
Merpay Tech Fest 2022 は、事業との関わりから技術への興味を深め、プロダクトやサービスを支えるエンジニアリングを知ることができるお祭りで、2022年8月23日(火)からの3日間、開催しました。セッションでは、事業を支える組織・技術・課題などへの試行錯誤やアプローチを紹介していきました。
この記事は、「Feature StoreとVertex AIを使った機械学習基盤の実現」の書き起こしです。
本日は、Feature StoreとVertex AIを使った機械学習基盤の実現についてお話しします。機械学習基盤は、私がメルペイに入社してから関わったプロジェクトです。設計から開発・運用していく中で、良かったことや工夫したこと、今後の取り組みについてお話しします。
自己紹介

メルペイのLiと申します。新卒でヤフー株式会社に入社し、Yahoo!プレミアムサービスのフロントエンド開発・運用を担当していました。入社2年目から機械学習エンジニアにキャリアチェンジし、ECサービスのためのモデリングやデータ分析、機械学習基盤構築に取り組みました。その後、2021年9月に機械学習エンジニアとしてメルペイにジョインし、現在は不正検知モデルや機械学習基盤の開発を担当しています。
Agenda

今日のアジェンダは4つです。機械学習基盤を作る背景、基盤の説明、約1年間開発・運用して感じたこと、今後の取り組みをお話しします。
Background

まずは、背景をお話しします。
Fraud Prevention Models

サービスの不正利用を防止するために、さまざまな機械学習モデルが作られています。たとえば、不正検知システムの誤検知率を下げるアラートフィルタリングモデルやクレジットカードの不正購入を検知するチャージ枠モデル、不審アカウント検知や不審挙動検知のモデルなどです。モデルの追加開発やアップデートが多く、短期間で複数モデルがリリースされる場合もあります。
最近取り組んでいるのは、アカウントベースでのチャージバックモデルや、アカウントの乗っ取りを検知するモデル、架空取引を検知するモデルです。不正手法は日々進化していきますので、対抗するためには早いスピードでのモデル開発・リリースが必要不可欠です。
参考資料
- Alert Filtering (multiple ML models) について:https://engineering.mercari.com/blog/entry/alertfiltering-ml/
- ChargeBack Detection (ML model)について:https://engineering.mercari.com/en/blog/entry/chargeback-ml/
- Suspicious Action Detection (complex network)について:https://engineering.mercari.com/blog/entry/complex-network-ml/
Features
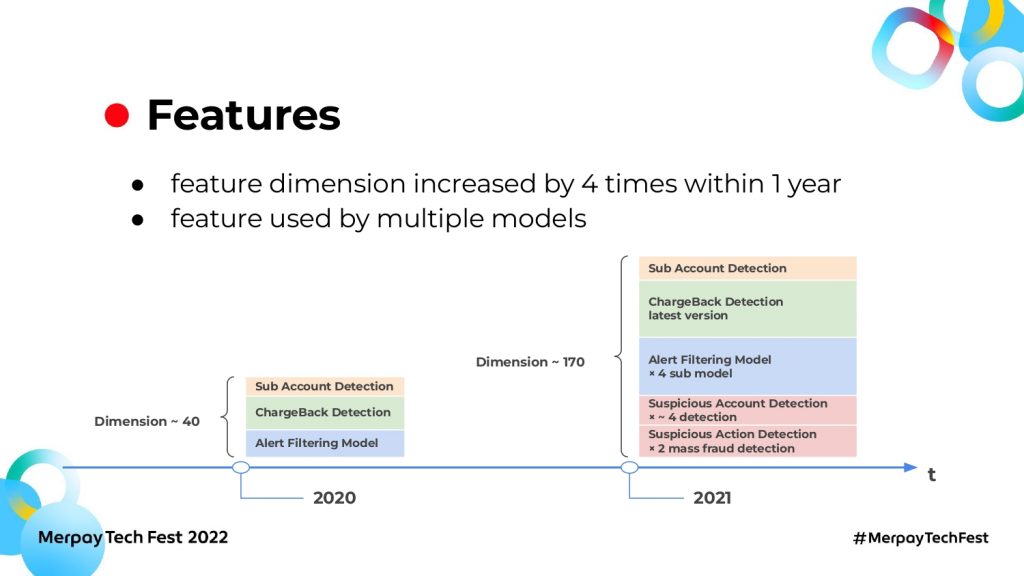
モデルの追加やアップデートに伴い、必要な特徴量も増えてきました。2020年から2021年の間で、特徴量の数は4倍になっています。特徴量のData Sourcesはバラバラで、 BigQuery のテーブルやGCS上のファイル、スプレッドシートなどがあります。
特徴量の中には、複数モデルで共通利用されるものもあります。そのため、増えていく特徴量を低コストで運用管理する需要が生まれました。また、モデルを作るたびに特徴量を生成するのではなく、再利用できる仕組みも必要になりました。
Machine Learning Infrastructure

次に、基盤についてお話しします。

これは、機械学習基盤の全体図です。左側から右側にかけて、Data Sources、Feature Store、Vertex AI、最後にOutputsとなっています。これは、メインのML pipelineロジックを実現するコア部分です。ExecutorやVersion Control、Monitoringはコア部分をサポートするパーツです。
コアは、データを取得してモデルの学習・推論をして、Outputsを格納する機能をもっています。いろいろなData Sourcesの情報をFeature Storeが受け取り、特徴量としてモデルに提供します。
次に GCP(Google Cloud Platform)のVertex AIを利用して、モデルの学習や推論を行います。Vertex AIの中では、主に3つのサービスを使っています。Vertex pipelines は具体的なML pipelineを実行、Vertex Endpoint はモデルのデプロイやオンライン推論、Vertex Models は作られたモデルの管理をします。
そしてOutputsでモデルや推論結果を必要な場所に格納し、後続の利用に対応します。これで必要なML pipelineのロジック実装をし、学習と推論を回せるのです。
ですが、これだけではまだまだ足りません。これらをすべて手動で運用すれば運用コストが高くなりますし、モデルの数が増えると日々の運用に追われて新しいチャレンジができなくなる恐れがあります。これを解消するために出した答えは「自動化できるものは自動化しましょう」でした。
たとえば左上のExecutorはML pipelineの自動実行が可能で、オンデマンド実行や定期実行をボタン一つで制御できます。Version Controlは、ML pipelineのソースコードのバージョン管理を実現しました。
「ソースコードのバージョン管理はGitHubだけでいいじゃん」と思うかもしれませんが、実はここには事情があります。私たちは基本的にKubeflow pipelinesのSDKを使ってVertex AIが実行できるML pipelineを構築しています。この特性上、一度ML pipelineのロジックのPythonファイルをコンパイルし、Vertex AIはコンパイルされたファイルを使ってpipelineを実行します。
「GitHubへの最新版のコードをコンパイルして使えばいい」と思われるかもしれませんが、実はpipeline間では、共通利用されるロジックやpipelineがあります。もしそれらを更新する場合、共通利用しているすべての箇所が影響を受けてしまいます。そのため、改修時にすべてのpipelineを動作確認しなければならず、気軽にアップデートできないという課題がありました。これを解決するために、コンパイルされたファイルに対するバージョン管理を導入しました。
図の右下にあるMonitoringでは、モデルのパフォーマンスや日々のアラートなどを Slackで通知しています。システムやモデルに対して継続的なモニタリングを実現し、何か起きたときにいち早く対応できる体制をとっているのです。
コアで利用しているVertex AIとFeature Storeの2つのサービスももう少しみてみましょう。
Vartex AI

Vertex AIとは、マネージド機械学習プラットフォームで、企業の機械学習モデルのデプロイやメンテナンスを迅速に行えるようにしたものです。
Vertex AIはGoogleCloudの既存MLサービスを一つの環境に統合し、MLプロジェクトのライフサイクルを効率的に構築・管理します。マネージドサービスですので、運用コストもオンプレミスより低く、MLプロジェクトの各ライフサイクルをカバーできるので便利なツールもいっぱい提供しています。
以上の理由から、Vertex AIをMLロジックを処理するメインプラットフォームとして採用しました。
参考資料:https://cloud.google.com/vertex-ai/docs/start/introduction-unified-platform?hl=ja
Feature Store(Feast)
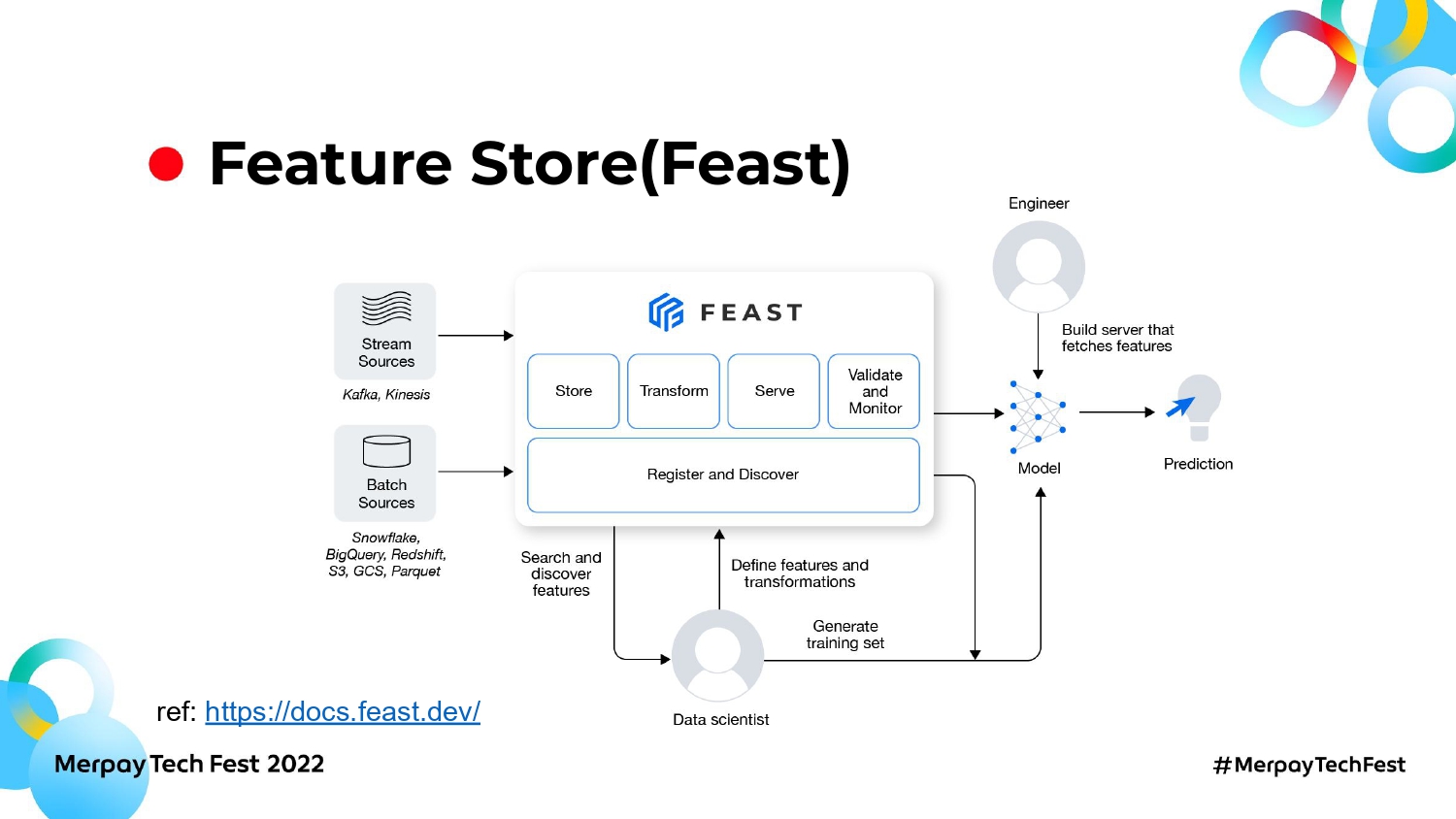
私たちが採用したFeature Storeのサービスは、Feastというオープンソースです。Feastは機械学習モデル用の特徴量を一括管理・提供できます。
さまざまなData Sourcesの違いを吸収し、一貫したインターフェースで特徴量を提供できます。MLエンジニアは、データ処理を気にせず特徴量を取得して利用できます。

Feature Storeがない場合、各Data Sourcesに対してモデルごとに独立したデータ処理をしなければなりません。モデル間で重複利用する特徴量があるとしても、毎回同じ処理をモデルごとにする必要があります。
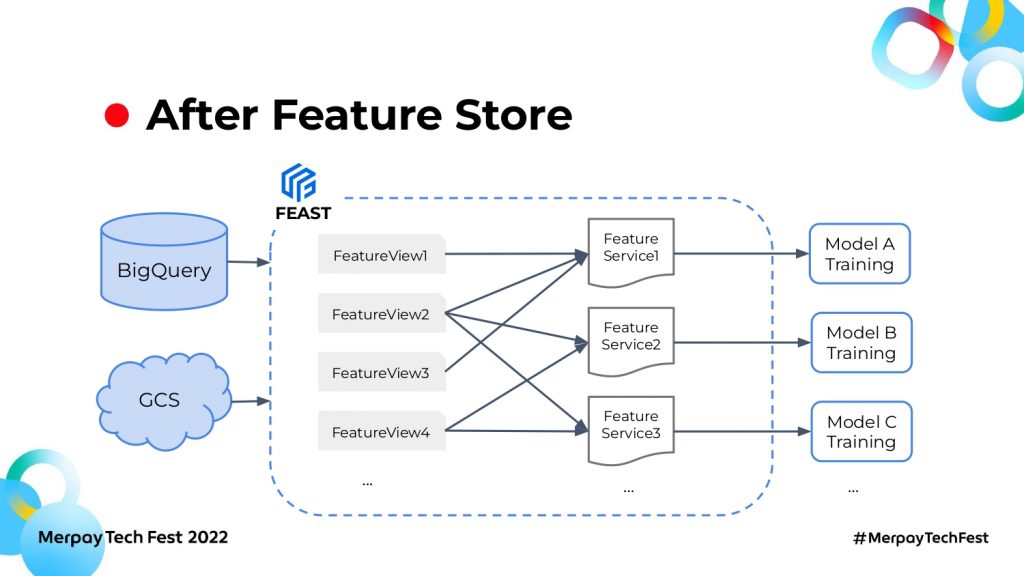
Feature Storeを導入した後は、BigQueryやGCSなど違うData Sourcesから特徴量を取り入れてFeature Viewを作ります。Feature Viewとは、ドメインごとの特徴量セットです。商品の特徴量リストをFeature View1、取引の特徴量リストをFeature View2と表現したとき、Feature ServiceはこれらFeature Viewを組み合わせて、モデルに必要な分だけの特徴量を提供できます。
Feature StoreがData Sourcesとモデルの間で特徴量を一括管理しますので、共通で利用される特徴量は一度開発すれば再利用できます。また、モデルでもFeature Serviceを使って自由に特徴量を組み込むことができるので、開発コストが下がります。
MLエンジニアはモデルの開発、データエンジニアは特徴量の生成・管理にそれぞれ集中できるため、役割分担がうまくできるようになりました。
what we think were good after 1 year of operation

次に約1年間、機械学習基盤を開発・運用して、よかったこと・工夫したことです。
Elements Definition
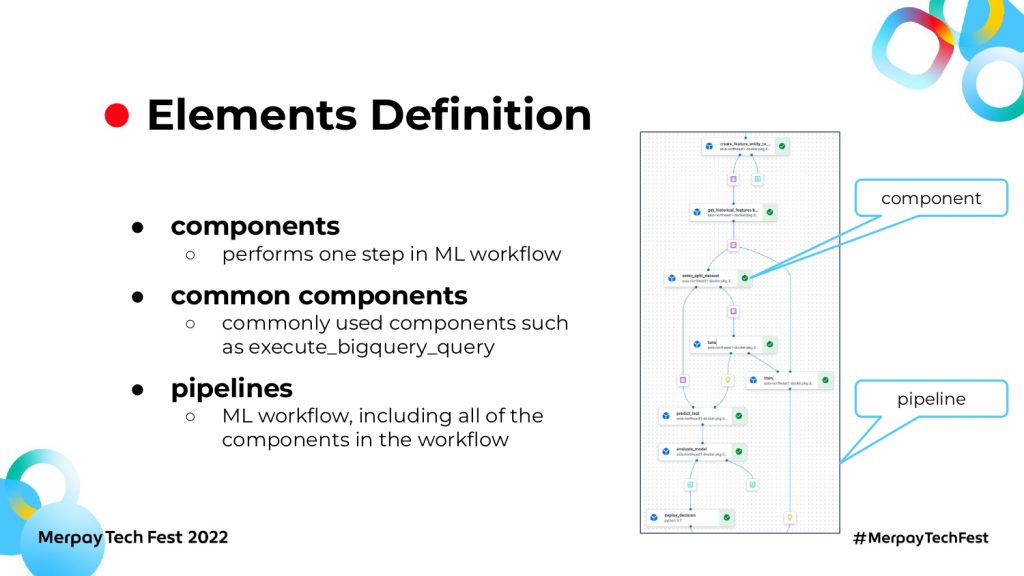
詳細に入る前に、まずは各エレメントを説明します。スライドの図はVertex pipelinesの一例で、データ取得からチューニング、学習、最後にモデルの評価などの流れが入っています。
ここでのcomponentsは、図の一つひとつのブロックで、単独タスクもしくはロジックを示しています。たとえばデータを取り入れてテストのデータに分割することが、1 componentになってます。また、いろいろなpipelineで共通利用されるcomponentもあります。たとえば BigQueryの実行結果を取得するcomponentは、いろいろなpipelineで幅広く利用されています。これをcommon componentsとも呼びます。
なお、common componentsは公式のものではなく、私たちが開発コストを下げるために頻繁に使われるcomponentを共通化しようとしたことから生まれたものです。
各componentで作られた一連の流れが1 pipeline、つまり1個のML pipelineになります。
ここまでが前提知識で、次に基盤の話に戻ります。
Common Piplines

一つ目のよかったポイントは、共通pipelinesを作ったことでした。
モデルごとの教師あり学習の流れはどれも大体同じで、データを取得して学習し、必要に応じてチューニングを行い、評価する流れです。違うのは、扱う特徴量リストやラベルの定義、Feature Store、ハイパーパラメータの範囲、モデルの名前などです。
そこで、共通する学習の流れを一つのpipelineにまとめました。そしてモデルごとに異なる部分のみconfig fileで管理し、pipeline実行時に該当するconfig fileをパラメータとして受け取り、必要なモデルを作りました。

モデルごとにconfig fileが存在し、ファイルの内容を参照しながらpipelineを実行すると、欲しいモデルが作れるようになります。たとえば、モデルAのconfig fileを入れて実行するとモデルAが生成できます。
最大のメリットは、開発コストを抑えながらモデルを量産できることです。config fileを1個追加することで、モデルが1個生成できます。
実験の段階でいろいろ試したい、あるいは短期間でモデルを複数作りたい場合、データさえ決まればモデルを作れるので、PDCAを高速で回す、ファストリリースするといったことが可能です。
Version Control

二つ目は、pipelineとcomponentのバージョン管理です。
ここではKubeflow pipelinesのSDK を使っています。先ほどpipelineのロジックをコンパイルする必要があるとお話ししましたが、実はcomponentもコンパイルする必要があります。
次にpipeline実行までの流れです。最初に各componentのロジックを定義します。たとえばこの図で言うと、train関数を定義して、モデルの学習ロジックを実装します。そのあとtrain関数をコンパイルします。pipelineのロジックを組み込むときは、コンパイルされたyamlファイルをcomponentファイルとしていくつか読み取り、pipelineの流れを構築します。最後に、pipelineを再びコンパイルして、Vertex AI を実行できるようにします。つまり、2回のコンパイルが必要です。
これには、共通のcomponentやpipelineを変更したい場合、他のモデルにも影響を及ぼすため改修しにくいという問題がありました。たとえば、パラメータやcomponentを追加したい場合が挙げられます。

たとえばエンジニアAが「このcomponentをアップデートしたい」と宣言したら、エンジニアBが「私たちもアップデートに対応しないと、pipelineがエラーになる」という問題が起こります。

そこで私たちは、同じパッケージでもバージョンを変えることでお互いの影響を防げないかと考えました。たとえばよく使用するPythonパッケージのように、とあるサーバーではバージョン1.0、他のサーバーではバージョン2.0のものを使用するイメージです。
これを実現できると、MLエンジニアAがcomponentをアップデートする場合であっても、エンジニアBが前バージョンを使用することで干渉を防げるので、気軽に開発できます。
そこで出した答えは、コンパイルされたファイルに対して、バージョン管理することでした。GCS上のファイルを保存して参照しているのであれば、GCSのパスごとにバージョン分けします。たとえば、コンパイルしてGCSに上げる際、0.1や0.2などのパス名を指定するのです。するとパスごとにバージョンが分けられるので、参照するときは違うパスを指定することで、違うバージョンのpipelineを実行できます。

システム構造は図の通りです。GitHubでソースコードが更新されると、GitHub Actionsを通じて、GCS上にコンパイルされたファイルがアップロードされます。左のcommon componentや右のpipelineは、バージョンごとにファイルが分けられています。
右のpipelineを見ると、0.5.0バージョンではML pipelineA、ML pipelineB、train pipelineの3つがあります。0.6.0ではML pipelineCが追加されました。ポイントは、ML pipelineCが追加されただけで、ML pipelineA・ML pipelineBは何も変わってない点です。
このように、1つのバージョンで全てのpipelineの状態を保存する、スナップショットのような方法を採用しました。
同じファイルが何回も保存されている分冗長ではありますが、ファイルの扱いやすさという点で優れています。これを私たちはone-for-all versioningと呼んでいます。
common componentsも同様で、pipelineは違うバージョンのcommon componentsを指定して利用できます。何か変更があったとしても、バージョンが上がれば今使ってるファイルはなくならないため既存通り利用できますし、変更された部分は新しいバージョンのパスに保存することで、お互い影響を及ぼさずに開発・運用していくことができます。

まとめると、私たちはone-for-all versioningを使ってcomponentsやpipelineのバージョンを管理しています。 componentsとpipelineズはコンパイルされて、GCS上にアップロードされるので、違うGCSのパスを使って、バージョン管理をしています。
Schedules/On-demand Execution

三つ目は、実行の自動化です。それぞれのpipelineは異なる実行要件をもっています。たとえばtrain pipelineは、データドリフトが起きてモデルのパフォーマンスが落ちたら都度オンデマンド実行をしたいですし、predict pipelineはデイリーもしくはアーリーなどの定期実行をしたいと思います。共通pipelineは違うconfig fileを指定して実行できるようにしたいです。
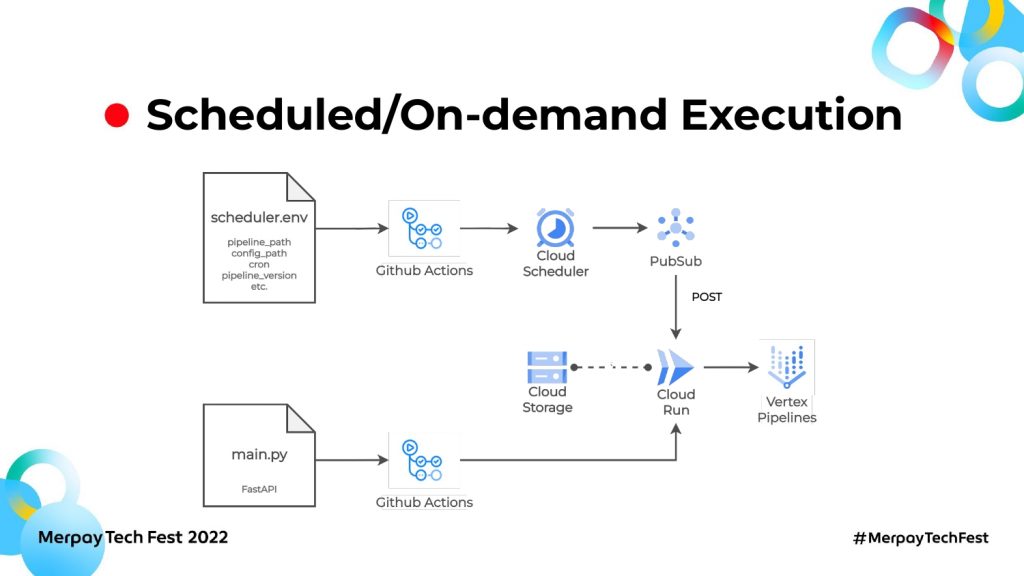
これを実現したのが、上記システムです。先に図の下半分を見てみましょう。main.pyと、Github Actionsを使ってCloud Runを立てました。Cloud RunではファーストAPIが動いていて、リクエストを受け取って必要なpipelineファイルをGCS上から参照し、Vertex AIで実行します。
そのリクエストは、図でいう上の半分からきています。先にCloud Schedulerの設定を行い、Cloud Schedulerでどのpipelineをどのタイミングで実行するのかを管理します。pipelineごとにscheduler.envがありまして、実行したいpipelineのパスやconfig fileのパス、定期実行したい場合のクーロンなどが書かれています。GitHub Actionsを使ってCloud Schedulerにpipelineの実行パターンを設定します。
定期実行の場合、クーロンに設定された時刻になるとPubSubにメッセージを送ります。送るメッセージの内容はscheduler.envで設定したpipelineのパスや、pipelineの名前やconfig fileなどです。
PubSubは、受け取ったメッセージをCloud RunにPushします。Cloud RunはPubSubからメッセージを受け取り、必要なpipelineを実行できます。オンデマンドを実行したい場合、普段はCloud Schedulerは非アクティブ化します。必要なときだけアクティブ化して「今すぐ実行」のボタンを押すと、train pipelineやオンデマンド実行が必要なpipelineが実行できます。
Cloud SchedulerとPubSubの合わせ技で、オンデマンド実行や定期実行、違うconfig fileでの実行をボタン一つで制御できるようにしました。

モデルが更新されたら、A/Bテストが必要です。こちらも自動化させました。
右側のVertex AI Endpointはモデルをデプロイして、Endpointからの推論もできます。トラフィックスプリット機能も提供しており、一つのEndpointに最大2つのモデルをデプロイできます。
たとえばモデルAとモデルBを一つのEndpointにデプロイし、パフォーマンス評価を行います。モデルAが勝った場合、モデルAをトラフィック50%から100%にすることで、A/Bテストを完了します。Endpointの手動設定もできますが、運用コスト削減や手動によるヒューマンエラーの検証のために、自動化しました。
具体的には、Endpointのconfig fileを設けて、Endpointにデプロイしたいモデルや設定を記入します。次にGitHub Actionsを使って、Endpointにデプロイすると、欲しいモデルが欲しい状態でデプロイされるようになります。
一つのファイルで、Endpointの状況を自動制御できるので、A/Bテストのハードルも下がります。
ML Monitoring with Slack Notifier

最後に、pipelineの実行状況やモデルのパフォーマンスをSlack連携で通知することで、モニタリングを実現しています。
Future work

ここからは、今後取り組みたい部分をお話しします。
Feature Online Store with Stream Ingest

一つ目は、Feature Storeの拡張です。Feature Storeは、今までパッチインジェストしたデータをオフラインストアに保存し、過去のデータからのモデル学習に使われていました。
今後はリアルタイムの推論への需要が高まりますので、kafkaなどのStream Ingest機能も取り入れたいと思います。
具体的にはストリームインジェストしたデータをオンラインストアに格納し、Vertex Endpointと連携して、リアルタイムのデータを使ったモデルの推論を実現したいです。
推論の結果はBigQueryやGCS、Cloud Spannerなどに保存して後続の利用に対応する予定です。
不確実性が高いポイントとしては、Feastのアップグレードです。Feastはコミュニティが活発なオープンソースのため、成長が著しいのです。アップグレードに対応するのと、まだストリームインジェストや欲しい機能に関してはαになっている箇所もありますので、プロダクション環境で安定運用をするのと、新しい機能を取り入れる間のバランスをどう取るかが課題になりそうです。
Data Drift Detection and Re-Train
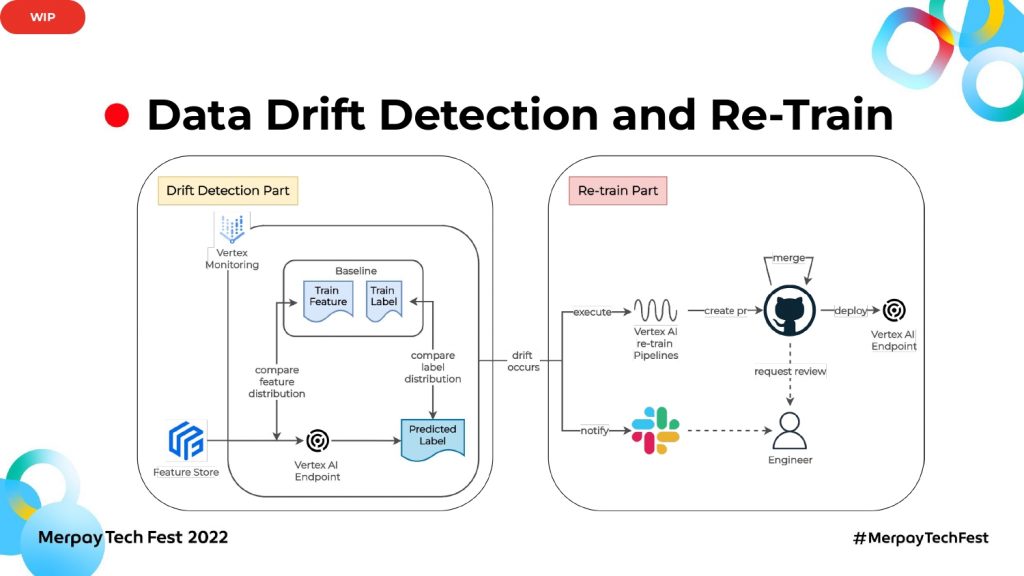
二つ目に、データドリフト検知と再学習のフローを自動化したいです。図のように2つのパーツに分けられていて、左側の部分がデータドリフトの検知、右側が再学習です。データドリフト検知では、Vertex AIが提供するモニタリング機能を使おうと思います。学習時の特徴量とラベルをベースラインにして、Endpointで推論する際の最新特徴量とラベルを比較対象にします。
2つの特徴量やラベルの統計分布間の距離が特定の閾値を超えると違う分布になるので、ドリフトが発生したと判断できます。ドリフトを検知できたら、右の再学習フローに入ります。
まずはデータドリフトが起きたことをSlackで通知し、再学習用のVertex pipelineを実行してモデルを生成します。
次に生成されたモデルのconfig fileなどのプルリクエストを出し、エンジニアにレビューを依頼します。新しいモデルを実際使うかどうかは、人間が判断するということです。
プルリクエストがアプルーブされたらマージして、実際にVertex Endpointに新しいモデルをデプロイし、モデルの更新もしくはABテストを行います。こちらに関してはまだ取り組み中で、設計も今後変わる可能性があります。
最後に
不正検知は、ビジネス要件の変化が激しいです。そのため、モデルの作成・デプロイが早くでき、かつモデルが100個あっても気軽に運用できる機械学習基盤を作りました。これは、同じくビジネス要件が変わる環境にも適応できる基盤だと思います。
ご清聴ありがとうございました。




