
この記事は、Merpay Advent Calendar 2022 の6日目の記事 メルカードの舞台裏編です。
こんにちは。 株式会社メルペイ バックエンドエンジニアの norifumi です。今回は、11月8日に発表された、メルカードの還元率に関しての記事です。まず私が還元率管理のマイクロサービスの全体のアーキテクチャについて説明をし、記事の後半で 機密情報のための設計について naoina より説明させていただきます。
マイクロサービスの役割について
解説するマイクロサービスの役割について説明します。メルカードを開発する際に、これまでメルカリ・メルペイではお客さまの一人ひとりに対して個別の特典を付与する恒常的な機能を持つマイクロサービスというものがありませんでした。そこで、新たにメルカリアプリの利用度合いによってポイント還元率を設定するためのマイクロサービスが必要になり、今回解説する還元率管理のマイクロサービスが作成されることとなりました。
このマイクロサービスはお客さまの行動によって還元率が決まることのみを責務とします。
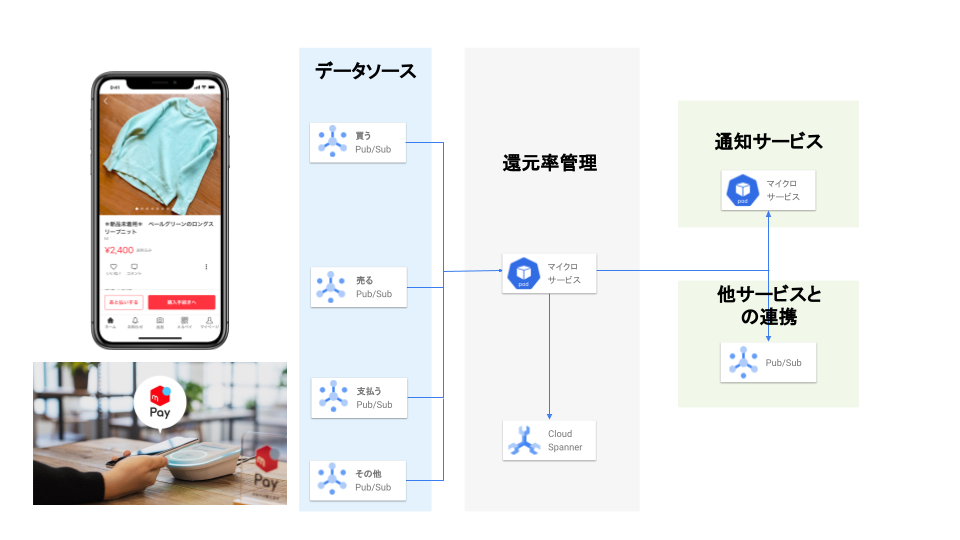
売る・買う・支払うを取得する
発表であったとおり、メルカードではメルカリ内で売り買いやメルペイの利用など様々な行動で還元率が上がるようになっています。これらの情報を取得するためにGoogle Cloud Pub/Subを利用してそれらのイベントを取得し、非同期で還元率の更新を行います。メルカードのサービスが始まる以前のメルカリがサービスインしてから今現在に至るまでのお客さまの行動も考慮されて還元率が設定されます。これによって、昔メルカリを頻繁に使っていた方にもよりよい還元率が設定されるように設計されています。
Pub/Subを利用しているのは次のような理由からです。メルペイでは、数多くのマイクロサービスが存在しており、還元率の情報を更新するために各マイクロサービスからリクエストするように修正するとなると、処理が複雑になってしまいます。また、多くのエンジニアの工数や各プロダクトマネージャーとの調整が必要になり現実的ではありません。解決策としてPub/Subを使うことによって、データを利用されるマイクロサービスと疎結合になり、今回作成したマイクロサービスの中で処理を完結することができ、開発期間を短縮することができました。また、今回はPush型を利用しているので、イベントが発生してから処理までの時間も早く、お客さまへの通知もすばやく行うことができたり、負荷が高まったときのスケールの設定などもgrpcと同様に考えることができたりします。エラーや処理が詰まったときであっても、リトライポリシーの設定やデッドレターキューなどの設定により、きちんとリトライができるようにもなっています。これらの状況はDatadogを使って監視しています。
https://github.com/kubernetes/community/tree/master/icons
https://cloud.google.com/icons?hl=ja
データ処理の設計
こんにちは。この章を担当する、株式会社メルペイのバックエンドエンジニアの naoina です。
この章では、他の各マイクロサービスから受け取ったデータをどう処理しているかを説明します。
前章で説明されているとおり、還元率管理のマイクロサービスでは、還元率を算出するためのデータとして他のマイクロサービスから、売る・買う・支払うなどのデータを Pub/Sub を通して受け取っています。
還元率管理のマイクロサービスでは、これらのデータを種類ごとに加算したデータとして保持しています。例えば、あるお客さまがメルカリで 1,000 円分を購入すると、そのデータが Pub/Sub 経由で飛んできます。還元率管理のマイクロサービスではそのデータをまず下記のように保存します。
お客さまAの購入金額 = 1,000 円その後、同じお客さまがメルカリで 2,000 円分の購入を行うと、還元率管理のマイクロサービスでは下記のようにデータをすべて加算した値として保存します。
お客さまAの購入金額 = 3,000 円この値を使って還元率の算出が行われます。
メルペイではすべてのサービスがマイクロサービスとして実装されているため、還元率管理のマイクロサービスでももちろん冪等性を担保しなければなりません。ですが、上記のデータを加算して保存する方法 (以下、加算方式) は冪等性と相性が良いとは言えません。なぜならば、加算方式では不可逆なデータを保存することになるため、同じデータを重複して加算してしまう問題が発生する可能性があるためです。ではなぜ我々は加算方式を採用したのか?という理由を次から書いていきます。
すべてのデータを保存する方式について
我々が検討したもうひとつの方法は、Pub/Sub で受け取ったデータをすべて還元率管理のマイクロサービスで保存しておく方法です。例えば、下記のようにメルカリでの購入ごとに 1 レコードを保存しておきます。
お客さまAの購入金額 = 1,000 円
お客さまAの購入金額 = 2,000 円還元率を算出する際に、毎回集計を行うことになります。
Pros
- 冪等性と相性がよい
- データの補正が簡単
冪等性と相性が良い
1レコードごとにユニークな ID を付ければ、重複してデータが保存されることがありません。加算方式では重複して加算してしまう可能性があります。
データの補正が簡単
すべて個別のレコードとして保存しているので、何かしらエラーが発生しデータの抜けが出てしまった場合でも、何が保存されていて何が保存されていないのかが明確に把握できます。
さらに前述の冪等性との相性の良さにより、補正するべきデータかどうかの精査をせずに抜けている可能性のあるデータをすべて投入するような補正の仕方が可能です。
Cons
- 毎回集計するのは遅い
- 保存するデータが膨大
- 個人情報を大量に保持することになる
毎回集計するのは遅い
一番問題になるのが、毎回集計するのは遅いという問題です。メルカリにはヘビーに使っていただいているお客さまもおり、そういったお客さまは売る・買う・支払うなどのデータを大量に持っています。その大量のデータを還元率を算出するたびに集計していたのでは、メルカリを使っていただければいただくほど処理が重くなっていきます。
サーバープログラム側で集計を行う場合でも、データベース側で集計を行った結果を返してもらう場合でも、程度の差はあれど同様の問題が起こります。リリースした直後はデータ量が少ないためおそらく問題にはならないですが、いつか問題が顕在化するのは明白で、そういう時限式爆弾を抱えた実装はなるべく最初から避けるべきです。
保存するデータが膨大
メルカリでは日々大量に取引が行われており、また、同じようにメルペイを使った決済も多く行われています。それらすべてのデータを保存していくのはデータ量がかなり多くなることがわかります。
いちマイクロサービスが持つデータ量としてはいささか多いと思われるので、データベースの維持コストなどを考慮してすべてを保存しなくてよい方法を考えるほうが良いと思います。
個人情報を大量に保持することになる
メルカリでは個人情報に当たるデータは厳密に管理されているため、必要のないデータはできるだけ持たないのがリスク管理的にも妥当です。
売る・買う・支払うなどのデータはそれぞれを管理しているマイクロサービスから Pub/Sub で飛んできますが、それらをすべて保存する場合、元のデータと同じコピーを還元率管理のマイクロサービスで持つことになります。そうすると、還元率管理のマイクロサービスも同様のレベルの管理を求められることになります。
これは本来必要のないリスクを抱えることになってしまうので、機密情報の保持はできるだけ避けるべきです。
加算方式について
すべてを保存しておく方法の Pros/Cons を挙げました。これらに対して我々が採用した加算方式ではどうなのかを書いていきます。
冪等性と相性が良くない
加算方式では、うまく制御を行わないと同じデータを重複して加算してしまうリスクがあります。これに関して、我々が取った方法は、飛んできたデータの ID をデータベースにユニークキーとして入れておき、そのデータがもう一度飛んできた場合にまずデータベースにその ID がすでに入っているかを確認します。入っている場合はデータの保存と加算処理をスキップします。入っていない場合は始めてのデータとみなしてデータの保存と加算処理を行います。

これにより、重複して加算されることを防いでいます。
新しいデータが飛んでくるごとにデータベースに INSERT されるので、大量のデータになりそうですが、データすべてを保存する方法と比べて 1 レコードのサイズが遥かに小さくて済みます。
データの補正が難しい
加算方式では、どのデータが加算されていて、どのデータが加算されていないかが、加算後のデータを見てもわかりません。
そこで、前述した、データの ID をユニークキーとして入れておくという仕組みを使います。
補正する候補のデータを、Pub/Sub で飛んでくるものと同じデータ構造で作成し、通常フローと同じように流してやることで、冪等性を担保しつつ、加算されていないデータを加算することができます。
還元率管理のマイクロサービスでは前述の冪等性担保の仕組みとPub/Sub自体のリトライの仕組み機構によって、障害が起こった際にも基本的にデータの補正が自動的に行われるようにしています。
毎回集計しなくてもよい
加算方式では、Pub/Sub のデータが飛んできたときに単純な加算処理だけで済むため、毎回集計するより遥かに効率的です。
保存するデータが削減できる
加算方式では、お客さまの売る・買う・支払うなどのデータは 1 レコードごとではなく、集計した値を保持するため、データ量を大幅に削減できます。
個人情報の保持を最小限にできる
加算方式では、売る・買う・支払うなどのデータを集計された値として保持するため、それ以外の、いつどこで何をいくらで買ったか?などの情報は保持していません。
この必要以上に個人情報データを持たない方針によって、システムの安定性とセキュリティを向上させています。
まとめ
検討したどちらの方式も一長一短がありますが、我々が加算方式を採用した大きな理由は下記の 2 つです。
- 個人情報の保持を最小限にできる
- 保存するデータが削減できる
特に前者の理由が大きく、その他の Cons に関しては、サーバーリソースを増強するなど資金で解決が可能ですが、個人情報の扱いはそれでは解決できないため、還元率管理のマイクロサービスに求められる要件を満たしつつ、扱う個人情報は最小限にすることを考えて加算方式を採用しました。
この他にも、還元率管理のマイクロサービスのアーキテクチャについて書きたいことはまだまだありますが、今回は以上としておきます。ありがとうございました。
明日の記事は keitasuzuki さんです。引き続きお楽しみください。




