
この記事は、Merpay Advent Calendar 2021の16日目の記事です。
こんにちは、メルペイSREチームのfoostanです。普段はキーボードのことばかり話していますが、本業ではSREチームの一員としてソフトウェアエンジニアリングをしたりEM(Engineering Manager)をしています。
SREチームの重要な役割の一つはサービスの信頼性を高め、当たり前のようにメルペイを使えるようにすることです。信頼性を高めるためにはサービスが止まらないようなシステム構成にすることが重要ですが、サービスが異常な状態になったとき、関係者に状況を知らせるためのアラートを適切に上げることも重要です。そこで本記事ではお客さま影響に基づく実践的なアラート方法についてご紹介します。
適切なアラートとはなにか
まずはどのようにアラートを上げるのが適切か考えてみます。アラートを上げる目的のひとつはサービスの異常をすばやく検知して、お客さまへの影響を最小限にすることです。よって適切なアラートとは以下のようなものでしょう。
- お客さま影響のある異常が発生した時にすぐ気付ける
- サービス復旧や原因特定などのアクションがすぐ取れる
ここで難しいのは「お客さま影響」とは具体的に何なのか、またそれをどのようにして計測し、どのような考えに基づいて異常だと認識すべきか、という点です。抽象的かつ人によって認識のずれが出てきそうな部分かなと思いますが、これについては後ほど取り上げます。
過剰なアラートによる生産性の低下または健康被害
適切にアラートが上がらないとどのような悪影響を及ぼすのか考えてみます。具体例として適切ではないアラートをいくつか挙げてみます。
- サービスの異常を検知できない、もしくはアラートが上がるまでの時間が長い
- 過剰にアラートが上がっており、かつ特にアクションする必要がないものが多い
1つ目に関しては、せっかく監視設定をいれてもそれが正しく機能しないのであれば意味がありません。よってこれが適切ではないのは明らかであり、サービスの信頼性を下げることに繋がります。
2つ目はどうでしょうか。取りこぼしが発生するぐらいなら過剰にアラートを上げたほうがいいという考え方もあるかもしれません。しかし過剰なアラートによってそれが形骸化して、結局重要なものを見逃したという経験に身に覚えがある方は少なくないのではないでしょうか。
過剰なアラートは監視体制の悪化を招くだけでなく、頻繁に飛んでくる通知による集中力の低下、運用コスト増加による生産性の低下、深夜帯に発生する不要なアラートによる健康被害など、大きなデメリットがあります。サービスを安定的に稼働させるためにも不要なアラートを減らして、健康的にサービス運用することはとても大切なことです。
信頼性の定義と目標
話を少し戻し、適切なアラートを上げるための指標となる「お客さま影響」について考えていきます。下記の図はお客さまの幸福度とサービスの信頼性の関係性を表したものです。

※ 参考: Shrinking the impact of production incidents using SRE principles—CRE Life Lessons
サービスを利用するお客さまにとってサービスが安定的に稼働し、信頼性が高いことは当然の要求だと思いますが、「絶対に止まらないサービス」を提供することは不可能です。信頼性を高めるためには、災害を考慮したマルチリージョン構成にしたり、クラウドサービスの障害を考慮したマルチクラウド構成にしたりと、それ相応のコストがかかるのが現実です。ですのでお客さまの幸福度の期待値とコストとのバランスが取れるポイントを見極め、それを信頼性の目標値として設定する必要があります。なおこの目標値を最初から完璧に設定することは困難であり、定期的に見直しをする必要があります。
「お客さま影響」があったときにアラートを上げるためには、それぞれの要素を数値化し機械的に扱えるようにする必要があります。そのために使える概念として SLI/SLO/Error budget があります。
SLI (Service Level Indicator)
サービスの信頼性を測るための指標であり、お客さまの幸福度を数値として計測可能なものを選びます。例えば以下のようなものです。
- 成功したリクエストの割合
- 100ms以内で完了したリクエストの割合
このようにSLIはハッキリとOKとNGの判断が出来るもの選び、その割合を利用することが好ましいです。どのようなSLIを選択するかはサービスの性質やお客さまの幸福度が何によって変化するかをよく考えて理解する必要があり、これもまた定期的な見直しが必要な要素の一つです。
SLO (Service Level Objective)
何を計測するか決まったら具体的な目標値を定めます。例えば以下のようなものです。
- 成功したリクエストの割合が30日間で99.9%
- 100ms以内で完了したリクエストの割合が7日間で99%
このようにSLIに対して達成すべき割合(%)と期間を定めます。先程も述べたとおり、目標値を最初から完璧に設定することは困難なので、最初はある程度の数値を決め打ちで定めると良いと思います。実際メルペイにおいてもサービスの重要度に応じて設定すべきデフォルト値を定めていて、定期的に見直す機会を設けて調整しています。
また期間の設定はサービスの性質にもよりますが、SLOを見直す間隔と揃えると運用しやすくなります。リリース当初は頻繁に見直すため7日間にし、安定してきたら30日間にするなど途中で変更するのもいいかもしれません。特に次に説明するError budgetの概念を利用する場合、開発の優先度にも関係してくるため開発のスプリントに合わせるのも一つの手です。
Error budget
SLOに対して許容できる異常系の割合です。この許容範囲を予算(Budget)と捉えて、予算が残っているうちは新規機能のリリースなどのリスクを伴う施策が実施できます。しかし、異常系の割合が増加し、予算が底を尽きた場合は新規機能のリリースを中断し、信頼性を回復させるための施策を実施することになります。このようにError budgetをうまく利用することで信頼性を担保しつつチャレンジングな行動が取りやすくなります。
Error budgetの計算について具体例を用いて説明します。
なおここで挙げる例は
- SLO: 成功したリクエストの割合が30日間で99.9%
- リクエスト頻度: 秒間100リクエスト
であるものとします。Error budgetは「リクエスト総数 * (1-SLO) 」で計算することができ、今回の例では
- 100 * 60 * 60 * 24 * 30 * (1-0.999) = 259,200
となります。つまり30日間で異常リクエストを259,200まで許容することできます。具体的にどのぐらいで予算を使い果たすか例を挙げると
- デプロイミスでエラー率が100%になる (秒間100エラーが発生する)
- 259,200 / 100 = 2,592秒 = 43.2分
- バグを仕込んでエラー率が1%になる (秒間で1エラーが発生する)
- 259,200 / 1 = 259,200秒 = 3日間
と計算することができます。大きな障害であるほど予算の消費が早いことがわかります。
お客さま影響とアラート
お客さま影響が出ている状況とは
ここまででお客さまの幸福度と信頼性との関係性、信頼性を数値化するためのSLI/SLO/Error budgetについて説明しました。では具体的に「お客さま影響」とは何か、またどのような状態になるとお客さま影響が出ていると判断できるのかを考えてみます。
- Error budgetが底をついている状態
- SLOとは信頼性の目標であり、これを下回るとお客さまの幸福度が著しく損なわれます。そしてこの状態は明らかにお客さま影響が出ている状態と言えます。
- 障害が発生しすべてのリクエストがエラーになっている状態
- サービスが利用できない状態は明らかにお客さまの幸福度が下がります。仮に10分程度で回復しError budgetが残っていたとしてもお客さま影響が出ている状態と言えます。
- 何かしらの原因で常に0.01%のエラーが発生している状態
- エラーが出ていることが明確であれば、それはお客さま影響が出ているのではないかと考えるかもしれません。しかし0.01%のエラーがError budgetに及ぼす影響を考えると十分にその許容範囲に収まっているため、お客さまの幸福度への影響も軽微だと捉えることできます。
このように何かしらの異常が発生している状態に対して、Error budgetがどの程度消費されているかを計算することで「お客さま影響」がどの程度出ているかを判断することができ、その許容範囲を超えた時にアラートを上げることができるようになります。
Burn rate
Error budgetの消費量を表現する方法としてBurn rateというものがあります。
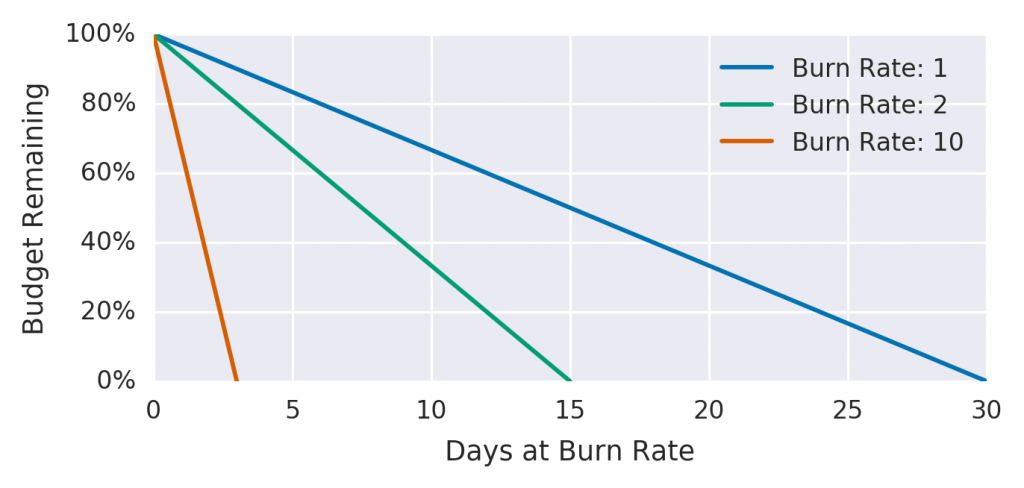
※ 転載: The Site Reliability Workbook Figure 5-4. Error budgets relative to burn rates
この図は期間が30日のSLOにおけるBurn rateの特徴を示したものです。Burn rateとはError budgetの消費量を示す度合であり、SLOで定めた期間で丁度使い切った場合を1とします。消費量が2倍になればBurn rateは2となり、半分の期間の15日で使い切るという意味になります。
お客さま影響が出ているかどうかの判断基準はそのサービスの性質によりますが、このBurn rateの値を用いることでお客さまへの影響度合いに応じてアラートを上げることができます。
Datadogによる設定例
ここからは実際の設定例を紹介します。メルペイではDatadogを利用しているのでDatadog上での設定例を取り上げます。
SLIの選定
SLIとして利用するメトリクスはお客さまへの影響度合いが測れる必要があり、これを適切に選定する事は最初の重要なステップです。例えば単純なWebサービスであれば、ロードバランサーのメトリクスから正常なリクエストの割合を計算したり、レスポンスタイムを利用することができそうです。
メルペイの場合はマイクロサービスごとにSLOを設定しており、独自の実装でサービス間の通信のログをカスタムメトリクスとして収集しています。なお近い将来にはIstio等のサービスメッシュのログから同様のメトリクスが収集できると期待しています。

※ The Go gopher was designed by Renée French.
Datadog APM を利用していればトレースログのメトリクスを利用するのも有効な選択肢の一つです。例えば
- trace.grpc
- trace.grpc.hits
- trace.grpc.errors
これらのメトリクスが利用可能です。詳しくは https://docs.datadoghq.com/tracing/guide/metrics_namespace/ に記載があります。なお、トレースログはあくまでアプリケーションが処理した際に出力されるものであり、アプリケーションにリクエストが到達しないケースの障害は検知できないので注意が必要です。
SLOの設定
SLIの選定が済んだらドキュメントに従ってSLOを設定していきます。詳しい設定方法は省きますが
の2種類があるのでそれぞれの特性を理解した上で選択する必要があります。詳しくは各ドキュメントまたはGCPのドキュメントに説明がありますが、それぞれリクエストをベースにするのか(Metric-based SLOs)、時間をベースにするのか(Monitor-based SLOs)の違いがあり使い勝手が異なるということ、また扱うメトリクスによっては Metric-based SLOs が利用できないケースがある点に注意が必要です。
Burn Rate Alertsの設定
先月初旬にPublic betaとしてDatadogでもBurn Rate Alertsが使えるようになりました。
詳しい設定方法はドキュメントが用意されているのでそちらから確認できます。
https://docs.datadoghq.com/monitors/service_level_objectives/burn_rate/
Burn Rate Alertsの設定項目は主に以下の3つです
- 対象のSLO
- 評価のWindow (Long Window を入力すると Short Window が自動で入る)
- アラートのしきい値(Burn rate)
対象のSLOに対してLong/Short Windowで指定した期間におけるBurn rateを計算し、しきい値を超えた場合にアラートが上がります。Windowや推奨する各パラメータは上記のドキュメントにありますが、The Site Reliability Workbook 5: Multiple Burn Rate Alerts に詳しい説明があります。Long/Short の2つのWindowを設定することからも分かる通りDatadogの実装はMulti Burn Rate Alertsです。
またThe Site Reliability Workbook 6: Multiwindow, Multi-Burn-Rate Alertsを実現するには複数のBurn Rate Alertsを設定します。ただし単純に複数設定してしまうとそれぞれの設定から通知が来てしまうのでCompositeモニターを使うなどの工夫が必要です。
下記はCompositeモニターを利用してMultiwindow, Multi-Burn-Rate Alertsを設定するためのTerraformの記述例です。
resource "datadog_monitor" "slo_monitor_composite" {
name = "SLO sample - Burn rate Composite"
type = "composite"
query = "${datadog_monitor.slo_monitor_burnrate_14_4.id} || ${datadog_monitor.slo_monitor_burnrate_6.id}"
message = <<EOM
*A lot of the Error budget has been consumed*: [SLO Status & History](https://app.datadoghq.com/slo?slo_id=${slo_id})
*Please confirm Customer Impact, Investigation, and Mitigation from playbooks.
@slack-alert-channel
EOM
}
resource "datadog_monitor" "slo_monitor_burnrate_14_4" {
name = "SLO sample - Burn rate: 14.4, Long-window: 1h, Short-window: 5m"
type = "slo alert"
query = <<EOT
burn_rate("${slo_id}").over("30d").long_window("1h").short_window("5m") > 14.4
EOT
monitor_thresholds {
critical = 14.4
}
message = "Example monitor message"
}
resource "datadog_monitor" "slo_monitor_burnrate_6" {
name = "SLO sample - Burn rate: 6, Long-window: 6h, Short-window: 30m"
type = "slo alert"
query = <<EOT
burn_rate("${slo_id}").over("30d").long_window("6h").short_window("30m") > 6
EOT
monitor_thresholds {
critical = 6
}
message = "Example monitor message"
}CompositeモニターのqueryでそれぞれのBurn Rate Alertsを OR で計算しているため、いずれか一方で検知した場合でも両方で検知した場合でも1度だけ通知が来ます。

まとめ
この記事では、お客さま影響を検知してアラートを上げる方法や考え方についてご紹介しました。またお客さまの幸福度とサービスの信頼性との関係性やSLOに基づくアラート方法の紹介及び設定例を記載しました。
適切にアラートを設定することはサービスを利用するお客さまにとってはもちろん、サービスを開発/運用する我々にとってもとても重要なことです。この記事がサービスのSLOやアラートについて見直すきっかけになれば幸いです。




