はじめに
はじめまして、@takashi-kun です。
自分が所属するチームでの連載企画 "Blog Series of Introduction of Developer Productivity Engineering at Mercari" 、今回はメルカリが成長を続けている中で多くのレガシーな技術と私達 Core SRE チームがどのように向き合っているか具体例を基に紹介します。
突然ですが、「レガシーな技術」と聞いて何を思い浮かべるでしょうか?
古いミドルウェアを利用している、昔の言語で書かれている、オンプレ環境を利用している、などなど、いろいろな定義が浮かぶと思います。
メルカリは事業スピードの加速に伴いシステムが日々拡張/拡大されていくため、「owner/maintener ともに存在しないシステム」が少なからず存在します。owner も maintener もいない中でシステムの概要を把握しつつアラート対応や移設などを行うことは、注意しなければならないポイントが多岐にわたるだけでなく影響範囲も把握しにくいため、とても大変な作業となります。
本記事ではこのような「owner/maintener ともに存在しないシステム」を「レガシーなシステム」と定義し、そのようなシステムには大きく分けて Stateful/Stateless の2つに分類できます。Stateless は一般的に状態を持たないサーバで、主に API サーバや Proxy サーバなどがあげられます。一方 Stateful なサーバは DB に代表されるような状態(データ)を持つようなものです。今回の記事では先程定義した「レガシーなシステム」において Stateful/Stateless なシステムを一つずつ選び、それぞれにどのような調査と改善を行っているかについてご紹介します。
Stateless な oauth-proxy
まず Stateless なシステム oauth-proxy についてお話します。現在私達は大きなデータセンター移管作業を行っており、その対象として古くから稼働している oauth-proxy というシステムがあります。
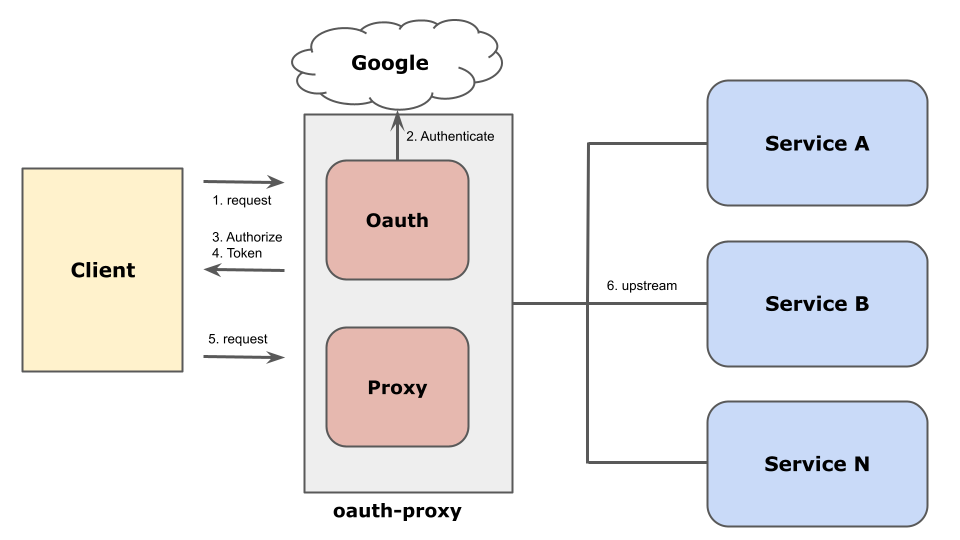
oauth-proxy は上図のように様々な社内システムのアクセス制御を Google account、group、organization 単位で行うための認証基盤システムです。
この oauth-proxy を移設するにあたって、今回私達は Identify-Aware Proxy(以下 IAP)の利用を検証しました。
Identify-Aware Proxy の利用
IAP は Google workspace の User、Group、ServiceAccount、Organization などの単位でアクセス制御をするための proxy で、proxy という名の通り HTTP(S) LoadBalancer や GCE への TCP レベルでのアクセス制御を行うことができます。
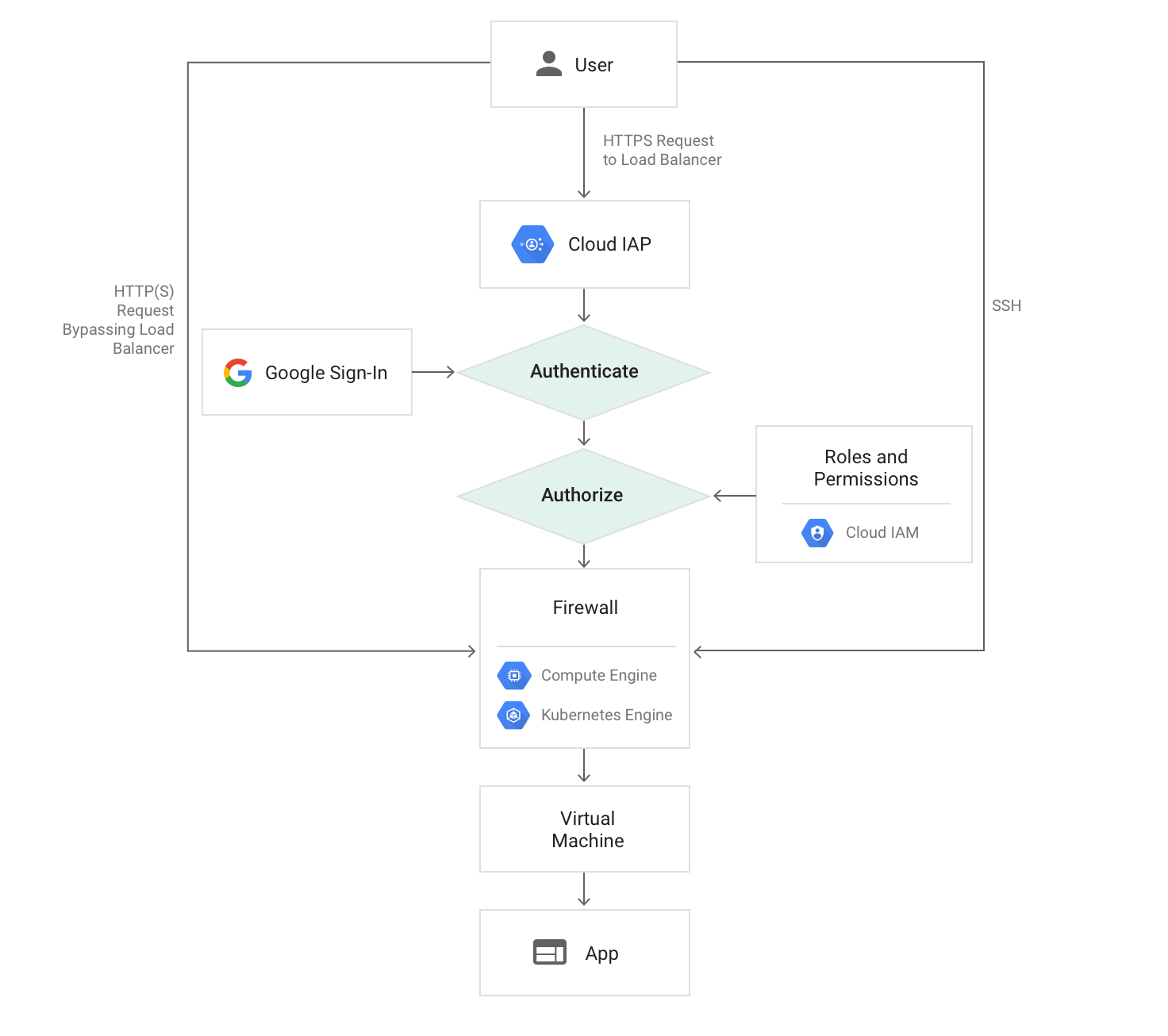
(https://cloud.google.com/iap/images/iap-load-balancer.png)
Load Balancer の Backend は GCE だけでなく GAE や CloudRun など Google managed なサービスを選ぶことも可能なため、今回 IAP を利用できるようにすればいずれは完全に GCP managed service への移管もできます。
先程の図の oauth-proxy はやっていることがほとんどこの IAP で置き換え可能であるため、移設にあたって Google managed なサービスを利用したいと思ったことが動機でした。
結論から言うと今回は IAP を用いた移設をすることができませんでした。
oauth-proxy のバックエンドの殆どのサイトでは入れ替え可能だったのですが、とある1つのサービスのみ入れ替えが難しいということがわかりました。
そのサービスとは db-proxy と呼ばれるもので、下記の構成になっています。
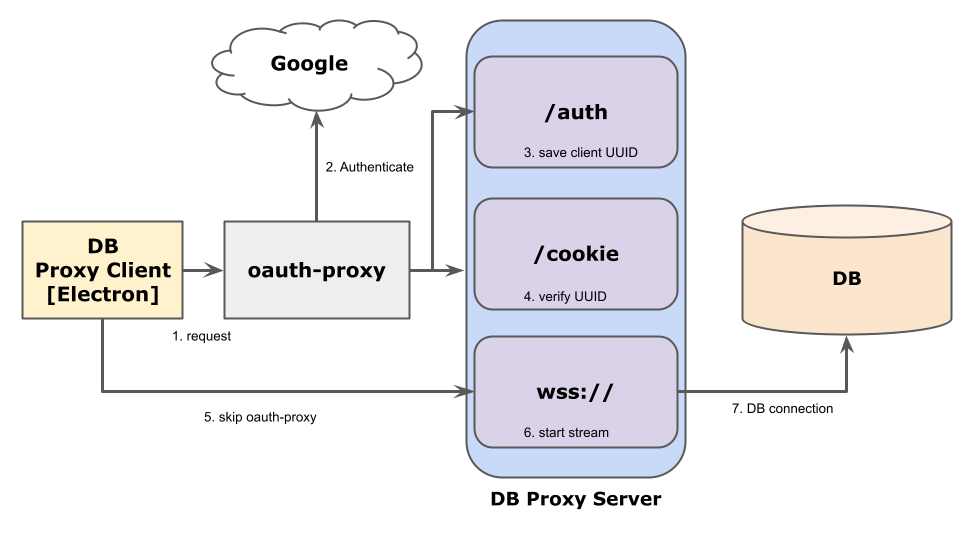
最初に /auth にリクエストしたときに、oauth-proxy 経由で authenticate/aurhorize し、その後 client 側で生成した uuid を DB proxy server で保存します。次に /cookie へのリクエストで /auth で保存した uuid と一致するかを調べます。それに成功すると wss:// の Socket を open し DB への proxy として local port を listen します。wss:// のリクエストは oauth-proxy で Google 認証を突破するための Cookie が /auth の際に生成されているため wss の socket を開く際には実際はskip されます。
ここで IAP 移行を考えたときに問題になるのが次の点です:
IAP Skip のリクエストのための認証情報には Cookie を利用できない最初の /auth や /cookie などエンドポイントは IAP を通過後サーバ側で操作できるのですが、その後の wss リクエスト時に IAP を skip するためには Authorization Header が必要でそれをクライアント側を改修しないまま行うのは不可能でした。
クライアント側の改修も利用者が数百人単位でいたため、すべてのアップデートの周知と担保を owner/maintener を自分が担当しつつ数週間で行うことは難しいと判断したこと、 SSL 証明書を Google managed にするときに無停止でサービスの切り替えが不可能なことなど、 IAP 導入のために超えなければならない障壁を全て解決することが難しかったため、今回は導入を見送りました。
導入することはできませんでしたが、 IAP 導入に向けて Cloud Certificate Manager の必要性や
CloudRun を使った proxy 構築などの新技術だけでなく DB Proxy Client で利用されていた Electron、 IAP で権限管理するために Google Workspace の organization 構造といったような、SRE だけでは検証できないことも触れられてたくさんの知見を得られました。
また、IAP 移行のブロッカーとなっている db-proxy ですが接続先の DB は前日の「特殊な構成のMySQLに対するDDL適用の一例」で述べられている DB で、それ自体を BigQuery に移管することでこの db-proxy を廃止できるので IAP 導入のために現在「特殊な MySQL」の移行作業をしています。
Stateful なレガシー MySQL server
続いて Stateful なレガシーシステムについてです。それは現在私達が運用しているシステムの中で最も大きな課題でもあるメルカリの根幹の MySQL DB たちです。
その課題は単純で、メルカリの事業成長に伴い MySQL のデータサイズ、buffer pool size が肥大化し続けていて、インシデントや脆弱性対応など、今後も安定運用し続けるには困難なレベルまで大きくなっているということでした。
一般的に大きくなりすぎた DB は垂直分割、更には水平分割をしてキャパシティと安定性を確保することが多いと思います。
メルカリでも同様のアプローチを取ってキャパシティと安定性の確保に努めてきました。
まず、垂直分割ではテーブルをデータの系統ごとで分割をしていきましたが、超巨大なテーブル数個が互いに密結合してしまっておりこれ以上の分割は望めないというレベルまでなりました。
続いて水平分割ですが、水平分割を行うためにはアプリケーション側への大幅な変更が伴い、現在進めている microservice 化と並行で行うことは困難かつ責任範囲の境界決めが複雑化して、SRE 側だけで完結しない場面が多いので手が出せなくなっています。
MySQL DB たち自体の運用は私達のチームで行っていますが、データそのものの owner/maintener が microservice 化に伴い切り出すことが困難になっているテーブルが多数存在していて、メルカリの MySQL は「レガシーなデータベース」となりつつあります。
レガシー MySQL server の移管
そんな「レガシーなデータベース」をこのまま運用するのではなく、今よりもスケール可能かつ高可用性なものとするために、 ScalableDB への移管プロジェクトが現在進行しています。
ScalableDB への移管のために私達は、 NewSQL(Cloud Spanner、 Vitess、 TiDB) など以下の項目に対して必須なもの、あるといいものなど点数を付けて比較しました。
項目の一例をあげると下記のようになります。
| 項目 | 内容 |
|---|---|
| 構成 | writer、 reader の scalability、 failover 機能の有無など DBMS としての安定性 |
| Query | MySQL 互換を前提とし、 AutoIncrement、 SELECT FOR UPDATE への対応などアプリケーションレベルの互換性 |
| 運用 | warm-up の要否、 AZ 障害への耐性、監視がどこまで整備されているかなどの運用の容易性 |
| Security | password rotation、 Software upgrade など脆弱性への対応の容易性 |
| Migration | MySQL binlog が読めるかなどの MySQL と replication 可能かなど移管性能 |
| 他システム連携 | CDC など現在連携しているシステムとの親和性 |
比較結果を簡単にまとめると下記のとおりとなります。
| 項目 | Cloud Spanner | Vitess | TiDB |
|---|---|---|---|
| 構成 | ◯ | ◯ | ◯ |
| Query | ✕ (*1) | △(*2) | ◯ |
| 運用 | ◯ | △(*3) | △(*3) |
| Security | ◯ | ✕(*4) | ✕(*4) |
| Migration | ✕(*5) | ◯ | ◯ |
| 他システム連携 | ◯(*6) | ◯(*6) | ◯(*6) |
(1) AutoIncrement 非対応、単調増加な主キー非推奨
(2) Vitess の互換性のないクエリ https://github.com/vitessio/vitess/blob/main/go/vt/vtgate/planbuilder/testdata/unsupported_cases.txt
(3) warm-up が必要
(4) password rotate、IAM 認証、監査ログ非対応(TiDB は enterprise で監査ログ対応可)
(5) 現時点で MySQL の binlog をそのまま読むことはできない、また InterLeave などテーブル構成の変更が必要
(6) Cloud Spanner は BigQuery、Vitess/TiDB は Kafka へと streaming 可能
まとめてみたところ、Migration と Query の対応範囲の広く現在のメルカリの運用体制も合わせると TiDB が最も有力な候補となりました。Migration と Query の対応範囲でいうと、メルカリでは microservice、 monolithic PHP、CDC などデータの利用者が多岐にわたるためその中でも特に現在の MySQL 5.7 と互換性があるインターフェースを持つこと、MySQL => Scalable DB だけでなく Scalable DB => MySQL と相互に replciation し安定的に移行と切り戻しが可能となることが挙げられます。
またメルカリの運用体制について特に Vitess と TiDB の比較すると、TiDB はクラスタ構成のため Failover をサポートしていることや利用可能な Query が多いことに加え、水平分割をしていない DB をこれまでと同様に垂直単位でクラスタを構成できる点といったことが挙げられます。
TiDB についてはサービス導入に向けて現在検証作業を進めている最中で、この検証結果についてはまた後日紹介させていただければと思います。
さいごに
今回は私達がどのように「レガシーなシステム」と日々向き合っているかについて紹介しました。このように事業拡大のスピードが急速なサービスだとブラックボックス化したシステムや 肥大化したデータを運用していかなければならない場面が多々あると思います。
私達のチームでは、そのような場面では「レガシーなシステム」構築時には存在しなかったであろうオープンな技術や Cloud Service で代替できるかを念頭におきつつも、現在のユーザーへの互換性を維持しつつ責任範囲を明確化して進められるように取り組むことで、ユーザーも私達も幸せになれる信頼性の高いシステム構築を推進しています。
このような様々な課題に対して技術的に解決したい方、ぜひ私達のチームで一緒に解決していきましょう!





{kind=link}