
この記事は、Merpay Advent Calendar 2022 の22日目の記事です。
こんにちは、メルペイSREチームでEM(Engineering Manager)をしているfoostanです。今回はメルペイにおけるインシデントマネジメントとナレッジシェアについてご紹介します。なおメルペイではインシデントをいくつかのタイプに分類してマネジメントフローを定めていますが、今回はシステム障害を原因としたインシデントにフォーカスしています。
インシデントから学びを得る
私たちはメルペイのサービスを開発し提供していますが、システムが何も壊れずに24時間365日動き続けることはありえませんし、オペレーションミスを絶対にしないとも言い切れません。そのためSLI(Service Level Indicator)を定義し、SLO(Service Level Objective)という担保すべき信頼性の目標を掲げて運用を行っています。サービスの信頼性を確保するために、SREとして信頼できるインフラの整備や、サービスの監視強化、リスクの検知や除外などさまざまな取り組みを行っています。その中でも重要な取り組みの一つにインシデントマネジメントがあります。インシデントが発生する要因は、ハードウェア障害やソフトウェアのバグ、オペレーションミスやサードパーティのシステムに起因するものなどさまざまであり、それら複数の要因から発生する事象を事前に防ぐ必要があります。ただし先述したように、システムは不具合を起こす可能性があり、人間はオペレーションミスをする可能性があります。よっていかに素早く検知できるか、いかに事態を早急に収束させられるか、またいかにそこから学びを得て次に繋げられるかが重要です。
インシデントマネジメント体制
インシデントが発生した場合、関連する開発チームやPM(Product Manager)、SREチーム、セキュリティチームなどさまざなチームが協力し事態の収束にあたります。また特に重大なインシデントの場合はIT Riskチーム※の主導のもと当局への報告がなされます。発生したインシデントに関しては次のようなツールや体制によってマネジメントおよびナレッジシェアを行っています。
※ システムリスク管理を専門に行うチーム https://mercan.mercari.com/articles/33642/
Blameless
https://www.blameless.com/
インシデントのステータス管理やレトロスペクティブ(ふりかえり)の実施、分析などに利用しているサービスです。Slackと連携することができ、インシデント対応開始時に専用のチャンネルを作ったり、インシデントやレトロスペクティブのステータス変更をトリガーにしてアクションを実施することができます。ここで蓄積されたインシデントやレトロスペクティブの情報を元にグラフやダッシュボードの作成をすることができ、インシデントの傾向分析などにも役立てています。Blamelessを利用したインシデントマネジメントフローについては後述します。
Incident Management Committee
インシデントマネジメントの改善を目的とした社内コミッティで、開発チーム、PM、SREチーム、IT Riskチームなどを中心に構成されています。週次でミーティングを行っており、各インシデントの対応状況やレトロスペクティブの進捗状況の共有/レビュー、インシデントマネジメントフローの策定/改善、レトロスペクティブのテンプレートの策定/改善、過去インシデントの分析、社内で公開するためのレポートの作成などその活動は多岐にわたります。
Incident Sharing Opendoor
Incident Management Committeeが運営しているナレッジシェアを目的としたミーティングで、インシデントから得られた学びを各インシデントコマンダーに共有してもらう場となっています。社員であれば誰でも参加可能なミーティング形態(Opendoor)となっており、エンジニアやPMを中心に毎回数十人ほど集まって情報共有が行われています。
Incident Summary Report
Incident Management Committeeが作成しているナレッジシェアを目的としたレポートで、3ヶ月ごとに発生したインシデント全体の件数やチームごとの内訳、原因の内訳等をBlamelessに蓄積されたデータを元にグラフ化しまとめたものです。またチームごとのインシデントマネジメントの状況(インシデントの解決時間やレトロスペクティブの実施件数、再発防止策の実施状況)についてもまとめており、正しくインシデントマネジメントがなされているかの評価も行っています。
Severity
各インシデントにその重大性を分類するためにSEV1~SEV5※までの5段階のレベルを設定しています。各Severityの基準は大まかに次のとおりです(実際はもっと細かい定義とポリシーが存在しますが本記事では割愛します)。
※ SEV5は現在検討中の段階で、定義と運用ポリシーを確定してこれから利用していく予定です

重要度や緊急性が高いインシデントであるほど即時対応と再発防止策の実施の徹底を行っており、状況に応じて専用の対策プロジェクトを発足し、多くのチームが連携して対応に当たるケースもあります。またお客さま影響が出ていない場合でも、ソフトウェアのバグなどの潜在的リスクを発見した場合はSEV4のインシデントとして扱い、リスクを排除することで重大なインシデントの発生を事前に防ぐ取り組みがされています。
インシデントマネジメントフロー
メルペイではインシデントを検知してからクローズ(対応完了)とするまでに4つのステップに分けて対応しています。ここからはインシデントマネジメントフローをステップごとに紹介していきます。

Step1: エスカレーション
インシデントが発生する要因はさまざまです。システムの不具合を起因とする場合は、システムモニタリングにより障害を検知してインシデントとして対応を行うケースがあります。どのような観点でモニタリングを行いアラートを上げるかについては以前に「お客さま影響に基づく実践的なアラート方法」として紹介しているのでよければご覧ください。その他にもソフトウェアのバグを開発チームが発見するケースや、お客さまからのお問い合わせで判明するケースなどがありますが、いずれの場合においてもインシデントと疑わしき事象が発生した際は速やかに関係者に状況が伝わるようにエスカレーションすることが重要です。
メルカリグループではインシデントに関する情報を共有する専用のSlackチャネルを用意しており、何かあればここに関係者が集まり、先述したBlamelessによってインシデント対応を開始します。Blamelessには専用のSlackコマンドも用意されているのでSlack上で速やかに開始することができます。
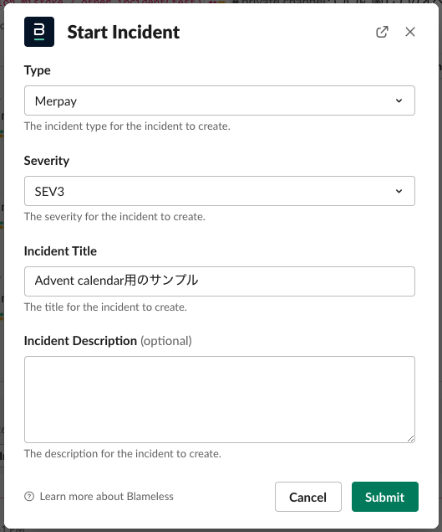
インシデントの対応が遅れる要因のひとつにエスカレーションが遅れるケースが存在すると思います。例えば、不具合が起こっているのはわかっているがインシデントとして扱うべきなのか?と悩んでしまい時間が経過してしまうなどが考えられます。またはその後の対応コストのことを考えてしまい問題を隠してしまうという心理が働いてしまうかもしれません。メルペイでは誤報を恐れずに少しでも疑わしい場合はインシデントとして扱うべきとオンボーディングで伝えています。確かに対応コストはそれなりに掛かってしまいますが、早急に対応することで被害の拡大が防げる可能性が高いためエスカレーションは早いに越したことはないです。また誤報である場合はSeverityを下げることでその後の対応コストを極力少なくできるフローを用意しているので恐れずに伝えてほしいと考えています。
Step2: インシデント対応
Blamelessによりインシデント対応が開始されると専用のSlackチャネルが作成されるため、以後はそこで具体的な対応と情報共有が行われます。また開始時にはインシデント対応をするにあたっての注意事項やインシデント対応に慣れていないメンバーのために対応ガイドへのリンクを表示するようにしています。
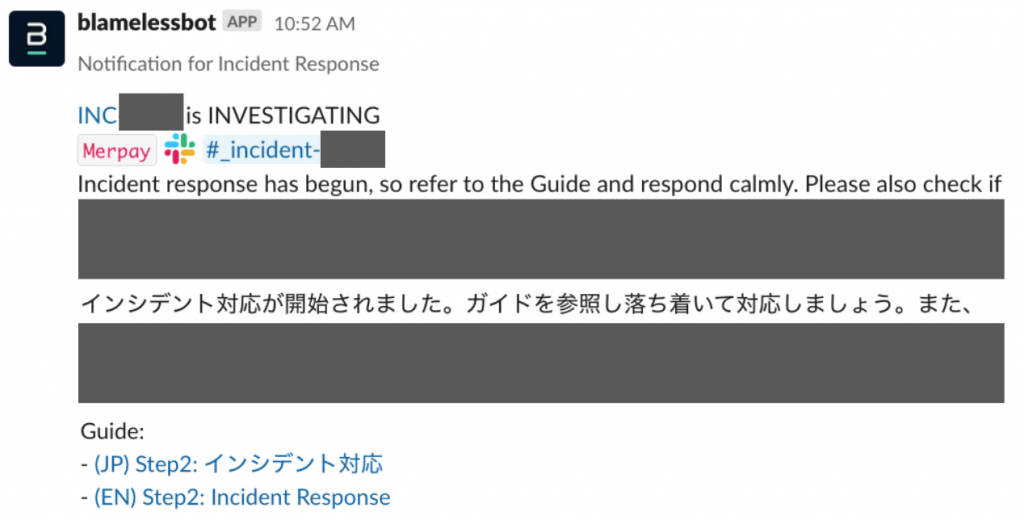
インシデント対応は発生した規模にもよりますが、インシデントコマンダーと呼ばれる役目を特定のメンバーにアサインしてその場のリードをしてもらいます。インシデント発生初期はどうしても現場が混乱していたり、インシデントのきっかけを作ってしまったメンバーが慌ててしまっているケースが想定されます。なので現在起きている事象の整理や、関係する各メンバーとのコミュニケーション、必要に応じたメンバーアサインなどインシデント対応をリードする人がいるとスムーズな対応が行えます。もし規模が大きいようであれば、情報収集と共有をメインに担当するコミュニケーションリード、事態の収束にあたり技術面で現場を仕切るテクニカルリード、といった役割をインシデントコマンダーとは別にアサインします。
Step3: レトロスペクティブ
インシデントの事態が収束し落ち着いたらレトロスペクティブ(振り返り)を行います。インシデントが起きた根本的原因を明らかにし、恒久対応と再発防止策を行うことで同じようなインシデントの発生を防ぎます。またインシデント発生時の行動についても改善点を話し合って次に備えます。なおレトロスペクティブ用のテンプレートを用意しており、内容はおおよそ以下のとおりです。
- インシデントの概要
- サービスの概要
- タイムライン
- 被害状況
- インシデントの原因と対応
- 直接的な原因
- 暫定対応
- 根本的な原因
- 恒久対応
- 再発防止策
- インシデント対応の振り返り
またレトロスペクティブで意識している点は以下の通りです。
- 相手を非難せず建設的な議論を行う
- インシデントから学ぶ
- 恒久対応、再発防止を行いインシデントを繰り返さない
Step4: 恒久対応/再発防止策の実施
レトロスペクティブで挙げた恒久対応と再発防止策を確実に実施することが重要です。他のタスクを優先してしまい、実施しないままだと同じ原因のインシデントの発生を防ぐことができません。そこで以下の点を意識しています。
- 場当たり的な修正ではなく、根本原因を潰し切る
- チケット化して期限を設けて確実に実施する
- 短期的に完全な対応が難しい場合、マイルストーンを分けて段階的な対応を計画する
- チームで継続的に完了までトラックする
なお実施する期限はSeverityによってポリシーを決めており、重大なインシデントであるほど期限を短くして短期間に改善が行われるようにしています。また恒久対応/再発防止策については以下のような視点でチームで話し合い決めています。
- バグ修正
- 運用や設計の改善
- 体制の見直し
- 残存リスクへの対応
- 監視やSLOの見直し
- MTTA※およびMTTR※の改善
※ MTTA (mean time to acknowledge): インシデントに気づくまでにかかる時間
※ MTTR (mean time to resolve): インシデントに気づいてから解決するまでにかかる時間
まとめ
インシデントマネジメントとナレッジシェアの体制と、実際に行っているマネジメントフローの概要について紹介しました。メルペイ内でIncident Management Committeeを立ち上げてから1年ほど経ちましたが、この1年で確実にインシデントに対する取り組みの意識改善と次に繋げるための活動が増えてきています。インシデントから学びを得てサービスに還元することで、メルペイを利用して頂いているお客さまに対して品質の高いサービスを提供し続けられるよう努めていきたいと思います。




