
This post is for Day 17 of the Mercari Advent Calendar 2023, brought to you by @CAFxX from the Mercari Backend Architecture Team.
A few months ago, Mercari realized that an older design was seriously harming our ability to deliver new features quickly and cost-effectively. This realization spurred a rethink of the highest-volume API exposed by our backends. To do so, we clarified exactly what the responsibilities and scope of the new API should be, with an eye on allowing the most efficient implementation possible that still satisfied our business requirements. The result is a much simpler API that is faster, lower-maintenance, and millions of dollars cheaper to run, and a testament to the need, when appropriate, to go back to the drawing board and question long-held assumptions, including about technical and business requirements.
The solution identified, while not too dissimilar at its heart from a standard static asset server, makes full (and somewhat unusual) use of standard HTTP mechanisms – such as content negotiation – paired with an asynchronous content ingestion pipeline to deliver master datasets as efficiently as possible to all clients, internal or external, that need them. The solution is highly reliable, scalable, extensible, and reusable both for additional datasets, as well as a generic blueprint for other classes of content.
Master Data
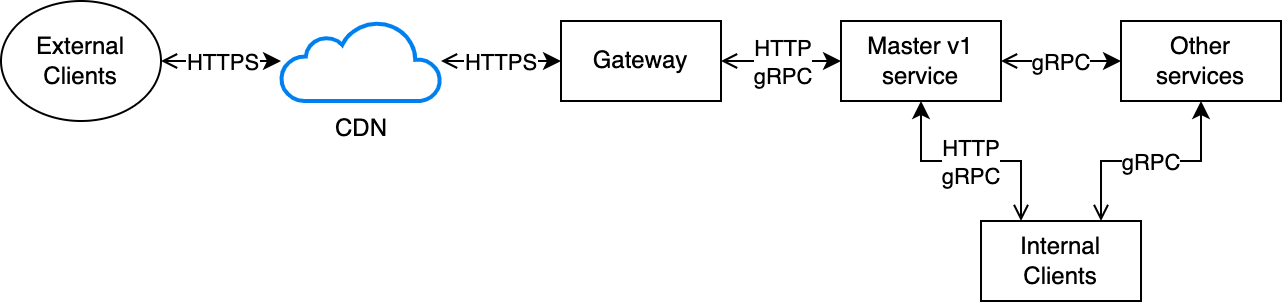
One of the oldest APIs of the Mercari marketplace is the Master API. This API is used by clients – both internal and external – to obtain the master data used as the shared context of our businesses. Without this master data, many of our systems – including clients – are unable to work correctly.
Historically, the master data in Mercari has always been somewhat limited in size, scope, and frequency of updates: most master datasets were in the kilobyte range (with a single notable exception: the list of brands that was over a megabyte in size), and they were very seldomly updated (roughly, a few times per year). This, coupled with the fact that external clients would check for updates to this data only once per session, naturally led to a design that emphasized simplicity (both implementation-wise and maintenance-wise) over efficiency.
The original design, in a nutshell, maintained the master data as static data in the Master service Git repository. A specialized internal tool allowed business users to make and approve changes to the master data, and these changes would be synced back to the data in the repository. When appropriate, the Master service (alongside the modified master data baked into the container image) would then be redeployed.
This approach had the benefit of having no external dependencies, so it was perfectly horizontally scalable and extremely reliable.
At the same time, this simplicity had a few downsides. Internally, the Master APIs – like most of our internal APIs – were implemented over gRPC. This posed a few problems: first of all, gRPC is not really designed for returning responses larger than a few megabytes; this is fine for dynamic responses as they normally implement some form of pagination, but for static responses, this is somewhat inefficient as it forces to implement pagination even if ultimately we always have to fetch the full dataset.
Related to this, all of our gRPC APIs that must be available externally are exposed as HTTP APIs by our gateways, which in addition to performing the gRPC-HTTP transcoding also perform response payload compression. This is normally fine for dynamic responses, but it is fairly inefficient for static ones, as the data returned is almost always identical, so transcoding and compressing it in every response is wasteful, especially since the Master API is the one that consumes the largest amount of egress bandwidth – largely due to the large size of the response payloads.
Over time, as business requirements evolved, the Master API also started supporting some form of dynamic capabilities, e.g. allowing to lookup by ID specific entries inside a dataset or, in some cases, even limited filtering/searching capabilities. This was done mostly for the convenience of other internal services and clients, but had the unfortunate consequence of forcing the Master service to understand the semantics of each of the datasets, pushing onto the team that runs the Master service concerns that should rightfully belong to the domain team that owns each dataset.
Furthermore, in the last year, additional business requirements led to a fundamental change in the architecture of the Master service, in that a minority of datasets were internally delegated to services in other domains. As a result, for these datasets, the Master service started acting as a proxy for the other services – thus adding critical dependencies to a service that initially was designed to have none. Furthermore, over time, internal clients have started to use the filtering/lookup functionalities of the Master service instead of performing the same operations on locally copies of the datasets, thus generating significant amounts of internal traffic, and adding Master (as well as the other services that Master proxies to) to their critical runtime dependencies.
This situation reached a critical point in June 2023, when the brands dataset was suddenly tripled in size as part of new business requirements. The Master team first ran into the (soft) 4MB limit in gRPC response size enforced by our gateways: a temporary exception raising the limit was initially granted to accommodate the larger payloads of this dataset, but it quickly became clear that the API itself had a much more fundamental problem: the increase in payload alone would have cost hundreds of thousands of dollars in Internet egress costs per year. As this was just the first planned increase in dataset size, it quickly became clear that a rethinking of this API was necessary and urgent.
Rethinking the Master API
The initial approach to solving this problem was to reuse a part of the Master API that was partially implemented in the last few years, chiefly the ability for clients to specify they wanted to receive, for a specific dataset, only the records modified since a specified timestamp.
This functionality was initially supported by the Master API, but had not been implemented in clients, that were thus always fetching the full dataset. Consistently using this approach would have helped in some aspects, such as reducing the amount of data transferred on average, but it would have fallen short in others: chiefly, it would not have solved the following problems, among others:
- the Master service would still need to be aware of the semantics of each dataset (so adding additional datasets would have required non-trivial work); this is important as it frees up engineering resources in critical teams
- the APIs to fetch each dataset would have still differed between datasets; this is important as we maintain multiple clients, and each additional API requires work on each of them
- the gateways still had to repeatedly compress the same data over and over; this is important as compression takes up ~⅓ of the CPU resources consumed by our Gateways, and the Master API is, by traffic volume, the top user of Gateway resources
- for datasets delegated to other services, the services would have had to implement pagination and incremental fetching as well; this is important as doing this consistently across teams is not trivial and adds overhead
- modifying the schema of a dataset would have still required work also on the Master service; this is important as it creates overhead and friction when we need to roll out changes
- making the API work with CDN caching would have been quite difficult due to complexity of the existing per-dataset APIs; this is important as adding CDN caching would significantly cut the most expensive line item for this service, i.e. the GCP Internet egress
- clients, due to the availability of the search/filtering functionality on some datasets, have started to treat the Master APIs as dynamic APIs instead of APIs for accessing static data; this is important as it leaks concerns from the domains that own each dataset into the Master service, and this adds unneeded complexity and overhead to a critical
To attempt to solve or alleviate these problems, a proposal was put forward to disentangle the two main functionalities offered by the Master service, i.e. separating the dissemination responsibilities from the master data interpretation ones, and letting the Master service focus exclusively on the former, while delegating the latter to shared components/libraries.
Under this proposal, the new Master v2 service would become a much simpler generic dataset server, singularly optimized for ensuring that any dataset can be made available to all clients that need it as quickly and efficiently as possible. The proposal also contained compelling quantitative estimates for the expected benefits and cost reductions that the design should be able to achieve.
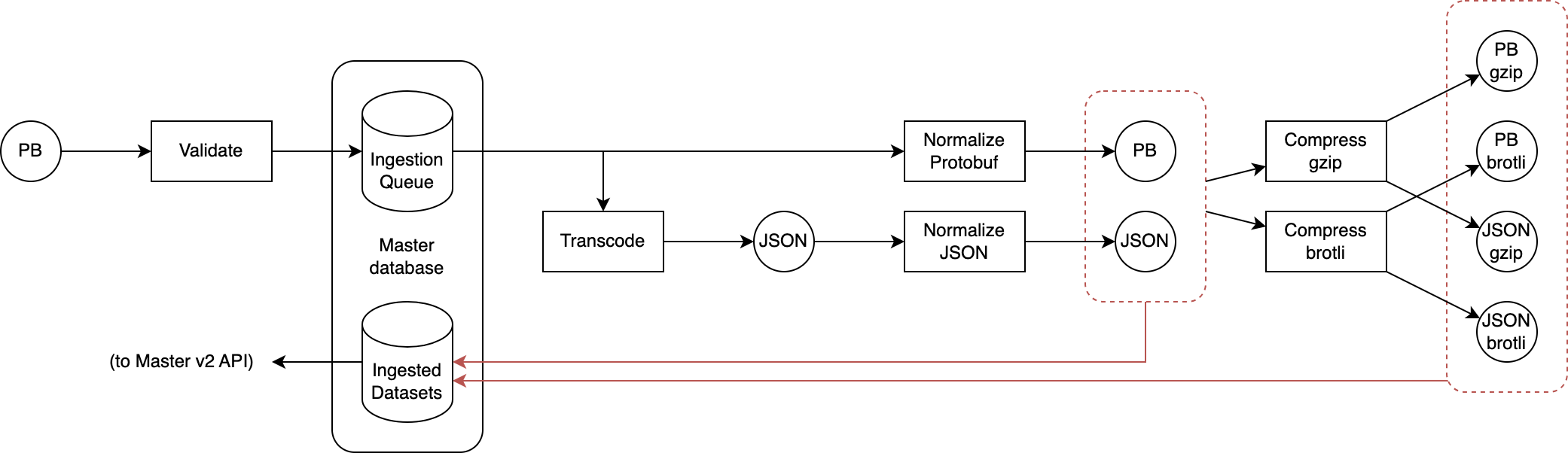
The new design flips the relationship between the Master service and the sources of the delegated datasets: now these services, whenever a new version of a dataset needs to be published, push the Protobuf-encoded updated dataset to an ingester that validates1 the dataset, transcodes it to JSON2, normalizes it3, compresses it using multiple encodings (currently gzip and brotli) at maximum compression level, and assigns a unique ID to each version.
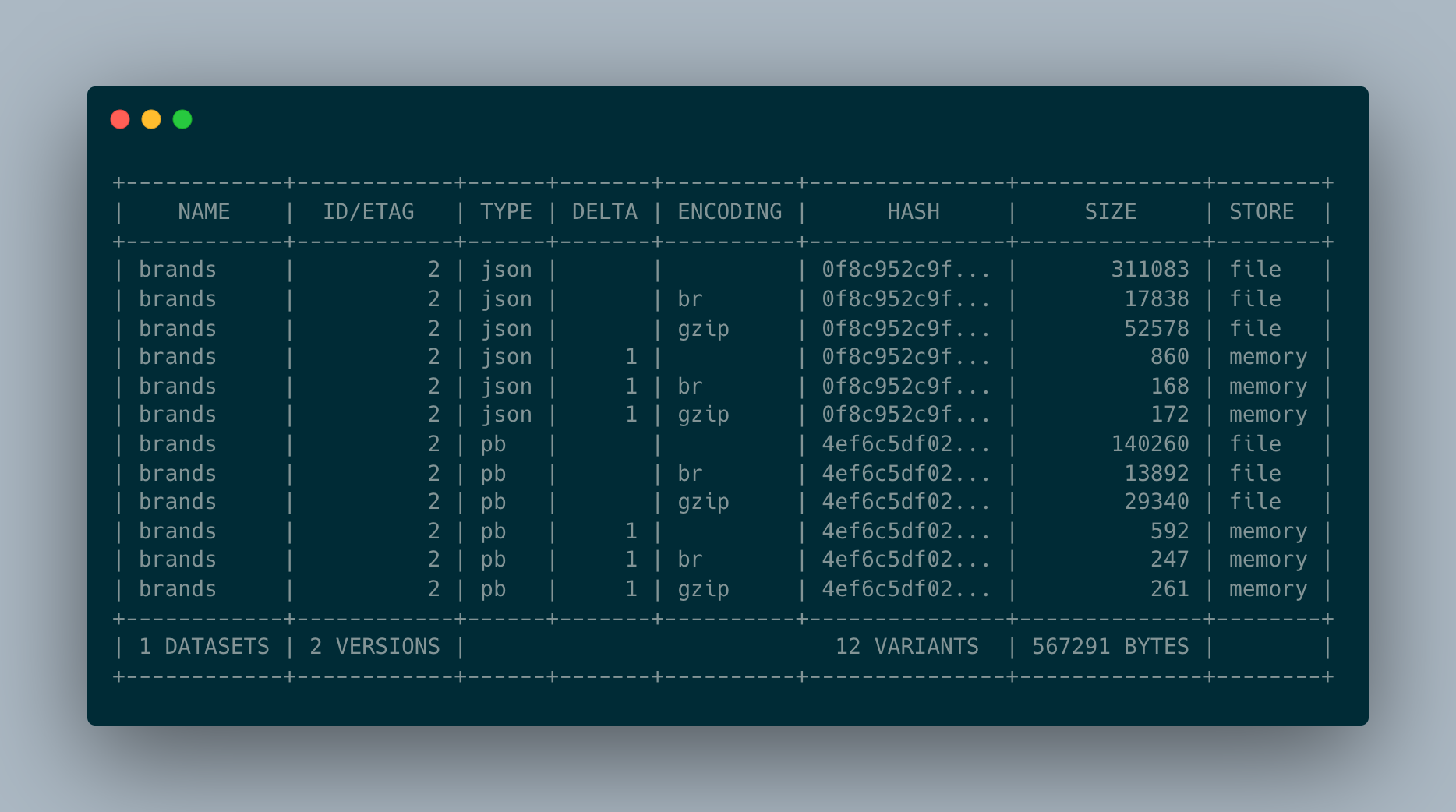
When this ingestion process is complete, all the resulting variants (protobuf, json, protobuf+gzip, protobuf+brotli, json+gzip, json+brotli) of the dataset are atomically stored in the newly-created Master database4. Each replica of the Master service monitors the database for changes, and when any are detected a local copy of all variants’ data is made in the ephemeral local storage of each replica5, while a copy of the variants’ metadata is kept in memory in each replica: this ensures that requests to the Master v2 service can always be served by each replica without relying on any dependency (including the master database itself).
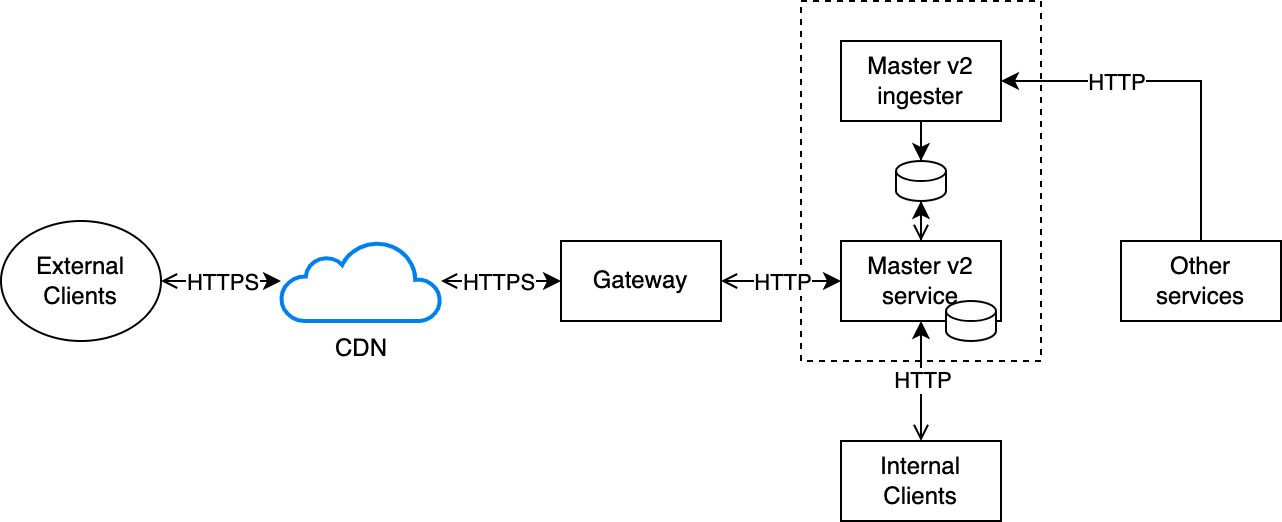
Since each version of the dataset is assigned a unique ID, this ID is also used as an Etag to enable conditional HTTP requests with If-None-Match to return a 304 Not Modified response immediately in case the client already has the latest version of that dataset.
This design allows all requests to be served extremely quickly and efficiently:
- For a 304 response (that is the vast majority of responses) the service performs a single in-memory hashmap lookup to check the dataset ETag
- For a 200 response, the service performs a single in-memory hashmap lookup, followed by sending the response with appropriate content type and encoding that is stored in a local file
As all variants of a dataset are already converted to the appropriate content type and encoding, no further compute-intensive processing is required by either the service or gateway, and the workload thus consists of just serving a static file per request – and that file is likely to be in the kernel page cache anyway6. As a result of this, almost all requests will complete in the order of microseconds, while consuming almost no CPU resources.
Furthermore, as all variants are available ahead-of-time and their metadata kept in-memory, during content negotiation we can trivially perform a neat trick: if the client accepts multiple content types and/or content encodings we can quickly select the smallest among all variants that the client can accept, and transparently serve it to further reduce egress bandwidth7.
This may initially seem unnecessary as one would expect e.g. brotli to always outperform gzip. The reality though is that, depending on the size and nature of the dataset, it is possible for some unintuitive situations to occur, such as a gzip or even uncompressed variant being smaller than a brotli compressed one8. By deterministically selecting the smallest variant among all the ones that the client can accept we can further gain a few percentage points reductions in traffic volume.
This mechanism is fully extensible, and could easily support e.g. additional content encodings and content types: we will get back to this later in the post when we talk about delta encoding, but it’s also worth pointing out that something like this could similarly be used to serve other large static assets (such as images) that can be served using multiple content types/encodings, or even other criteria altogether9.
An additional benefit of this design is that, as the datasets are versioned and rarely changing, and the payload depends exclusively on metadata in the request (the dataset name contained in the URL, and the Accept, Accept-Encoding, and If-None-Match headers) it is safe to enable CDN caching on the API serving the datasets10. Doing so, with an appropriately-tuned revalidation policy, has eliminated almost entirely the Internet traffic between our GCP backends and the CDN, as the CDN is able to directly serve almost all traffic, while still allowing new dataset versions to be pushed out to clients within approximately a minute. As a welcome side effect, this also allows the CDN to continue serving datasets to external clients even in the unlikely case in which the Master service is unavailable for short periods of time11.
Once the Master v2 API was rolled out on our backends, our Android and iOS clients, and our web frontends, could migrate to it and implement the caching required to make use of the conditional HTTP requests mechanism. Once support for caching was rolled out in the clients, traffic between the clients and our CDN decreased by over 90% as in most requests the client reports having already the most recent version of the dataset, and thus the CDN can respond with a 304 response.
Thanks to all the benefits and improvements described above, the new Master v2 API managed to cut our infrastructure and traffic costs by over 1M USD/year, matching and surpassing the estimates given in the original proposal. All of this is just considering a subset of the datasets and clients, as only a few datasets, and only the external clients, have already been migrated to the v2 API: once all datasets and internal clients have been migrated, and given the expected increase in active users and dataset sizes, we estimate the savings will be even greater. All of this was achieved while fixing all the issues that we set out to address at the start of this section, and also delivering E2E API latency improvements.
| v1 | v2 (with larger datasets) | ||
| E2E latency (iOS) | p50 | 248mss | 68ms | p95 | 1873ms | 761ms |
| p99 | 10886ms | 4005ms | |
| E2E latency (Android) | p50 | 0.69s | 0.76s |
| p90 | 2.58s | 2.58s | |
| p99 | 12.27s | 5.74s | |
As a final note, it is important to underline how the description given above left out many design and implementation details, such as the client standardization and improvement efforts, or the CDN integration and tuning, that may be covered in future posts.
What’s next?
Master v2, while the migration is not complete yet, is already a significant success, but we know there are some scenarios in which this design may not live up to its efficiency goals.
One such scenario is that of a large dataset that is updated fairly frequently (e.g. multiple times a day). This is something that we currently do not have use cases for, but it is quite possible that in the future we will run into them. Luckily, the design we have chosen has one last trick up its sleeve: delta compression.
Since we know that most clients of our external APIs are under our control and therefore implement client-side caching, we can take advantage of this and use the data in the client cache (of which we know the version, as the client sends it in the If-None-Match header) and use it as the base upon which to apply a delta that transforms the client-cached version into the current one. This would allow our backends and clients to only transfer much smaller payloads, instead of having to download the full dataset every time part of it changes.
This is normally not done as it’s not practical: backends normally do not keep previous versions around to use to compute the delta. But our ingestion pipeline can do this trivially: we already version datasets in the master database, so during ingestion we can easily fetch older versions of the dataset and generate a delta (using vcdiff) from each to the version we are ingesting: each delta is generated against the normalized, uncompressed variants of the previous version, and the results are then compressed as in the case of the non-delta encoded variants12.
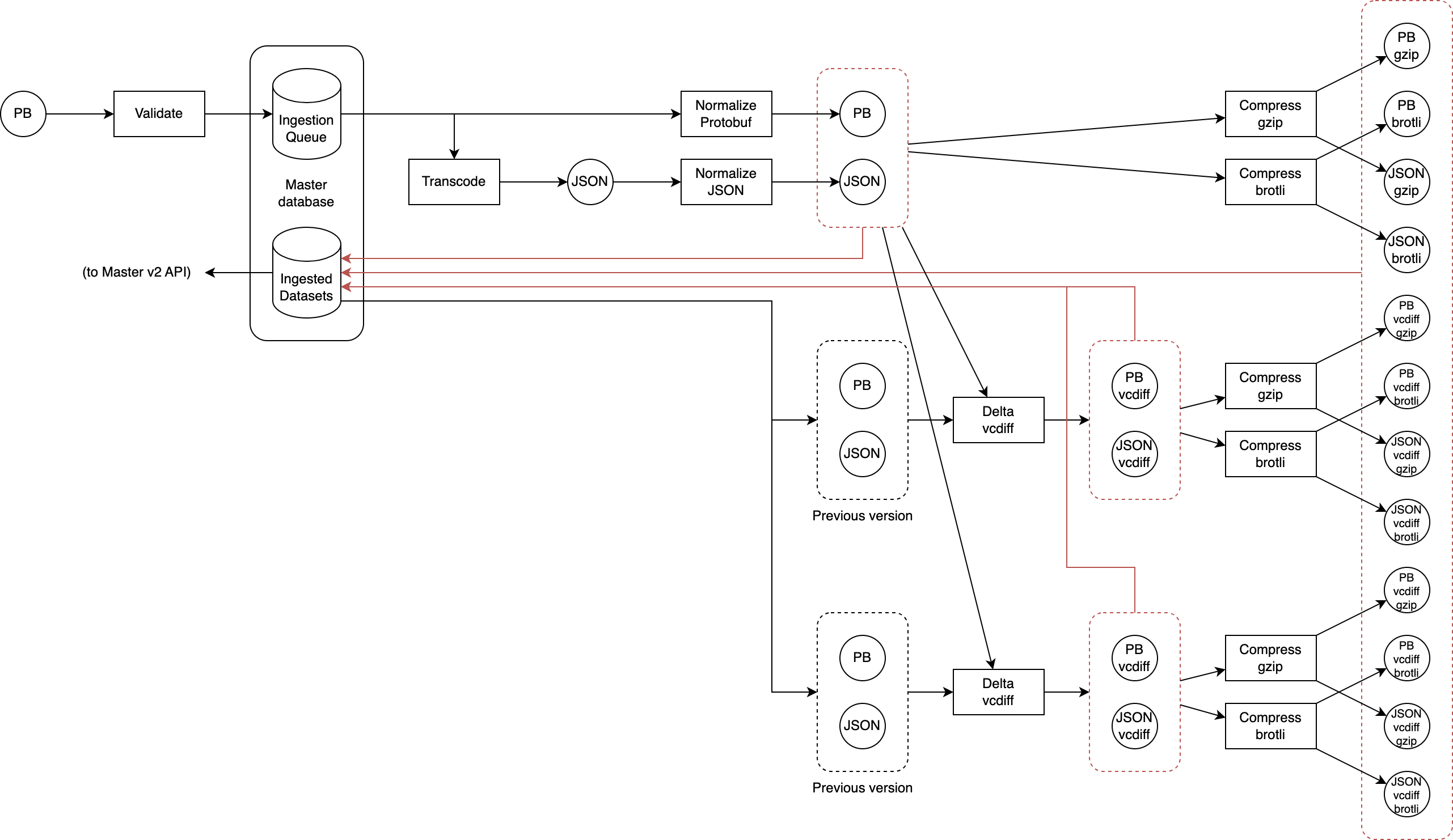
While this may seem much more complicated, its implementation is actually trivial if (as in this case) we have readily available the normalized variants of the previous version we are using as the delta base. It’s true that for each old version that we want to use as a delta base we need to generate a new set of 6 variants, but storage is cheap so this is not a huge concern. Furthermore, the resulting delta-encoded variants are normally very small, as their size only depends on the amount of data added/modified between the delta base and the version we are ingesting. We can also apply a few other tricks to further reduce storage (and bandwidth):
- First of all, as the Master v2 API does not need to support fetching older versions of a dataset, we don’t need to keep delta variants targeting versions older than the most recent one. This means that when we ingest e.g. version 6 of a dataset, we can immediately delete from storage all delta variants that target version 5 or older.
- Because we produce all variants during ingestions, we can immediately prune useless variants. E.g. if the delta variant between v4 and v5 is larger than v5 alone, there is no point in ever considering it for serving (as during content negotiation we deterministically pick the smallest variant that the client supports, and if the client can accept the v4-v5 delta variant, it is also guaranteed that it will accept the full v5 variant). This is true also separately and in conjunction with compression (so e.g. if a gzip-encoded variant is larger than the uncompressed variant, there is no point in ever considering the gzip variant). This protects us from wasting storage on pathological edge cases.
From the perspective of the clients, implementing support for the delta variants is not excessively complicated13: when a client needs to check for an update to a dataset, it sends as usual the request containing the If-None-Match header set to the ETag of the locally-cached version of the dataset, if any. In addition, it adds vcdiff in the Accept-Encoding header: this signals to the Master v2 service that the client can accept delta variants.
Master v2 then performs the usual checks: if the ETag in the If-None-Match is the same as the most recent version of the dataset, it returns 304; if not it performs content negotiation as usual, but this time also considering the delta variants; if a delta variant is selected as it has the smallest payload, the service sends it and adds vcdiff to the Content-Encoding header14 in addition to the compression encoding used (gzip, brotli, or no compression); if not (e.g. because the If-None-Match refers to a version for which no delta variant is available) the full variant is sent, as usual.
When the client receives the response, it first decompresses it as usual, and then if the Content-Encoding header also includes vcdiff it performs vcdiff decoding using the locally cached uncompressed version as the delta base. In case delta decoding fails for whatever reason, including e.g. due to a mismatch between the delta base expected by the delta variant and the one provided by the client cache, clients repeat the request but without specifying vcdiff in the Accept-Encoding header: this forces the server to send a full variant, that will overwrite the locally-cached corrupted dataset version, thereby fixing the problem for future requests.
The benefits of delta encoding are, as mentioned above, that the amount of data transferred depends only on the amount of data modified between versions. Due to this, it is difficult to predict exactly how beneficial delta encoding is going to be, but rough estimates based on current datasets and usage patterns, indicate a further 70~80% likely reduction of egress traffic between the CDN and the clients. Given the already significant cost reductions that were achieved just by the initial Master v2 implementation, delta encoding will likely not make a very significant in absolute infrastructure costs, but will definitely help latency and client power and bandwidth consumption, all things that are fairly important to our users since most of them use Mercari on mobile devices.
There are also other avenues for further reducing bandwidth. One such example is adopting Zstandard in addition to Brotli and Gzip, since web browsers are starting to consider supporting it. While Brotli is normally already extremely efficient, preliminary testing suggests that, on our datasets, Zstandard can often compress JSON variants better than Brotli can – even though this is normally not the case with Protobuf, where Brotli is often better. Another possibility is to use Zopfli to perform Gzip compression instead of the standard gzip tools15 to achieve better compression ratios for gzip variants. Adding support for both would basically just involve adding one more compressor in the ingestion pipeline, and (for Zstandard) support for it during content negotiation. Doing these would likely further cut egress bandwidth, both between backends and CDN and between CDN and clients, by a few percentage points16.
And this is not all: on our roadmap there are plenty of additional features and ideas that were considered and helped shape the extensible design and architecture of the new Mercari Master API; these will be explored and implemented (and possibly documented in followup posts) when good use cases for them materialize.
1 Validation leverages our Protobuf infrastructure to ensure strict syntactical conformance to the Protobuf schema of each dataset.
2 While our Android, iOS, and internal clients consume the datasets as Protobuf, our web clients prefer JSON, so supplying the dataset in both formats was a hard requirement.
3 Normalization reduces the payload and makes it deterministic (e.g. by sorting fields and map keys in a standard order). This helps compression, makes it possible to compute stable hashes that only depend on the semantically-relevant content of the payload and, as we will see later, is especially important for delta encoding.
4 For simplicity and familiarity this is hosted in a small Cloud SQL instance. Performance is not a concern, since the only time when activity occurs on this database is when a new dataset version is posted, and the workload is trivial.
5 As with all other services in Mercari, the Master service is also deployed on GKE with auto scaling enabled, so the number of replicas varies depending on load. As will be discussed later, thanks to CDN caching, the load on this service is extremely low – but if needed (e.g. because of issues with CDN caching that force us to bypass the cache) it can quickly autoscale to handle the whole load.
6 We also use a few other tricks to make this as fast as possible: first of all we use a single long-lived file descriptor per file to avoid opening/closing the file for each request, and we read from the file descriptor concurrently. Second, we store very small variants – approximately smaller than the memory overhead required to keep a file descriptor open – directly in the memory of the Master API service. Both allow us to minimize the number of system calls required to process a single request, minimizing CPU resource utilization and response latency.
7 These advanced content-negotiation capabilities, especially considering the delta encoding functionalities discussed later in this post, is one of the main reasons why we avoided using GCS/S3+CDN to serve the datasets, as it would have been borderline impossible to achieve the same results with lower complexity than a simple API under our full control, fronted by a CDN.
8 This frequently happens for payloads smaller than a few hundred bytes.
9 Quality/bitrate, resolution, aspect ratio, client capabilities, bandwidth, or preferences, etc.
10 Having worked around a number of bugs/quirks of the CDNs we use.
11 Up to a few hours.
12 vcdiff is normally used with LZMA compression, but this is optional and can be disabled. We do this as we do not want to force clients to also implement LZMA decompression. And since HTTP and Master v2 already have mechanisms for compression, we use vcdiff just for the delta encoding/decoding, and delegate compression to standard HTTP mechanisms.
13 In theory the Delta encoding in HTTP RFC specifies also how to use VCDIFF in HTTP. Unfortunately support for that scheme is not widespread among HTTP implementations, so what we are describing here is a custom, simplified solution loosely based on that RFC. Some details required for compatibility with specific CDNs have been omitted for brevity.
14 The Content-Encoding header can contain multiple encodings, so e.g. “vcdiff, gzip” is a valid value that means that the the response payload has to first be decompressed using gzip, and then decoded using vcdiff.
15 This would normally be an absolute no-go for web resources, as Zopfli is famously slow during compression, taking hundreds of times longer than gzip to compress the same data. But because all of this runs exactly once during ingestion, we do not need to worry about whether compressing a dataset takes a few seconds.
16 Both of these examples have already been implemented as PoCs, but we do not yet have reliable large scale numbers about their effectiveness.
Header image generated using DALL-E 3.



