
この記事は、Merpay Advent Calendar 2022 の14日目の記事です。
こんにちは。メルペイ Solutions チームの orfeon です。
メルペイ Solutionsチームはメルペイに限らず社内のプロジェクトでデータ処理が必要になった際にすぐに活用できる汎用的なデータパイプラインをいくつか提供しています。
本記事ではメルカリの Marketing Platform チームと協力して、お客さまの行動に応じてニアリアルタイムにインセンティブ付与を行うために Cloud Dataflow で Beam SQL を活用した例を紹介します。
背景
メルカリでは出品促進など様々なキャンペーンを実施しています。
キャンペーンでは新規会員登録や商品の出品・購入など、お客さまが事前に定義された特定の行動条件を満たしたタイミングでポイントなどのインセンティブを付与します。
キャンペーンの効果を高める上で、お客さまが必要なアクションを起こした際に即座にインセンティブを付与することが大事です。
そのためには大量のお客さまの行動を追跡してルールにマッチするかリアルタイムに判定する必要があります。
またキャンペーンの実施にあたっては、マーケターが考案したキャンペーンの内容をデータパイプラインに落とし込む必要があります。
キャンペーンごとにデータパイプラインを個別に開発していたのでは開発・動作確認に時間が掛かってしまいます。
そのためキャンペーン内容を迅速にパイプラインに変換できる仕組みが必要になります。
キャンペーンに用いるデータパイプラインシステムには、マーケターがキャンペーン内容を定義しやすい簡易性とインセンティブを付与するさまざまな条件を定義できる柔軟性も求められます。
システム構成
こうした要件を満たすデータパイプラインシステムを実現するために、サーバレスなデータ処理サービスであるCloud Dataflowを使った仕組みを採用しました。
以下の図は今回構築したシステム構成の概要になります。
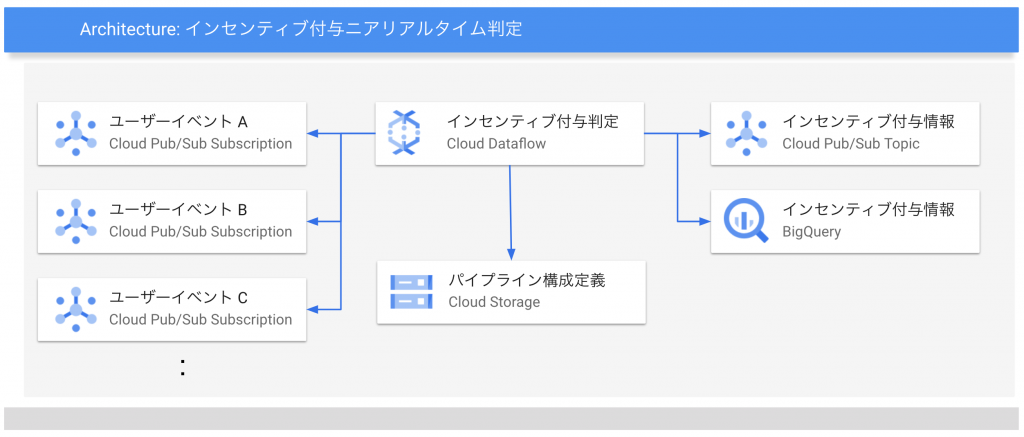
Cloud Dataflowで開発したデータパイプラインが各種ユーザイベントデータをCloud Pub/Subから受け取り加工・集計を行いインセンティブ付与判定をニアリアルタイムにおこないます。
その結果をお客さまに対してインセンティブ付与を行うマイクロサービスが利用できるようPub/Sub トピックに配信したりBigQueryのテーブルに保存します。
Cloud Dataflow によるデータパイプラインはFlex Templateという形態でデプロイされます。
Flex TemplateはCloud DataflowのJobを開始する際にデータ処理グラフを実行時のパラメータに基づいて動的に構成することができる仕組みです。
これによりキャンペーンごとにコード修正を行うことなくインセンティブ判定のためのデータパイプラインのJobを実行することができます。
データパイプラインの実装
Cloud Dataflowによるデータパイプライン実装には以前ブログ記事で紹介した Mercari Dataflow Template を利用しました。
Mercari Dataflow Template はFlex Templateの機能を利用することで、データ処理内容を定義したJSONファイルからDataflow Jobを生成することができるOSSです。
処理内容を定義するJSONファイルでは事前に準備された様々な組み込みモジュールにパラメータを指定して組み合わせます。
キャンペーンでの利用では、内容によっては差分もありますがおおむね以下のモジュールを使って処理を行っています。
- Cloud Pub/Sub source module
- Union transform module
- Window transform module
- Beam SQL transform module
- Cloud Pub/Sub sink module
おおまかにはCloud Pub/Subから取得した各種イベントデータをひとつにまとめて、インセンティブ判定処理をイベントデータ到着ごとに行うように設定した上で、SQLによるインセンティブ判定を実行し、判定が出たものがあれば出力用のPub/Subに配信する、という処理の流れとなっています。
ここでは各モジュールでどのように処理が行われていくのか、以下の条件でインセンティブ付与を判定する架空の例を用いて説明します。
新規会員登録から24時間以内にキャンペーンに参加したお客さまが
24時間以内に出品を行った際にポイントを付与する。
初回出品時は1,000ポイント、その後4回まで出品ごとに100ポイントを付与する。ここから各モジュールごとに処理内容について説明します。
Cloud Pub/Sub source module
インセンティブ付与判定のためにはお客さまに関する様々なイベントデータが必要になります。
システムの入力となるCloud Pub/Subからメルカリ・メルペイの様々なマイクロサービスから配信されるイベントデータを取得しています。
イベントデータはイベントごとに割り当てられたトピックにそれぞれ配信されています。
1つめのCloud Pub/Sub source module ではインセンティブ付与の判断に必要なイベントデータをこれらのCloud Pub/Subのトピックから取得します。
今回の例では、以下3つのイベントデータを各Cloud Pub/Subトピックから取得します。
- お客さまの新規会員登録イベント
- お客さまのキャンペーン参加イベント
- お客さまの出品イベント
各イベントデータは以下のようなスキーマのJSON形式で取得されるものとします。
# 新規会員登録イベント
{
"user_id": 1,
"event_type": "event_registration",
"timestamp": "2022-12-14T15:00:00Z"
}
# キャンペーン参加イベント
{
"user_id": 1,
"event_type": "event_entry_campaign",
"timestamp": "2022-12-14T15:01:00Z",
"campaign_name": "campaign_A"
}
# 出品イベント
{
"user_id": 1,
"event_type": "event_listing_item",
"timestamp": "2022-12-14T15:02:00Z",
"item_id": "A"
}いずれのイベントも、イベント種別を示すevent_typeと、お客様の識別子を示すuser_id、そのイベントが発生した日時を示すtimestampフィールドを持っています。
キャンペーン参加イベントはそれに加えてキャンペーン識別名のcampaign_nameフィールドを、出品イベントは出品された商品の識別子となるitem_idフィールドをそれぞれ持っています。
Union transform module
2つめのUnion transform module では、先に紹介した異なるスキーマをもつ3種のイベントデータをスキーマをそろえてこの後に続くモジュールで単一スキーマの入力として扱えるよう結合します。
今回の例では3種のイベントデータは以下のスキーマを持つイベントデータに変換されます。
{
"user_id": 1,
"event_type": "xxx",
"timestamp": "2022-12-14T15:00:00Z",
"campaign_name": "CampaignA",
"item_id": "A"
}ここでは各入力のスキーマの全てのフィールドを持つスキーマとして結合されています。
これは各入力固有のフィールドがあった場合はNULLABLEなフィールドとして結合後のスキーマに追加されます。
各入力スキーマで名前が同じで型が異なるフィールドがない限りは問題ない変換になります。
異なるスキーマを持つ入力を単一の入力として扱うことで、このあとのBeam SQL transform moduleで指定するSQLを簡素化することができます。
なお、同様の処理のために、Beam SQLで UNION ALL などのサブクエリを実行することもできます。しかしこのあとのWindow trarnsform moduleによる設定を一回ですませ、データパイプラインをシンプルにできるメリットもあるためこちらのモジュールを今回利用しました。
Window transform module
3つめの Window transform module では直後のBeam SQL transform module で集計処理を行う際のトリガーと蓄積モードを設定しています。
バッチで処理を行う際に意識することは少ないのですが、ストリーミング処理である範囲のデータで集計処理を行う場合、どのタイミングで集計を実行するか意識しなければならないケースも出てきます。
今回の例ではイベントが発生するたびにお客さまがインセンティブ付与条件を満たしたかどうかを判定する必要があります。
そのためトリガーとして、入力データが(最低でも)1つ到着するたびに後段のBeam SQLを実行するように設定を行っています。
蓄積モードでは処理を実行した際にそのタイミングで処理に使った入力データを残すかどうかを設定します。
今回の例ではインセンティブ判定でお客さまの過去のイベントデータが必要となるため、蓄積するよう設定します。
なお時間範囲は今回のキャンペーンにおいて特に固定的な時間枠がないためGlobal Windowを指定しています。
(トリガーや蓄積モードの詳細につきましてはApache Beam のドキュメントを参照ください)
BeamSQL transform module
4つめの Beam SQL transform module ではイベントデータを単一のテーブルとみたてて指定されたSQLを用いてインセンティブ付与を満たす判定ロジックを実行します。
Beam SQLはApache Beamによる独自SQL拡張で、BigQueryでなどで用いている標準SQLに比べて利用可能な関数などで一部制限があります。
ここではお客さまごとにインセンティブ判定を行うために以下のようなSQLを指定します。
WITH
withAdditionalFields AS (
SELECT
*,
IF(event_type="event_registration", timestamp, NULL) AS registration_time,
IF(event_type="event_entry_campaign" AND campaign_name="CampaignA", timestamp, NULL) AS entry_time,
IF(event_type="event_entry_campaign", campaign_name, NULL) AS campaign_name,
IF(event_type="event_listing_item", timestamp, NULL) AS listing_time,
IF(event_type="event_listing_item", item_id, NULL) AS listing_item_id
FROM
Inputs
),
grantedIncentive AS (
SELECT
user_id,
MAX(registration_time) AS registration_time,
MAX(entry_time) AS entry_time,
MAX(listing_time) AS latest_listing_time,
MAX(item_id) AS latest_listing_item_id,
FROM
withAdditionalFields
WHERE
event_type IN UNNEST(["event_registration", "event_entry_campaign", "event_listing_item"])
GROUP BY
user_id
HAVING
entry_time > registration_time
AND latest_listing_time > entry_time
AND TIMESTAMP_DIFF(entry_time, registration_time, HOUR) < 24
AND TIMESTAMP_DIFF(latest_listing_time, registration_time, HOUR) BETWEEN 0 AND 23
)
SELECT
user_id,
COUNT(latest_listing_item_id) AS listing_count,
CASE COUNT(latest_listing_item_id)
WHEN 1 THEN 1000
WHEN 2 THEN 100
WHEN 3 THEN 100
WHEN 4 THEN 100
WHEN 5 THEN 100
ELSE 0 END AS incentive
CURRENT_TIMESTAMP() AS granted_timestamp
FROM
grantedIncentive
GROUP BY
user_id
HAVING
listing_count <= 5SQLの内容について説明します。
WITH句の最初のクエリである withAdditionalFields ではこのあとの処理ために、UNIONにより一つに統合された3種のイベントから種別ごとにtimestampなどのフィールドを種別と紐づけて抽出しています。
次の grantedIncentive クエリでは3種混在するイベントをお客さまごとに集計してインセンティブ付与を判定します。
お客さまごとに集計を行うためにGROUP BY句でuser_idを指定していますが、先に行ったトリガー設定によりイベントが到着するたびに集計が実行されます。
インセンティブ付与条件を判定するために、以下の集計結果によるフィルタをHAVING句で指定しています。
- 会員登録後に今回のキャンペーンにエントリーしたこと
- キャンペーンエントリーが会員登録後の24時間以内であること
- 最新の出品がキャンペーンエントリーした後であること
- 最新の出品が会員登録後の24時間以内であること
このクエリにより、インセンティブ付与対象となるイベントであるかを判定します。
最後のクエリでは、インセンティブ付与対象となるイベントに対して付与するポイントを計算しています。
先に設定したトリガーは集計を含むサブクエリがあった場合、いずれのクエリでも同じ設定で実行されます。
grantedIncentiveでインセンティブ付与条件を満たす出品があるたびに、お客さまごとに有効な出品数をカウントしてその数に応じてポイントを付与しています。
PubSub sink module
最後の Cloud PubSub sink module ではBeam SQLによりインセンティブ判定が出た場合に指定されたCloud Pub/Subトピックに配信されます。
実際にお客様にポイントを付与するサービスはこのトピックからメッセージを取得利用します。
なお、判定結果のロギングなど必要に応じてBigQuery sink moduleなども出力先として設定します。
以下が今回の例の Mercari Dataflow Template の全体のconfigファイル設定例になります。
(Beam SQLモジュールのsqlパラメータはSQL文をGCSに保存して参照しています)
{
"sources": [
{
"name": "pubsubEventRegistration",
"module": "pubsub",
"parameters": {
"subscription": "projects/xxx/subscriptions/event-registration",
"format": "json"
},
"schema": {
"fields": [
{ "name": "user_id", "type": "string", "mode": "required" },
{ "name": "event_type", "type": "string", "mode": "required" },
{ "name": "timestamp", "type": "timestamp", "mode": "required" }
]
}
},
{
"name": "pubsubEventEntryCampaign",
"module": "pubsub",
"parameters": {
"subscription": "projects/xxx/subscriptions/event-entry-campaign",
"format": "json"
},
"schema": {
"fields": [
{ "name": "user_id", "type": "string", "mode": "required" },
{ "name": "event_type", "type": "string", "mode": "required" },
{ "name": "timestamp", "type": "timestamp", "mode": "required" },
{ "name": "campaign_name", "type": "string", "mode": "required" }
]
}
},
{
"name": "pubsubEventListingItem",
"module": "pubsub",
"parameters": {
"subscription": "projects/xxx/subscriptions/event-listing-item",
"format": "json"
},
"schema": {
"fields": [
{ "name": "user_id", "type": "string", "mode": "required" },
{ "name": "event_type", "type": "string", "mode": "required" },
{ "name": "timestamp", "type": "timestamp", "mode": "required" },
{ "name": "item_id", "type": "string", "mode": "required" }
]
}
}
],
"transforms": [
{
"name": "unionEvents",
"module": "union",
"inputs": [
"pubsubEventRegistration",
"pubsubEventEntryCampaign",
"pubsubEventListingItem"
],
"parameters": {}
},
{
"name": "eventsWithWindow",
"module": "window",
"inputs": [
"unionEvents"
],
"parameters": {
"type": "global",
"unit": "second",
"accumulationMode": "accumulating",
"trigger": {
"type": "repeatedly",
"foreverTrigger": {
"type": "afterPane",
"elementCountAtLeast": 1
}
}
}
},
{
"name": "grantIncentive",
"module": "beamsql",
"inputs": [
"eventWithWindow"
],
"parameters": {
"sql": "gs://xxx/beamsql.sql"
}
}
],
"sinks": [
{
"name": "pubsubOutput",
"module": "pubsub",
"input": "grantIncentive",
"parameters": {
"topic": "projects/xxx/topics/granted-incentive",
"format": "json"
}
},
{
"name": "bigQueryOutput",
"module": "bigquery",
"input": "grantIncentive",
"parameters": {
"table": "xxx:monitoring.incentives",
"createDisposition": "CREATE_IF_NEEDED",
"writeDisposition": "WRITE_APPEND"
}
}
]
}今後の課題
本システムは実際の出品促進キャンペーンにて稼働しました。
2週間のキャンペーン期間中稼働し、インセンティブ判定は大部分がほとんど遅れることなくイベント投入から数秒以内に出力されました。
ただ実際に利用する過程でSQLによるインセンティブ判定ロジックの定義を作成するのが難しいという課題もわかってきました。
今回の構成ではBeam SQLを利用することによりSQLを使ってインセンティブ判定を定義しています。
しかし分析関数が使えないなどBeam SQLには一部制限があります。
またイベントが来るたびに集計を行うためのトリガー設定など、BigQueryでバッチ実行する際には普段意識することのない要素にも注意する必要がありました。
コンソール上で手軽にSQLを使って判定条件を試行錯誤する環境も現状用意していませんでした。
そのためBigQueryと同じようにSQLを手軽に組み立てることができず、インセンティブ判定ロジックのためのSQL作成には、実際にモック環境でSQL等の設定によるパイプラインを動かして動作検証を行うためにエンジニアによる支援が必要になりました。
その他にも、Job実行時に問題が発生した際にバッチ処理によるリカバリだけでなく、ストリーミング処理を継続したまま問題を解決して処理を滞ることなく行う課題なども挙げられます。
今後はこれらの課題に対応できるよう、よりシンプルにロジックを記載できるモジュールを追加したり、ストリーミングJobにおいても手軽に処理を試行錯誤できる環境構築、状態のスナップショット化などの対応を進めています。
明日の記事は @vvakame さんです。引き続きお楽しみください。




