This article was published on day 22nd of Merpay Advent Calendar 2021, brought to you by @ravi from the Merpay SRE team.
When it comes to DBaaS, all the cloud providers offer some solutions for meeting various kinds of user requirements. Google’s Cloud Spanner is one such solution from their list of available database options. It is a relational database which can provide unlimited scale, consistency and four nines of availability (five nines for multi-regional setup). This makes it a good candidate for usage at Merpay.
Cloud Spanner provides you with a certain number of Nodes (or Processing Units) and the user data is distributed amongst these nodes. Each node provides a fixed amount of storage capacity (2TB) and consumes varying amount of CPU based on the load. You can add more nodes or processing units to your Spanner instance as your data grows in size.
Spanner usage at Merpay
After using Cloud Spanner for a while, we started facing some issues related to sudden traffic spikes. This sudden increase in the queries to Spanner could originate either from some microservices or as a direct result of increase in user operations. Whenever there is a high volume of queries, the CPU usage would become very high (above the recommended level of 65%) and queries would start slowing down. This would lead to an increased latency for microservices and users could sometimes feel that the operations had become slower. The traffic spike could last from less than an hour to a few hours.
The recommended way to resolve the latency caused by high CPU usage, is to add more compute capacity (nodes), which enables Cloud Spanner to handle larger workloads. At Merpay, we use Terraform heavily in all our operations and have achieved Infrastructure as Code through the use of Terraform and GitHub. But when we suddenly need to increase the compute capacity of one of our Spanner instances, making a change to the configuration files and getting it merged through a pull request after approvals, is a time consuming task. Not to mention that the spike in CPU usage has to be detected and someone always has to be available to take care of increasing the compute capacity whenever there is an alert for high CPU usage. The whole process from receiving an alert to finally increasing the compute capacity, would easily take 10 minutes at the very least. Using Cloud Console (GUI) is a little faster, but leads to divergence from Infrastructure as Code model.
Thus, we felt the need for automatically performing these scale-up operations whenever CPU usage crossed a certain threshold. To heavy users of Kubernetes, this requirement would seem very similar to that of a Horizontal Pod Autoscaler (HPA) in Kubernetes. Since Merpay’s microservices are all containerized and everything is deployed and run on Kubernetes, this idea of autoscaling the Cloud Spanner compute capacity just like we do for all our deployments using HPA, was very natural.
Origin of Spanner Autoscaler
So we set out to build a Kubernetes operator (using kubebuilder) which would work just like an HPA but would monitor and scale Cloud Spanner instances. Achieving autoscaling for Spanner instances, would not only solve our problem of handling sudden latency spikes due to CPU surge, but could also be helpful in saving additional costs by removing unused compute nodes. Active users of Spanner would already know that the cost of a Spanner instance can increase quite steeply for each additional compute node. Thus, adding that one or two extra nodes for resolving a latency spike and then forgetting to remove them later, could have a considerable difference on the monthly bill.
The Spanner Autoscaler started as an internal project, but suddenly realizing that this solution is something generic which can be used by anyone, we open sourced it (at mercari/spanner-autoscaler) and continued development.
Merpay encourages the use of open source technologies and actively tries to contribute to open source whenever possible. You can take a look at our open source projects on GitHub here. Our team has also made large contributions to several projects under the cloudsapnnerecosystem community on GitHub. yo, spanner-cli and wrench to name a few.
The Spanner autoscaler is completely Kuberentes native and works by monitoring the CPU metrics of a Spanner instance. Whenever the CPU usage crosses a certain threshold, it computes the number of nodes which should be added to bring the CPU usage within the limit. It then adds the desired number of nodes and continues to monitor the Spanner instance. Similarly, if the Spanner instance is over provisioned and removing some compute capacity will still keep the CPU usage within the threshold, the autoscaler will delete the over provisioned nodes.
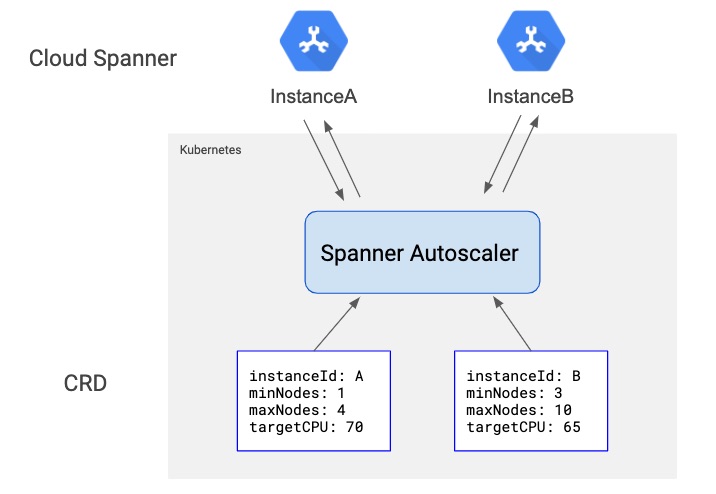
Since it is a Kubernetes native solution, it can be installed on a k8s cluster using well-known tool Kustomize as well as (lesser-known) kpt. After installation, various Spanner instances can be configured for autoscaling by creating a custom resource. An example of a minimal SpannerAutoscaler resource can be as follows:
apiVersion: spanner.mercari.com/v1alpha1
kind: SpannerAutoscaler
metadata:
name: spannerautoscaler-sample
namespace: your-namespace
spec:
scaleTargetRef:
projectId: your-gcp-project-id
instanceId: your-spanner-instance-id
minNodes: 1
maxNodes: 4
targetCPUUtilization:
highPriority: 60Following figure shows an overview of how such multiple resources can be used for autoscaling multiple Spanner instances:
Features of Spanner Autoscaler
Since its creation, the Spanner Autoscaler has been improving continuously. This is what we use for managing the compute capacity of a lot of our internal Spanner instances in development as well as production. And while the initial version only supported a single authentication mechanism (GCP Service Account JSON key), it now supports key-less authentication too.
Some of the noticeable features of this autoscaler are as follows:
- Easy to install:
It can be easily installed in any Kubernetes cluster with just a few simple steps using Kustomize and/or kpt. Installation instructions are here. - Easy to use:
Custom Kubernetes resources can be created quickly and easily to manage compute capacity of any Spanner instance. Some examples can be found here. - Minimal GCP setup:
You just need to create a GCP service account and provide it permissions to modify your Spanner instance. The autoscaler can then use this service account’s JSON key for node addition or removal. Exact steps can be found here. - Advanced authentication methods for enhanced security:
You can also choose to go one step further for making your setup more secure by using key-less authentication methods. If deployed in a GKE cluster, the autoscaler can make use of Workload Identity and impersonation. More details on these methods can be found here. - Open Source, flexible, extensible:
Since it is an open source solution, you can browse through the code or make modifications to it or on top of it according to your requirements: mercari/spanner-autoscaler.
[coming soon] Scheduled scaling:
There are times when autoscaling isn’t just enough. At Merpay, we often run some batch processing jobs on our Spanner databases and sometimes these can be responsible for causing high CPU usage and causing disruptions to user facing requests. So we are working on introducing a scheduled scaling feature so that we can scale up our Spanner instances right before a batch processing job begins. Some discussion on this can be found on this github issue.
Spanner Autoscaler in Production
The Spanner Autoscaler has helped avoid some incidents in our production infrastructure. It kicks in as soon as the CPU usage starts increasing and can prevent our applications from getting affected by increasing latency due to traffic spikes. It also automatically keeps increasing the compute capacity gradually as the number of users grows over time. As already mentioned earlier, this helps in saving our infrastructure costs too, by automatically removing over provisioned compute capacity.
Mitigating latency during traffic spikes
An example of Spanner Autoscaler usage from one of the incidents can be found below:
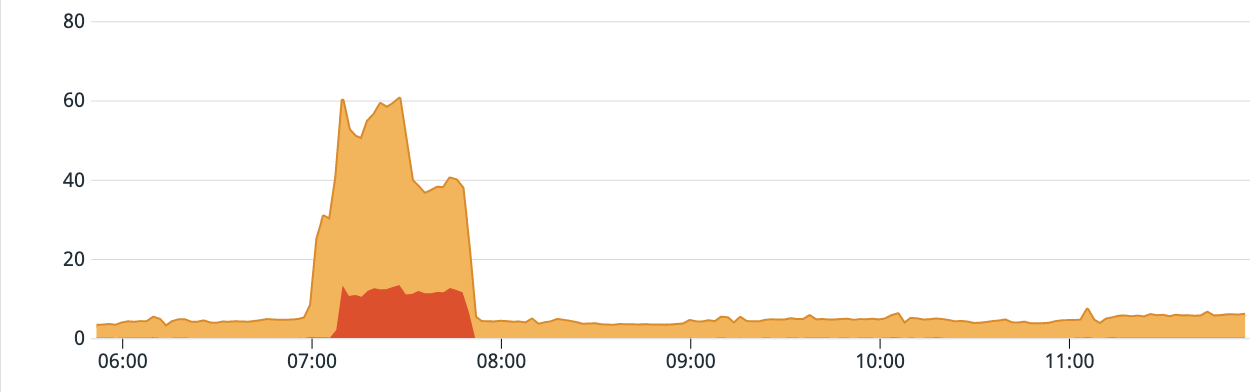


It can be seen here that when the CPU usage increased, the Spanner Autoscaler increased the compute capacity to bring the CPU usage under threshold limits. This helped in alleviating the existing latency spike and in avoiding any new latency spikes which could have been caused by high CPU usage.
Downscaling during night time
Another team used the Spanner Autoscaler for saving their costs while still improving their reliability. The microservice which they have built is used mostly during the daytime. They set the target CPU usage to just 20%. By setting the target CPU threshold to such a low value, they can rest assured that their service can easily handle even large spikes in CPU usage. But this increased confidence and reliability does not come at any extra cost because the Spanner Autoscaler automatically removes these extra nodes at night time, when there is almost negligible traffic.
This can be seen from the following graph:

Comparison with another Spanner Autoscaler
There is another approach to autoscaling the Spanner compute capacity which is mentioned in cloudspannerecosystem/autoscaler. As can be seen from the architecture, it is completely based on tools and solutions from GCP.
However, since we had already adopted Kubernetes for running all our workloads, mercari/spanner-autoscaler was designed with a reconciliation based approach and was well suited for our infrastructure as code model (which is largely YAML based).
Users with non-kuberenetes based environments might prefer to manage the autoscaling of their Spanner instances using cloudspannerecosystem/autoscaler approach.
Coming Soon
As mentioned in the features section above, in addition to real time scaling, we are currently actively working on a scheduled scaling feature which would allow users to scale the compute capacity of Spanner instances at predetermined times as well.
We here at Merpay are actively developing the Spanner Autoscaler and are planning to soon adopt it for managing the compute capacity of all our Spanner instances. We will continue to work on any new requirements which we come across or things which can be improved.
Please give mercari/spanner-autoscaler a try and let us know your feedback!
References
- https://github.com/mercari/spanner-autoscaler
- https://kubectl.docs.kubernetes.io/guides/introduction/kustomize/
- https://kpt.dev/
- https://cloud.google.com/spanner/docs/cpu-utilization
- https://cloud.google.com/spanner/docs/latency-guide
- https://cloud.google.com/blog/products/identity-security/enable-keyless-access-to-gcp-with-workload-identity-federation