と管理に専念することができます。効果的な役割分担が可能となり、生産性が向上します。

Feature Storeの中には、Online StoreとOffline Storeという2つのコンポーネントがあります。これらは主に異なる目的で使用されます。
Online Storeは、オンライン予測時に特徴量を提供するために使用されます。対象の最新特徴量のみを保存し、低遅延のアクセスを可能にすることで、特徴量値の迅速な取得を最適化しています。
一方、Offline Storeは大量の過去データを保存・管理することに特化しており、バッチ予測やモデルトレーニングジョブに活用されます。
これらの2つのコンポーネントは、効率的かつ効果的な特徴管理を提供するために協力して動作します。

Feature Storeのアーキテクチャはこちらのようになります。
データ自体は、BigQueryやSpannerなどのデータストレージに格納されています。Feature Storeは、中間層として機能し、特徴量へのアクセスを簡単かつ整理された形で提供します。
まず、Online Storeを見てみましょう。
Online Storeには、2つの異なるデータ収集方法があります。1つ目は、Kafkaから流れてきたデータをFlinkが処理し、処理済みのデータがFeature Server APIを介してOnline Storeに取り込まれる方法です。2つ目は、Offline StoreからデータをOnline Storeにマテリアライズする方法です。
なぜなら、一部の特徴量はリアルタイムではなく、直接的にKafkaから取得することができないため、Offline Storeからデータを取得して必要な特徴量セットを揃え、予測時に提供する必要があるからです。マテリアライズジョブはCloud Schedulerからトリガーされます。
Offline Storeに関しては、データ変換ツールであるdbtを使用して特徴量テーブルが作成および管理されます。

先程、Online Storeへのデータ取り込み方法について2つ存在すると話しましたが、ではいったいどの特徴量はマテリアライズし、どの特徴量をストリームで取り込むべきでしょうか。
基本的には、リアルタイムで取得可能な特徴量はストリームで取り込み、処理するべきです。一方で、集計された特徴量などのリアルタイムではない特徴量は、Offline Storeからマテリアライズするのが適しています。
もちろん、すべての特徴量をOnline Storeにマテリアライズすることも可能です。その場合、モデルのパフォーマンスは基本的にバッチ予測と同様になります。
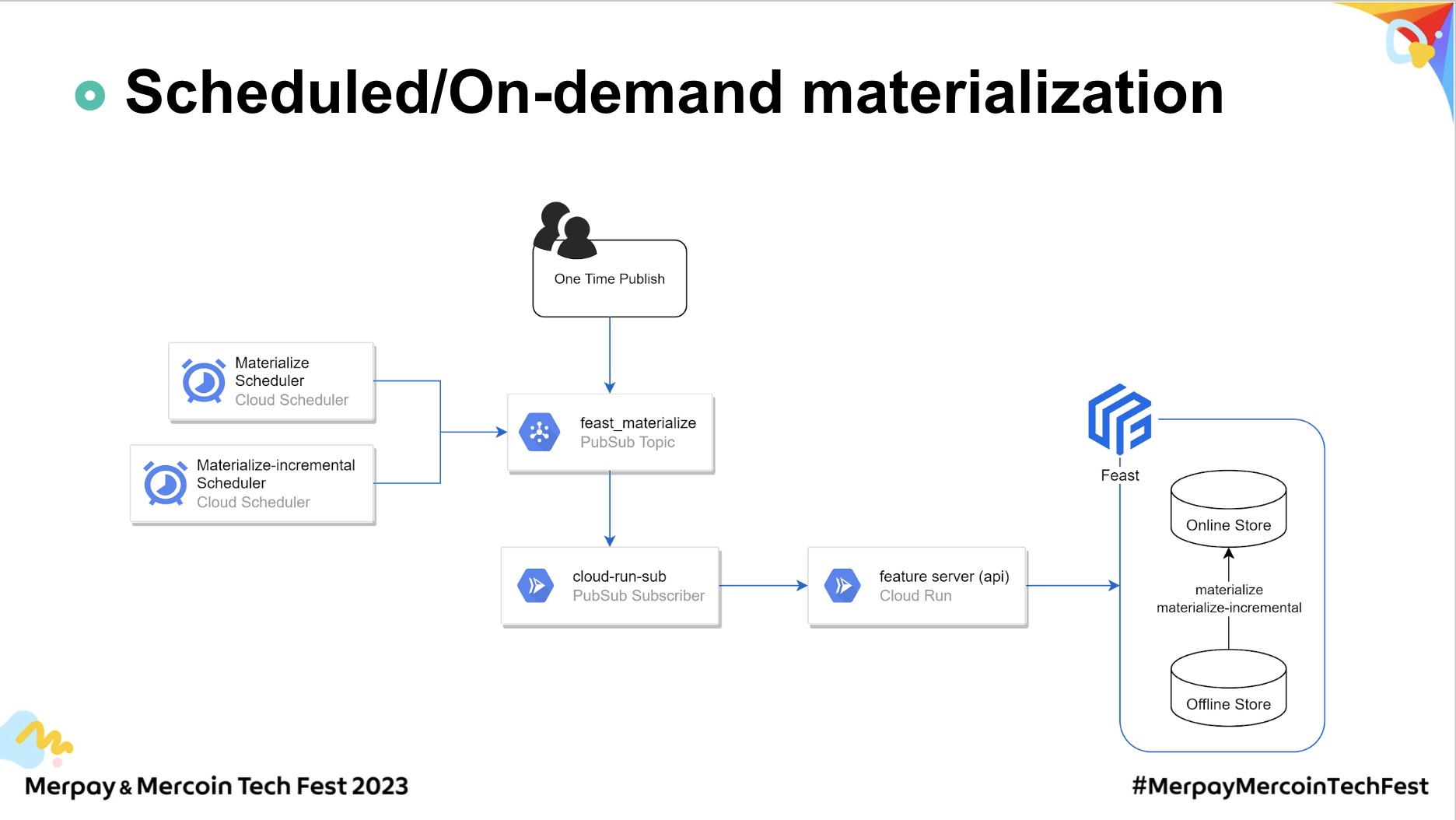
マテリアライズジョブの実行方法には、定期実行とオンデマンド実行の2つがあります。
定期実行では、主にCloud Schedulerがトリガーとして活用されます。Cloud SchedulerはPub/Sub経由でマテリアライズジョブに関する設定情報を送信します。それにより、サブスクライバーAPIがメッセージを受け取り、Feature Serverにジョブの開始をリクエストします。
一方、オンデマンド実行では、マテリアライズジョブ情報を含むメッセージを直接Pub/Subに送信します。その後の流れは定期実行と同様です。
このときのPubSubは、マテリアライズジョブに関するすべてのリクエストを受け入れるハブとして機能しています。
最後に話したいもう一つのポイントは、Online StoreとOffline Storeの間でFeatureViewを管理する方法です。

FeatureViewは、特徴量データをコンテナのように保持し、エンティティに関連する特徴量の論理的なグループを表現しています。
Offline Storeには"M"という名前のFeature Viewがあり、リアルタイムの特徴量Aと非リアルタイムの特徴量Bを含んでいると仮定しましょう。
予測のために、Online Storeにもデータを持たせたい場合、どのようにOnline Storeにデータを取り込むかを選択する必要があります。

ここでの問題は、特徴量AはKafkaから取得できますが、特徴量Bはマテリアライズジョブを介してOffline Storeからのみ取り込むことができるということです。
異なる方法で同じFeatureViewにデータを取り込むと、データ上書きが発生し、新しいデータが古いデータに上書きされてしまう可能性があります。

この図は、2つの方法を使用して同じFeatureViewにデータを取り込む場合に何が起こるかを示しています。
Kafkaからの取り込みとマテリアライズジョブの両方がFeatureView単位でデータの挿入を行うため、同じFeatureView内ではストリームで取り込まれた最新の特徴量が、マテリアライズジョブで取り込まれた1時間前の特徴量に上書きされる可能性があります。
もちろん、Offline Storeからすべての特徴量をマテリアライズして上書きを防ぐこともできますが、ストリーム取り込みはニアリアルタイムで行われるため、最大限活用したいと考えています。

解決策は非常にシンプルです。それは、Online Storeで取り込み方法ごとにFeatureViewを分けることです。
まず、Online Storeで新たに2つのFeatureViewを作成します。
"stream_feature_view_M"では、"feature_view_M"の中でKafkaから取り込まれるリアルタイム特徴量定義のみを含めます。
"materialize_feature_view_M"では、"feature_view_M"の中でOffline Storeからマテリアライズされる特徴量定義のみを含めます。
モデルには、2つのFeatureViewデータを合わせて全体特徴量としてを提供します。
最終的に、Offline Storeではモデルのトレーニングとバッチ予測向けに"feature_view_M"の特徴量を提供し、Online Storeではオンライン予測向けに"stream_feature_view_M"と"materialize_feature_view_M"を合わせた特徴量を提供します。
これにより、同じFeatureView内で特徴量の更新頻度が違うとしても、データが上書きされず、正しく更新された特徴量データを提供することができます。

これがこの解決策の基本的な考え方の説明になります。

最後にまとめです。

本セッションでは、不正検知速度を向上させるための新しい仕組みについて説明しました。この仕組みでは、取引が行われる前に潜在的なリスクランクを算出し、即時不正防止システムに提供することで、全体的にニアリアルタイムの不正検知を実現しました。
この仕組みは不正検知を高速化し、機械学習モデルの予測をニアリアルタイムで不正防止に活用することができます。

また、このメカニズムを実現するためのシステムアーキテクチャやその具体的な実装方法についても話しました。既存のバッチソリューションにストリームソリューションを導入することで、包括的な不正防止ソリューションにより一歩近づくことができました。

お知らせがあります。私たちは不正防止システムにGraphDBを取り入れました。グラフベースのアプローチは、不正検知に置いて顕著な効果を発揮しています。データ間の関係やパターンを見つけることで、さまざまなタイプの不正を特定することができます。さらなる詳細については、近日中に公開されるブログ記事をお楽しみにしてください。

それでは本日のプレゼンテーションは以上とさせていただきます。ありがとうございました。




