この記事は、Merpay Tech Openness Month 2023 の13日目の記事です。
こんにちは、メルペイ Solutionsチームのエンジニア@orfeonです。
メルペイ Solutionsチームでは社内向けの技術的な相談対応や研修、部門を跨いだ共通の問題を発見して解決するソリューションの提供など行っています。
自分は主に社内のデータ周りの課題を解決するソリューションを提供しており、一部成果はOSSとして公開しています。
過去の記事では検索APIサーバを手軽に構築して利用するソリューションを紹介しましたが、今回の記事ではグラフデータベースであるNeo4jを手軽に活用するソリューションを紹介します。
はじめに
社内では日々生成される大量のデータがBigQueryに蓄積され、レコメンドや異常検知などさまざまな用途で活用されています。
活用するデータの形態として不正利用などのユースケースではグラフデータを扱うケースもあります。
しかし一般的なRDBやDWHでは関係性に基づくクエリを実行しようとすると、レイテンシが大きくなったり、SQLで表現するのが難しいといった課題があります。
そのためこうしたグラフデータを活用するのに特化したさまざまなグラフデータベースが選択肢にあがります。
たとえば人気のグラフデータベースの1つであるNeo4jではCypherというグラフクエリを使ってグラフから情報を抽出します。
以下の例ではCypherを使って指定した(この例ではUserID=1を持つ)人物と同じ店舗でよく買い物をする人物を抽出しています。
MATCH (u1:User {UserID: 1})-[:BUY]->(s:Shop)<-[:BUY]-(u2:User)
RETURN u2.UserID AS UserID, COUNT(DISTINCT s.ShopID) AS ShopCount
ORDER BY ShopCount DESC
LIMIT 10グラフデータベースを活用することでこうした関係性に基づく情報を手軽かつ低レイテンシに抽出することができるようになり、レコメンドや不正検知に活用することができます。
グラフデータの活用にあたっては、グラフデータが実際に業務に本当に有効か検証したり、グラフデータベースが既存システムとの連携でスムーズに運用を行えるか検証する必要があります。
そのためさまざまなデータソースからグラフデータベースを構築し検証するにはまずさまざまなデータの繋ぎこみが必要です。
データ分析やMLで活用するにはデータ加工や特徴量作成などの試行錯誤を高速にまわすことが重要ですので、グラフデータベースの作成で手間取るわけにはいきません。
そこでこうしたデータの繋ぎこみの手間を減らして、さまざまなデータソースからグラフデータベースを構築したり、グラフデータベースと既存データとの付き合わせを手軽にできるようにするソリューションを検討しました。
今回は有力なグラフデータベースのひとつであるNeo4jにフォーカスしました。
Neo4jはフルマネージドなサービスであるNeo4j AuraDBなどさまざまな形態で提供されています。
こうしたグラフデータベースのシステム採用の検証を容易にすべく、以下の項目を実現するソリューションを紹介します。
- 手軽にグラフデータベースを構築
- BigQuery等の多様なデータソースからグラフデータベースを手軽に作成
- コンテナを利用して手軽にAPIサーバを立てたり手元でクエリを試せる
- 手軽にグラフデータベースを検証
- 作成したグラフデータベースに対して大量クエリのバッチ処理を手軽に実行
- データの生成日時からグラフの発展にあわせたクエリバッチ処理も実現
- ニアリアルタイムなグラフデータベースの検証(開発中)
なお、今回のソリューションでは検証を主要な目的とすることから以下の制約を想定しました。
- 1つのマシンに搭載できる大きさのデータしか扱わない
今回紹介するソリューションではグラフデータベースの作成や検証にあたって、大量のデータ処理やバッチとストリーミングで同じ処理を動かすのに便利なCloud Dataflowをデータ処理基盤として活用しています。
Cloud Dataflowのパイプライン実装はOSSのMercari Dataflow Template(以下MDT)のモジュール(localNeo4j sink モジュール / localNeo4j transform モジュール)として公開しています。
(Mercari Dataflow Templateについては過去の紹介ブログ記事を参照ください)
以下、多様なデータソースからバッチでグラフデータベースを作成するシステムと、作成したグラフデータベースを検証活用するシステムをそれぞれ紹介します。
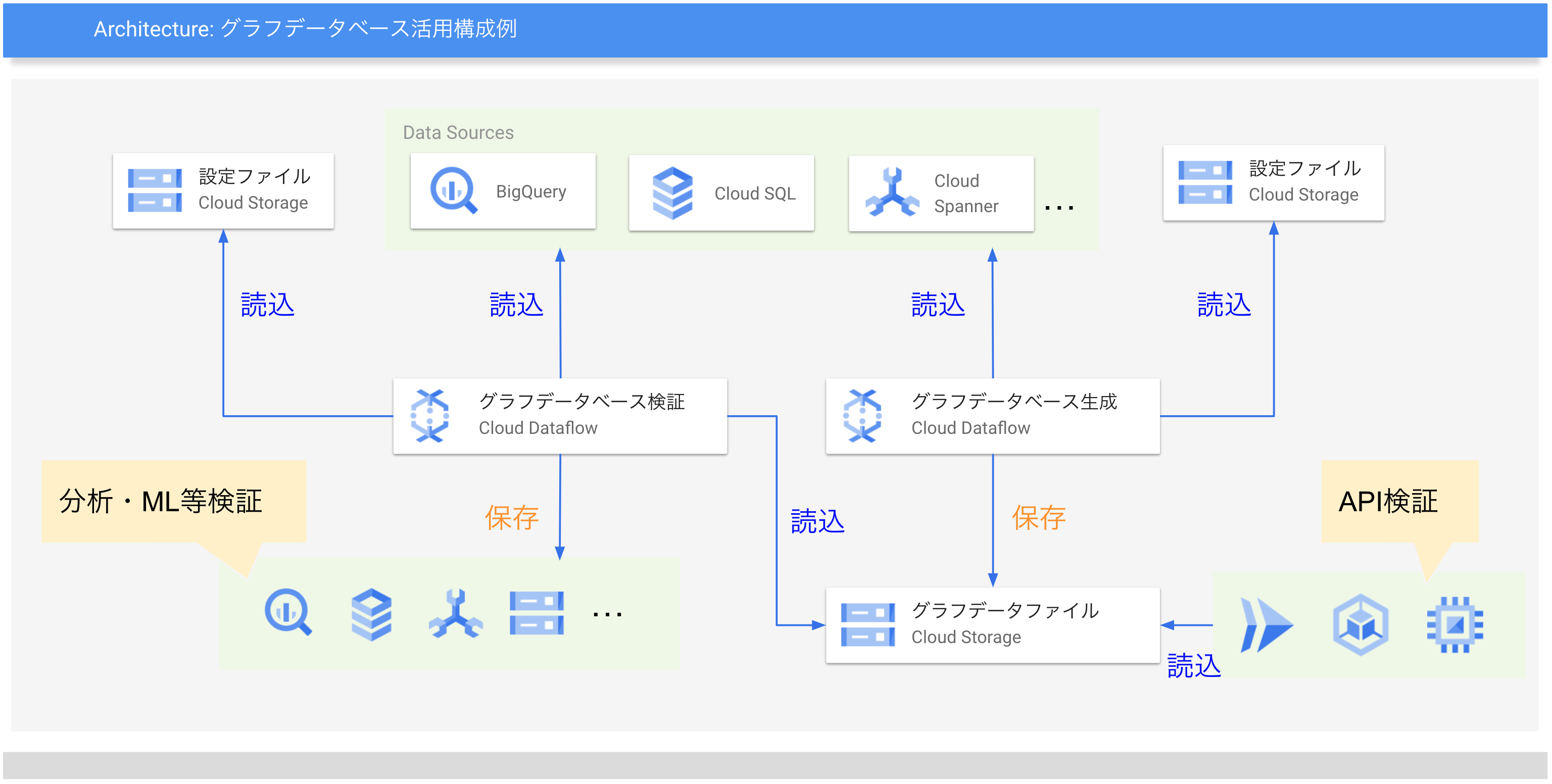
グラフデータベース作成
まずグラフデータベースに登録したいデータを用意します。
ここではシンプルなケースとしてBigQueryの一つのクエリ結果から構築する例を紹介します。
(MDTがソースとして対応しているものであれば置き換え可能です)
グラフデータベースではデータをノード(Node)、関係(Relationship)として登録します。
BigQueryから読み取ったデータは表形式なのでノード、関係として変換する必要があります。
MDTのlocalNeo4j sinkモジュールでは以下のような設定で変換を定義します。
{
"sources": [
{
"name": "BigQueryInputTransaction",
"module": "bigquery",
"parameters": {
"query": "SELECT UserID, ShopID, Pay FROM `mydataset.Transactions`"
}
}
],
"sinks": [
{
"name": "LocalNeo4jSink",
"module": "localNeo4j",
"inputs": ["BigQueryInputTransaction"],
"parameters": {
"output": "gs://examble-bucket/neo4j/index/transaction.zip",
"setupCyphers": [
"CREATE CONSTRAINT UserUniqueConst FOR (u:User) REQUIRE (u.UserID) IS UNIQUE",
"CREATE CONSTRAINT ShopUniqueConst FOR (s:Shop) REQUIRE (s.Shop) IS UNIQUE"
],
"nodes": [],
"relationships": [
{
"input": "BigQueryInputTransaction",
"type": "BUY",
"source": {
"label": "User",
"keyFields": ["UserID"]
},
"target": {
"label": "Shop",
"keyFields": ["ShopID"]
},
"propertyFields": ["Pay"]
}
]
}
}
]
}上のMDTの設定ファイルではシンプルな例としてBigQueryの購入履歴データから購入グラフを登録しています。
最初のbigquery sourceモジュールではBigQueryから購入者と店舗と支払額を取得しています。
次のlocalNeo4j sinkモジュールではデータから、購入者ノード、店舗ノード、購入関係を作成します。

localNeo4j sinkモジュールの各種パラメータを説明します。
inputs項目ではグラフデータとして登録した入力元のnameを指定しています。今回は購入履歴として一つの入力を指定します。
parameters項目の子項目ではより詳細なデータベース情報やグラフ変換内容を指定します。
outputでは作成したデータベースファイルのアップロード先としてCloud Storageのパスを指定します。
ちなみに今回は指定していませんが、inputという項目でデータベースファイルCloud Storageのパスを指定するとそのファイルを読み込んでデータベースの初期状態とします。
setupCyphers項目ではデータの登録に先立って実行しておきたいCypherクエリを指定します。
ここではグラフデータ登録の効率化のため、今回登録対象となる2つのノードUser,Shopに対してそれぞれユニークキーによるCONSTRAINTを指定します。
(ユニークキーに対してインデックスが貼られるため更新確認が高速になる)
relationships項目では関係の定義を行っています。
今回は購入者と商品の購入の関係のみ登録しています。
参照する入力名をinputで指定して関係の元と宛先のノードのラベル名、ユニークキーをそれぞれsource,targetで指定します。
また関係の属性として購入額を登録するようにpropertyFieldsでPayを指定しています。
今回は関係登録時に同時にノードも登録しているため利用していませんが、独立したノードを登録するにはnodesでノードの登録内容を定義します。
作成したMDTの設定ファイルをCloud Storageにアップロードして以下のようなコマンドでMDTでDataflow Jobを起動します。
gcloud flex-template run create-graphdb \
--project=myproject \
--region=asia-northeast1 \
--template-file-gcs-location=gs://{MDTデプロイファイルパス} \
--staging-location=gs://{stagingパス} \
--parameters=config=gs://{設定ファイルアップロード先パス}Jobが完了するとoutputで指定したCloud Storageのパスにグラフデータベースファイルがアップロードされます。
このファイルはグラフデータを構築したNeo4jのホーム配下のファイルをzipでまとめたものです。
利用するNeo4jサーバからこのzipファイルを解凍して参照することで作成したグラフデータを活用することができます。
ちなみに今回の検証では1億件強のデータを利用したところ約4時間でJobが完了しました。
zipファイルのサイズは23.8GBで、ノード数はUser,Shopあわせて約560万件、関係数は約1億件でした。
実際のデータ登録に掛かった時間は2時間程度で、残りはグラフデータベースファイルをzipファイルに圧縮してCloud Storageにアップロードするのに掛かった時間でした。
なおCloud DataflowのworkerのmachineTypeにはe2-highmem-4を指定し、SSDのPersistent Diskを256GB指定しました。
作成したグラフデータベースファイルはCloud Buildを利用することで、Neo4jの公式Dockerイメージからグラフデータを同梱したコンテナイメージを生成することができますし、Cloud RunやGKEにデプロイしてAPIサーバとして活用することもできます。
以下、グラフデータが同梱されたイメージを生成するDockerfileの例と、コンテナイメージ生成とCloud Runへのデプロイを定義したcloudbuildファイルの例を紹介します。
(ポートを複数利用するため現状Cloud RunからGUIによるグラフ操作を利用することはできません)
Dockerfile_graph
FROM neo4j:4.4.21
USER neo4j
COPY --chown=neo4j:neo4j data/ /data/
COPY --chown=neo4j:neo4j logs/ /logs/
ENV NEO4J_AUTH=neo4j/password※ ENV_NEO4J_AUTHではログイン時の初期アカウント名とパスワードを指定します
cloudbuild.yaml
steps:
- name: 'gcr.io/cloud-builders/gsutil'
args: ["cp", "gs://examble-bucket/neo4j/index/transaction.zip", "."]
- name: 'gcr.io/cloud-builders/gsutil'
entrypoint: "unzip"
args: ["transaction.zip"]
- name: 'gcr.io/cloud-builders/docker'
args: ["build",
"-f", "Dockerfile_graph",
"-t", "$_REGION-docker.pkg.dev/$PROJECT_ID/graph/graph",
"."]
- name: 'gcr.io/cloud-builders/docker'
args: ["push", "$_REGION-docker.pkg.dev/$PROJECT_ID/graph/graph"]
- name: 'gcr.io/cloud-builders/gcloud'
args: ["run", "deploy", "graph",
"--image", "$_REGION-docker.pkg.dev/$PROJECT_ID/graph/graph",
"--platform", "managed",
"--region", "$_REGION",
"--memory", "2Gi",
"--port", "7474",
"--min-instances", "1",
"--no-allow-unauthenticated"]
timeout: 600s
substitutions:
_REGION: asia-northeast1また、グラフデータベースファイルをPCにダウンロード・解凍して、Neo4jの公式Dockerイメージからコンテナを起動して参照することで、手元で手軽にクエリを試すこともできます。
以下、コンテナ起動コマンド例を紹介します。
docker run \
--name graph \
-p7474:7474 -p7687:7687 \
-d \
-v {graph_db_dir_path}/data:/data \
-v {graph_db_dir_path}/logs:/logs \
-v {graph_db_dir_path}/import:/var/lib/neo4j/import \
--env NEO4J_AUTH=neo4j/password \
neo4j:4.4.21(windows環境で動かない場合はNEO4j_dbmsconnector{http|https|bold}_advertised__address環境変数の指定を試してみてください)
グラフデータベースの検証活用
次に作成したグラフデータベースファイルをさまざまなデータと付き合わせて手軽に検証活用するソリューションを紹介します。
作成したグラフデータベースの活用方法としてはグラフデータベースAPIサーバを立てて、グラフデータを利用したいサービスからリクエストを送って結果を取得・活用するのが一般的です。
しかしAPIサーバ利用では少し面倒なケースも存在します。
たとえばグラフデータベースに大量のクエリを実行して結果を保存する場合、リクエストを組み立て結果を取得して保存するコードを書く必要があります。
クエリ内容をいろいろなパターンで試したい場合に都度コードを書き換えて実行するのは少し面倒です。
またグラフデータは時間と共に変化していくこともあります。
リアルタイムにグラフデータを活用する場合はグラフデータの発展推移に合わせてクエリを実行する必要があります。
たとえばリアルタイムなグラフデータを活用したMLモデルの活用ではグラフデータを特徴量として活用する際に、特徴量として用いるデータが生成された時の状態のグラフデータへのクエリ結果が必要になります。
APIサーバを使ってこうした特徴量を学習用のデータとしてバッチで生成する場合、APIサーバにデータの生成日時順に更新とクエリを実行して結果を取得する必要があります。
こうした発展推移するグラフデータからのクエリ取得をバッチで手軽に生成できるようになるとデータ分析や特徴量作成での試行錯誤を高速にまわすことができると考えられます。
以下表ではグラフデータの更新の有無に加え、グラフデータの処理形態がバッチかストリーミングかで想定するユースケースをまとめました。
MDTのlocalNeo4j transform モジュールではこれらのユースケースをサポートすることを目指しました。

ここからはMDTによる更新を伴うグラフデータベースへのBatchでのクエリ取得例として、BigQueryにある購入履歴データからグラフデータを更新・クエリ実行結果を取得してBigQueryに保存する例を紹介します。
この例では先ほどと同じ購入履歴を用いて、ユーザが購入を行うごとにその時点での同じ店舗で買い物するユーザの数を数えています。
以下はMDTによる設定例です。
{
"sources": [
{
"name": "BigQueryInputTransaction",
"module": "bigquery",
"parameters": {
"query": "SELECT UserID, ShopID, Pay, CreatedAt FROM `mydataset.Transactions`"
},
"timestampAttribute": "CreatedAt"
}
],
"transforms": [
{
"name": "LocalNeo4j",
"module": "localNeo4j",
"inputs": ["BigQueryInputTransaction"],
"parameters": {
"index": {
"setupCyphers": [
"CREATE CONSTRAINT UserUniqueConst FOR (u:User) REQUIRE (u.UserID) IS UNIQUE",
"CREATE CONSTRAINT ShopUniqueConst FOR (s:Shop) REQUIRE (s.ShopID) IS UNIQUE"
],
"nodes": [],
"relationships": [
{
"input": "BigQueryInputTransaction",
"type": "BUY",
"source": {
"label": "User",
"keyFields": ["UserID"]
},
"target": {
"label": "Shop",
"keyFields": ["ShopID"]
},
"propertyFields": ["Pay"]
}
]
},
"queries": [
{
"name": "SimilarUserCount",
"input": "BigQueryInputTransaction",
"cypher": "MATCH (u1:User {UserID: ${UserID}})-[r:BUY]->(s:Shop)<-[:BUY]-(u2:User) WITH u1.UserID AS UserID, u2.UserID AS TUserID, COUNT(DISTINCT s.ShopID) AS ShopCount WHERE ShopCount > 4 RETURN UserID, COUNT(DISTINCT TUserID) AS SimilarUserCount",
"schema": {
"fields": [
{ "name": "UserID", "type": "long" },
{ "name": "SimilarUserCount", "type": "long" }
]
}
}
],
}
}
],
"sinks": [
{
"name": "BigQueryOutput",
"module": "bigquery",
"input": "LocalNeo4j",
"parameters": {
"table": "myproject:mydataset.results",
"createDisposition": "CREATE_IF_NEEDED",
"writeDisposition": "WRITE_TRUNCATE"
}
}
]
}最初のbigquery sourceモジュールではBigQueryから購入者と商品と支払額と購入日時を取得しています。
また先のデータベース作成時には指定していなかったtimestampAttribute項目に購入日時を示すCreatedAtフィールドを指定しています。これは指定したフィールドの値をデータの生成日時として扱うことを宣言するものです。
この指定により次のlocalNeo4jのtransformモジュールでは入力となる購入履歴データをCreatedAtの値の順に処理を実行します。
次のlocalNeo4j transformモジュールでは入力データに基づいてグラフデータを更新・クエリを構築して結果を取得します。
inputs項目ではグラフデータベースへ登録するデータやクエリの入力元のモジュールのnameを指定しています。今回は購入履歴の取得を定義したBigQueryInputTransactionを指定してグラフデータベース登録かつクエリ生成に利用します。
parameters項目では詳細なグラフデータの更新設定とクエリ設定を指定します。
index項目ではグラフデータの更新設定を定義します。
今回の例ではデータベース作成時の設定とほぼ同じ内容を指定しています。
今回は利用していませんがpath項目であらかじめ作成したグラフデータベースファイルのCloud Storageのパスを指定することでデータをロードして処理を開始することができます。
queries項目では入力データからcypherクエリを生成・実行して結果を取得する定義を行います。
cypher項目ではApache FreeMarker形式のTemplate文字列を指定します。
ここに入力データのフィールド値が埋め込まれてCypherクエリが生成・実行されます。
この例では購入履歴レコードのユーザのIDから、5店舗以上同じ店舗で買い物をしたユーザ数を抽出するCypherクエリを生成しています。
schema項目ではCypherクエリの結果データのスキーマを指定します。
クエリ結果はここで指定したスキーマを持つレコードの配列として保持されます。
こちらのクエリ定義は複数指定することができ、一つの入力から複数種のクエリを実行することもできます。
最後のbigquery sinkモジュールでは生成した結果を指定したBigQueryのテーブルに保存しています。
保存されたデータはデータ分析や特徴量生成などに活用することができます。
おわりに
今回の記事ではグラフデータベースのNeo4jを手軽に試せるソリューションを紹介しました。
グラフデータを活用してみたいけどデータの連携が面倒で試すのに二の足を踏んでいたような場合でしたら今回紹介したソリューションが役立つかもしれません。
今回紹介したソリューションによるグラフデータ活用の展開はまだこれからというフェーズで、紹介したMDTのモジュールも発展途上です。もしご利用いただいた方がおられましたらフィードバックをいただけると幸いです。
過去に紹介した検索APIサーバ構築とも共通するのですが、さまざまなデータソースから各種データベースを構築してコンテナイメージに同梱するなど、1台のマシンに載るサイズの更新不可なデータとして活用できるパターンは他にもまだあるかもしれません。
引き続き社内データ活用を広げるソリューションを見出して提供していきたいと思います。
明日の記事は@fukuchanさんです。引き続きお楽しみください。




