この記事は、 Merpay Advent Calendar 2021 6日目の記事です。
はじめに
こんにちは。メルペイ Architect の @goccy です。
この記事では、日々実行しているマイクロサービス間の結合テストを高速化するために開発したツールについて紹介します。
マイクロサービス間の結合テスト
結合テストの仕組みについては、過去に @zoncoen さんが発表したこちらに詳しく書かれています。簡単にまとめると次のようになります。
- あるサービスにリクエストを送った結果を利用して別のサービスにリクエストするという一連の流れを「シナリオ」としてYAMLファイルに定義する
- 各サービスへのリクエストに対して期待するレスポンスを記述でき、バリデーションをしながらシナリオを進めていく
- シナリオが記述されたYAMLファイルは
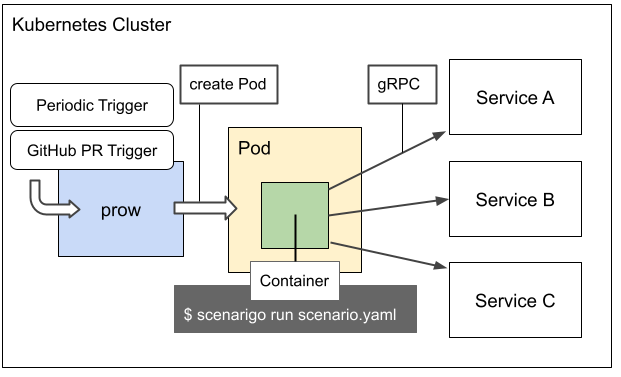
scenarigoというツールを使って処理できる scenarigoを用いた結合テストは CI で定期的に実行されている- CI には Kubernetes の開発でも利用されている prow を利用している
prow で定期的にテスト用のジョブが起動すると、次の図のようにマイクロサービスが動いている Kubernetes クラスタと同じクラスタ内にテスト実行用の Pod が起動し、その Pod 上で scenarigo がテストシナリオが書かれたYAMLファイルを読み込んで結合テストを行います。
また、新しいシナリオを書く場合はそのシナリオ自体の妥当性をテストしたいはずなので、GitHubのPull Requestでシナリオに修正があった場合にも prow でテスト用のジョブが起動します。
テスト実行時間の課題
しばらく結合テストを運用していく中で、テストにかかる時間が増大していく問題が生じました。シナリオを適切な粒度で並行処理することは scenarigo 自身が行ってくれるため、複数のシナリオを直列に実行していることが原因ということはありませんでした。また、シナリオの実行時間のほとんどはリクエスト先の各マイクロサービス側での処理時間になるため、時間のかかる原因の大半がリクエスト先のサービス側にあります。
例えば歴史的経緯でスケールのしにくいサービスがあり、そのサービスの処理結果を待たなければシナリオを先に進められないような場合に問題が顕著に現れます。メルペイのシナリオテストではテスト用ユーザーを作成するリクエストを最初に実行し、作成されたユーザー情報を用いて以降のリクエストを行うのですが、まさにこのユーザー作成処理が遅いことから実行時間が伸びていました。
そこで、この問題を解決するためにテストに必要なユーザーを予め作成して貯めておくプールを作り、ユーザー作成リクエストが来た場合にはその場で作成処理を実行するのではなく、プールから作成済みユーザーを取り出して返すようにするといった対応をとりました。
これにより、シナリオを実行する上で依存するサービス側の処理時間がボトルネックになるようなケースは解消されましたが、それでもシナリオの数が数百にもなるとシナリオを実行する側のCPUリソースを使い切ってしまい、スケールしなくなりました。いったんこうなると、単純にテスト数が多くなればなるほど実行時間が伸びていってしまいます。
分散テストというアプローチ
もちろん、prow がテスト実行用に立ち上げた Pod に与えるリソースを増やしてCPU負荷を下げる方法もありますが、スケールアップではシナリオが増えたときにまた限界が来てしまうかもしれません。そこで、理論上テストがどんなに増えたとしても対応できるように、テスト実行に必要なリソースをスケールアウトできる分散テストのアプローチでこの問題を解決することにしました。
次からは、分散テストのために開発した kubetest というツールについて紹介します。
kubetest
kubetest は、Kubernetes を前提とした分散タスク処理を実現するために開発した CLI ツールで、Kubernetes クラスタのリソースを効率的に利用しながら重いタスク処理を分割して処理することができます。「分散テスト」というキーワードを出発点として開発したため、名前に test とついていますが、説明にも書いたとおりテスト以外の用途 ( 例えば分散ビルドなど )でも利用することができます。prow のコードが置かれているリポジトリに同名のコンポーネントが存在することを後から知って名付けに失敗した感が強いですが、とりあえず気にしないことにしています。
kubetest CLIは分散実行の定義が書かれたYAMLファイルを引数にとって実行します。
YAMLファイルは以下のように Kubernetes の Custom Resource として TestJob というリソースを定義する形式をとっています。これは後ほど TestJob リソースを処理する Controller をサポートして、TestJob を本当の Custom Resource として扱えるようにすることが狙いですが、現状では kubetest CLI 経由の実行のみをサポートしています。
apiVersion: kubetest.io/v1
kind: TestJob
metadata:
name: simple-testjob
namespace: default
spec:
mainStep:
template:
metadata:
generateName: simple-testjob-
spec:
containers:
- name: test
image: alpine
workingDir: /work
command:
- echo
args:
- "hello"上記のYAMLの内容は、Kubernetes Job を利用したことがある方は理解しやすいかもれません。
spec.mainStep.template がちょうど Kubernetes Job でいう spec.template に対応しており、 template 配下には PodTemplate と同じ内容を記述できます。上記の例では、 alpine イメージをもとにしたコンテナがひとつ起動し、その中で echo "hello" を実行して終了します。
実際 kubetest はタスク処理のために Kubernetes Job を内部で利用しており、prow を含めた動作イメージは以下のようになります。
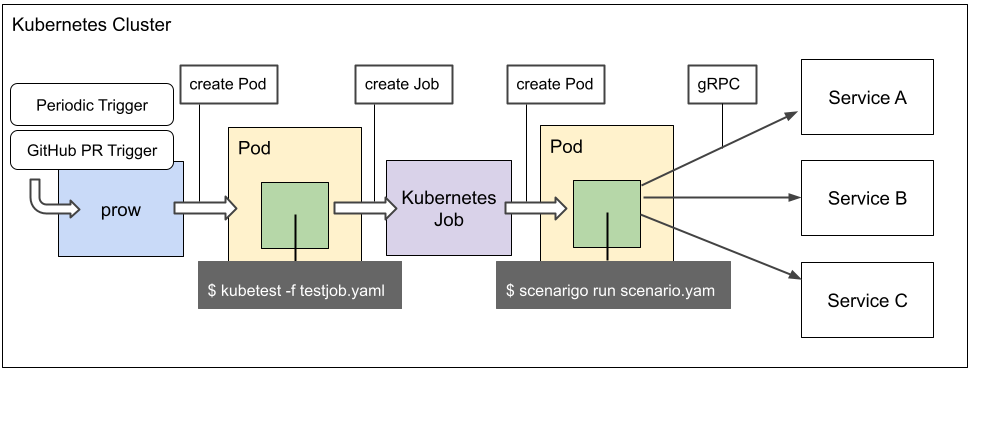
kubetest 内部で Kubernetes Job を作ってログを取得しつつ、終了するまで待つといったことが簡単にできるように kubejob というライブラリを作って Kubernetes Job の制御を行っています。
さて、上記の例ではコマンドをひとつ実行するだけなので、Kubernetes Job を使う場合とできることに違いはありません。次から本題の分散テストをどのように実行するか解説します。
kubetest による分散テスト
分散タスク処理を行うためには、まず重いタスクをどのようなルールで分割するかを決める必要があります。今回のケースで言うならば、「全てのシナリオを処理する」というタスクを重いタスクとして定義し、これをどういったルールで分割するかということを定義する必要があります。
kubetest ではこれを以下のように spec.mainStep.strategy で定義します。
apiVersion: kubetest.io/v1
kind: TestJob
metadata:
name: strategy-static-testjob
namespace: default
spec:
mainStep:
strategy:
key:
env: TASK_KEY
source:
static:
- TASK_KEY_1
- TASK_KEY_2
- TASK_KEY_3
scheduler:
maxContainersPerPod: 2
maxConcurrentNumPerPod: 2
template:
metadata:
generateName: strategy-static-testjob-
spec:
containers:
- name: test
image: alpine
workingDir: /work
command:
- echo
args:
- $TASK_KEY上記のように、 spec.mainStep.strategy.key.source で分割するタスク毎の名前を定義します。( kubetest では説明上これを分散キーと呼んでいます )
すべてのタスク名が事前に分かっている場合は、 static というフィールドの配下に列挙します。上記では TASK_KEY_1 ~ TASK_KEY_3 までの3つのタスク名を定義しているので、重いタスクを TASK_KEY_1 といった名前の3つのタスクに分割して処理するということを表現しています。分割された3つのタスクは strategy.scheduler の設定によってそれぞれ別の Container 上で実行されます。
各 Container には strategy.key.env で指定した環境変数の値としてタスク名(分散キー)が渡るので、この値によってそれぞれのタスクが異なる処理を行うことができます。
この機能をテストに利用する場合、分散キーはテストケースの名前になります。こうすることで、各 Container でテストを実行する際に、指定した環境変数にテストケースの名前が入っているので、その値を使って対象のテストだけを実行することができます。
例えば Go でテストをする例は以下のようになります。
apiVersion: kubetest.io/v1
kind: TestJob
metadata:
name: go-testjob
namespace: default
spec:
mainStep:
strategy:
key:
env: TEST
source:
static:
- TEST_1
- TEST_2
- TEST_3
scheduler:
maxContainersPerPod: 2
maxConcurrentNumPerPod: 2
template:
metadata:
generateName: go-testjob-
spec:
containers:
- name: test
image: test-image
workingDir: /work
command:
- go
args:
- test
- .
- -run $TESTテストケースとして TEST_1 ~ TEST_3 があるときに、それぞれの名前を TEST 環境変数を参照して取得し、 go test . -run $TEST によって対象のテストだけを実行しています。もちろん、テストを追加するたびにその名前を static の下に書いていくのは大変なので、動的に分散キーのリストを作ることもできます。
その場合は、デフォルトではコマンドを実行した結果の標準出力を改行で分割したものになるので、Goの場合は go test -list . を実行した結果のうちテスト名と関係ない行をフィルタしつつ利用すれば良いでしょう。
シナリオテストの場合も同様で、全てのシナリオを取得するコマンドを使ってシナリオ一覧を取得し、それぞれのシナリオ名が異なる Container 上の環境変数に渡ります。そしてその名前をつかって、 scenarigo を利用してシナリオテストを実行します。
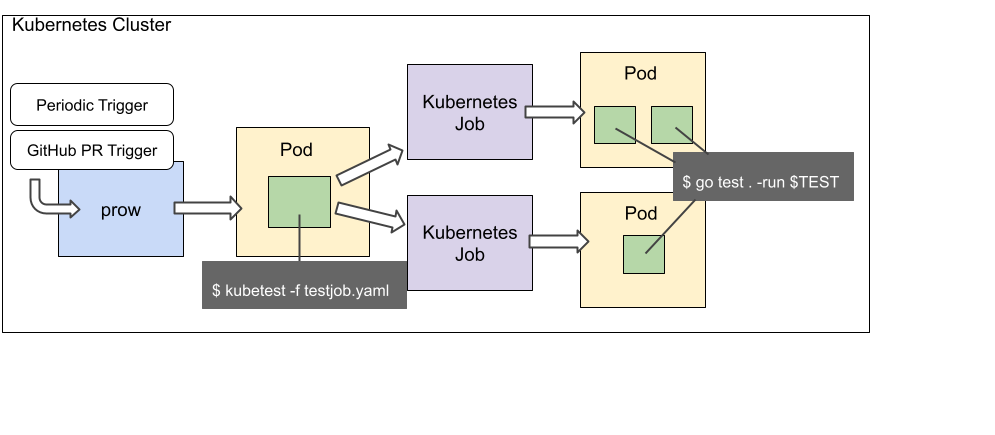
ここまでで、分散タスクひとつを実行するために Container をひとつ利用することに気づいたと思います。
テストの場合では、ひとつのテストケースを実行するために Container をひとつ立ち上げます。
これは富豪的なリソースの使い方にも見えますが、他のタスク処理の結果に依存せずに処理できる単位としてContainer 単位で処理することによって、タスク処理を抽象化しやすくできていると考えています。
分散タスクとContainerの関係がわかったところで、どのように Kuberenetes のリソースを利用するかが気になると思います。例えばすべての Container が同じ Pod の上で動作してしまうと、せっかくタスクを分割したのに、同じ Pod 上のリソースを食い合ってしまってスケールしません。
そこで kubetest では spec.mainStep.strategy.scheduler に分散ルールを書くことで、それぞれのタスクが異なる Pod で動くように制御できます。
maxContainersPerPod では 1 Pod あたりで動作するコンテナの最大数を指定でき、 maxConcurrentNumPerPod では 1 Pod あたりで平行にタスク処理を行う数を指定できます。これらを利用すると、例えば上記の例ではテストケースが3つあり、1Podあたり2つのコンテナまで動くように書かれているので、テストを実行するために起動するPodの数は2つになります。また、同時に動く処理の数が 2 に設定されているので、各 Pod 上で 2つずつ同時にタスク処理が行われます。
こうした並行処理数の制御は、今回のシナリオテストのように、テストが依存するサービスのうちスケールしにくいサービスが存在するような場合に効果があります。
上記のGoのテストを実行する際の流れを図にすると、以下のようになります。
テスト実行を助ける仕組み
実はここまで解説してきた内容だけでは、いざテストを実行したいときに困ることがたくさんあります。例えば、多くの場合は社内のプライベートリポジトリに置かれているテストコードを利用してテストしたいはずです。このとき、テストの度にリポジトリの内容を image に含めるのは大変ですし、PullRequest の内容をテストしたいときにコミットの度に image を焼き直すのは非効率です。そこで、テストで使用するリポジトリをテスト実行の直前に clone してくる処理が必要になります。ただしプライベートリポジトリの clone には適切なアクセストークンが必要になるので、そのトークンをどのように準備するかを考える必要があります。また、リポジトリの clone に利用したトークンがテストを実行する際に必要ないのであれば、セキュリティの観点からテスト実行時の環境でトークンを参照できないようになっていることが望ましいです。
kubetest はこれらを実現するために、リポジトリやトークンをそれが必要な環境(Container)にだけマウントできる仕組みを用意しています。
リポジトリとトークンのマウント
spec.repos 配下にタスク処理をする過程で参照したいリポジトリの情報を書くことができます。 clone したいリポジトリの url や clone 後に切り替えたい branch 名や commit hash を指定するのですが、プライベートリポジトリの場合は追加でトークンを指定できます。ここで指定するトークンは spec.tokens 配下で定義でき、以下の例では GitHub App の情報を使って一時的な GitHub Access Token を作ります。
apiVersion: kubetest.io/v1
kind: TestJob
metadata:
name: private-repo-testjob
namespace: default
spec:
tokens:
- name: github-app-token
value:
githubApp:
organization: goccy
appId: 123456
keyFile:
name: github-app
key: private-key
repos:
- name: kubetest-repo
value:
url: https://github.com/goccy/kubetest.git
branch: master
token: github-app-token
mainStep:
template:
metadata:
generateName: private-repo-testjob-
spec:
containers:
- name: test
image: alpine
workingDir: /work
command:
- ls
args:
- README.md
volumeMounts:
- name: repo
mountPath: /work
volumes:
- name: repo
repo:
name: kubetest-repoclone したリポジトリを利用する場合は、volumes に対象リポジトリの名前を指定し、その volume に付けた名前を使って volumeMounts でマウント先を指定するだけです。これは emptyDir など Kubernetes 組み込みの volumes / volumeMounts の仕組みと併用することができます。
リポジトリの他には、トークンや次で説明する前のタスク処理の成果物も同様にマウントすることができます。
これによって、タスク処理に必要な最小限のものだけを選択して利用することができます。
成果物の引き継ぎ
分散タスク処理を行う際に、すべてのタスクで行う共通処理があったとします。
例えばテストコードのビルドやテストコードが依存するモジュールのダウンロードなどです。こういった処理をすべてのタスクで行うことは非効率なので、できれば分散タスクを実行する前に一度だけ行いたいものです。
kubetest ではこのために、 spec.mainStep で実行するメインのタスク処理に必要なものを事前に作ることができる spec.preSteps を用意しています。
apiVersion: kubetest.io/v1
kind: TestJob
metadata:
name: prestep-testjob
namespace: default
spec:
preSteps:
- name: create-awesome-stuff
template:
metadata:
generateName: create-awesome-stuff-
spec:
artifacts:
- name: awesome-stuff
container:
name: create-awesome-stuff-container
path: /work/awesome-stuff
containers:
- name: create-awesome-stuff-container
image: alpine
workingDir: /work
command: ["sh", "-c"]
args:
- |
echo "AWESOME!!!" > awesome-stuff
mainStep:
template:
metadata:
generateName: prestep-testjob-
spec:
containers:
- name: test
image: alpine
workingDir: /work
command:
- cat
args:
- awesome-stuff
volumeMounts:
- name: prestep-artifact
mountPath: /work/awesome-stuff
volumes:
- name: prestep-artifact
artifact:
name: awesome-stuff上記のように preSteps には mainStep の前に実行したい処理を複数書くことができ、最初に書いたものから順番に実行されます。このとき、 preSteps[].template.spec.artifacts に処理結果を成果物として保存するための定義を書くことができ、ここで保存された成果物は以降のタスク処理でマウントを利用することで再利用できます。
これによって、例えばトークンを使用して取得したプライベートモジュール自体を成果物として保存し、その成果物だけをメインのタスク実行時に参照することで、トークンをメインタスクの実行環境から排除することもできるようになります。
また、同様に mainStep 実行後に実行できる postSteps も用意されているので、テストを実行した際にできた成果物を保存しておき、postStep で外部にそれを保存するといったことも可能です。
ここまでできると、テストを実行するタスクを書くイメージが大分湧くのではないかと思います。
まとめ
メルペイのマイクロサービス間の結合テストの仕組みに始まり、テストの数が増えるにつれて実行時間が伸びる問題を分散テストというアプローチで解決しようとした話、そのために開発したツールの紹介をしました。
今回紹介した kubetest は日々テスト時間の短縮に貢献してくれていますが、更に良くできるところはあるので、様々な改善を通してより良いテスト実行環境が実現した場合にはまたご紹介したいと思います。
明日は @vvakame さんです。お楽しみに!




