This article is from Day 10 of Merpay Tech Openness Month 2023.
About me:
Hello, Tech Enthusiasts!
Greetings from a passionate techie and an aspiring blogger (though this is my first blog post)!
I introduce myself as Amit Kumar, a software backend engineer at Mercari Inc.
My expertise lies in architecting/designing/implementing/testing/deploying/maintaining scalable and distributed systems. I’ve been edging my skills through hands-on experience, continuous learning, and a deep interest in solving complex technical challenges. You can find more detail about my expertise from my LinkedIn profile.
Knowledge needs to be shared, and that’s precisely why I’ve chosen to write this blog post. Through this blog post, I aim to bridge the gap between the complex technical challenges for everyday engineers.
My goal is to make engineering simple and leverage different ways to make the technology accessible and empower engineers to leverage it effectively according to their use case.
I aim to provide valuable insights, practical solutions, and thought-provoking discussions in this dynamic realm of engineering.
Introduction:
Mercari uses various strategies to engage and retain users of the Mercari app. One such approach is incentivising users by granting incentives.
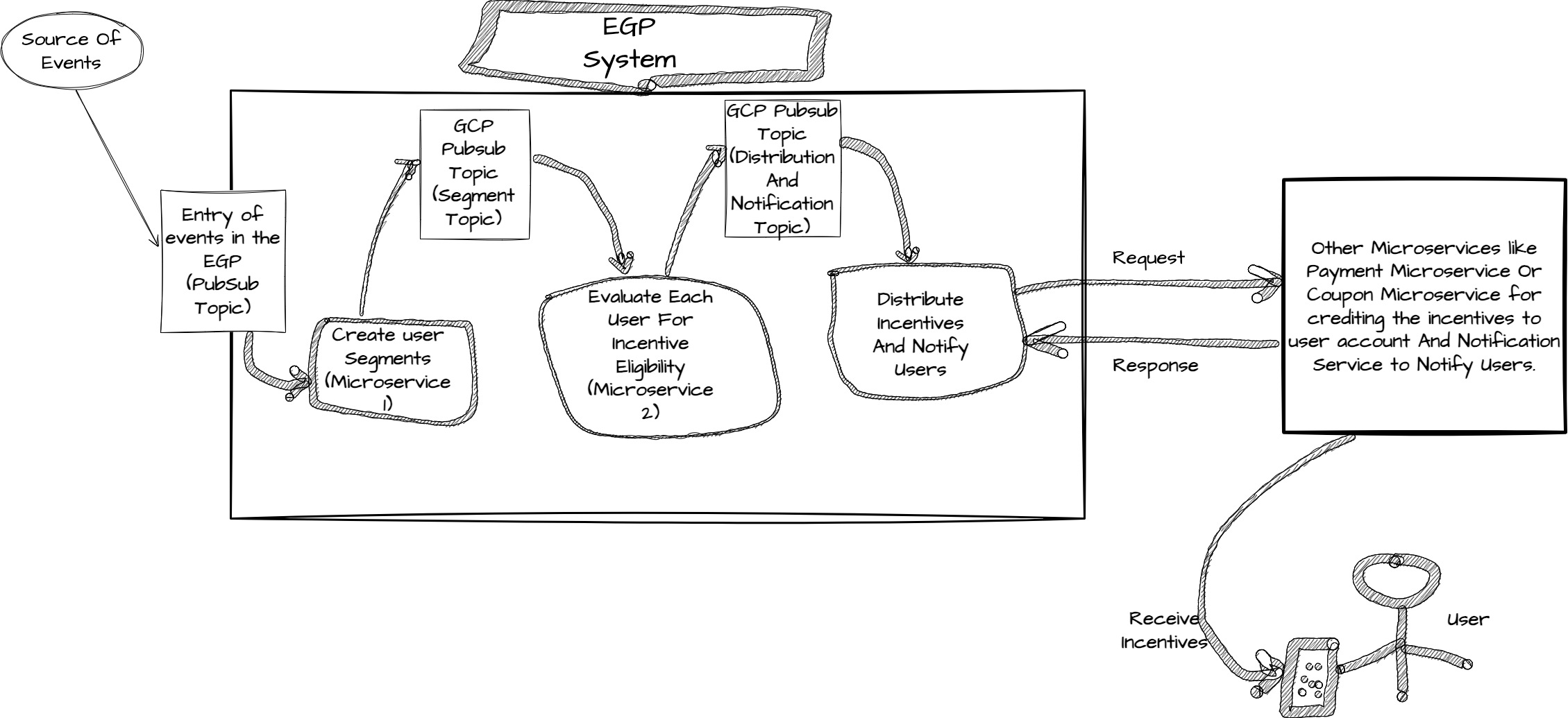
Mercari has an internal platform called Engagement Platform (EGP), which handles the whole incentivisation process. EGP consists of various microservices, and each microservice plays a significant role on its own and helps:
- To define the list of users, we need to incentivise.
- When the user will receive the incentives.
- How to be incentivised, i.e. by Mercari coupon or Mercari points or other mechanisms.
- How often will users be incentivised depending on the campaign participation rules?
- Notify users about the incentives received, i.e. using in-app, push notifications or private messages, etc.
The system incentivises users in real-time or batch. In “real-time”, upon completing the campaign actions, the users receive incentives. In the “batch”, users are evaluated and incentivised based on past actions. Hence, the scale or the amount of requests handled by the EGP system is very high. We need to process millions of requests per day.
Background:
For us, incentivising the users with 100% accuracy and on time is the objective, and it’s not as easy as it sounds.
During the incentivisation process, the system goes through various possible points of failure, and any failure could affect us in two ways:
Failures to distribute incentives correctly would mean a financial loss to Mercari.
If the user doesn’t receive the incentive for his defined action, then we will have an unhappy customer, and thus the whole objective of the engagement platform is at stake.
In modern distributed systems, ensuring high availability and reliability is paramount. Inevitable intermittent failures and transient errors can pose significant challenges to systems. It is necessary to make the system resilient to mitigate the impact of distribution failures during incentivisation. We achieved it by implementing automated retry and recovery mechanisms.
This blog post will discuss how we made EGP fault-tolerant and improved its reliability by designing and implementing a resilient retry and recovery mechanism.
Please enjoy reading it 👍
Challenges Faced:
Before 2021, Mercari had a legacy tool called Ptool, which distributed Incentives. Ptool was a monolithic application; over time, it started to get into many technical constraints. Also, at the same time, it wasn’t scaling to our needs to incentivise more users and be fault tolerant. Hence, the circumstances led us to build a new tool called Engagement Platform based on microservices architecture.
We designed EGP as a common platform for the Mercari Group, including Mercari Marketplace, Merpay (Fintech) and other subsidiaries of Mercari for the entire Japan region.
With Mercari group having more than 20 million monthly active users, designing a system to handle millions of users was necessary and challenging.
Along with being able to scale to handle millions of users, the system also needed to achieve 100% accuracy in incentive distribution by ensuring that:
- We distribute incentives to the users according to the campaign criteria.
- All the users should be able to receive the incentives.
- The system should have the ability to keep track of all the events and can regenerate the same event.
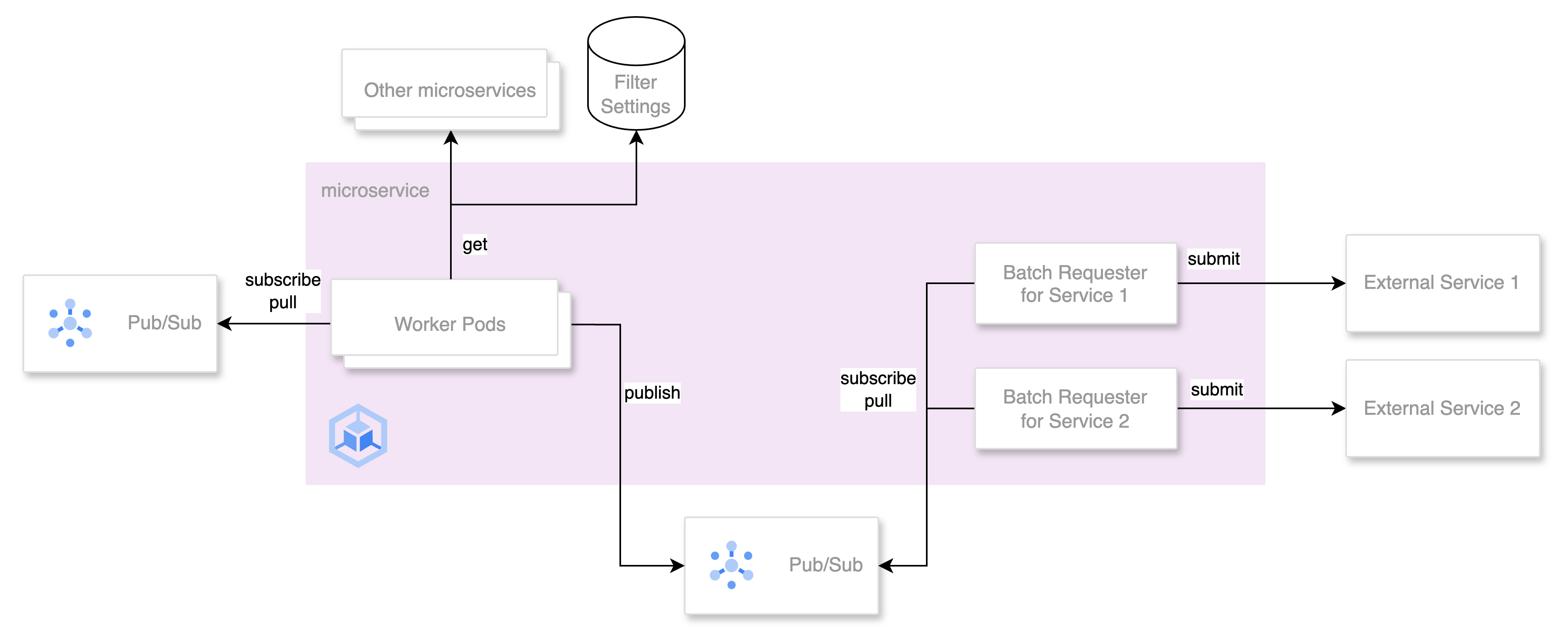
The architecture of EGP
Once the MVP was created and deployed to production, we ran some campaigns and obtained good results. It was time to migrate traffic from ptool to the EGP.
We, as developers, were quite confident that this wouldn’t result in any of the failures we discussed above (developers are always right, right? 😂).
But to avoid distribution risk for the millions of users, we devised the test case and started deep diving into the code to find the failure points (plant UML helped us understand the event flow in our code).
From the architecture diagram, we can see that most of the services are async services. However, as the event moves closer to the incentivisation part, it reaches a service called Incentive Hub which consumes asynchronous events and makes synchronous requests.
Incentive Hub is a critical service responsible for receiving and processing events to distribute incentives to the user.
We started identifying various problems around this service based on our use case.
Here is the part from the architecture diagram around which we had concerns.
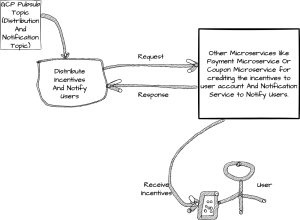
Some of the concerns are listed here:
Data Loss:
- Incentive events are only generated once. If we fail to incentivise a user, we must take extra measures manually to incentivise the user.
Also, when we failed to incentivise the users, even though we saved the event details in the database, addressing the cause of failure and reprocessing those events in the pubsub topic with the same message structure was complicated. And while we fix the cause of failure, the failed event will keep replaying because of the nature of the pubsub. - When we receive the events from pubsub and cannot save it to DB before processing them for incentivisation, it could also result in data loss.
- In any situation, if the system crashes at any point, the processed message could be lost.
In GCP Pub/Sub default behaviour, when an event is NACK-ed by the application explicitly or if we fail to ACK an event within a certain duration (this could happen because the process that pulled the event got terminated for some reason), the event will be republished to Pub/Sub.
Republishing an event to the Pub/Sub when there is a lack of acknowledgement is a sensible behaviour, it means that the message was not processed properly and we might want to reprocess it again.
But it could lead to dangerous problems if not planned properly: reprocessing an event could lead to duplicate distribution of incentives.
This would incur unwanted financial damage to the company.
In summary, the system could distribute duplicate incentives or none when data loss occurs. Impacting the company’s finances in those ways was unacceptable.
There are 2 systems properties that could help to solve these issues:
Idempotency:
- We must ensure idempotency and prevent duplicates for these critical systems. We were able to identify some gaps here too.
- Also, it is not only essential to make one service idempotent. It required all upstream (caller) services to be idempotent to ensure the system’s idempotent.
Consistency:
With multiple read/write happening for one event, we must ensure data consistency in our database.
(I’ll not write about this situation in this blog post as it’s a different topic. But for highlight, we ensured the spanner ReadWrite transactions are in place in our system and validated it using Load tests.
You can read more about Cloud Spanner transactions here)
Strategy and Implementation:
Well, now we have the problem definition in hand and know the root cause of those problems. So it was time to work on the solutions.
Solutions? What could it be? From where to start?
As a software developer, I have a theory that you need to start by writing the main(), and then the rest of the code will automatically get written…lol you will just be able to find the next line of code, which you need to write 😀
The pubsub system will replay (retry) the events when the failure occurs. If we continue replaying the failed events, it could lead to inconsistent services and duplicate distributions.
It was clear that we needed Retry, but to avoid extra distribution because of replaying the messages, we need our system to be idempotent.
Ok! So now, when I can retry the messages, and if my system is idempotent, then we can say that no duplicate distribution would happen. Very nice 👏
How many times to retry?
GCP Pubsub keeps on replaying the event until it is ACKed.
We cannot afford to keep retrying the message even though we know it won’t succeed in case of any issue in the system.
Also, even if the problem was intermittent, like a network issue, we cannot keep on retrying as in all situations, as sending the failed messages to the pubsub topic, there was a risk of creating a mini-DoS attack on self or upstream services. In addition, new events are also coming on the pubsub topic.
So, to overcome this situation, we have to limit the maximum number of retries. Five retries (depending on your use case) could be sufficient; add some exponential back-off and jitter, and with all these, we have a retry mechanism that won’t be stuck in a loop.
Is that all 😣?
We have events failing and retry them for some defined maximum number of times. What do to do after the maximum number of retries? Can we analyze them later? Ohh, yes, let’s recover those failed messages later.
Above was the thought process that followed when trying to find the solution to the problem. And your solutions mustn’t become your system’s new problem.
So, now I’ll write about how we designed and implemented all our thought processes to make our system resilient and consistent and one of the significant steps taken to address the issue of scalability and 100% accuracy.
Idempotency:
The first thing we needed in our system was Idempotency. Idempotency will be the baseline for the strategies we have discussed above.
What is Idempotency:
The system must consistently return the same output for the same input.
Users will receive the incentive only once if the same event is sent more than once on the pubsub topic.
Hence, we need an idempotency key (unique identifier) for every event, which is standard across the system and available with all the microservices in the EGP platform. It would also help us trace our events anywhere in the system.
How we ensure idempotency:
We can do various things to ensure idempotency. But we keep the implementation according to our system’s needs.
- As the event is received, generate a unique key and attach it with the event request to identify it during the incentive distribution uniquely.
- We need to store the event details and the idempotency key.
- Before storing the event details along with the idempotency key, ensure that the event with the given idempotency key doesn’t already exist in the system.
- If it doesn’t exist, save the event details and perform further operations.
- If the event exists, fetch the event details and perform additional functions.
- Before storing the event details along with the idempotency key, ensure that the event with the given idempotency key doesn’t already exist in the system.
These two steps will ensure that event processing will happen only once, even if the same event is replayed more than once by the pubsub system.
Retry:
GCP Pubsub keeps delivering the event to subscribers until the event is ACK-ed. We had the same situation in case of event failure.
We had two problems because of this:
- The same message is getting subscribed multiple times and can cause a mini Dos attack on the system.
- If we ACK a events upon error without persisting it somewhere else, the message will disappear and it may lead to data loss..
Here is what we did to overcome these situations:
-
To limit the replay of the events, we leveraged GCP pubsub configurations to the subscriber upon how many times a message can be NACK-ed.
We set the value as 5 (depending upon the use case).
It helped us retry all the failed messages and re-evaluate them automatically. The events that failed initially because of transient issues could lead to the successful distribution of incentives during one of the retries. -
We retried the failed events with some exponential back-off (progressively increasing the interval between consecutive retry attempts) and added jitter (randomisation) values.
Adding randomisation (jitter) to the exponential backoff strategy helps to avoid synchronized retries and distributes the load on the system during recovery periods. Randomized delays reduce contention and increase the chances of successful retries. -
We leveraged the concept of dead letter queues.
We created a Dead Letter Topic associated with the main Pub/Sub subscription. So, if any event fails, it is retried a maximum of 5 times, and then if it doesn’t succeed on the 5th attempt, it will be sent to DLQ. Hence, this helped remove the failing events from the main pubsub topic and send them to DLQ.
DLQ can be set up easily and cost the same as initializing a Pub/Sub topic.
Since GCP pubsub manages the Retry and DLQ, the chances of failures were meager as their SLA uptime was >=99.95%.
Outcome:
- We could control the number of retries of the failing events.
- We are not worried about retrying multiple times as we already have idempotency.
- The accuracy increased because failing events without retry meant lower distribution accuracy. Because of retry, processing failed messages resulted in successful distributions and improved accuracy.
- Failed events are removed from the system and preserved on a separate dead letter topic.
- Also, any new event is coming to the main pubsub topic, and, for some reason, our system is down or going through some issues. In that case, we don’t have to worry because that event will remain the main topic. Hence, our data loss issue got addressed with this.
Recovery:
Messages that have failed 5 times end up in the DLQ.
To improve our distribution accuracy, we can analyze the reason for the failure of these failed messages by looking at the logs and metrics from our observability and monitoring tools (for us, it’s Datadog).
For reprocessing the same event, we created an Error Worker responsible for saving the failed events that ended up in the DLQ into a DB (called Error DB) so we could keep a persistent trace of it. While committing to Error DB, the Error Worker ensured that information such as idempotency key and the original JSON data of the event were persisted.
By persisting all the failures in a proper DB we can now develop one or several auxiliary components that would be specialized into digging in those failures and perform various tasks like failures reporting, alerting or attempting recovery.
To recover the failed events, we created a job and scheduled it to run at a desired time daily. When required, we could also invoke the job manually using a pipeline. We called this as Recovery Scheduler.
The responsibility of the Recovery Scheduler is to attempt various recovery attempts on the failed events stored in the Error DB. The Recovery Scheduler can process a row from the Error DB and depending on the reason of the failure can execute a dedicated process to attempt a recovery.
For example if the failure was due to one of our upstreams being unavailable for a period long enough and our retry mechanism was not enough. We could imagine that retrying the message once the upstream is back online could recover this event..
That’s why re-sending the message is one of our recovery systems. If we detect a failure likely due to a network error. Recovery Scheduler could decide to re-send the message with its original payload to its original topic several hours after the initial failure when it is likely to succeed. We could even have the Recovery Scheduler check the health of the upstream before attempting the re-sending.
By having such mechanisms in place, our system is able to recover some failures by itself without manual intervention and thus increasing the accuracy of the distribution.
As I mentioned earlier, your solution shouldn’t become your next problem. When the Recovery Scheduler attempts to recover failures, it could start re-sending many events to the original topic. If the system is already going through high traffic and the Recovery Scheduler sends more records, it could cause a mini DoS on our system. It could impact the current state of our services or any upstream services.
To handle this situation, we have added Rate-Limiting, but I’ll not write about it in this blog post.
End-to-end (E2E) Event Monitoring System:
Our E2E monitoring is a vast system, but I would like to mention it here as it helped to monitor our events from source to destination (outside EGP) and ensure that we haven’t missed incentivising any user.
It monitors various systems across the company to create user-friendly failures reports as there is a need for our Project Managers (PMs) and Marketers to be notified about failures to incentivize users.
When such failures happen and are not resolved automatically by EGP systems, PMs and Marketers can decide to take action by contacting our Customer Service (CS) team or can recover those failures manually with various processes (like a manual distribution of incentive targeted at the users who failed to get incentivized).
As such receiving timely reports of failures with the number of users not being incentivized so we can react and resolve these failures is vital for our brand reputation.
EGP systems have different mechanisms to notify about failures to incentivise the users, but their reports are too technical and aimed at engineers. Also, those failure notifications are local to each microservices; hence, it is difficult to have a consolidated overview.
I won’t get into details here, but I would mention that E2E monitoring is one of the backbones of the EGP system.
Here is how our architecture evolved to address these concerns around the Incentive Hub MicroService.
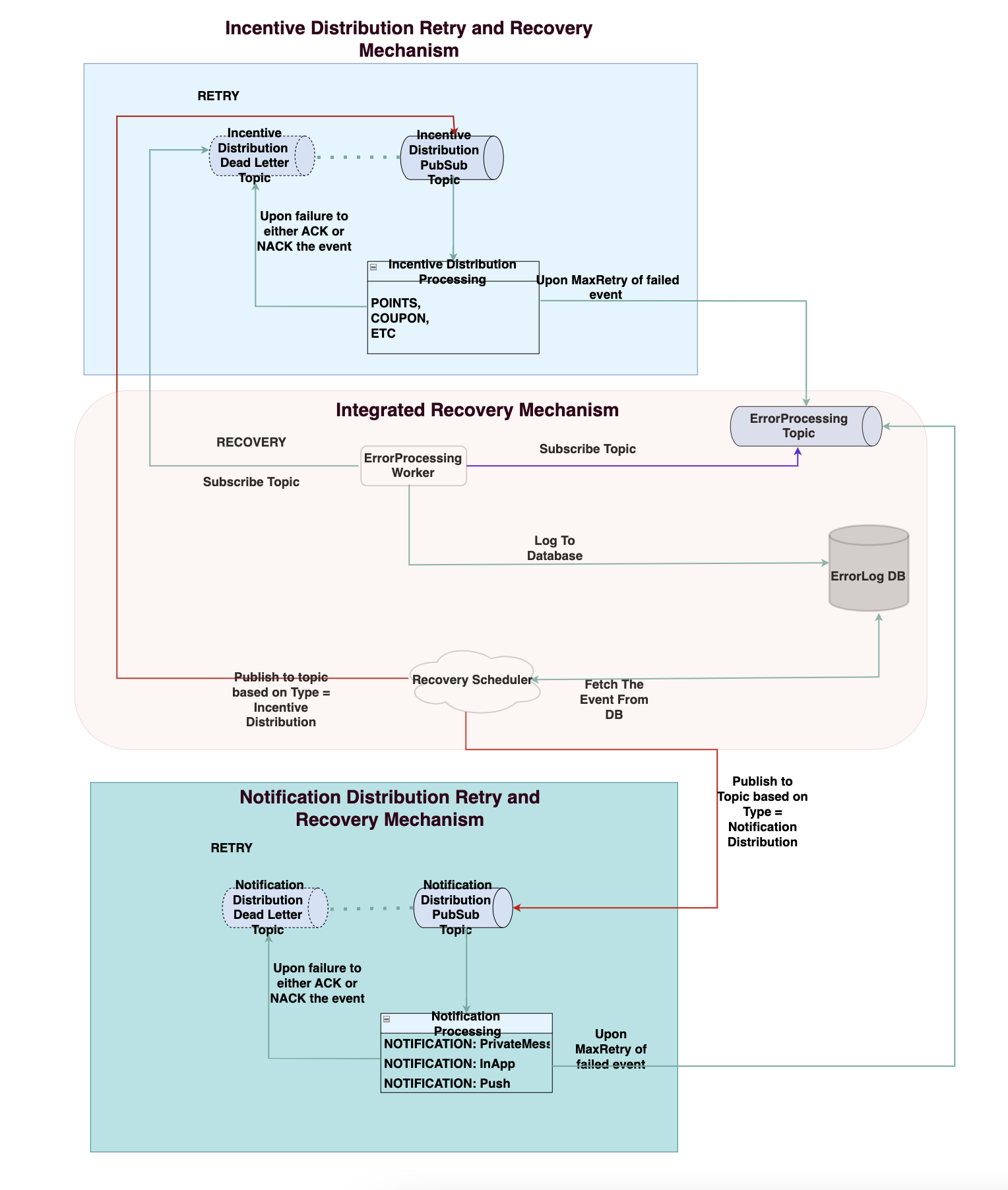
Conclusion:
Our experiments demonstrate the effectiveness of our proposed Retry and Recovery Mechanism in achieving high system availability, handling millions of requests in a day, minimizing data loss, ensuring consistency, and overall boosting distribution accuracy.
Also, I have a short story to share here, which I read on LinkedIn sometime back.
There were three friends, and they had two apples and a knife. They all wanted to eat equal amounts of apples but with only one knife stroke.
There are multiple ways to do it:
1. Line the apples up at a two-thirds offset, and cut through them both with one slice. You’ll end up with two large pieces, each of which go to one person, and two small pieces, both of which go to the third person.
2. Put the two apples together and cut them in half. You get four pieces, give 1 piece to each, and offer the last to someone else.
While 2. doesn’t maximize the apples given to the 3 people, it was never mentioned it had to be.
Engineering is like this; It’s not complex if we can select the right solution depending on our requirements and use cases.
Feedback:
I’m here to learn and grow with you. Your input is invaluable, and I encourage you to join the conversation by sharing your insights, experiences, and even constructive criticism. Together, we can create a vibrant tech community.
Closing Note:
Once again, welcome to Mercari Engineering blog post. I hope you find the content informative, engaging, and thought-provoking. Let’s explore the vast possibilities of technology and embark on this adventure together!
Tomorrow’s article will be by @katsukit. Please look forward to it!