はじめに
この記事は、Merpay Tech Openness Month 2023 15日目の記事です。
こんにちは。メルペイ加盟店精算チームのバックエンドエンジニア@r_yamaokaです。
今日は現在自分がリードして取り組んでいるテストコードの改善について紹介したいと思います。
抱えている課題
私が所属している加盟店精算チームのマイクロサービスは加盟店さま向けサービスとして欠かせないものであり、メルペイ最初期から存在するサービスです。他のマイクロサービスにあまり無い特徴として多数のバッチ処理を行っている点が挙げられます。
お客さま(メルペイユーザー)がお店で行った決済は、一定の頻度で集計し決済手数料を差し引いた上で加盟店さまの銀行口座へ振り込むことになります。
最終的な振込金額を算出するまでの流れとしては
- 個々の決済金額のリコンサイル(会計マイクロサービスとの金額照合)
- 日次集計
- 締日集計・返金分相殺・振込データ作成
- 振込指示
といった複数の処理を順に跨ってデータが処理されていきます。またこれら決済金額を直接集計するもの以外にも実行された振込の結果を取得してシステムに反映させたり、各バッチが作成したデータに誤りや矛盾が無いかをチェックしたりするバッチがあり、そのデータの流れは極めて複雑です。
こうした複数のデータ集計を伴う処理は前提条件が複雑になりがちで通常のテストだけでは動作を担保することが難しく、時折トラブルにより集計データの修正や整合性の確認をエンジニアが手作業で行うケースが発生し、品質面の改善が必要な状況となっています。
また長い時間を経てデータ構造やアーキテクチャーが最善とは言えない状態にもなっておりその解消のためにリアーキテクチャーを検討しています。この場合、変更したコードが既存の動作を破壊していないことを担保するテストコードは非常に重要ですが、前述した複雑さによりテストの網羅性が低くまたテストの可読性が低いことも相まって安全なリアーキテクチャーに自信を持てていないのが現状です。
解消のためのアプローチ
テスト粒度とその責務を分類する
テストの粒度は一般に「単体テスト」「結合テスト」等と2つ程度に別けられることが多いかと思いますが、これらは実質的に大小関係の定義のみで実際に何をどこまで担保するのかについては人・組織によりバラつきがあります。
私のチームのテストコードも例に漏れず主に「ユニットテスト」「E2Eテスト」が存在しますが、ユニットが簡素な代わりにE2Eで非常に多くのパターンを実装して網羅していたり、反対にユニットは充実している代わりにE2Eが非常に簡素であったりと統一感がありません。
このためテストケースの認知負荷が高く日々の開発で苦慮しており、まずは粒度の分類とその責務を定義しコードを整理するための基準を作ることにしました。
この問題に対する解の一つとしてとあるGoogle Testing Blogの投稿ではSmall, Medium, Largeと3つに分類しそれぞれでどの機能をどこまで使うのかについて定義されています。
(注: 13年前の記事なので現在もこのような分類を運用しているかは不明です)
当初はこれに倣ったテスト構成を考えていたのですが、SMLでは規模の分類に絞った命名であり大分類として何をテストするのかが依然として分かりづらく感じました。そのためSMLを参考にしつつテスト範囲が狭い順に「ユニット」「コンポーネント」「インテグレーション」という説明的な命名を採用し、解釈のバラつきはドキュメントの作成と丁寧な説明でカバーすることとしました。
ユニットは個々の関数やメソッドを対象としたテストで、データや条件分岐の面で高い網羅性を持たせることを主眼においています。コンポーネントは各種APIやバッチ単体を対象とし、マイクロサービスを構成する個々のコンポーネントが正しく動作するか確認します。インテグレーションは複数のバッチを跨いで最終的に正しいデータが得られるかを確認します。
基本的な考え方としてはカバーする範囲が狭い低コストなテスト(個々の関数・メソッド等の粒度)ほど網羅性を高くし、反対に範囲が広く高コストなテスト(API・バッチ等の粒度)ほど網羅性を低くするピラミッド型としています。
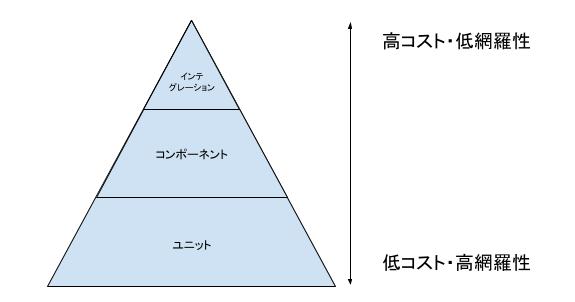
参考(Testing Pyramid): https://testing.googleblog.com/2015/04/just-say-no-to-more-end-to-end-tests.html
範囲が広いテストで網羅性も担保しようとするとコードの複雑性が増してメンテナンスが困難になるだけでなく実行時間が伸びます。また安定性を欠いた所謂FlakyTestになりやすく逆に開発の足を引っ張りかねないため、どの粒度でどこまでを担保するのかを明確にするのが重要です。
各分類にどの程度労力をかけるべきかについては様々な議論があるかと思いますが、Google Testing Blogの記事を参考に概ね以下のように考えています。
- ユニット: 5
- コンポーネント: 3
- インテグレーション: 2
コンポーネントとインテグレーションテストの割合が増えていますが、これは前述の通り複数の処理をまたがって行われる複雑な処理を検証しなければならないという特性をカバーする意図です。
以下に3つの分類とその責務をまとめます。
ユニットテスト
責務: コードの細部において高い網羅性を持った検証を行う
- 条件分岐や投入データのパターンを可能な限り網羅する
- レイヤー内に閉じたテストを指す
- レイヤーを跨ぐコード(usecaseからrepositoryの呼び出し等)はモックorスタブで対応する
- 外部コンポーネント(マイクロサービス、Pub/Sub、GCS等)との通信もモックorスタブで対応する
※コードのアーキテクチャーとしては、概ね一般的なレイヤー分けをしたクリーンアーキテクチャーと考えて頂いて差し支えありません。
コンポーネントテスト
責務: サービスのコンポーネント単体として一気通貫な動作(各APIのリクエスト〜レスポンス or バッチ単体での起動〜終了まで)を検証する
- 仕様書を網羅すること
- 試験環境(各個人の端末やCI環境)内で加盟店精算サービスを稼働させるテストを指す
- 外部マイクロサービスとの通信を要する箇所は極力bufconnと社内テストフレームワークでエミュレートする
参考: https://engineering.mercari.com/blog/entry/gears-microservices/
インテグレーションテスト
責務: 複数のバッチを通して行われたデータ処理の正当性を検証
- 基本的な動作環境はコンポーネントテストに準ずる
- バッチAで処理したデータをバッチBで処理しその値をチェックする、というようなテスト
- 網羅性は追求せず主に正常系と重要な異常系のみに絞る
記述スタイルを統一する
粒度の分類ではテストコードを整理し認知負荷を下げることを目指していますが、個々のテストの記述方法を統一することで更にその効果を高めることができます。そのためテスト実装の細かいスタイルについても話し合い、これもチームとして合意しました。
参考として以下にいくつか例を挙げます。
値の検証にはアサーションを使用する
Goでは標準でテスト結果のアサーション機能が提供されていません。これは「エラーメッセージは重要なので自ら考えて書くべき。記述のコストは高いがエラー分析やオンボーディングが楽になるので回収できるはず」というGoの思想によるもので、標準提供の関数とif文等の条件分岐を使い素朴な形で実装することが推奨されています。
参考: https://go.dev/doc/faq#assertions
しかし、自分が経験した限りでは手動ではどうしても手間がかかることと複数のエラー要因について配慮したメッセージを記述しようとすると冗長になることが多く、結局のところ
t.Errorf(“want %v, got %v”, want, actual)というようなあまり中身の無いエラーメッセージになりがちです。またerrorやstructの検証のようなコードはそれなりに難解な記述になってしまい、あまり恩恵を感じられていません。
それであるならいっそアサーションライブラリをを利用する方が簡便に記述でき、エラー分析はデバッガー等を駆使することでカバーすればよいというのが今のところの自分の考えです。
ライブラリにはtestifyとgo-cmpを採用しています。基本的には前者でチェックしますが、主にstructやproto messageはエラーメッセージの可読性や記述の容易さから後者でチェックしています。
未だ議論の余地がある事柄と思いますので、これが絶対の正解というわけではないですが少なくとも我々のチームとしてはこちらの方が合理的であるという判断のもと採用することにしました。
原則としてテーブル駆動で記述する
既存のテストコードには以下のような記法が散見されています。
TestXXX(t *testing.T) {
t.Run(“test pattern1”, func(t *testing.T) {
// do something
})
t.Run(“test pattern2”, func(t *testing.T) {
// do something
})
}前述の通り、加盟店精算サービスのテストは前提条件が複雑でモックやデータベースのセットアップの記述が難しいため、この記法にも一定の合理性があると言えます。しかし、このまま網羅性を向上しようとすると重複部分が多く保守性に難が生じることが予想されます。また再利用部分が無いため個々のテストケースを最後まで読まないとどのような検証が行われているのかわからなく認知負荷が高いことも欠点です。
そこで基本に立ち返りテーブル駆動で統一することに決め、複雑なセットアップは以下のように各ケース毎にfuncで定義することにしました。
参考: https://github.com/golang/go/wiki/TableDrivenTests
setupMock func(ctrl *gomock.Controller) (*mock.MockXXXService, *mock.MockYYYService)
prepareQueries func(ctx context.Context) []*spanner.Mutationこうすることでパターンの記述は少々長くなってしまいますが、ケースが増えても重複が膨れ上がることがなく検証内容とパターンを別けて読み込め認知負荷を下げることができます。
テストでも命名を省略しない
まず最初のケースですが下記サンプルのk, vとは何でしょうか?testCasesはテーブル駆動のケース定義と考えられるので、大概map[string]struct{ … }型と類推はできますが必ずしもそうとは限りません。vという変数は生存期間が極短い使い捨て変数として使いたくなる名前なので、下に続く検証部分が長くなった中でうっかり別の用途として使ってしまうと混乱を引き起こすかもしれません。
for k, v := range testCases {
t.Run(k, func(t *testing.T) {
….代わりにname, tc等とするとどうでしょう。明らかに理解が容易になったことがわかるかと思います。k, vとタイプの手間はほぼ変わらないのでこの僅かな手間は惜しまない方がよいです。
なお、必ずしも直接的な命名を採用する必要は無く、可読性が担保できるのであればどのようなものでも問題ありません。IDEやVSCodeの自動生成の場合テストケースは tt とされることが多いようなのでこういった慣例やチームの標準に倣うのもよいでしょう。
for name, tc := range testCases {
t.Run(name, func(t *testing.T) {
….次のケースです。このretはreturn(戻り値)から命名されたのだと思いますがさて何が入っているのでしょうか?errorかもしれませんし新規発行されたユーザーIDか、はたまたUser型のstructのポインターかもしれません。
ret := createUser(ctx, userName)
assert.NotEmpty(t, ret)これもやはり説明的な変数を採用し、何が入っているか一目でわかるようにするべきです。
userID := createUser(ctx, userName)
assert.NotEmpty(t, userID)流石にプロダクションコードでこういった命名がされることはないのですが、特に小規模なテストではついやってしまいがちです。しかし、書いた時点では正しく認識できていても2,3日もすれば書いた当人すら忘れてしまいますし、コードは日々成長していくものなので少々の手間は惜しまず、将来に渡って理解容易性を損ねないよう常に細部まで気を配るべきです。
自らサンプルを実装する
これまでの取り組みによってテスト改善のための方針をまとめ、チームのエンジニアに認識してもらうことはできたはずですが、本件をリードしているエンジニア(私)以外のメンバーの頭にある姿は微妙に異なっている可能性が高いです。また0から書いたコードをレビューに出すのは少々勇気が必要かもしれません。
そこで既存テストが無い部分については、最初にサンプルとなる実装を行い他のエンジニアが参照できるようにしておき、既存のものがある場合でもいくつか新しい形への移行を行います。こうすることで全員の認識を揃え、バラつきをより抑えることができるでしょう。その後は積極的にコードレビューに参加し、あるべき形へ誘導していくことも重要です。
おわりに
変化の激しい今日ではシステムは常に改善されていくものであり、その礎となるテストコードは決して軽視できません。既存のテストが膨大なためこの取り組みはまだ完了していません。しかし、一部新しい書式で書かれている部分については良好な感触を得ており、品質の向上とリアーキテクチャーの遂行に貢献できると確信しています。
今回の記事が皆様のテストコード改善の参考となれば幸いです。
明日の記事は @panorama さんです。引き続きお楽しみください。




