
Credit Designチームでバックエンドエンジニアをしている@iwataです。主にメルペイスマート払い関連の開発をしています。
Merpay Advent Calendar 2021 の21日目の記事をお届けします。
メルペイスマート払いの開発においてもご多分に漏れず、マイクロサービスアーキテクチャを採用しています。マイクロサービス開発において避けては通れない問題として、分散トランザクションによるデータ整合性の担保があります。メルペイスマート払いマイクロサービスでは一部APIにおいて整合性担保のために、Transactional outboxパターンを用いた実装をしています。
本記事ではテーブル設計を含めたその実装の詳細を紹介したいと思います。
tl;dr
- Transactional outboxパターンを使ったSpanner, Pub/Sub間での整合性担保
- Spannerならではの運用を考慮したテーブル設計
- Spannerで
LOCK_SCANNED_RANGES=exclusiveを有効活用できた事例の紹介
Transactional outboxパターンとは?
Transactional outboxパターンとは、分散システムにおけるアーキテクチャパターンのひとつです。
サービス開発において、データベースを更新するトランザクションの一部としてメッセージをパブリッシュしなければならないことはよくあります。例えばMySQLなどのデータベースを操作しつつ、非同期にメール送信するためにメッセージキューを間に挟む場合などです。
これら2つの操作はアトミックに行われなければなりません。すなわちどちらか片方だけが成功もしくは失敗といったデータ不整合の発生を回避する必要があります。
この問題の解決策のひとつがTransactional outbox パターンです。
このパターンの概要についてmicroservices.ioに掲載されてあるコンポーネント図を元にもう少し説明します。
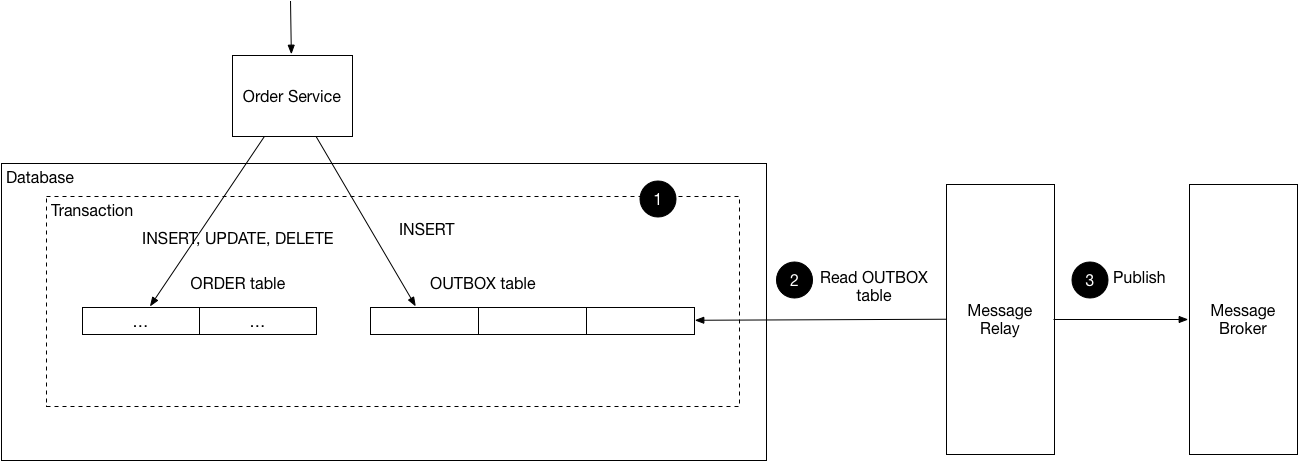
(出典元: microservices.io)
登場するコンポーネントは以下の4つです。
- Order Service
- Database
- Message Relay
- Message Broker
ここではOrder Serviceという架空のサービスを対象にしています。Database上にはORDERテーブルとOUTBOXテーブルがあり、ORDERテーブルが操作対象のテーブルです。OUTBOXテーブルはこのパターン用に追加するテーブルで、これを一時的なメッセージキューとして用います。ORDERテーブル操作時に送信したいメッセージデータを一時的にOUTBOXテーブルに追加します。ORDERテーブルの操作とOUTBOXテーブルへの追加は同一Database内のローカルトランザクションとしてアトミックに実施できます。追加されたOUTBOXのレコードをMessage Relayが読み、Message Brokerにバプリッシュします。Message BorkerへのパブリッシュをMessage Relayが保証することでDatabaseとMessage Brokerとの間で結果整合性を担保することができます。
メルペイスマート払いサービスにおける実装
メルペイでは主にGCPを使ってマイクロサービスを開発していることもあり、メルペイスマート払いのサービスではDatabaseとしてCloud Spanner、Message BrokerとしてCloud Pub/Subを使っています。またマイクロサービス自体はGo言語で開発しているため、Message RelayもGo言語を使って実装しました。
上記Order Serviceのコンポーネント図との対応を表にまとめると以下のようになります。
| Order Service | メルペイスマート払い |
|---|---|
| Database | Cloud Spanner |
| ORDERテーブル | 各種テーブル |
| OUTBOXテーブル | AsynchronousTasks |
| Message Relay | publishworker(Go実装) |
| Message Broker | Cloud Pub/Sub |
AsynchronousTasksはこのサービス内でのテーブル名で、publishworkerは今回実装したGoのアプリケーションです。Message Relayの実現方法にはPolling publisherとTransaction log tailingとの2種類ありますが、今回はPolling publisherで実装しました。(GCPのドキュメントでもpollingが推奨されていたりする)
以下はコンポーネント間のやりとりのシーケンス図です。

以降では、シーケンス図内での重要な点を説明します。
Register task
ビジネスロジック内のTrasaction処理でAsynchronousTasksにレコードを追加します。
(以下AsynchronousTasksのレコードのことをtaskと表現する)
AsynchronousTasksのDDLは次のようになります。
CREATE TABLE AsynchronousTasks (
Id STRING(64) NOT NULL,
Topic STRING(255) NOT NULL,
Data BYTES(MAX) NOT NULL,
Priority INT64 NOT NULL,
Shard INT64 NOT NULL AS (MOD(ABS(FARM_FINGERPRINT(Id)), 10)) STORED,
CreatedAt TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
SentAt TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
) PRIMARY KEY(Id);
CREATE INDEX AsynchronousTasksByShardSentAtPriorityCreatedAt
ON AsynchronousTasks(Shard, SentAt, Priority DESC, CreatedAt);各カラムの説明を表にまとめました。
| カラム | 説明 |
|---|---|
| Topic | パプリッシュするCloud Pub/SubのTopic。1つのテーブルで複数のTopicを扱えるようにしている |
| Data | パブリッシュするメッセージ(PubsubMessage)をシリアライズしたもの |
| Priority | パブリッシュする優先度。高い値だと優先的にパブリッシュされる |
| Shard | セカンダリインデックスのホットスポットを回避するためのShard key |
| CreatedAt | task作成時のタイムスタンプ |
| SentAt | パブリッシュ時のタイムスタンプ。パブリッシュした後はレコードを消さずにこのカラムを更新する |
AsynchronousTasksへのレコードのインサートは、バッチによる大量インサート処理で行われる場合と、ユーザからのリクエストで行われる場合があります。Priorityは、バッチが実行中であっても、ユーザからのリクエストに伴うパブリッシュの遅延を最小限にするために使います。(バッチではPriority=lowでインサートし、ユーザリクエストのものはPriority=highでインサート)
AsynchronousTasksByShardSentAtPriorityCreatedAtはpolling用のセカンダリインデックスです。
Register関数は以下のようなコードになります。
func (r *Registrar) Register(
ctx context.Context,
tx *spanner.ReadWriteTransaction,
topic string,
msg *pubsubpb.PubsubMessage,
priority int64,
) error {
id := uuid.New().String()
pubsubpublisher.AddAsynchronousTaskIDAttribute(msg, id)
data, err := proto.Marshal(msg)
if err != nil {
return err
}
t := &database.AsynchronousTask{
ID: id,
Topic: topic,
Data: data,
Priority: priority,
CreatedAt: spanner.CommitTimestamp,
}
return tx.BufferWrite([]*spanner.Mutation{t.Insert(ctx)})
}特に珍しいことはしていないですが、idは関数内で生成しメッセージのAttributeとして追加(pubsubpublisher.AddAsynchronousTaskIDAttribute()の処理)しています。これはidをサブスクライバ側でログ出力しておくことでリトライ可能にするためです。
Publish process
別プロセスで起動しているpublishworker側の処理について。
2.1.1 Find AsynchronousTasks
AsynchronousTasksを定期的にpollingしてパブリッシュされてないtaskを取得します。
以下のようなSELECT文を使います。
SELECT *
FROM
UNNEST(GENERATE_ARRAY(0, 9)) AS OneShard
CROSS JOIN UNNEST(ARRAY(
SELECT AS STRUCT *
FROM AsynchronousTasks@{FORCE_INDEX=AsynchronousTasksByShardSentAtPriorityCreatedAt}
WHERE Shard = OneShard AND SentAt IS NULL
ORDER BY Priority DESC, CreatedAt ASC
LIMIT @limit
)) AS t
ORDER BY t.Priority DESC, t.CreatedAt ASC
LIMIT @limit`Shardを考慮したSELECTについては以下の@sinmetalさんのノウハウを参考にしてください。
https://github.com/gcpug/nouhau/blob/spanner/shard/spanner/note/shard/README.md#v3
SentAtでフィルタしつつ、PriorityとCreatedAtでソートしています。これで未送信のtaskを高優先度かつ古い順に処理できます。
2.1.3 Shuffle & sample tasks
前述のSELECT文で取得したtaskをシャッフルしつつサンプリングします。これはpublishworkerのスループットを上げるためです。publishworkerは複数のプロセスで起動しますが、単純にPriorityとCreatedAtの順で処理しようとするとプロセス間で衝突(同じtaskを処理するの意)が起こり、スループットの低下が予想されます。これを避けるために例えば100件のソート済みのtaskを取得しつつ、シャッフルした上で先頭10件のみを後続の処理で使う、というようなことをしています。
2.2.x以降の処理は各task単位での並列処理になります。
2.2.2 Select a task with exclusive lock hint
SpannerのReadWriteTransactionを張った上で、PrimaryKey(Id)で排他ロックを取得します。Statement hintsのLOCK_SCANNED_RANGES=exclusiveを使うことで排他ロックの取得を試みることができます。(あくまでヒントなので必ずしも排他ロックをかけられるわけではない)
@{LOCK_SCANNED_RANGES=exclusive}
SELECT Id, Topic, Data, Priority, SentAt
FROM AsynchronousTasks
WHERE Id = @Id排他ロックを取得しつつ、SentAtがNOT NULLであれば別プロセスで既に処理されたものとしてRollbackしつつ処理を終了します。これによりさらなる衝突回避を行っています。
2.2.5 Publish, 2.2.6 Get
GoのPub/Subクライアントによるパブリッシュは即座にメッセージが送信されるわけではない点に注意が必要です。
Publish queues the message for publishing and returns immediately. When enough messages have accumulated, or enough time has elapsed, the batch of messages is sent to the Pub/Sub service.
Publish returns a PublishResult, which behaves like a future: its Get method blocks until the message has been sent to the service.
https://pkg.go.dev/cloud.google.com/go/pubsub#hdr-Publishing
publishworkerでは確実にパブリッシュが成功したのちにSpannerのトランザクションをCommitする必要があるため、上記GoDocにあるように続けてGetをしてパブリッシュされたかどうかを確認しています。
2.2.8 Set SentAt
SentAtをコミットタイムスタンプで更新します。レコードを削除することも検討しましたがリトライを容易にするために削除ではなく更新にしました。運用をしているとサブスクライバ側の不具合で意図せずACKを返してしまい、リトライをしたくなるケースがあります。この場合レコードを削除してしまっていると同じメッセージでリトライすることが難しくなります。しかしSentAtを更新する方式であれば、Idさえ分かればそのtaskを再度SentAt=NULLに更新することでpublishworkerが勝手にリトライしてくれます。このためIdはPub/SubメッセージのAttributeいれておいて、サブスクライバ側で必ずログ出力するようにしています。
不要なレコードが残り続けるとpolling時のパフォーマンスが気になります。しかしながら現在このテーブルのレコードは約2500万まで増えていますが、特にパフォーマンス上の問題は発生していません。(さすがSpanner!!) 今後さらにレコード数が増えて問題になったとしても、SpannerにはTTLを設定することが可能なので簡単に対応できると考えています。
またリトライ操作はこれまで何度か発生しましたが上記のようにDMLだけでリトライできるようになっているのと、DMLの実行もSpinnakerパイプラインで簡単に実行できるようになっているため、運用し易くなっています。(SpinnakerによるDML実行については拙作Cloud SpannerにPriority指定してDMLを実行してみたにも記載)
2.3.x Commit or Rollback
Pub/Subへのパブリッシュに成功するとSpannerのトランザクションもCommitします。このCommitがAbortedなどで失敗するとトランザクションはRollbackされ、対象のtaskはpollingによるリトライループに入ります。この場合既にPub/Subへのパブリッシュは成功しているため、同じメッセージが複数回パブリッシュされることになります。従ってサブスクライバ側では同じメッセージが来ても同じ結果となるように必ず冪等に実装しておく必要があります。
リリース後の改善
Transactional outboxパターンを実装してから既に1年以上が経ちますが、運用しながら改善したところがあるのでいくつか紹介したいと思います。
メトリクスの送信
publishworkerがPub/Sub前段のミドルウェアのような扱いになるため、メトリクスがないと中で何が起きているのか把握できず運用に支障がでることは容易に想像できました。そこでリリース後の早い段階からメトリクスの設計にとりかかりました。現在では以下に挙げるようなメトリクスをカスタムメトリクスとしてDatadogに送信しています。
| metric name | 説明 |
|---|---|
| registered_task_count | Registerしようとした数 |
| total_published_task_count | Pub/Subにパブリッシュした数 |
| already_published_tasks_count | パブリッシュしようとしたが既に別プロセスでパブリッシュされていた数 |
| published_but_failed_commits_count | パブリッシュは成功したがCommitに失敗した数 |
| oldest_task_age | pollingで取得したtaskのうち最も古いtaskのCreatedAtと現在時刻との差分 |
registered_task_countとtotal_published_task_countとの差分をとることでおおよそのtaskの滞留を把握already_published_tasks_countから処理の衝突率を把握oldest_task_ageによってpublishworkerの処理遅延を把握
などなど他にも取得しているメトリクスはありますがここでは割愛します。
pollingをPriority=Mediumで実行
ここでいうPriorityはAsynchronousTasks.Priorityではなく、SpannerのPriorityです。Spanner Priorityについては拙作「Cloud SpannerにPriority指定してDMLを実行してみた」で詳しく説明しているので詳細は割愛しますが、publishworkerのリリース時から前述したpolling時のSELECTにはSpannerへの負荷の懸念がありました。
リリース当初、pollingのインターバルを1秒にしていたところSpannerへのCPU負荷が増加してしまったため、インターバルの間隔を何度か調整しました。これはSpannerのProcessing Unit数にも依存しますが、現在のノード数であれば5秒程度のインターバルであれば大丈夫であることが分かりました。また前述のメトリクスから5秒間隔であったとしてもスループット上許容できる範囲であったため、最終的には5秒間隔としました。
その後SpannerクライアントでPriorityを指定できるようになったため、Priority=HighからMediumに優先度を下げてSELECTするようにしています。これでもし今よりスループットを上げたいとなれば、インターバルを短くすることも可能だと思われます。
排他ロックをかけるようにした
2.2.2 Select a task with exclusive lock hintで述べたようにトランザクション内で改めてロックをとった上でパブリッシュするようにしています。実はこの処理は初めから入っていたわけではなく、後から追加したものです。当初はロックはとらずにサンプリングしたtaskは全てパブリッシュするようにしていました。これは処理の衝突よりもスループットを優先させたためです。
基本的にサブスクライバ側の処理は冪等に作ってあるので、さほど衝突率は気にせずスループットを上げる実装にしていました。しかしながら冪等に作ってあるとはいえ、あまりにも衝突率が高いとサブスクライバ側の処理が遅延したり、予期せぬエラーが発生したりすることが分かってきました。具体的には同じメッセージが多数パブリッシュされることでサブスクライバ側でSpannerのAbortedが多発する、などです。
また当初は同期的に処理したAPIをパフォーマンスの問題から非同期処理に置き換える場合があります。そういった場合だと厳密に冪等性が担保されていないことがありえます。メルペイスマート払いに「あとから定額」という機能がありますが、この処理を提供するAPIは実際に非同期処理への切り替えを行いました。その結果、衝突が多数発生するとサブスクライバ側でエラーが起きる状態になっていました。これらの不具合に対処するために排他ロックの処理を追加しました。
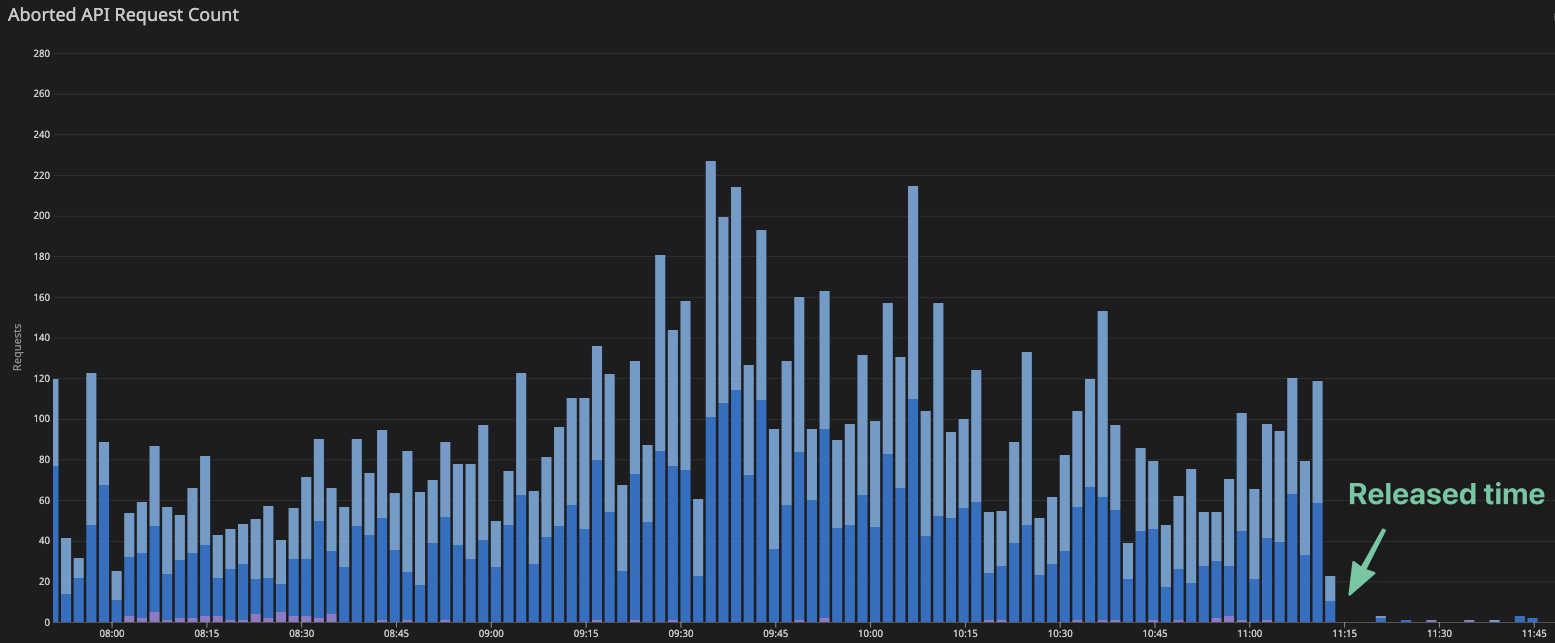
上のグラフはロック処理を追加したリリース前後のAbortedの数です。驚くほどにAbortedが減っていることがわかります(100分の1以下!!)。
Abortedが減るのはよいですが、ロック待ちのせいでpublishworkerのスループットが落ちることはないのでしょうか?メルペイスマート払いでは月初に実行するバッチで大量にAsynchronousTasksへのインサートが行われます。そこで改修前後での月初のスループットを比較することでロック待ちによる影響を確認してみました。
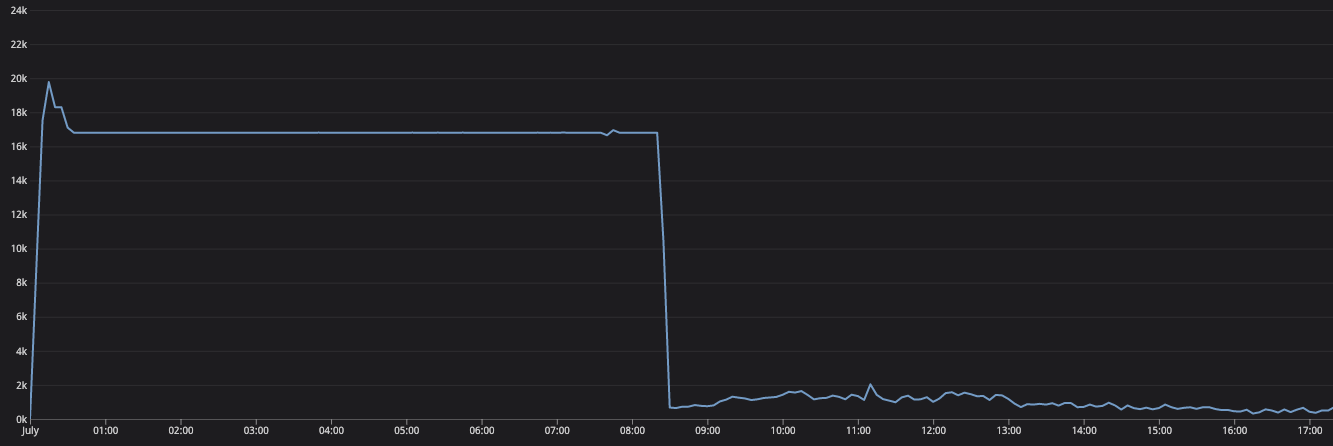
以下はリリース前後でのtotal_published_task_countのグラフです。
リリース前。
こちらはリリース後。
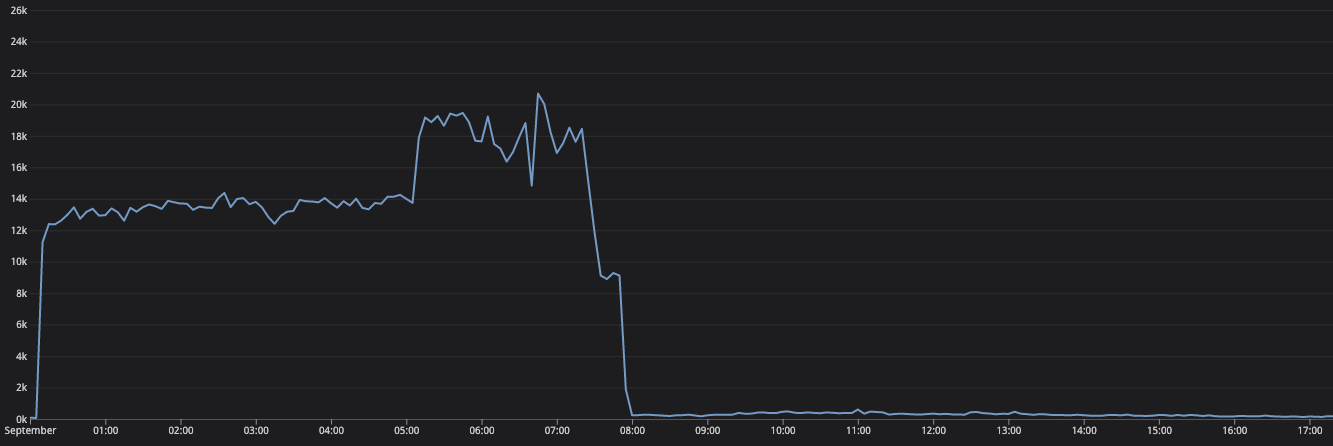
両方とも8時前後には大抵の処理は終わっていることがわかります。むしろリリース後の方がスループットが上がっているようにみえます。この結果から考察すると、
- ロック待ちは入るがその遅延よりもPub/Subへのパブリッシュにかかる時間の方が支配的だった
- パブリッシュには秒単位で時間かかることがザラにある
- 無駄な(重複した)パブリッシュが減ったことで全体としてのスループットが改善した
のようになるかなと思います。結果排他ロックをとることによるデメリットはない、という結論に至りました!!
さらなる改善
最後に今後の改善点を挙げておきます。
コンテナの分離
実は今回実装したpublishworkerはメインのgRPCサーバ上に同居(別goroutineとして起動)しています。これは複数コンテナを管理したくなかったためです。しかしながらこれだとパフォーマンス上の懸念があります。gRPCサーバのDeploymentはHorizontal Pod Autoscaling(HPA)でスケールするようになっています。従ってリクエスト増によりPODが増えると同時にpublishworkerのプロセスも増え、pollingによるSpannerへの負荷も増えてしまいます。これを回避するためにgRPCサーバとpublishworkerとでバイナリを分離し、別コンテナとして起動したいと考えています。
External Metrics Providerを使ったオートスケール
Kubernetes v1.6のHPA(autoscaling/v2beta1)からカスタムメトリクスを使ってオートスケールすることが可能になりました。前述のようにコンテナを分離した上で、Datadogに送っているカスタムメトリクスを元にオートスケールすることを考えています。これができるとtaskが滞留してきたらPODを増やす、といったスケールができると思われます。
まとめ
SpannerとPub/Subとでトランザクションをアトミックに処理するためにTransactional outboxパターンを実装した話をしました。このパターンはSagaパターンやTCCパターンに比べるとシンプルなことで知られていますが、それでも運用していく上では考慮すべき点が多いです。
この記事が皆さんの分散トランザクションとの戦いにとってよい一助とならんことを願っております。




