こんにちは、メルペイ DataPlatformチーム(@rerorero, @darklore, @laughingman7743)です。
この記事は、Merpay Tech Openness Month 2022 の14日目の記事です。
今日はメルペイ DataPlatformで取り組んでいるCDCパイプラインについて紹介します。
CDCパイプラインとは何か
CDCとは Change Data Capture の略称で、データベース内のデータの変更(新規作成、削除、変更など)を追跡するシステムです。データソースで発生した変更は、ニアリアルタイムでデータシンクに反映させることができます。
CDCの実現方法にはいくつかあるのですが、メルペイ DataPlatformでは以下の2つの方法を使ったパイプラインを構築しています。 Striim社のブログ がよくまとまっていたので、こちらから引用させてもらいます。
Log-Based Change Data Capture
一般的にデータベースにはトランザクションログ(あるいはredoログ)というものが存在し、データの変更に関するイベントがログとして記録されています。これらのログを読み取ってデータシンクに連携させる方法です。一貫した変更内容が取れる一方、データパイプラインで利用するにはログフォーマットの変更が必要であったり、そもそもログを取得できないデータベースではこの方法は利用できません。
Audit Columns
データソースのテーブルに、最終更新時間を表すタイムスタンプカラムを追加し、定期的に以下のようなクエリを実行して抽出したデータをデータシンクに送信します。
SELECT * FROM source WHERE last_updated > @LAST_POLL_TIMESTAMP次の定期実行では、前回抽出したところから更新されたデータだけがSELECTされてデータシンクに送信されるという仕組みです。SQLを実行するだけなので、トランザクションログが利用できないデータベースでも利用できます。一方で、SELECTを実行するためデータベースへの負荷が発生しますし、タイムスタンプに対するインデックスを張る必要も出てきます。また削除されたデータは検知できないため、この仕組みだけでは削除イベントをデータシンクに反映できないというデメリットもあります。
CDCパイプラインの概要
以下がメルペイ DataPlatformのCDCパイプラインの概略図です。
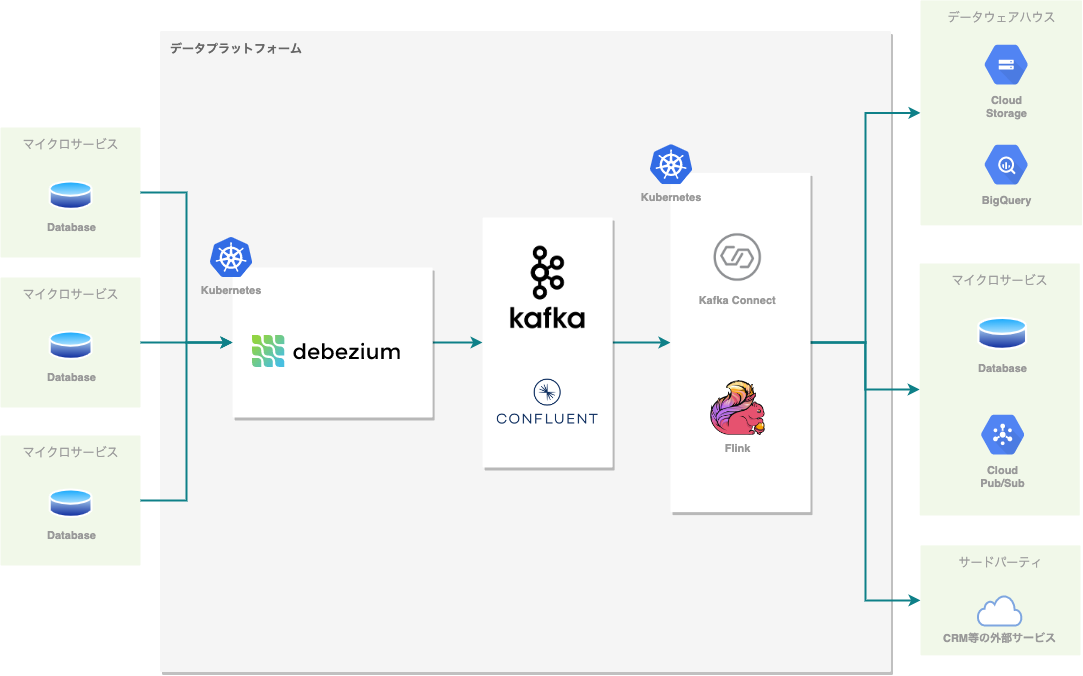
パイプラインは Kafka を中心に構築されています。Kafkaの運用は非常に大変なので、Kafkaのマネージドサービスである Confluent Cloud を利用しています。Kafka を選択した理由は、 Kafka Connect という様々なデータソースに接続するためのフレームワークが利用でき、将来のユースケースの拡大も容易に行えることが期待されるからです。
データソースからはKafka Connectを利用してKafkaに変更イベントを配送し、Kafka ConnectまたはFlinkでそれらをKafkaから取り出して各シンクに配送するという仕組みです。
Kafka Connect とは
Kafka Connect はKafkaからデータをストリーミング取得、または入力するための処理をスケーラブルかつ高可用に実行できるフレームワークです。Confluent CloudではマネージドでKafka Connectを動かすこともできますが、データソース・シンクへの接続、運用のしやすさ、コストの観点から、Kubernetes上で動かすことを選択しました。
今現在利用しているコネクターには以下があります。
Debezium
Debezium は Log-Based CDCを実現するOSSのコネクターで、MySQL、MongoDB、Cassandraなどいくつかのデータベースをサポートしています。メルペイ DataPlatformではMySQLとPostgreSQL のデータソースからの変更イベントをKafkaに配送するために利用しています。
JDBC Connector
JDBC Connector はJDBCをサポートしているデータベースからデータを取得してKafkaに配送する、あるいはKafkaから取り込む事ができる、OSSのコネクターです。メルペイ DataPlatformではCloud Spannerのデータソースから、Audit Columns方式で変更イベントをKafkaに配送するために利用しています。
BigQuery Connector
BigQuery Connector は Kafkaから取り出したデータをBigQueryに配送するためのコネクターです。メルペイ DataPlatformのCDC PipelineではSpannerからのデータはこのコネクターを利用してBigQueryに配送している一方で、DebeziumからのデータはFlinkを使ってBigQueryに配送しています。Debeziumからのデータには変更前・変更後のデータやメタデータなどの情報が入っており特殊なスキーマとなっていて、後述する神Viewで利用するためこれらの情報を維持しつつBigQueryに配送するためです。
Spanner Sink Connector
Spanner Sink Connector はKafkaから取り出したデータをSpannerに配送するためのコネクターです。このコネクターはConfluent社によって提供されており、ソースも公開されていません。実際にプロダクションで利用するにはConfluent社のライセンスが必要になります(30日間の試用期間あり)。
各コネクターの利用
前節では、メルペイDataPlatform Teamが取り組んでいるCDCパイプラインについて概要を説明しました。ここからはCDCパイプラインを構成する各要素について説明していきます。
Debezium
Debezium https://debezium.io/ はChange Data Captureを実現するJava製のOSSです。RDBMSを始めとする様々なデータソースからデータの変更イベントを読み取り、Kafkaのクラスタにストリームとして送信します。DebeziumはKafka Connectのコネクターとして実装されていて、データソースごとにコネクターが用意されています(MySQL Connector、MongoDB Connectorなど)。 コネクターそれぞれにドキュメントがしっかり用意されているので、まずはこれを読むとよいでしょう。( Connectors :: Debezium Documentation )
また、Kafka Connectの機能によりデータをAvro形式でKafkaに投げることが可能です。 ( Avro Serialization :: Debezium Documentation ) Schema情報もSchema Registryへ自動で登録してくれます。これによりKafkaとSchema Registryをハブにして、様々なストリーム処理を連携させることが可能になります。
メルペイDataPlatformではMySQLとPostgreSQLのコネクターを使用しています。以下に各コネクターについて説明していきます。
セットアップ
その前にDebeziumそのもののセットアップ方法を説明します。公式のセットアップ方法は こちら (Installing Debezium) で説明されています。
必要なものは以下の通りです
- Kafka Connect クラスタ (https://kafka.apache.org/documentation.html#connect)
- Kafkaクラスタ(データの送信先)
Kafka ConnectのpluginディレクトリにDebeziumのjarを放り込んでやればセットアップ完了です。Confluent PlatformやConfluent Cloudが使用可能な環境にある方はConfluent platformのdocker イメージにKafka Connectの環境が入ったイメージがあるので、そちらにDebeziumをインストールすることでも使えます。
MySQLConnector
MySQL ConnectorはトランザクションログとしてMySQLのbinlogを読むことでデータの変更履歴を取得します。そのためMySQL側にもユーザや権限の追加等が必要になります。設定内容はこちら ( Debezium connector for MySQL ) に詳しく書かれています。
PostgreSQL Connector
PostgreSQL ConnectorはPostgreSQLのlogical decoding機能を使ってトランザクションログを取得します。そのためMySQLと同様にPostgreSQL側にもlogical decodingの設定が必要になります。詳しくはこちら( Debezium connector for PostgreSQL)に書かれています。各種クラウドサービスのマネージドDBについての手順も書かれているので参考になります。GCPのCloudSQLについてはこちら(Set up logical replication and decoding | Cloud SQL for PostgreSQL)も参考になります。logical decoding output plug-inは何種類かありますが、メルペイDataPlatformではpgoutputを使用しています。
設定
メルペイDataPlatformではDebeziumに特別凝った設定はせず、RDBのテーブルとKafkaのトピックを1対1で対応付けるような構成で運用しています。Debeziumの設定は各コネクターのWebページの”Deployment”の節に詳しく書かれています。ここではメルペイDataPlatformで主に使っている設定を2つ紹介します。
snapshot.mode
デフォルトではDebezium(MySQL、PostgreSQL Connector)は、初回起動時にターゲットとなるテーブルのスナップショットを取りKafkaに送ろうとします。これはテーブルの完全な状態をストリームとして送りたい場合は有用ですが、メルペイDataPlatformの場合は以下の理由で使用しないことにしています。
- RDBに負荷がかかる(※)
- スナップショットを取りたい場面が初回起動時以外にもある(※)
- ストリームではなくバッチでデータをBQにロードしたい場合
- スナップショットに何らかの不具合があることが後で判明した場合
- Kafkaへのリアルタイム送信は継続しつつスナップショットを再度取り直す
- RDBのデータをすべてストリーム処理したいわけではない
- BigQueryテーブルをニアリアルタイムに更新することを目的としている
そのため、実行タイミングを自由に調整できる別の仕組みを使ってRDBのスナップショットを取得しています。Debeziumでは ”snapshot.mode” の設定を”never”か”schema_only”にしてスナップショットを取得しないようにしています。snapshot.modeについての説明は各Connectorのページで詳しく説明されています。
※Debeziumによるスナップショット取得に関して、DBにかかる負荷を軽減しつつつスナップショットを取得する機能が最近Debeziumに追加されました ( https://debezium.io/blog/2021/10/07/incremental-snapshots/ , https://debezium.io/blog/2022/04/07/read-only-incremental-snapshots/ )
データマッピング
DebeziumはRDBのレコードをAvroまたはJSONに変換してKafkaに送信しますが、この変換は1対1で決まっているものではなく、変換の詳細をDebeziumの設定で調整できます。代表的な例がTIME型です。
MySQLやPostgreSQLのTIME型は精度を指定できますが、例えばTIME(3)のデータをDebeziumで送る際に、ミリ秒の精度で変換するかマイクロ秒の精度まで拡張して変換するかをDebeziumの設定 time.precision.mode で決めることができます。どの設定にすべきかはパイプライン後段の処理内容に依存すると思います。TIME型を精度の区別なく扱いたい場合は一律マイクロ秒精度で変換すればよいでしょうし、精度を区別して扱う必要がある場合は逆にミリ秒とマイクロ秒を分けて変換する必要があると思います。ただし、このようなデータマッピングの設定は運用中に変えると変更の前後でデータの意味が変わってしまうため、できるなら運用を始める前に決めておきたいです。
データマッピングについての設定は各Connectorのページに記載されています。
JDBC Connector
Spannerからデータを取得するために JDBC Connector を利用しています。前述したAudit Columns方式でSELECTクエリを定期的に実行した結果をKafkaに配送します。以下のような設定で、定期的に実行するクエリを指定することができます。
{
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:cloudspanner:/projects/merpay-dataplatform-jp/instances/myinstance/databases/mydb;readonly=true;minSessions=1;maxSessions=10",
"poll.interval.ms": "30000",
"mode": "timestamp",
"timestamp.column.name": "UpdatedAt",
"query": "SELECT * FROM MyTable"
}mode=timestamp では query で指定したクエリに、タイムスタンプカラムによる絞り込みWHERE句をくっつけて定期的に実行するので、実際には以下のようなクエリが動くことになります。
SELECT * FROM MyTable WHERE UpdatedAt > @LAST_POLL_TIMESTAMPしかしSpannerではこのクエリでは問題になる可能性があります。Audit Columns方式ではクエリのパフォーマンスを向上させるためタイムスタンプカラム(ここでは UpdatedAt )にインデックスを張るのが一般的ですが、Spannerではタイムスタンプのような、値が単調増加・減少するカラムにインターリーブされていないインデックスを作成することはホットスポットを発生させる原因になるため、アンチパターンとなっています(詳しく知りたい方は公式ドキュメントのスキーマ設計ガイド をご覧ください)。
これを回避するため、ベストプラクティス に従い ShardIdカラムを用いたインデックスを作成します。
CREATE INDEX MyIndex ON MyTable(ShardId,UpdatedAt);JDBC Connectorの設定では、WHERE句を直接変更することはできないようなので、以下の様にqueryを変更することでこのインデックスを利用できるようになります。
"query": "SELECT * FROM ( SELECT * FROM MyTable@{FORCE_INDEX=MyIndex} WHERE ShardId BETWEEN -15 AND 15)"Spanner Change Stream の登場
SpannerでのAudit Columns方式ではこのようなひと手間が必要だったり、前述したように削除データの連携もできません。Audit Columnsを選択した理由はSpannerからトランザクションログが取得できなかったからですが、先日ついに Spanner Change Stream がアナウンスされました 。今後はこちらへの置き換えを検討していきたいと考えています。
Flink on K8s
メルペイDataPlatformではストリーミング処理の基盤としてFlinkを採用し、多くのストリーミングアプリケーションを開発運用しています。CDCパイプラインのデータのBigQueryへの配送にもFlinkを使っています。Flinkは障害耐性が高く、データをロストすることなく配送できるアーキテクチャを備えています。特にセーブポイントやチェックポイントの仕組みがあることにより、AtLeastOnceにデータを配送できます。
Flinkアプリケーションは全てK8s上で動かしています。FlinkアプリケーションをK8s上で実行する方法として、ジョブマネージャとタスクマネージャのDeploymentのYAMLを記述してStandaloneクラスタを構築する方法以外に、K8sのオペレーターを使う方法や、Flink自体のK8sネイティブサポート機能を使う方法があります。メルペイDataPlatformでは以前はGCPのアンオフィシャルなK8sのオペレーターflink-on-k8s-operatorを利用して、
SessionModeのStandaloneクラスタを構築して動かしていました。Flink 1.13からReactiveModeというオートスケーリング機能が実装されましたが、ApplicationModeでしか利用できません。flink-on-k8s-operatorはSpotifyがフォークして開発を進めていますが、ApplicationModeには未対応です。FlinkのK8sネイティブサポート機能もReactiveModeに対応していません。このオートスケーリングの機能は、今後積極的に使っていきたいと考えているので、新規で構築するFlinkアプリケーションは全てDeploymentのYAMLを記述する形で、ApplicationModeのStandaloneクラスタで動かしています。flink-on-k8s-operatorで動かしていたアプリケーションは順次移行を進めています。K8sのオペレーターは、オフシャルのオペレーターの開発が始まっています。現在は0.1.0がリリースされており、今後はFlinkをK8sで動かす場合のデファクトスタンダードになるのではないかと期待しています。
FlinkはK8s上でZookeperを使わずにHA構成を簡単に構築することができます。HA構成にすることで単一障害点となるジョブマネージャを複数台起動できるようになり、ノードやPod、ジョブが落ちても最新のチェックポイントから自動的に復旧することができます。HA構成の情報は自動的にConfigMapで管理されます。セーブポイントやチェックポイントの管理にはGCSを利用しています。
CDCパイプラインのデータを配送するFlinkアプリケーションでは、Debeziumのbefore/afterフィールドをJSON文字列に変換してBigQueryに配送しています。BigQueryへの書き込みはStreaming APIを利用していますが、Storage Write APIがGAになったので置き換えを進めています。FlinkにはBigQueryのコネクタ実装がないので、自前でScalaで実装しています。機会があればJavaで書き直し、OSSとして公開したいと考えています。
神View
Debeziumのデータは、Flinkアプリケーションでbefore/afterフィールドをJSON文字列化して、MySQLの場合は以下のようなスキーマでテーブルごとにBigQueryに配送されます。
| Field | Type | Mode |
|---|---|---|
| key | STRING | NULLABLE |
| before | STRING | NULLABLE |
| after | STRING | NULLABLE |
| op | STRING | NULLABLE |
| ts_ms | TIMESTAMP | NULLABLE |
| transaction | STRING | NULLABLE |
| database_name | STRING | NULLABLE |
| ddl | STRING | NULLABLE |
| source | RECORD | NULLABLE |
| source.version | STRING | NULLABLE |
| source.connector | STRING | NULLABLE |
| source.name | STRING | NULLABLE |
| source.ts_ms | TIMESTAMP | NULLABLE |
| source.snapshot | STRING | NULLABLE |
| source.db | STRING | NULLABLE |
| source.table | STRING | NULLABLE |
| source.server_id | INTEGER | NULLABLE |
| source.gtid | STRING | NULLABLE |
| source.file | STRING | NULLABLE |
| source.pos | INTEGER | NULLABLE |
| source.row | INTEGER | NULLABLE |
| source.thread | INTEGER | NULLABLE |
| source.query | STRING | NULLABLE |
各テーブルの初期構築用のスナップショットデータは、CDCパイプラインとは別にバッチ処理(DataflowやSparkを利用)でBigQueryにアップロードしています。この初期構築用のスナップショットデータとストリーミングで配送されるJSON形式のDebeziumのデータをうまくUNIONして、常に最新のデータが参照できるViewを作成しています。
具体的にMySQLのitemsというテーブルを例にして説明します。
itemsテーブルのMySQLのスキーマは以下です。
CREATE TABLE `items` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`created_at` datetime NOT NULL,
`updated_at` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4BigQueryのViewは以下のようなクエリになります。cdc-project.cdc_dataset.items が初期構築用のスナップショットデータが格納されているテーブルで、cdc-project.cdc_dataset.binlog_items がFlinkアプリケーションが配送するJSON形式に変換されたDebeziumのデータが格納されているテーブルです。
WITH
binlog AS (
SELECT
* EXCEPT(row_number)
FROM (
SELECT
CAST(JSON_EXTRACT_SCALAR(key, '$.id') AS INT64) AS id,
CAST(JSON_EXTRACT_SCALAR(after, '$.name') AS STRING) AS name,
TIMESTAMP_MILLIS(CAST(JSON_EXTRACT_SCALAR(after, '$.created_at') AS INT64)) AS created_at,
TIMESTAMP_MILLIS(CAST(JSON_EXTRACT_SCALAR(after, '$.updated_at') AS INT64)) AS updated_at,
ts_ms AS binlog_ts_ms,
source.pos AS binlog_pos,
source.row AS binlog_row,
ROW_NUMBER() OVER (PARTITION BY key ORDER BY ts_ms DESC, source.pos DESC, source.row DESC) row_number
FROM
`cdc-project.cdc_dataset.binlog_items`
WHERE
op = 'c'
OR op = 'u'
)
WHERE
row_number = 1
),
delete_binlog AS (
SELECT
CAST(JSON_EXTRACT_SCALAR(key, '$.id') AS INT64) AS id,
ts_ms AS binlog_ts_ms,
source.pos AS binlog_pos,
source.row AS binlog_row,
FROM
`cdc-project.cdc_dataset.binlog_items`
WHERE
op = 'd'
),
binlog_row AS (
SELECT
*
FROM
binlog t1
WHERE
NOT EXISTS (
SELECT
1
FROM
delete_binlog t2
WHERE
(
t1.id = t2.id
AND t1.binlog_ts_ms < t2.binlog_ts_ms
)
OR
(
t1.id = t2.id
AND t1.binlog_ts_ms = t2.binlog_ts_ms
AND t1.binlog_pos < t2.binlog_pos
AND t1.binlog_row <= t2.binlog_row
)
))
SELECT
*
FROM
binlog_row
UNION ALL
SELECT
*
FROM (
SELECT
id,
name,
created_at,
updated_at,
binlog_ts_ms,
binlog_pos,
binlog_row
FROM
`cdc-project.cdc_dataset.items` tt1
WHERE
NOT EXISTS (
SELECT
1
FROM
binlog_row tt2
WHERE
tt1.id = tt2.id
)
) t1
WHERE
NOT EXISTS (
SELECT
1
FROM
delete_binlog t2
WHERE
(
t1.id = t2.id
AND t1.binlog_ts_ms < t2.binlog_ts_ms
)
OR
(
t1.id = t2.id
AND t1.binlog_ts_ms = t2.binlog_ts_ms
AND t1.binlog_pos < t2.binlog_pos
AND t1.binlog_row <= t2.binlog_row
)
)クエリの内容はここでは詳しく説明しませんが、JSON形式のデータをパース、DebeziumのINSERT、UPDATE、DELETEのイベントをうまく時系列に反映させる形になっています。このViewはメルペイDataPlatformでは神Viewと呼ばれており、Jinjaテンプレート化され、MySQLやPostgreSQLのインフォメーションスキーマからPythonスクリプトで自動的に生成できるようになっています。PythonスクリプトはCLIツールとしてパッケージングされており、kamiというコマンド名で実行ができるようになっています。kamiコマンドはコンテナで簡単に実行できるようにしており、K8sのジョブを実行するだけでこの神Viewを自動的にBigQueryに生成することができます。
このViewは定期的にマテリアライズ処理され、クエリの実行速度が気になる場合は、マテリアライズしたデータを参照できるようにもしています。さらにJSON形式のDebeziumのデータは、定期的に実テーブル化するような処理を行い、削除(実際には削除せずに別テーブルにアーカイブ)して神Viewのクエリができる限り重くならないようなバッチ処理も行っています。
それ以外にも、DBの変更の履歴が全て閲覧できることになるので、そのような履歴が見れるようなデータの作成もバッチ処理で行い、データ分析等に利用しています。今まではこのような履歴データを収集することは難しかったのですが、CDCパイプラインによって簡単にこのようなデータを収集することが可能となり、データ分析に利用できるようになったのは大きな成果だと思います。
まとめ
Confluent Cloudを利用することで、Kafkaの運用コストを最低限に抑えつつ、Kafkaのエコシステムである豊富なコネクターを利用できるようになり、複数あるデータソース・シンクの組み合わせのパイプラインを柔軟かつ迅速に構築することができるようになりました。
結果ニアリアルタイムのデータ連携要件にスピード感を持って対応できるようになり、社内での利用も増えつつあります。
今後もより多くのデータソースやユースケースへ対応していくとともに、Flinkのオートスケール、SpannerのChange Stream などに取り組み、改善をしていきたいと考えています。




