
Microservices Platform TeamでTech leadをしている@deeeeeeetです.
昨年のMTC2018ではMicroservices Platformチームの立ち上げから1年で僕らが取り組んできたことを紹介しました.
具体的にはStranglerパターンによるMonolithからMicroservicesへの段階的なリクエスト移行を行うためのAPI gatewayの開発や,Microservicesのインフラのセットアップを簡単にしサービス開発チームのSelf-service化を進めるためのStarter-kitの開発,GoでのMicroservicesの開発を高速で始めるためのTemplateプロジェクトの開発,Spinnakerの導入などについて紹介しました.
これらはPlatformとして最低限の機能を整備したにすぎず,さらなるDeveloper productivityの向上を目指してPlatformを進化させてきました.本記事でその後1年間でチームとして僕らが取り組んできたことを簡単に紹介したいと思います.
Platform上で動き始めたMicroservices
開発者がサービスが動かしてそのサービスがお客さまに価値を出してこそPlatformとしての意義があります.これはPlatformの初期からの思想であり,Platformを完成させる→ サービスを乗せるという段階的なやり方ではなくて,動かせるサービスを動かしながら同時に基盤を進化させるということをやってきました(スピード感を出せた一方で負債を負い古い方式からの移行が必要になることもありましたが…).
2019年はMercari側はMonolithへのコードへの変更を基本的に禁止するコードフリーズによってよりMicroservices化が加速し出品機能などがMicroservices化として切り出されてPlatform上で動き始めました(より詳しくは@stanakaさんによるメルカリのマイクロサービス移行の進捗 (2019年冬)を参考にしてください).そして2019年の2月にはMerpayもリリースされました.@tjunさんによるメルペイのマイクロサービスとCloud Native が詳しいですがMerpayは初期からMicroservicesとしてPlatform上で動かすように開発がされておりそれらも本番で動き始めています.
PlatformのベースとなるインフラにはKubernetesを使っていますが,現時点でのPlatformの規模感はNamespaceの数(=microservicesの数)では150+にPodの数は3000+にまで増えており,2020年もさらに増加していく予定です.
2019年の取り組み
以下では昨年の冬から2019年にかけてPlatformチームが取り組んできたことを一部ですが簡単に紹介します.
Production Readiness Check
MercariのMicroservicesではサービスチームがデザインから開発,QA,運用までのE2EのResponsibilityを担えるようにすることを目指しています(たまに誤解があるので書いておくと,全てをBackend Engineerに担ってもらいたいと思っているわけではなく,サービスの規模や特性に合わせてSREやQAやData scientistといった専門的なメンバーがチームにEmbeddedされていく,もしくはチームに専門の役割のひとを立てる,採用していくのが一番の理想だと思っています).しかしいきなりサービスチームに本番運用をやる・それに耐えうるアプリケーションを書くのは非常に大変なことです.一方で大量に開発されていくMicroservices開発にPlatform teamが入り適宜その補助をすることも現実的ではありません.
このような課題を解決するために始めたのがProduction Readiness Checkとそのレビューです.MaintainabilityやObservability,Reliability,Security,Accessibilityといった複数の観点から本番運用のためにアプリケーションが満たすべきことをチェックリストとして準備し,Github Issueベースでそのチェックのレビューを依頼するという仕組みを作りました.例えばチェックとしてはKubernetesに関してPod Disruption Budgets(PDB)をちゃんとセットしてるか? やDatadogのTimeboardとScreenboardを準備しているか? などがあります.サービスチームは本番Release前にこれらのチェックを満たしPlatform team(現在はArchitect team)に依頼を投げ,レビューが完了して初めて本番へReleaseが可能になります.この仕組みによりある程度のReliabilityを担保でき,かつPlatformとしても自動化が追いついていないことをチェックとしてある程度強制していくことも可能になりました.

一方で1年近く運用して多くの課題も出てきました.例えばProduction Readiness Checkを満たすアプリケーションの開発に時間がかかりすぎること(50近くの項目がありサービス開発をしつつそれらを満たすのは大変です…),レビューに時間がかかること,最初のリリースでしかチェックができておらず継続的なチェックができていないことといった課題が挙げられます.これらの多くはより基盤としての抽象化や自動化を進めることで解決できると思っています.例えば最低限のMonitroing dashboardは自動でBootstrapしたり,このあと触れるService meshによってコードで解決している部分をなくしていくといったことに取り組んでいます.もちろんレビュー自体の自動化も考えています!
Secure Container Supply Chain (Kritis)
Securityと一言に言っても多くの次元があります.IAM管理からネットワーク構成,Node・ContainerレベルのAttack surfaceの最小化やIsolationの強化などなど…中でもMicroservices化により,そしてContainer化により様々な種類のアプリケーションが,より高頻度にデプロイされるようになったため,予期したイメージのみが決められた場所にデプロイされることを担保することが非常に重要になってきました.そのためまず我々が今年に注力したのはContainer supply chainのSecurityです.Container supply chainとはざっくりいうとContainerイメージのBuildからそれに対する様々なテスト,そしてDeployするまでのPipelineのことです.
Container supply chainにおけるセキュリティ強化の構成でよくあるのはCI/CD Pipelineの1ステージでセキュリティチェックを行い,予期しないもしくは脆弱なContainerが見つかったときにPipelineを失敗させてデプロイを止める方式です.しかしこれは最終的なデプロイの権限をもつアカウントがCompromiseされた時に何の意味もなくなるという問題があります(以下の図が分かりやすいです.どれだけPipelineでチェックを強化しても最後の最後で無になる…).

Secure Software Supply Chains on Google Kubernetes Engine (Cloud Next ’19)
これらの課題解決するためそして将来的な拡張性を考慮して導入したのがKritisとGrafeasです(より具体的にはGrafeasではなくてそのAPIを持ったGoogle Container Registry(GCR)のContainer analysis APIを使っています).KritisとGrafeasの動作を簡単に説明すると,まず各CI/CD PipelineのStageではそのチェックの結果に応じてメタデータをGrafeasに送りつけます.例えばContainerイメージのSecurity scanを行いその結果をGrafeasに保存します.KritisはKubernetesのAdmission webhookとして実装されており,デプロイのManifestがApplyされた直後に呼ばれます.そこでKritisはGrafeasに問い合わせを行いそのイメージに対して予期するチェックが行われたか否かを確認します.もしされていればデプロイを継続し,そうでなければデプロイを失敗させます.例えば,QAとSecurity scanを通して欲しければそれを指定しておきKritisにチェックさせます.これによりデプロイの権限を攻撃者に奪われたとしても,予期したチェックを通っていない任意のイメージをKubernetes clusterにデプロイすることはできなくなります

現状の僕らの使い方は非常にシンプルです.既にいくつかの発表で述べているように僕らのKubernetesはMultitenant構成にしておりMicroservicesごとにNamespaceを準備しています.さらにStatefulなサービスはKubernetes上には載せないでGCPのmanaged serviceを使うようにしており,各ServiceごとにGCP Projectも準備しています.そしてコンテナも各GCPプロジェクトのGCRに置いてもらうようにしています.Kritisはこれを強制しています.つまりあるNamespaceへデプロイできるイメージをそのNamespaceに紐づくGCRにあるイメージに限定しています.これにより少なくともチームが管理していないイメージをそのNamespaceにデプロイできなくしています.
GrafeasとKritisは長期的にみた拡張性に期待しています.Grafeasはコンテナイメージに対して様々なメタデータを付与できます.例えばQAチームがテストをしその結果をメタデータとして保存することもできるし,セキュリティチームがContainerイメージをScanして結果をメタデータとして保存することも考えられます.そしてKritisはそのメタデータを自由に組み合わせてPolicyを作ることができます.例えばシンプルなPoCのサービスであれば最低限のチェックが通ってればデプロイを許可し,Merpayにおいて非常にセキュアなサービスは厳密なチェックを強制することもできます.Platformとして強いと思うのは,僕らが関わる必要がないことです.僕らが気にするのはデフォルトで強制するべき部分のみで,サービスチームはその特性に応じてメタデータもPolicyも自由に追加して進化させていくことができます.
ただKritis自体が未成熟である課題もあります(僕らはForkして使っています).GCPのManaged版であるBinary Authorizationの採用も考えましたが,当時はClusterレベルのチェックしかできずNamespaceレベルの細かな制御ができなかったので採用を見送りました.将来的にはBinary Authorizartionに移行するか,もしくは自分たちでKritisに相当するものを書くか?という意思決定が必要になると感じています.
より詳しくは@vbanthia_のSecuring microservices continuous delivery using grafeas and kritis を参考にしてください.
Service mesh (Istio)
Microservices化が進むほど,分散システム化が進むほどネットワークに起因する問題は多くなってきました.特にKubernetes ServiceはLBとしてはL4レベルで最低限の機能しか提供していないため,よりReliableなサービス間通信を実現するためには自分たちで解法を準備する必要があります.例えば僕らはサービス間通信にgRPCをメインに使っていますがそのロードバランシングのためにClient side LBをライブラリとして実装したりしています.これ以外にもインシデントが起こる度に適切なTimeoutやRetry,APIのRate limit,Circuit breaking機能が必要だという声があがるようになりました.
MercariとMerpayのMicroservicesは基本的に全てGoで実装しており現在はPolygrotへの志向は持っていません(特に初期は技術を統一してその上で仕組みを構築することが大切だからです).一方で,どうしてもGoのみでは十分でないところもあります.フロントエンドのためにNode.jsを使う,MLのモデルのServingのためにPythonを使うといった要望が挙げられます.これらの言語の要望に合わせてライブラリを開発してメンテナンスしていくには大きなコストがかかります.Goだけでも非常に大変です…
これらの課題を解決するためそして将来的な多くの利用事例を考えService mesh Istioに投資していく意思決定をしました(Service meshについてはService meshとは何かに書きました).より詳しくは@vbanthia_のAdopting Istio for a multi-tenant Kubernetes cluster in Productionを読んでもらいたいですが,Istioがまだ成熟していないこと,Kubernetes clusterがMultitenant構成でありSelf-serviceによる各チームの自立性を重視していることなどを考慮して段階的にIstioを導入することに決めました.
段階的な導入として僕らが採用した戦略はまずMeshの構築のみに集中することです.Istioが提供する機能は何一つ開発者には提供しないで単純にSidecarコンテナを入れるか否かのみを設定できるようにしました.これによってIstioの複雑なCRDの管理のことは一旦忘れていかにReliableにMeshを構築するかに集中することができました.例えばSidecarコンテナと言っても現状Kubernetesから見るとそれはメインのコンテナと違いはありません(SidecarコンテナをSidecarとして扱えるようにするという実装は進んでいます).そのため厳密にSidecarコンテナの起動の順番を制御しないとデプロイの際にリクエストを落としてしまうことがあります.導入前にこのような問題は全て洗い出して解決しました.
Meshの構築のみに集中することで管理するべきコンポーネントを減らすことができます(現状はSidecar injecterとPilotしか使ってない).コンポーネントを減らすことで問題が起こったときの原因特定が容易になります.また少ないコンポーネントでIstio自体のオペレーションに慣れつつ,一つ一つのReliabilityの改善に投資することもできます.Istioを導入して半年位経ちましたが未だに起こるバージョンごとの破壊的な変更やインストール方法の混乱などを見ていると段階的な方式は正解だったと感じています(現状僕らはバージョンを上げるのはそこまで難しくない).
来年はDevelopr Surveyや要望に応じて段階的に機能を開放していく予定です.
DevStats
Microservices PlatformのMissionはメルカリグループ開発者がよりサービスを速くReliableにお客様に提供することができるようなPlatformをつくることです(詳しくは開発者向けの基盤をつくるで話しました).Platformを作るにあって特に僕らはDeveloper productityを非常に重要なKPIと考えています.もちろんこれまで要望や皆が抱える問題を初期衝動として改善を重ねきたつもりですがそれを具体的な数字として可視化することができていませんでした.あるプロジェクトによりちゃんとProductivityが改善されているかを客観的な数字で見て振り返り,次のプロジェクトのPriorityの意思決定に繋げないと意思決定が個人の考え方などに偏ってしまったり,本当に顧客の欲しかったものからかけ離れてしまう可能性があります.
この課題を解決するために作り始めたのがDevStatsです.これはMicroservicesの各コンポーネントからあらゆる情報を引っこ抜いてきて一箇所に集約して可視化する仕組みです(今は集約先にDatadogを利用しています).例えば僕らはDeveloper Productivityの可視化としてAccelarateでも使われていたDeploy per developer per dayという指標を使っています.この可視化を実現するためにSpinnakerやTerraformのCIなどDeployに関わる全てのコンポーネントにAgentを仕込みデプロイ情報をDatadogに集めてグラフ化しています.
この仕組はまだ動き始めたばかりで改善が必要ですが,今後Platformの意思決定のための重要な要素になっていくと考えています.より詳しくは@babarotによるマイクロサービスの成果を可視化するCloud Functions in Go at Mercariを参考にして下さい.
Network Re-design (GCP Shared VPC)
Platformを始めた人(@deeeet)がとても未熟だったのでこれまでGKEのNetworkはGCPのDefault networkで作られていました.Merpayのリリースも終わりReactiveな機能だけでなくより長期を見てProactiveにPlatformを拡大していくことを考えたときにネットワーク構成が大きな障害になりました.
今後の拡大として僕らが現状考えているのは,HomogeneosなMulti-cluster構成(同じClusterを複数立ててHA構成にする)やMicroservices Platform以外が持っているGKE clusterとのプライベートな接続,Multi-regional構成,AWSとのHybrid cloud構成などです.それらを全て踏まえてゼロからNetworkの再設計を行いました.具体的には以下の図のようにShared VPCを使い全てのネットワークを司るGCPプロジェクトとその管理コンポーネントを準備し(今はPlatformチームが管理していますが将来的にCloud networkチームができることを想定しています)それらが全てのサービスプロジェクトとメルカリグループMicroservices全体のプライベートIP空間,そしてCloud間通信を集中管理するというものです.

より詳しくは@lainraによるNetwork Architecture Design for Microservices on GCPを参考にして下さい.
GKE Cluster Recreation & Migration
GKE clusterを構築して既に2年以上に渡って運用をしてきました.Platformも進化してきましたがGKE自体も多くの機能がリリースされました.多くの機能はそのまま使えますが,中にはClusterを作り直す必要があるものもあります.例えばRoutes-based clusterをVPC native clusterにZonal clusterをRegional clusterにするには作り直しが必要です.特にVPC native clusterは大きな変更で,いくつかの機能がVPC native Clusterであることを前提に作られ始めています(例えばNEGsなど).また上述したShared VPC構成への移行もClusterの作り直しが必要です.
現状GKE cluster上には100を超えるMicroservicesが動いています.Clusterの作り直しはこれらを動かしつつサービス開発に影響を与えない形で行う必要があり簡単なことではありません(飛行機で乗客を運びつつそのメインエンジンを入れ替えるようなものです).しかしさらなるScalabilityとAvailabilityのため,GKEとその周辺のGCPサービスの恩恵を受けるため,そして何よりPlatformの今後のさらなる発展のためにGKE Clusterの作り直しとその移行を行う意思決定をしました.
このプロジェクトは動き始めて既に半年以上が経っておりまだ終わっていません.より詳しい話はプロジェクトが完了した時点で公開しますが,シームレスな移行(完全な自動化)にはコストがかかりすぎるためある程度の自動化+筋肉という選択肢を取っています.特にGKEを触る複数のコンポーネント間(TerraformやKubernetesのmanifestを管理するCI/CDやSpinnaker)の統一ができていないことが大きな課題として上がってきました.移行後は筋肉でやるしかなかった部分を課題としてその改善に投資する予定です.まあ後発の人言えることはただ1つ.いつでも作り直して移行できるように設計しておけ!!
働き方改革
上で紹介したようなプロジェクトはどれも大きなプロジェクトであり,決して個人の力でどうにかなるものではありません.チームとして同じVisionを見てAlignし,PlatformをProductとして見てProduct managementをし,決めたプロジェクトを確実に進めるProject managementをする,チームが決められたタスクに集中できる環境を用意するといったことが非常に大切です.Plattformチームはこのような働き方も常にチームで改善してきたチームです(僕らがどのようにプロジェクトの進め方を改善してきたかは How We Structure Our Work At Mercari Microservices Platform Teamで話しました).
これに関しては別途ブログを書く予定ですが,今年やったこととしてはPlatformチームのMissionとVisionを明確に定義すること,そのVisionとDeveloper surveryにより向こう3年のRoadmapを決めること,Roadmapをもとに次の半年のチームの目標を立てること(四半期では短すぎる…),そしてその目標を達成するために6-week release cycleによりプロジェクトを回すこと,などをやりはじめました.「やるべきこと」と「やりたいこと」は無限にあるのでその中で何に優先度をつけるかはとても大切です.今の仕組みではそれがうまく決められつつあると思います.また長期でものを考えることで日々の意思決定も改善できました.例えばこの機能Aをつくるときに,将来XをやることになるからAはこうしておいたほうが良いなど.これらもまだまだ改善の余地があります.
課題
最後に現状の僕らが抱えている課題をいくつか紹介します.
New feature adaptation
1つ目の課題は新しい機能の推進です.「KritisやIstioを入れて使えるようにしました!」と言っても皆が使い始めてくれるわけでありません.Platformとしてはそれが重要だと分かっていても,日々プロダクト開発に追われているサービスチームからすればそのメリットや意義をちゃんと理解してもらわないと導入の優先度は上げてもらえません.公式ドキュメントがあるからそれを読んでくれ!というもの通用しません.数十人のエンジニア組織であればそのような問題はないかもしれませんが,今のMercariのように数百人規模の組織では避けられない問題です.皆にその重要性を理解してもらい自律的に動いてもらうにはどうするべきか?はPlatformとしてちゃんと考えなければいけない問題です.
この課題を解決するためにはPlatform チームがより社内のAdvocateとしての役割を強くしていく必要性を感じています(もちろん専門の人を雇うことも考慮しつつ).機能を作って終わりではなくてそれを広げることまで責任を持つこと,プロジェクトの見積もりもそこまで考えて設定することが大切だと思っています(これは元GoogleのSREの@lizthegreyもCode less, engineer moreで同様のことを言っています).もちろん自動化による開発チームの手を借りないで移行を行うような仕組みを設計から考えることも大切です.
Operation maturity
PlatformをやりつつMicroservicesによるSelf service化を進めたことで辿りつた1つの課題は「オペレーションの成熟度はツールを提供するだけでは改善しない」ということです.これは同様のことをSREとして推し進めているNew York TimesのSREも同じことを言っています.
これは新機能の推進と似た課題です.SpinnakerやIstio,Vaultといったツールを提供するだけオペレーションやReliabilityが改善されるわけではないです.むしろツールに圧倒されて逆に使われてしまう可能性もあります.これは自分たちで運用するツールだけではなくてSaaSにも同様のことが言えます.Datadogを入れるだけ,PagerDutyを入れるだけで意味がなくそれらをしっかりと使い倒してこそ意味があります.
この課題の解法は上と似ていますが社内トレーニングやワークショップなどをやっていくこと考えています.また組織としてもよりEmbedded SRE(各ドメインに特化してReliabilityに責任をもつSRE)というロールの必要性が増していると感じています(以下のようなイメージが良いのではないかと思っています).

Too many tools and team growth
最後はPlatformチーム内の課題です.KubernetesからIstio,Spinnaker,Kritis,VaultなどなどPlatformが管理しているコンポーネントの数はかなり増えてきました.現状は1チームとしてこれらを管理してしまっておりチームとして考えることが多くなりすぎています.またチームの数も10人になりよりコミュニケーションコストも高まっています(以下の図がわかりやすい)
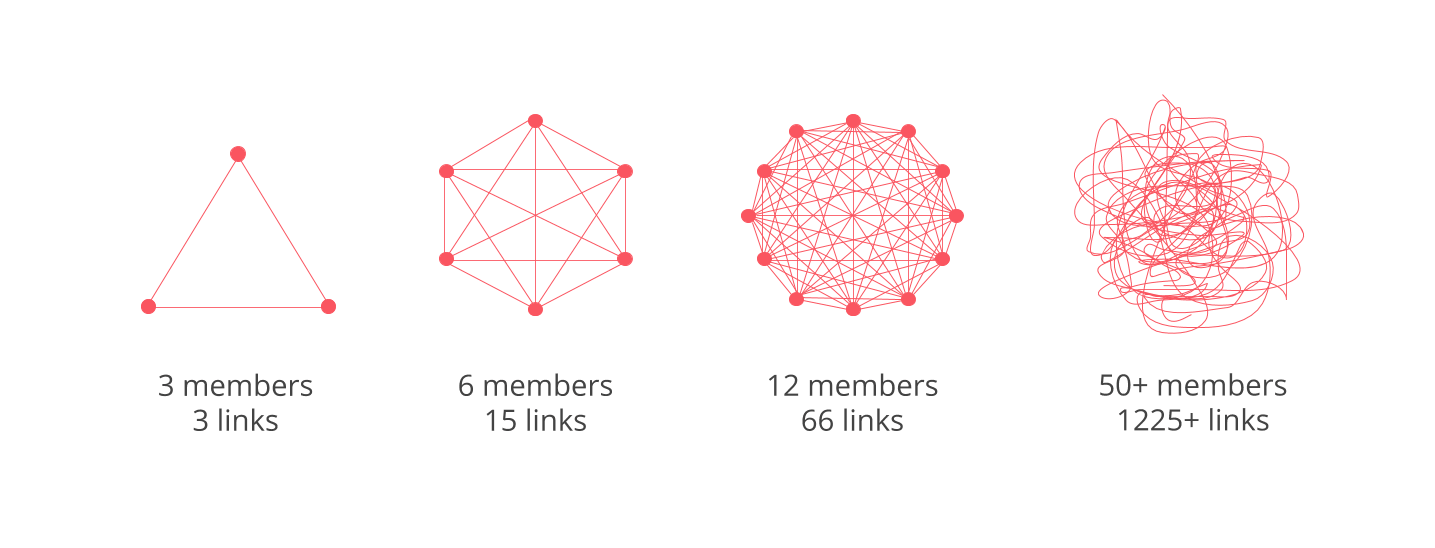
これらの課題を解決するためPlatformチーム内を専門的なチームに分割していく必要があると思っています.チームごとに管理するべきコンポーネントを明確に分け,それぞれのチームで自律的にそれぞれの問題にフォーカスできるような体制をつくる必要があります.これに関してはKubernetesコミュニティのSpecial Interested Group(SIG)のやり方が参考になると思っています.
今後の展望
最後に今後のPlatformの展望についていくつかアイディアを簡単にまとめます.まずより抽象化を進めること,Microservices Platform on Kubernetes at Mercariでも話したようにKubernetesに期待することはその拡張性です.MercariやMerpayのMicroservicesに適した抽象化を提供するMercari PaaS的なものを作れないかと考えています.また上述したように僕らはメルカリグループ全体のProductivityを考えています.今はJPのことをメインに考えていますがUSの開発に関してもより協力体制をもちGlobal Platformとなること目指しています(実験的にサポートは始めています).またProductivityだけではなくFlexibilityもPlatformとして重要なファクターだと思っています.例えばGCPだけではなくAWSのサービスもMicroservicesで使えるようにすること,Go以外の言語もシームレスに使えるようにすることなどを今後は考えていきたいと思っています.
最後に
最近読み始めたSoftware Engineering at Googleにはソフトウェアエンジニアとプログラマーの違いが明確に定義されています.「Software Enginnering is programing integrated over time(時間経過を考慮したプログラミングをするのがソフトウェアエンジニアです)」つまりコードを書くときにその長期的な運用やメンテナンス,チームでの開発を考えるのがソフトウェアエンジニアです.Platform チームは特にこれを真剣に考えなければならないチームです.低レイヤーであるからこそその変更は難しく,何気なく書いたコードが思いもよらずに長期的に利用される可能性があり,それが負債になってしまうこともあります.2年にわたりPlatformをやってきてこの定義の重さを実感しています.
今のPlatformチームに求められているのは0を1にすることではなく100を1000に1000を10000にする「ソフトウェアエンジニア」です.もしこのような仕事に興味を持ちより具体的なRoadmapなどを聞きたい方は是非連絡をください.




