はじめに
こんにちは、ソウゾウSoftware Engineerの@sue71です。連載:メルカリShops 開発の裏側 Vol.2の13日目を担当させていただきます。
以前メルカリメルカリShopsの技術スタックと、その選定理由でBFFの実装にGraphQLを採用していることをお伝えしました。メルカリShopsをリリースしてから約半年たった今、これまでを振り返ってGraphQLサーバーを実装する上での課題やあらかじめ考えておくと良い項目をまとめてみました。また、本記事ではメルカリShopsでGraphQLの実装としてApolloを採用しているため、Apolloの利用が前提の話もいくつか混在しています。予めご容赦ください。
GraphQLの説明や、メルカリShopsの実装方法に関しては以前こちらの記事で紹介しています。こちらも是非ご覧ください。
パフォーマンス課題
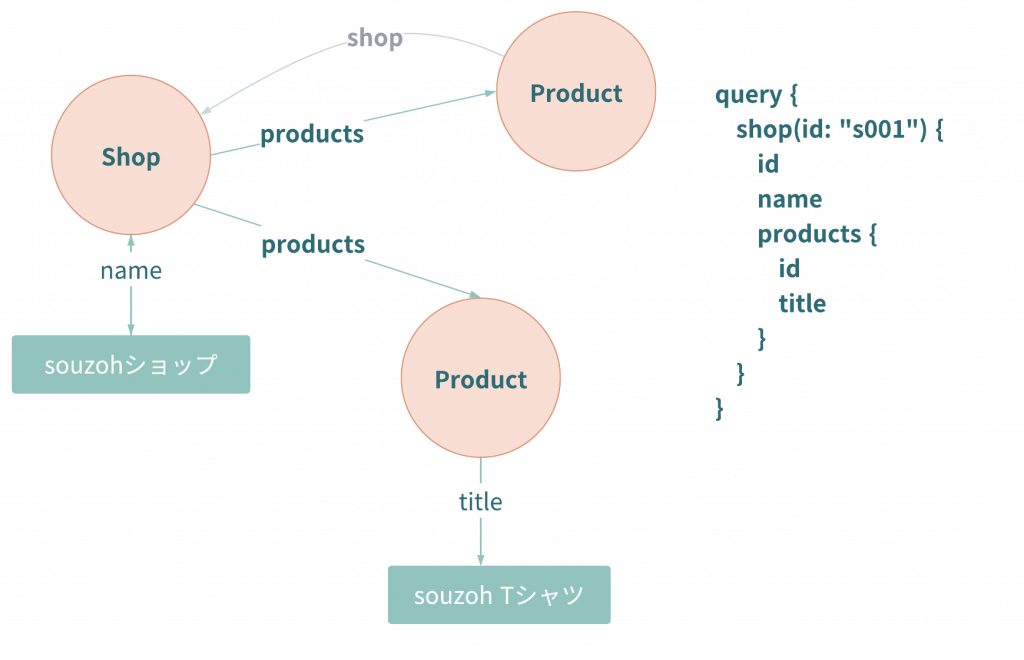
GraphQLは、アプリケーションのデータモデルを表したグラフ構造から、特定のノードから始まる木構造を取り出し、リソースの読み込みを解決していくというコンセプトで作られています。
クライアントはグラフ構造に沿って柔軟にデータを取得できますが、柔軟ゆえに引き起こされるパフォーマンス課題がいくつかあります。
N+1問題への対処
GraphQLでは木構造をたどりながらその都度リソースの読み込みを解決していくので、しばしばN+1問題が起こります。
次のクエリではproductを100件取得していますが、それぞれのノードでshopを取得することになるので、愚直に実装するとshopの取得が100回呼び出されることになります。
query {
products(first: 100) {
edges {
node {
shop {
id
name
}
}
}
}
}
N+1問題の解決方法として、リソースの先読みやリソースの遅延読み込みがありますが、メルカリShopsではできるだけ実装を再利用するため、DataLoaderを利用した遅延読み込みを採用しています。
DataLoaderの説明やメルカリShopsの対応方法はこちらで解説しているので是非ご覧ください。
Query complexityの計測
Query complexityとはクエリの複雑さをコストとして数値化したものです。コストの計算方法は明確な仕様が定められているわけではなく、ライブラリによってまちまちです。
例えば、GitHub API v4ではノード数に対して制限を設けており、下記クエリの場合、次のように計算されます。
complexity = productノード数(100) + shopノード数(10)
query {
shops(first: 10) { # ノード数 10
edges {
node {
products(first: 10) { # ノード数 10 x 10 = 100
edges {
node {
id
}
}
}
}
}
}
}ほとんどの場合、アプリケーション側でカスタマイズできるので、コストの高いフィールドには個別で高い数値を割り当てるなどの最適化も可能です。Query complexityを予め計測しておくことで、特定のクエリやページ単位のコストを制限したり可視化してパフォーマンスを意識できます。
メルカリShopsではApolloServerのプラグインを実装し、graphql-query-complexityを利用してリクエストごとに検証・ロギングしています。
Persisted Queriesの利用
GraphQLを利用する場合、REST APIと対比して次のような課題があります。
- GraphQLのクエリの複雑さに比例して、リクエストボディが肥大化する
- GraphQLではPOSTを使用するためHTTPキャッシュに乗らない
実際のところGETを利用することもできるのですが、GraphQLクエリやvariablesを全てクエリパラメータに含めた場合、サーバーやCDNの実装によってはURLのサイズ制限にひっかかる可能性があるため、そのままではCDNなどに乗せるのは難しいということになります。
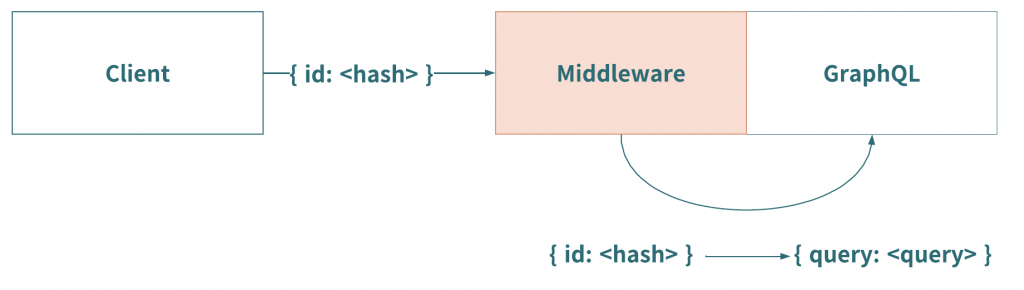
そこでクエリに対応するIDを予め用意し、GraphQLサーバーの前段でIDとクエリを交換することでリクエストパラメータを小さく収めようというのがPersisted Queriesです。交換のためのエンドポイントをGETで受け取るようにすれば、CDNなどのキャッシュサーバーに乗せることも可能です。
メルカリShopsでは、Next.jsによって生成されるHTML / next data jsonをCDNにキャッシュしているため、2に関しては今の所ボトルネックになっていません。しかしSSRを利用していないページのパフォーマンス最適化や、許可していないクエリの制限などの恩恵もあるので、導入を検討したい機構の一つです。
メルカリShopsのキャッシュ戦略についてはメルカリShopsのフロントエンドで紹介しているので是非こちらも御覧ください。
データストアによるキャッシュ
アプリケーションのキャッシュに関しては一般的なREST APIと大きな違いはありません。リソース解決のタイミングで、必要に応じてRedisやMemcacheなどのデータストアを利用します。ただし、DataLoaderを利用している場合は少し工夫が必要になります。DataLoaderのキャッシュ機構はリクエスト単位のキャッシュを目的としているので、ある程度有効期限のあるキャッシュを共有したい場合は、バッチ取得用の関数で別途調整する必要があります。
メルカリShopsではDataLoaderのキャッシュレイヤーとしてRedisを採用しており、DataLoaderのラッパーを実装しています。次のコードは実際のものではありませんが、 ioredis を利用した場合の処理の流れを示しています。Redis経由でデータを取得し、キャッシュが存在しない場合は通常のDataLoaderを経由してキャッシュの保持と取得を行います。
import DataLoader from 'dataloader';
import Redis from 'ioredis';
const client = new Redis();
// (1) 通常のリソース解決を行うDataLoader
const dataLoader = new DataLoader((keys) => {
// バッチでリソースを取得する処理
});
// (2) キャッシュを管理するDataLaoder
const redisLoader = new DataLoader(
(keys) =>
new Promise((resolve, reject) => {
client.mget(keys, (error, results) => {
// ...(省略)
Promise.all(
results.map((result, index) => {
// ...(省略)
// キャッシュが存在しない場合、(1)を利用してリソースを解決する
return dataLoader.load(keys[index]).then((value) => {
// ...(取得した値をRedisにセットする処理)
return value;
});
})
).then(resolve);
});
})
);
// 呼び出し側は(2)を利用してリソースを解決する
redisLoader.load("xxx");セキュリティ課題
様々なメリットのあるGraphQLですが、クエリの柔軟性や、開発効率を上げるための機能が意図せず脆弱性に繋がる可能性があります。本節では、一般的なwebアプリケーションの脆弱性に加えて対応が必要な項目をまとめてみました。
クエリのコスト制限
GraphQLではクライアントでレスポンスの内容を決定できるので、簡単に負荷の高いクエリを投げることができます。例えば次のように循環参照を利用すると無限の数のノードをリクエストすることができます。
query {
shop(id: "xxx") {
products(first: 100) {
shop {
products(first: 100) {
shop {
products(first: 100) {
shop {
…
}
}
}
}
}
}
}
}
Query depth
Query depthとはクエリのコストを深さで表したものです。前述のクエリのようなネストの深いクエリは通常のアプリケーションで使用されることはあり得ないので、深さに一定の制限を設けることで、比較的簡単に高負荷なQueryの実行を防ぐことが出来ます。
Query complexity
前節でも紹介したQuery complexityですが、セキュリティ対策としても利用できます。depthと同様に計算したコストにしきい値を設けることで、より多くのケースに対応できます。例えばdepthでは次のようなクエリには対応できません。
query {
products(first: 100) {
highCostCalcurationResult # CPU負荷が高い処理
}
}highCostCalcurationResult は単体のProductから解決されることを意図しているので通常利用では問題ありませんが、このクエリのように複数ノードに対して呼び出されるとサーバーのリソースを意図的に枯渇させることができます。
ある程度柔軟に制限を設けられる一方で、コストを適切に管理し、妥当なしきい値を割り出すのは難しい面もあります。まずはロギング目的で道入して徐々に最適化してくのも良いかもしれません。
Query rate limit
Query complexityによる制限は一度のリクエストに対してかける制限ですが、算出したコストを利用して時間単位で制限を設けるQuery rate limitという方法があります。
GitHub API v4で使用されている方法で、一定期間のクエリのコストを累積し、しきい値を超えた場合利用者に制限を課します。GitHubのようにサードパーティにAPIを公開する場合は有効な手段かもしれません。
GitHubのrate limit仕様はresource-limitationsを参照ください。
Introspection query
IntorospectionとはGraphQLスキーマ情報を取得するための仕様で、サーバーから直接使用可能なQueryなどの情報が得られます。
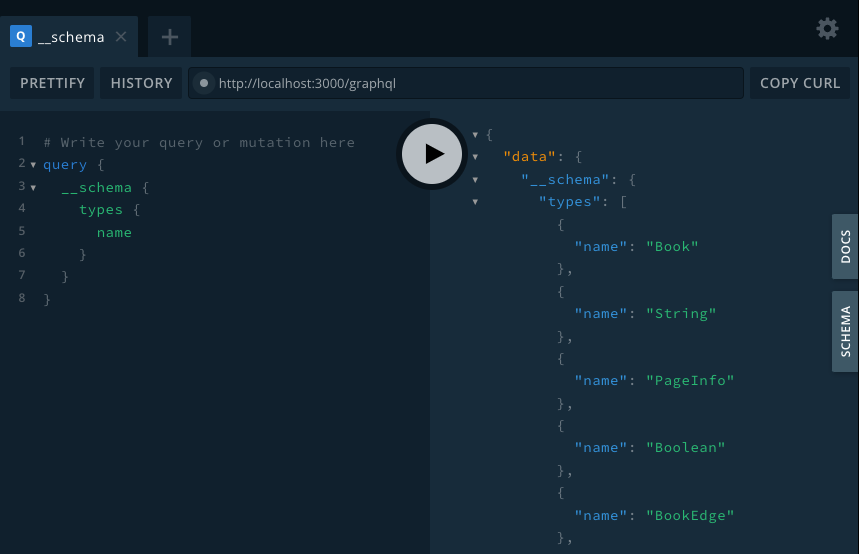
開発時はQueryの作成やコード生成に利用することができて非常に便利な仕様です。しかし、悪意のあるユーザーが簡単に処理の内容を知ることができてしまうため、攻撃のスキを与えることになってしまいます。
ApolloServerを利用している場合はintrospectionオプションで設定可能で、NODE_ENVがproductionの場合デフォルトでオフになります。
Field suggestion
ApolloServerを利用している場合、スキーマに存在しないqueryやフィールドを解決しようとした時に、「もしかしてxxxのことを指していますか?」というよう提案してくれることがあります。
{
"error": {
"errors": [
{
"message": "Cannot query field \\"producte\\" on type \\"Query\\". Did you mean \\"product\\"?",
"locations": [
{
"line": 2,
"column": 3
}
]
}
]
}
}開発時は便利な機能ですが、これもIntorospectionと同じように脆弱性に繋がります。
ApolloServerを利用している場合は下記のようにformatErrorに改修を加えることで制御できます。
const server = new ApolloServer({
...
formatError: (err) => {
if (isProduction && error instanceof ValidationError) {
return new ValidationError('Invalid query');
}
return err;
},
});スタックトレース
これもGraphQLに限った話ではありませんが、ApolloServerなどの実装では、エラーの内容にスタックトレースが含まれます。スタックトレースにはディレクトリ構造などが含まれるため、意図せず秘匿情報を公開してしまう可能性があります。
{
"error": {
"errors": [
{
"message": "Cannot query field \\"booke\\" on type \\"Query\\". Did you mean \\"books\\"?",
"locations": [
{
"line": 2,
"column": 3
}
],
"extensions": {
"code": "GRAPHQL_VALIDATION_FAILED",
"exception": {
"stacktrace": [
"GraphQLError: Cannot query field \\"booke\\" on type \\"Query\\". Did you mean \\"books\\"?",
" at Object.Field (/path_to_app/node_modules/graphql/validation/rules/FieldsOnCorrectTypeRule.js:48:31)",
" at Object.enter (/path_to_app/node_modules/graphql/language/visitor.js:323:29)",
" at Object.enter (/path_to_app/node_modules/graphql/utilities/TypeInfo.js:370:25)",
" at visit (/path_to_app/node_modules/graphql/language/visitor.js:243:26)",
" at Object.validate (/path_to_app/node_modules/graphql/validation/validate.js:69:24)",
" at validate (/path_to_app/node_modules/apollo-server-core/dist/requestPipeline.js:233:34)",
" at Object.<anonymous> (/path_to_app/node_modules/apollo-server-core/dist/requestPipeline.js:119:42)",
" at Generator.next (<anonymous>)",
" at fulfilled (/path_to_app/node_modules/apollo-server-core/dist/requestPipeline.js:5:58)",
" at processTicksAndRejections (node:internal/process/task_queues:96:5)"
]
}
}
}
]
}
}ApolloServerの場合debug オプションによって設定可能で、NODE_ENVがproductionの場合はデフォルトでオフになります。
スキーマ設計
最後にGraphQLを運用する上で最も重要なスキーマ設計に関してです。これまで説明してきた内容は比較的開発を進めつつ改修可能な内容でしたが、スキーマ設計は一度サービスをリリースしてしまうと大きく変更を加えることは互換性の観点から困難になります。予めチームで方針をすり合わせてから開発することをおすすめします。
リソースのグラフ構造の保守
GraphQLの設計はリソースを中心にグラフを構築していくことが前提となっているので、このグラフ構造が破綻すると途端に扱いにくいものになります。
グラフ構造が整理されていない場合、とある画面では本来は単一のリクエストで済むはずが、直列に2つのリクエストが発生したり、ユースケースごとにQueryを追加する羽目になります。
メルカリShopsの商品詳細の実装を考えます。商品詳細では商品そのものと、その商品がどのショップから出品されたのかという情報を表示します。
query ($id: String!) {
product(id: $id) {
id
shopId
...
}
}
query ($shopId: String!) {
shop(id: $shopId) {
id
...
}
}
商品を一件取得するQuery productとショップを一件取得するQuery shopが既に存在する場合、商品はショップへの関連を持つため、shopIdを利用して2回に分けて取得することができます。しかしこれはグラフ構造の構築をクライアント側に持たせることになる上、パフォーマンス面でも最適化されていません。グラフの構造上、商品から直接ショップを参照するべきです。
# product queryの実行結果にshopを含める
query ($id: String!) {
product(id: $id) {
id
shop {
id
}
}
}RESTの場合、関連するリソースを全て結果に含めてしまうと、レスポンスが肥大化してしまうため、常にこの設計にするのは難しい面があります。しかしGraphQLではクライアントが要求しない限りサーバー側で処理を行うことは無いので、フィールドに直接埋め込むことが出来ます。
今回紹介した例は典型的なGraphQLのアンチパターンですが、ユースケースごとに機能を追加しているとつい、リソースのグラフ構造の関係性があいまいになるものです。新たなオブジェクトやフィールドを追加する際は、全体のグラフ構造に立ち返って慎重に議論する必要があります。
ID表現
facebookが開発しているRelayプロジェクトではGraphQL Server Specificationが公開されています。GraphQLのスキーマ設計のベストプラクティスをまとめたもので、Relayをクライアントとして使用しない場合でも、この仕様を参考に実装されているサーバーやクライアントは数多くあるので参考にすると上手くいくケースが多いです。
Global Object Specificationもその一つで、ID表現のベストプラクティスとして紹介されています。
REST APIなどを利用している場合、URLをベースにHTTPキャッシュを利用することができますが、GraphQLの場合はURLなどの識別子が存在しないため、キャッシュのための識別子として、リソースに対してグローバルなIDが必要になります。例えばProductのIDがp001の場合Product:001のようなIDを生成し、リソースを横断してユニークな状態を担保します(base64などで再度エンコードするのが一般的です)。
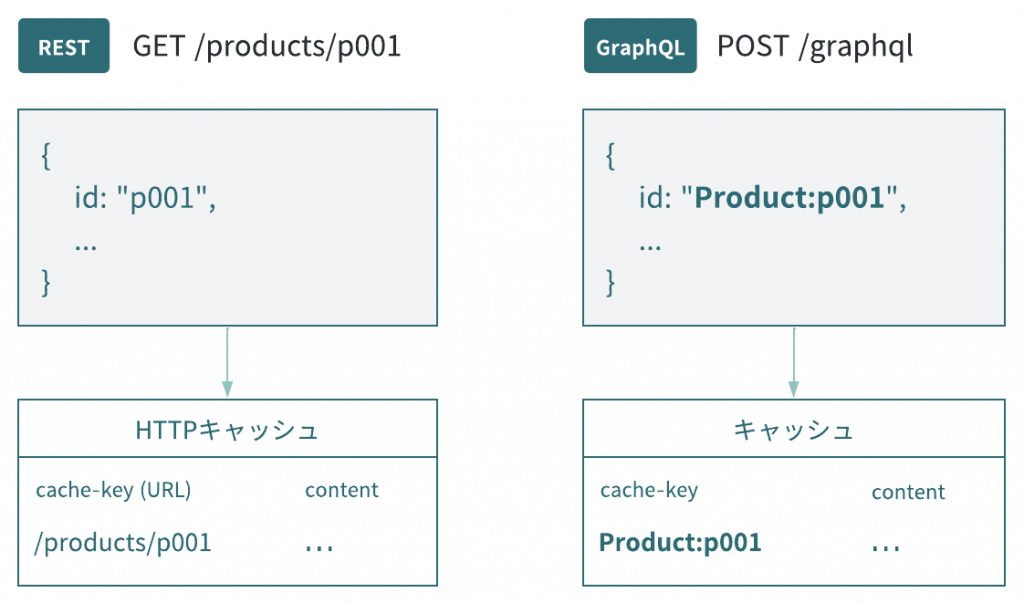
またIDからリソースの種別も判別できると次のように単一のqueryでリソースの取得ができるので再取得の実装が簡単になります。
query {
node(id: “Product:p001”) {
id
... on Product {
name
}
}
}
}とはいえ、BFF+micro serviceのような構成だとdata source側でグローバルにユニークなIDを割り振る仕組みを提供するのは難しいかもしれません。その場合GraphQLレイヤーでIDを再構築します。
メルカリShopsでは残念ながら本仕様に沿って作られていませんが、ApolloClientではデフォルトで__typeNameとリソースのIDを組み合わせたものをキャッシュキーとして利用します。これは正に、前述した仕様でも代替手法として上げられている方法です。
ちなみに以上のことから識別子を持たないただのオブジェクトなどを返却する場合は注意が必要です。IDなどの識別子がない場合、クライアント側が持つオンメモリのキャッシュは更新されないからです。
ページネーション表現
GraphQLに限らず、ページネーションのインターフェースを揃えておくことは呼び出し側の仕組みを再利用する上で重要ですが、ApolloやRelayなどのクライアントを利用している場合は、それ以上の意味を持ちます。
GraphQLではキャッシュを効率的に利用するためのベストプラクティスとして、Connectionsというカーソルベースのページネーションが紹介されています。
例えばproductのリストを取得する場合次のようなクエリになります。
{
products(first: 100, after: "cursorid") {
edges {
cursor
node {
id
}
}
pageInfo {
hasNextPage
startCursor
endCursor
}
}
}
Connectionsは次の要素で構成されます。
- サイズを指定する引数
first、カーソル位置を指定する引数after - 各ノードに対応した
cursorを持つedges - ページ情報を持つ
pageInfo
各ノードがcursorを持っていますが、これはクライアントでキャッシュを効率的に使用するためのものです。例えばある画面で10件データを取得し、違う画面で同じリソースを5件取得した場合、サーバーから再度データを取得せずとも正しいpageInfoを再構成することができます。
メルカリShopsのユースケースではpageInfoの持つstartCursorとendCursorで十分なので、各edgeのcursorは省略しています。
また、Relayをベースにした仕様ですが、ApolloClientを利用している場合も次のようにtypePolicyを設定することで、簡単にオンメモリのキャッシュを更新できます。
import { relayStylePagination } from '@apollo/client/utilities';
const client = new ApolloClient({
cache: new InMemoryCache({
Query: {
fields: {
products: relayStylePagination({...}),
},
},
}),
});Mutationのレスポンス表現
これはRESTの場合も同じことが言えるのですが、クライアントにリソースの変更内容を通知するために、Mutationの返却値は変化が起きたリソースをそのまま返すのが望ましいです。
前項でも説明したように、ApolloやRelayなどのクライアントではGraphQLのレスポンスは正規化してオンメモリ上にキャッシュされるため、レスポンスにリソースを返却することで自動的にキャッシュも更新されます。レスポンスにリソースが含まれない場合、クライアントは再度リソースを指定して取得する必要があります。また、ここで前項のID仕様に従ってqueryが構築されていると再取得が簡単になります。
メルカリShopsでは残念ながら全てのMutationで対応できているわけではありませんが、徐々に改修を進めています。
スタイルガイドの策定
これまでいくつかスキーマ設計のヒントとなる情報を紹介してきましたが、命名規則やスキーマ言語としての機能の利用方針など、議論の対象は数多くあります。レビューで変更を議論するのはもちろんですが、スタイルガイドのような土台があるとレビューのコストが減り、オンボーディングツールとしても役立ちます。
次のリンクは、普段私が参考にしているAPIやガイドから抜粋したものです。どれも汎用的で実用的な情報がわかりやすくまとまっています。最初は下記のような既存のガイドを参考に進めるのが良いかもしれません。
メルカリShopsでは今の所こういった運用はできていませんが、全員ソフトウェアエンジニアという体制を支援するためにも、スタイルガイド策定に取り組んで行きたいと思っています。
おわりに
この記事ではGraphQLを運用する上で予め考慮したほうが良い基本的な項目をいくつか紹介しました。ここまで紹介してきた内容全てを対応する必要はありませんが、新たにGraphQLの運用を始める際、議論の参考にして頂けると幸いです。
メルカリShopsでもまだまだ課題は山積みです。一緒に課題を解決していけるメンバーを大募集中なのでメルカリShopsの開発やソウゾウに興味を持った方がいればぜひご応募お待ちしています。
詳しくは以下のページをご覧ください。
- Software Engineer
- Software Engineer, Site Reliability
- Software Engineer, Machine Learning
- Software Engineer, QA Test
- Software Engineer (Internship) – Mercari Group (※新卒採用に応募するにはまずインターンへの参加をお願いしています。)
またカジュアルに雰囲気や話だけ聞いてみたい、といった方も大歓迎です。こちらの申し込みフォームよりぜひご連絡ください。




