※この記事は、Mercari Advent Calendar 2022 の15日目の記事です。
こんにちは。メルカリのPlatform DXチームの@masartzです。
今日はPlatform DX チームで取り組んでいる「開発に関わる指標の計測と可視化」に関して、いくつかの取り組みを具体例とともにご紹介していきます。
結論の項でも再利用するものを先にお見せします。

これはある期間におけるグループを横断したDeployment数の統計情報になります。
このような形で開発に関する情報の見える化とそこからのNext Actionを検討していこうというのが本記事のまとめになります。
取り組みの大枠 – DevStats Project
Platform チームによる指標計測の取り組みの歴史は古く、マイクロサービス移行の初期から行ってきました。社内ではDevStatsと呼ばれており、これまでも幾度か一端が公開されています。
- https://engineering.mercari.com/blog/entry/2019-12-23-084839/
- https://speakerdeck.com/b4b4r07/cloud-functions-in-go-at-mercari
上記記事でも触れられていますが、DevStatsによって計測したいものはDeveloper Productivityです。この指標はPlatformチームの最も重要なKPIです。Platformチームがマイクロサービス開発を行うDeveloper(= プラットフォームのユーザー)のために各種ツールを開発・提供するのは全てDeveloper Productivity向上のためです。最終的にサービスをお客さま(エンドユーザー)に届けるための力の源泉となるDeveloper Productivityにどれだけ寄与できるかを計測するための仕組みとしてDevStatsは作られ、運用されてきました。
継続的な運用のために技術的な変更も加えており、上記資料からの差分・更新点は主に以下の点です。
| データ収集(Collector) | データストア | 可視化 | |
|---|---|---|---|
| Before | Cloud Functions | Datadog | Datadog |
| After | Cloud Functions | BigQuery | Looker Studio |
データを永続的に管理したり、様々な結合を行うことを考慮してデータの収集先をDatadogからBigQueryに切り替えました。それにより可視化も担っていたDatadogの代わりにLooker Studioを用いています。
今回フォーカスする指標「Four keys」
本記事では、新たに計測した項目の中で、Four Keys のコンセプトに基づいて収集したその詳細をお伝えします。なお、これはグループ会社Souzoh 独自の取り組みとして、Souzoh内において同指標による計測を行った事例も参考になるので、ぜひそちらもご参照ください。
- https://mercan.mercari.com/articles/34283/
- https://engineering.mercari.com/blog/entry/20221116-souzoh-productivity/
Deployment Frequency
メルカリ グループのマイクロサービスはSpinnakerによってデプロイが行われています。この際にSpinnakerのイベントをトリガーとしたwebhookを設定可能です。このwebhookによってリクエストされる情報を受け口としてDevStats側に Collectorを実装・用意し、Spinnakerからのリクエストを受取り、どのマイクロサービスがいつデプロイされたかを記録します。
MTTR(Mean Time to Recover)
メルカリは全社的にIncident Management Toolを導入しており、サービスに何らかの障害が発生した際にはこのToolによってそれを管理しています。ツール上に障害発生時間や、お客さまへの影響が出始めた時間、障害が収束した時間などの記載項目があり、それらの項目から MTTRが自動計算されて管理されています。そのためデータソースとしてはこれを用いれば十分です。
しかし、このツールは webhook によるイベント送信に対応してなかったので、DevStats のCollector側から定期的に Incident Management ToolのAPI Callを行い、更新情報を取得して記録するという仕組みを構築しました。
このような形の定期的な情報更新処理はDevStats Collectorの典型例の一つであり、例えばPlatform チームがDeveloper向けに提供しているProductの使用Versionを分析するCollectorなども、定期実行で起動して集計処理をしています。
技術的には、Cloud Schedulerによって定期的にevent をPublishするとCloud FunctionsがPubSub triggerによって動作することで実現しています。
Change Failure Rate
前述の Deployment Frequency でデプロイ数、MTTR で障害の数、がそれぞれ導かれています。
そのため、これらを割り算することでChange Failure Rate(= 失敗数)を算出しています。
厳密には、Incident Management Toolに記録される障害の中には、一部デプロイに起因しないものも含まれますが、現段階ではそれらも含めた単純な計算になっています。当然精緻なデータの方が良いのですが、余分なデータを排除する対応のコスト面を鑑みての判断としています。一方で、データの分析結果の質を十分に担保できるかの判断はまだこれからです。
Lead time for Change
Lead time for Changeの説明として「commit から本番環境稼働までの所要時間」という説明があります。これに対して、メルカリの開発フローの主要な形は以下です。
- 開発(実装)開始
- Pull Requestを作成
- コードレビューと承認を受けた後、Pull Requestをマージ
- デプロイするタイミングで、Git tagをGitHubにプッシュ
a. CIがこれを検知して、同じタグがついたDockerイメージを作成 - Spinnakerを用いて、4. で作成されたDockerイメージをデプロイ
Pull Requestがmasterにmergeされた後、GitのTag発行及び新しいTagによるGitHub Releaseの作成を行い、特定のバージョニングされたDockerイメージをGoogle Container Registryに送っています。(一部異なる運用のリポジトリもあります)。なお、Git Tag&GitHub Release と Pull Requestの関係は 1:N になっており、どれくらいのPRをまとめるかはPRの性質含め、各チームの運用に任されています。
「commit から本番環境稼働までの所要時間」という指標定義に対して、起点となる「commit」を開発者として開発を終えた「Pull Request作成」時とするか、チームとしての開発終了の「Pull Request マージ」時とするかは議論の余地がありますが、今回は両方計測する事にしました。
以下の図において、それぞれの期間の定義を表しています。

- Mean Time for Review
- コードレビューに費やす時間
- Mean Time for Deploy
- デプロイ(まで)に費やす時間
- Lead time for Change
- 総合的に開発に費やす時間
特に Mean Time for Deployは、対象システム単体のパフォーマンスを測るだけでなく、その前処理にかかる時間の計測も可能です。ここに、他チームによるQAを必要としている、決裁者による承認を必要としている、などの技術面以外の課題が潜んでいる可能性もあります。
Lead time for Changeを知る上で必要な計測ポイントが決まったので、具体的に知らなければならないポイントを以下の通り整理しました。
- いつ PR が作られたか
- いつ PR がmergeされたか
- どのPRがどのDockerイメージ(= GitHub Release)に含まれるか
- いつ Dockerイメージがデプロイされたか
各項目の具体的な取得方法、そして統合方法についてそれぞれ見ていきましょう。
いつPRが作られたか、あるいはマージされたか
この情報は GitHubの Pull Request Event Webhookを使用することにより、取得可能です。
Deployment Frequencyの項と同様、Webhookを受け付ける Collectorを用意してやり、WebhookのPayloadから Pull Requestの created_at, merged_at の項目を抽出して記録します。
どのDockerイメージ(= GitHub Release)にどのPRが含まれるか
これはGitHub Releaseを起点として、調べる事が可能です。まず特定Releaseは特定のGit Tag versionと連動しており、そのTagの情報はWebhookのPayload内に含まれています。このTag versionから一つ前のTag versionの間のcommitの一覧を取得し、それぞれのコミットが紐づくPull Requestの番号がわかれば、該当のGitHub ReleaseつまりデプロイされるDockerイメージ と Pull Requestの紐付けができます。順を追って整理すると、
- GitHub Releaseが作成されたことを、Release Event Webhookを使用して取得します
- 該当Releaseに連動するGit Tagの情報はWebhook内に含まれているため、その一つ前のVersionのTag名を知るために、API CallによってTag一覧を取得します
- 一覧の中から、一つ前のTagを見つけた後、2つのTag Versionをパラメータとして、その間のcommit一覧を取得するAPIをcallします
- 得られたcommit一覧のそれぞれがどのPRに紐づくか判別するためのAPIをcommit数分だけcallし、ResponseからPR番号を取得します

これによって得られたPR の番号一覧を導くことによって、GitHub ReleaseとPR の関係性を明らかにし、それを記録するというのをCollectorの中で行いました。
いつDockerイメージがデプロイされたか
この情報は、実はDeployment Frequencyの計測と同じWebhookを契機としています。計測する指標が異なるため既存とは別のCollectorを用意しましたが、そのCollectorでやっていることは、どのマイクロサービスのどのGitHub Release(のDockerイメージ)が、いつデプロイされたかを記録することなので、Deployment FrequencyのCollectorとかなり近しいものになっています。
取得情報の統合
以下の図の通り、それぞれのCollectorがそれぞれのデータストアに記録したものをBigQueryのJOIN Queryによって統合することにより、最終的に導きたいデータが一つの固まりとなって現れます。

各マイクロサービスリポジトリへの計測機構の導入
上記までで、GitHub リポジトリの情報を取得することで Lead time for Changeの指標計測が可能であることがわかりました。そしてそのためにはWebhookの設定が必要でした。
この取組はプラットフォーム側からの全社横断向けのアプローチであり、対象のリポジトリは究極的には全マイクロサービスのリポジトリになります。それら全てに対して、都度Webhook設定をするのは現実的ではないため、GitHub Appを作成することとしました。
GitHub Appを用いることで、Webhookを発行するEventの選択や、リクエストするURLなどをAppの挙動として一箇所で設定することが可能です。また、Cloud Functions では GitHub からの webhook リクエストのみを受け付けるようにするためシークレットトークンを用いた保護を行うようにしていますが、GitHub App を用いることで、この設定も毎回リポジトリ単位で行う必要が無くなり、各リポジトリやその管理者が鍵管理をするなどのリスク・手間も排除することができます。結果として必要なのは「GItHub Appを各リポジトリにinstallする」だけになり、各リポジトリオーナーの手を煩わせることなくPlatform チーム側のみの作業で導入が可能です。
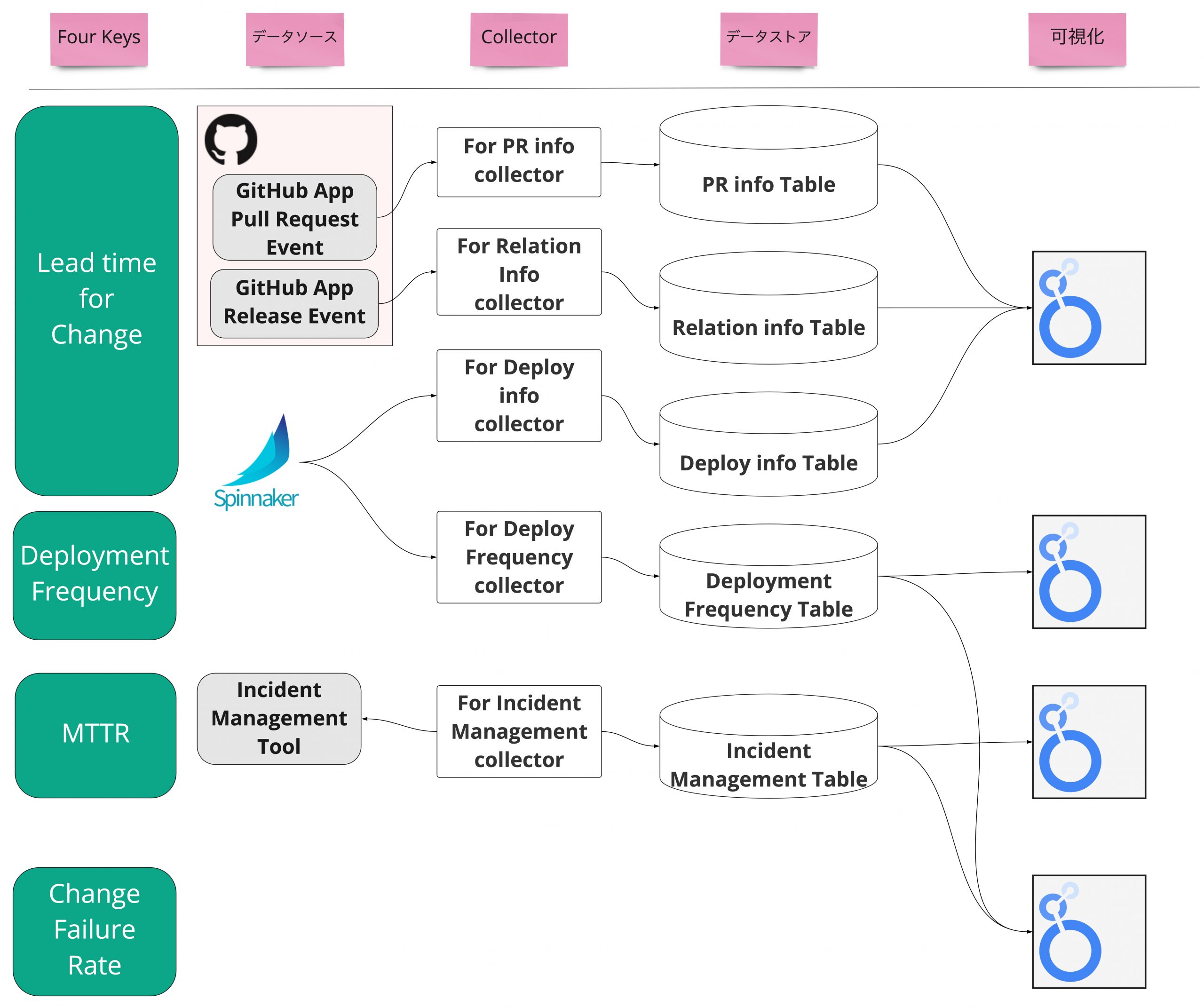
4指標を計測するためのアーキテクチャ概要
上記までで Four Keysに掲げられた指標を計測できるようになりました。
改めて、各指標、データ元、Collector、データストア、可視化 を一覧化すると以下の図のようになります。

計測した指標の可視化
以上の工程を経て BigQuery に蓄積されたデータは、Looker Studio を用いて可視化しています。
Looker Studioによる可視化はBigQueryとも相性がよく、手早く構築できるのが特徴です。
反面、設計したグラフ等をコード管理できないなど、メンテナンス面での課題はまだ残っています。
まとめ
本記事では、メルカリにて Four Keys を用いた開発指標の計測を行っていること、またそれぞれの指標を実際どのように計測しているのかを紹介しました。
このような指標は計測するだけでは意味はなく、それを元にアクションを起こせて初めて意義あるものとなります。現時点では実際にマイクロサービス開発を行うDeveloper(= プラットフォームのユーザー)への情報提供を行ったという段階です。
これを元に、このデータから何を読み取り、どう改善していくのかというアクションを最終的にDeveloperが自分たちで分析し改善していけるようにしたいです。
このサイクルを回す過程で、Developerからのフィードバックを得てさらに必要なデータを設計・提供し、改善していくようなサイクルを生み出していけるのがこの取組を継続していく上で理想の形ではないかと考えます。
もしこのような課題に興味を持っていただける方がいらっしゃれば、ぜひ以下のページをご覧ください!
明日は@darrenさんによる「Do We Need Engineers in a ChatGPT World?」です。引き続きお楽しみください!




