
ソウゾウの機械学習チームでSoftware Engineer Internをしている@manami-nです。
本稿ではインターン中に携わった、「売れやすい価格」をお客さまに提案するための機械学習モデル(価格推定モデル)の検証とインターンの様子について紹介します。
取り組んだタスクの概要
ソウゾウでは、メルカリShops というサービスを作っています。メルカリShopsとは、個人事業主・個人問わず自分のお店を持つことができ、メルカリ内で商品をかんたんに販売できるサービスで、メルカリアプリ内の「ショップ」タブから簡単に閲覧・購入ができます。
お客さまが出品する際、価格設定に悩まれることが多いです。
この問題の解決のため、メルカリでは「売れやすい価格」を自動的に提案する機能が既に存在します。このような機械学習による価格提案の機能をメルカリShopsにも導入できないか検討中で、今回は価格推定モデルの精度がメルカリShopsのデータでどれくらいの精度を出せるのか検証しました。
今回は、メルカリが過去に開催した価格推定モデルの精度を競うKaggleコンペ (Mercari Price Suggestion Challenge)のモデルを検証に使用しました。
このコンペで使用されたデータセットはまだメルカリShopsがない頃のUSのデータでした。しかし、お店として売ることができるメルカリShopsのデータは、個人として売るメルカリJPやUSのデータとは性質が違う可能性があります。そこで、実際のメルカリShopsのデータで学習を回し、検証しました。
価格推定モデルの説明
参考にしたモデル内部についてはこちらをご覧ください。
このモデルの検証のため、バッチサイズやEpoch数の調整をするために何度か学習を回すにあたって、callbackを用いてLogを残すことにしました。そのおかげで、TensorBoardに過去のデータと合わせて描画できるようになり、比較が容易になりました。
このモデルの検証時には価格推定に適した評価として、RMSLEを計算し使用していました。
以下のグラフは同じデータセットで学習を回した場合のBatch数の比較実験で、TensorBoardで描画したものです。 暖色が検証データ、寒色は学習データになっています。


価格推定モデルの評価・考察
次に、この機能自体を導入するか判断するために使用できるような指標でも検証を行いました。
手法として、実際の出品価格と価格推定モデルの予測価格の差異を表しました。
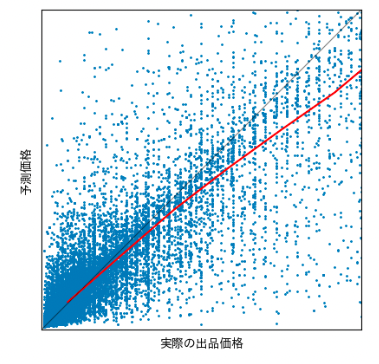
黒線に近いほど、実際の出品価格と予測された価格が近いことを表します。
赤線は実際の出品価格(x軸)が近い商品をグループ分けし、予測価格の平均値(y軸)をプロットしたものです。
当初は全体を1つの直線に近似した線をプロットしていましたが、価格が大きい商品に対する誤差が大きく計算されてしまうので、少数の高価格帯のデータセットに大きく左右されてしまいます。そのため、1次元の近似線を単純にプロットするだけでは全体の傾向を判断しにくく、各範囲ごとの平均をとる判断をしました。
ここで、カテゴリごとに商品の傾向が大きく違うのではないかと考え、カテゴリごとの予測傾向を確認することにしました。
例えば服の出品であれば、下図のような予測になりました。出品が多い低価格帯ものだと大方正しく予測できていそうな図です。
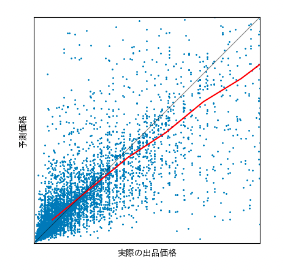
一方、食品(下図)では少額の出品が集中しています。
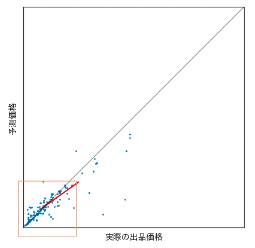
ここで、さらに範囲を絞って低価格帯での傾向を見てみました。
少額商品は正しく予測できていそうですが、高額商品はデータが少なくあまり予測が上手くいってなさそうです。

面白いデータとしては「メイクアップ」と「コスメ」で予測の傾向が異なることです。
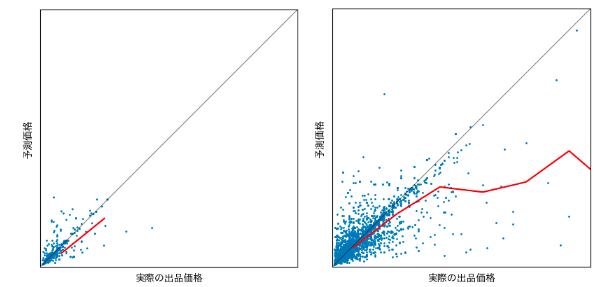
ジャンルとしてはメイクアップはコスメのサブカテゴリーです。
「メイクアップ」のカテゴリは大方予測できているのに対して、そのサブカテゴリである「コスメ」のカテゴリでは予測を大きく外していました。そこでどのような商品について予測を外しているのか具体的に確認したところ、高級ブランド香水を正しく評価できていない場合が多く見られました この原因として、現在メルカリShopsでは出品時に内容量を登録する部分はなく、タイトルや詳細に記載していただいているケースが多いことが考えられます。そのため、内容量や個数を数値特徴量としてタイトル等とは別にモデルに学習させることが出来ておらず、ここに改善の余地がありそうです。
タスクのまとめ
やったこと: コンペの価格推定モデルをメルカリShopsのデータで検証しました
発見した改善点: ・平均的にはそれらしく予測はできており、低価格帯にも強いものの、高価格帯の予測には改善の余地がありそうです ・カテゴリ別や個別でみると大きく傾向を外れているケースも存在します
改善案: 内容量や個数を価格推定モデルが認識していないことで予測に影響が出ている場合が多いので、記入していただく商品内容を変えていくことも考えられそうです
インターンの感想
1ヶ月半という短い期間でしたが、メンターはじめ、チームの方の多大なるサポートのおかげで学びの多い経験となりました!
学んだことの一例として、環境構築があります。大学で使用している私用のPCは学習の試行錯誤の末にpipやbrewを使い、がむしゃらに色んなものがインストールされている環境的に宜しくない状態でした。ただ、頻繁に買い換えないため、環境構築について考える機会はあまりありませんでした。
今回のインターンにあたり、まっさらな状態の社用のPCをいただいたことで、良い環境構築とは?便利な機能はあるのだろうか?という疑問が浮かぶようになりました。
SouzohのMachine LearningチームではpyenvとPoetryで環境構築を行っています。pyenvの利点は指定した特定のバージョンのPython実行環境を導入することができることです。さらに複数のバージョンをそれぞれ異なるディレクトリに収納して切り替えることができるのでプロジェクトごとに環境を変えることも可能です。また、pyenvで用意したPythonの実行環境にPoetryでpyproject.tomlに記述されたパッケージをインストールすることでチーム内で同じ環境が容易に再現できるようになっています。
「環境が壊れる」というハプニングも発生し、何度も環境再構築を試みる機会があり、最初は聞いたことなかったpyenvやpoetryが何か理解することができ、結果的に良い学びになりました。これは企業のチーム開発を経験しなければ得られなかった知見だと思います。
その他、コードのリファクタリングの過程などで多くつまづきましたが、メンターの@naoさんが拡張機能についてQiitaの記事を書いて投げてくださったり、朝会(オンライン会議)やSlackでチームの方に助けていただき、なんとかタスクを進めていくことが出来ました。
Slackコミュニケーションなど、フルリモートワークができる環境が整っているのは他のインターン生の方のブログでも書かれていてその通りなのですが、出社しても楽しく、真に働き方を自由にチョイスできて、とても働きやすい会社だなと思いました。そして、チーム外の方とも交流させていただく機会がありましたが、とてもオープンな社風で、期間が短いインターンの私にも気さくに話しかけて下さり色んな話を聞けて、とても勉強になりました。
Build@mercariのトレーニングプログラム後、このインターンの面接を受ける時、
1. 大学の授業では分からないような実際の業務を通しての経験や知見を得ること
2. 色んな方の話を聞いて自分の数年後のキャリアパスを探索すること
を目標としていました。
結果的に仕事としての機械学習や、院進学についてなどとても学びになることが多い期間となりました。
インターンが始まる前にやりたい事とタスクの擦り合わせができる環境で、「ある程度学習していて、この分野で実務経験を積みたい」というビジョンがある方におすすめのインターン環境です。
記事は以上となります。ありがとうございました!




