MLエンジニアとML Platformが協力してサービスの運用負荷を劇的に改善した話
こんにちは、メルペイのMLエンジニアのshuukと、ML PlatformチームのMai Nakagawaです。
今回は、複雑化・肥大化していた機械学習(以下:ML)サービスの運用コストを、いかにして削減したかについて、共同で執筆していきたいと思います。
課題感
メルペイは、メルペイスマート払いという後払いサービスを提供しています。
その裏側では与信額を決定するMLモデル(以下:与信モデル)が運用されており、下記のようなリリースオペレーションが毎月行なわれています。
- 最新のコードベースによるモデルのビルドとデプロイ
- デプロイされたモデルによる再学習
- 再学習モデルによる予測結果データのお客様への適用
与信モデル自体はリリース当初から高い精度とビジネスインパクトは出せていたものの、リリースから1年程経った頃から、月次のリリースオペレーションの負担の増加がチーム内で大きな課題になっていました。
具体的には、
- 工数面
- 手作業が多く、リリースの主担当は月の工数の半分をリリースにとられ分析・モデリングタスクに集中できない
- 手作業の多さゆえにオペレーションのミスによる手戻りがしばしば発生する
- 心理面
- 数千万人の与信枠を更新するという責任の重大さの一方で設定項目やレビュー項目が多く、作業者やレビュワーには大きなプレッシャーがかかっていた
- リリース作業中はコードの改修に一定の制限がかかる(後述)ため、開発者もリリース作業の進捗を常に気にする必要があった
という、工数面・心理面での負担がありました。
このようなコストがかさんでいった理由としては、下記のような背景がありました。
- 負債の返済に当てる工数の欠如
- MLエンジニアはビジネスKPIに直結する精度改善や機能の追加が期待されており、DevOpsの最適化やリファクタリングといった技術負債の返済にきちんと工数を割きづらい状況があった
- 専門性の不足
- MLエンジニアは全員がBackendエンジニアのような高度なエンジニアリングスキルを持っているわけではなく、目の前の課題に対して場当たり的な解決策が多かった
しかし2020年にMLの基盤構築と運用を専門とするML Platformチームが誕生し、この状況にメスを入れられる前提が整ったため、MLチームとML Platformチームが協力してDevOpsの改善に取り組むことになりました。
課題の洗い出しと要件定義
煩雑なDevOpsの課題感だけはMLエンジニア全員が認識していたものの、具体的にストレスを感じているポイントは人によってバラツキがあり、チーム内で同じ目線での議論がしづらい状態がありました。
そこでまず、チーム全員にDevOps関係のペインをできるだけ多く列挙してもらいました。
そして寄せられた数十のペインをもとに、チーム内で議論しながらグルーピングと原因分析を行いました。
その結果、課題の根本原因を大きく下記の2つに絞り込みました。
- 一貫したパイプラインの欠如
- 特徴量作成、モデリング、後処理といった各機能が独立に実装されており、エントリーポイントも設定ファイルも形式がバラバラだった
- そのため、前工程の実行が終わるのを人間が見届けたあと、手動で次工程の実行をトリガーする必要があった
- また、各機能間で受け渡すべきメタデータ(テーブル名やモデルID等)を、前工程の実行が終わるたびに次工程の設定ファイルに手動で転記する必要があった
- 設定ファイルが膨大なため、設定変更とレビューの負担が大きく、ミスの増加につながっていた

- DevとOpsが密結合したブランチ戦略
- 開発と動作確認を同じブランチ上で行っていたので、当月リリースするコードの動作確認が終わるまでブランチをフリーズするという運用がとられていた
- リリース担当者は動作確認していないPRがマージされないように目を光らせる必要がある一方、開発者はOpsの状況によっては自由にPRをマージできなかった

この2つの課題に対し、それぞれ下記のような目標を定めました。
- オペレーションのパイプライン化
- 一連のリリースオペレーションを、パイプラインで一気通貫に自動で行えるようにすること
各工程間のメタデータの受け渡しを自動化すること - 分散している設定ファイルを統一すること
- 一連のリリースオペレーションを、パイプラインで一気通貫に自動で行えるようにすること
- ブランチ戦略の変更
- 開発と動作確認のブランチを別にし、コードフリーズ期間やDevとOpsの依存関係を撤廃すること

MLチームとしては主要な要件のみを定め、具体的なHOWに関してはより高いエンジニアリングスキルを持つML Platformチームに委譲しました。
実装
オペレーションのパイプライン化
改善前は、各リリースオペレーションごとに実行環境が異なっていました:
- 特徴量生成は BigQuery クエリを利用
- 具体的には、Apache Airflow(以下 Airflow)から BigQuery クエリをトリガー
- 特徴量を使ったモデルのトレーニングと予測は Docker container 上で Python を実行
- Spinnaker API を経由して Kubernetes Job として実行
- 予測結果に適用する後処理は BigQuery クエリを実行
- 具体的には、Spinnaker API を経由して、GKE 上で Kubernetes Job から BigQuery クエリをトリガー
- 予測結果の本番環境への適用は Dataflow を利用
- 具体的には、Spinnaker API を経由して、GKE 上で Kubernetes Job から Dataflow Job をトリガー
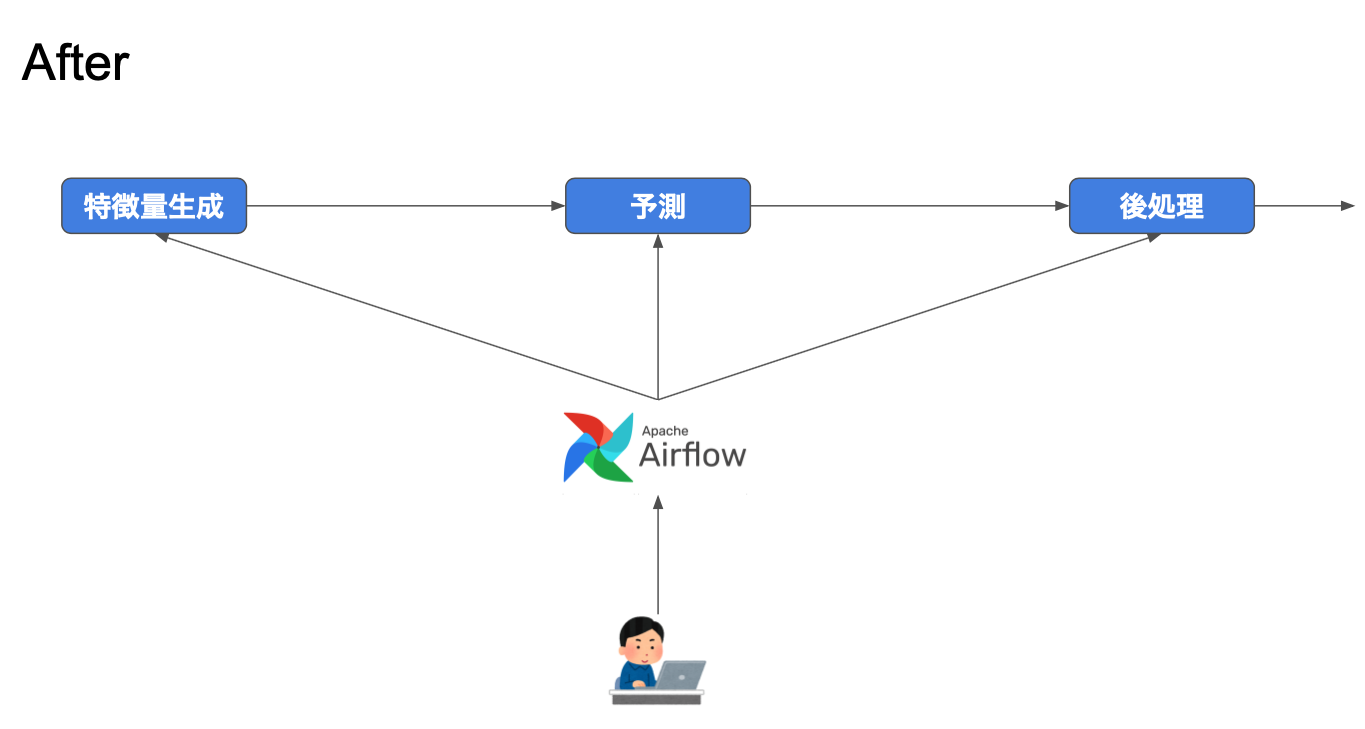
上記のリリースオペレーションを単一のパイプラインとして Airflow で実装しました。他の選択肢として、Spinnaker pipeline、kubeflow pipelines なども検討しました。しかし、既存のリリースオペレーションの中で一番大規模な実装が Airfow を利用した特徴量生成の部分でした。そのため、この部分の実装をそのまま使い回すことができて、かつ実現したい機能がすべて提供されている Airlfow を採用しました。実際には Google Cloud の提供するマネージドのAirflow である Cloud Composer を利用しています。
Airflow には、すでに BigQuery クエリを実行する BigQueryOperator や BigQueryHook、Dataflow job を実行する DataflowOperator や DataflowHook などが提供されています。これらを利用することで、簡単に BigQuery クエリや Dataflow job を実行したり、job を監視したりエラー通知をする仕組みを実装することができました。
また Docker container による Python 実行を行う環境として、今まではメルカリ・メルペイが利用している Kubernetes 環境を利用していました。ここにも課題がありました。機械学習のトレーニングや予測では、一般的なバックエンドサーバーよりも大きな計算リソースを必要とするため、バックエンドサーバーと同じ Kubernetes で Pod をリクエストしても、いつまでも Pod が確保されないことがありました。またトレーニングや予測で大きな計算リソースを消費することにより、他のバックエンドサーバーが高負荷時にスケールアウトできない、といったことが起こり得ることも心配でした。
そこで AI Platform Job の Custom Container を利用することにしました。これにより、AI Platform Job いわば Container as a service の Docker 実行環境として利用できるようになりました。計算リソースとして様々な machine type を選択することができ、またバックエンドサーバーなどの本番環境とは独立して実行できるため、前述したような問題を解消することができました。
こうして、全てAirflowを起点とする以下のようなすっきりしたパイプラインが構築できました:
- 特徴量生成は BigQuery クエリを利用
- Airflow から BigQuery クエリをトリガー(以前と同じ)
- 特徴量を使ったモデルのトレーニングと予測は Docker container を利用
- Airflow から AI Platform job をトリガーする Operator を自作。AI Platform job の提供する Docker container 上で Python を実行
- 予測結果に適用する後処理は BigQuery クエリを実行
- Airflow から BigQuery クエリをトリガー
- 予測結果の本番環境への適用は Dataflow を利用
- Airflow から Dataflow job をトリガー
全てのリリースオペレーションが Airflow を起点にするため、各オペレーションのためのメタデータを Airflow のパイプラインの設定ファイルとして一箇所にまとめることができました。またメタデータを可能な範囲で使い回すことで設定項目を減らすこともできました。
ブランチ戦略の変更
私達のチームでは、Githubフローをベースにしたブランチ戦略を採用しています。ベースブランチは develop ブランチとしていて、各機能開発にはここから feature ブランチを作って、開発が終わると develop ブランチにマージする Pull Request を作成します。この Pull Request をチームメンバーにレビューしてもらい、承認を得た上で Pull Request をマージする運用フローになっています。
改善前は、開発環境と本番環境の2環境があり、それぞれ develop ブランチと main ブランチが対応していました。新たにステージング環境を導入し、新たに staging ブランチを対応させました。そして、本番環境へのリリース前の動作確認を開発環境ではなくてステージング環境で行うようにしました。
これによりステージング環境で動作確認を行っている期間にも、develop ブランチに開発物をマージできるようになりました。

取り組みの成果
このような改善を行った結果、下記のような成果を得ることができました。
MLパイプライン構築の成果
- オペレーション工数の削減
- 処理間のメタデータの受け渡しが自動化されたことで、当時数十あった設定項目が数個に減り、修正とレビューの時間が大きく削減された
- オペレーションミスと心理的負担の減少
- 設定項目が減ったこと、設定ファイルが1箇所に集約されたことで、設定の記載ミスが激減した
- これによって、作業者の心理的な負担も大きく軽減した
- 開発工数の削減
- 独自のコンポーネントで実装されていた機能の一部をAirflowのオペレーターに置き換えたため、メンテするべきコードが減少した
ブランチ戦略の変更
- 1月あたりのPR量の増加
- コードフリーズ期間が撤廃されたことで、純粋に作成できるPRの量が増えた
- DevとOpsの開発容易性の向上
- 開発と動作確認を非同期に行えるようになり、DevとOpsの担当者が互いの状況を意識する必要がなくなった
こうしてリリース改善前は半ば戦地に赴くような心持ちで向き合っていたリリース当番は、今ではML業務の片手間に行えるほど軽量な作業に変わりました。
まとめ
ビジネスに近い領域をMLエンジニアが、システムに近い領域をML Platformが行うという分業体制ができてから、MLエンジニアは以前よりもビジネスKPIの改善に直結するタスク(分析やモデリング)に集中できるようになりました。
一方で、今後とも新しい機能の追加が予定されており、DevOps上の新しい課題も見えてきています。
MLチームとML Platformチームの二人三脚によるDevOps最適化は終りを迎えることはないでしょう。
私達は、メルペイのミッション・バリューに共感いただけるMLエンジニアとML Platformエンジニアを募集しています。
興味を持っていただいた方は、ぜひとも募集要項を御覧ください。
最後までお読みいただきありがとうございました。




