In the previous article, we covered what the Kauru monolithic service was, why Mercari decided to migrate it to microservices, and how the Product Catalog team achieved the first milestone of the migration project. Following that, this part 2 of 3 covers the most difficult milestone of the migration project.
Milestone 2: Kauru as a service proxy (Migration of user generated data)
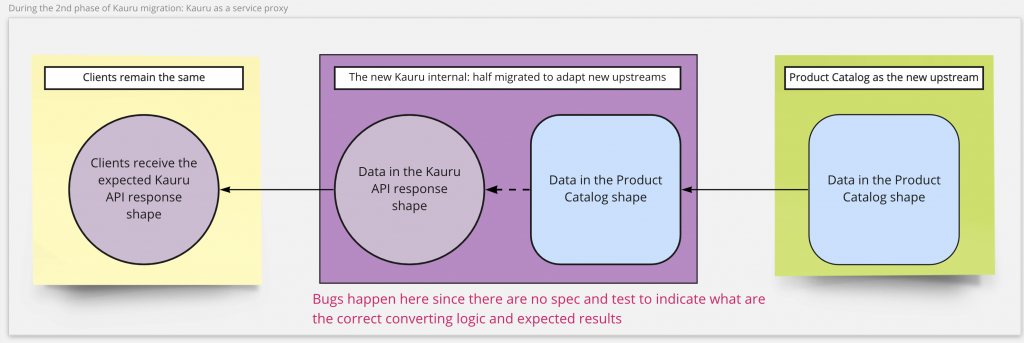
The Kauru internal logic would be re-wired in this second phase to call the product-catalog APIs as an upstream service. The original internal implementation of Kauru would be deprecated. From the aspect of clients, this means the Kauru becomes a service proxy – clients are actually calling the product-catalog to get what they need. However, the API requests, response, PubSub events, and data store tables were still required to match the Kauru specification.
It eventually became the most challenging phase in the whole migration process, and it caused project management turmoil. In addition, making Kauru a service proxy meant the new upstream microservice (product-catalog) needed to provide almost the same features and data as Kauru did.
If Kauru had clear specifications of its APIs, test cases, and examples of what responses clients expect to receive, it shouldn’t have been such a frustrating and long process. Nevertheless, the reality was that anything from the new upstream services not compatible with Kauru would break the app, web, machine learning, and other back-end services. The Product Catalog team was undoubtedly the first to debug every broken part due to the migration.
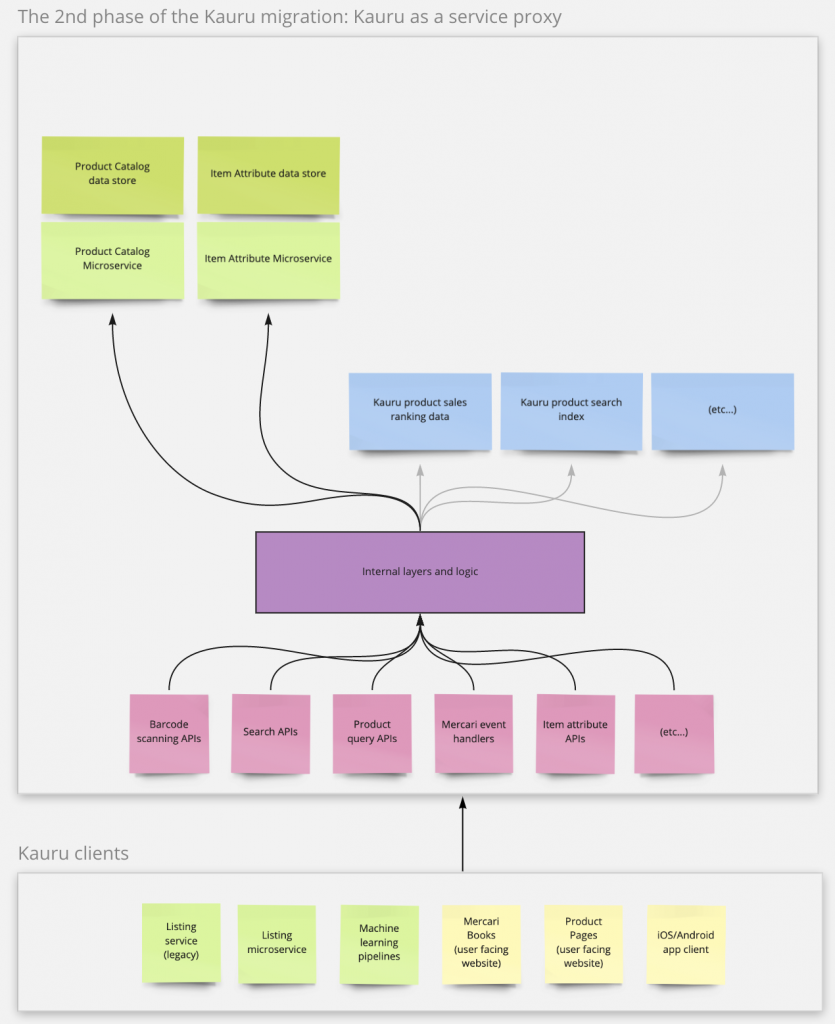
As a result, the small backend API team suddenly was required to debug issues on iOS, Android, web, machine learning pipeline, and other back-end services. Furthermore, after a bug is found, the team must trace back through the half-deprecated Kauru internal logic and eventually to the upstream services with the data just dumped from the Kauru in the previous phase.
Only the product-catalog service was in the team’s control in this whole flow. Even those data in the first phase just dumped from Kauru were not well-known to the team, since the team had neither time nor tools to explore them, not to mention how different clients expect to receive and fetch them.
Another significant difficulty for the Product Catalog team is that such a migration project and its phases won’t excite and satisfy developers. It is more like a “must-be-done” project than a “we-want-it-to-happen” project. Not to mention that there were almost no tech skill growth opportunities except learning tricky workarounds to debug and fix such an old monolithic service. As a result, when the 2nd phase looked like an endless phase due to such new “surprises” found in every sprint, the team and the project were stuck in moral and management hurdles.
The hurdles and the “investigation first approach”
In the previous phase, the team, the manager, and the stakeholders could see the progress sprint by sprint. Although it had never been as fast as everyone expected, it was easy to measure how much data the team needed to migrate and its progress.
Nevertheless, in the 2nd phase, it was impossible to migrate gradually: before the team switches Kauru implementation from itself to the new upstream, the new Kauru internal converters and upstream workarounds all need to be ready to release. Otherwise, such migration changes would break clients until the team delivers a hotfix.
In other words, there was no “today 20%, tomorrow 60%” and so on. In order to prevent breaking clients due to a half-done migration step, the Product Catalog team couldn’t deliver only half of one migration goal (like “half of one Kauru API”). From the aspect of the team manager and stakeholders, it means at the end of the whole sprint, either it is done totally, or there is no progress after all.
Furthermore, in the first phase, the Product Catalog team had barely collaborated with other teams since the first phase was a simple data migration phase. There were no cross-team meetings or discussions to help client teams and the Product Catalog team work together toward the same goal. When it came to the second phase, the relationship between the Product Catalog and other teams was more like a service provider and its customer. If the provider breaks something, it is 100% the provider’s responsibility to fix all the problems.
Such a long and unbalanced feedback loop made the team try to be more careful when changing any place of the Kauru code. The team also tried to manage unexpected bugs and their fixes in the manner of Scrum. The result was that the team prepared four types of tickets before any sprint started:
- User Story (migration goal)
- Investigation
- Implementation
- Bugfix
The idea is to estimate and make progress clear for each migration goal. Ideally, after the investigation task is done, the scope of implementation should be clear, and the need for bug fixes should be limited. In addition, the progress should be clear for the team manager and stakeholders by checking what type of ticket has been completed.


Nevertheless, like all coding experiences show, investigating without actual coding and trying means this approach would never work as the team expected. Even though the team spent a long time on each investigation task, after the implementation task was done, there were still many unexpected bugs reported by the clients.


Because this new approach didn’t work, the crisis continued. Before the second phase was completed, the migration project became a burden to developers, managers, business stakeholders, and even engineering heads. Since it also forced the team to provide fewer new features in longer development cycles per business requirement.
Despite all the tech and project management difficulties, another reason why the project went off track is that all of these participants seriously underestimated the difficulty of executing such a migration project by a small team. It eventually took about two years to complete the project, and lack of resources and cross-team collaboration continuously haunted the team during the migration.
Solution: the proof-of-concept approach
After the team realized that the investigation approach couldn’t fix the issues but made them worse, the Product Catalog team adopted a new proof-of-concept approach (PoC approach) from the MVP principle. Although the MVP principle is usually used to build new features, the Product Catalog team eventually found it helpful in migrating a legacy service like Kauru.
With this new PoC approach, the team does coding work as quickly as possible to check the actual migration scope for one migration goal. Once it is done, a PoC task should be demo-able to all participants, and the developer is allowed to do as many quick and dirty hacks to make things happen as the migration goal requires.
After the demo, the team and stakeholders together will decide if there should be a real implementation task for the PoC. One completed PoC doesn’t mean it must be a formal implementation task. Any PoC can be dropped because it might be too complicated, too time-costly, or too many potential issues shown during the developed PoC. The team manager, business stakeholders, and developers all agreed that PoC tasks are necessary investments with the risks to be dropped, but it is still a worthwhile investment.


if the team decided not to continue with the PoC
The benefit of such a PoC approach is that the PoC developer will explore all potential issues during the PoC task, including client bugs. Unlike the previous investigation first approach, PoCs ask that the result be demo-able, so developers must show something real, or at least very close to real (like, in a test-only runtime environment with production data).
The PoC approach also means the team can deliver something to show the progress for the project and team managers. Also, a demo is much easier to understand and count as progress than an investigation report. By utilizing the demos, upper management and different teams can also understand what the migration project is for and the current progress.
With this new PoC approach, the team finally put the migration project back on track. After the team started the first PoC sprint, migration sprints were planned and executed much smoother than before. It is because PoCs could fit into the Scrum model and reduce the number of overflown tasks. The team can even split the implementation tasks of a PoC. So if a PoC takes a long to complete before the demo, the PoC task itself won’t overflow after separating and moving its implementation task to the next sprint.

There was only one issue remaining with the new PoC approach: when setting a new migration goal, the team sometimes felt it was challenging to create a PoC, and the old investigation approach became more feasible. It is because it is not intuitive to think about what can be demonstrated for the features in some cases. For example, a migration goal was to close the user-facing Mercari Books service. How to do a PoC and what to demo for closing a web service confused team members for a while. It sounds more intuitive and feasible to do a detailed investigation of what impacts may happen if the team closes the service.
However, as the team becomes more and more familiar with the PoC approach, the PoC first approach eventually becomes the default development method for any requirement. Not only for the Kauru migration but for all requirements to the Product Catalog team. This PoC first approach shows its value to team engineers, managers, and business stakeholders, so it is an invaluable lesson the team learned from the Kauru migration project.
After the Product Catalog team achieved the goal of making the Kauru as a service proxy, clients were actually rebased on the new upstream product-catalog service instead of Kauru. Therefore, the next step was to change client implementations to directly depend on the new upstream service instead of keeping using Kauru.
Links
Part 1 of 3:
Migrating a monolithic service under the bed (part 1 of 3)
Part 3 of 3:
Migrating a monolithic service under the bed (part 3 of 3)