If at first you don’t succeed, try, try again. Then quit. No use being a damn fool about it
— W.C. Fields
Hi, this is @prashant, from the CRE AI/ML team.
After reading this blog post, you will have an understanding of the retry pattern used in microservices architecture, why it should be used, a few considerations while using the retry pattern, and how to use it in Python.
Microservices
We are living in the age of microservices. We can split a monolithic application into multiple smaller applications called microservices. Each microservice is responsible for a single feature and can be deployed, scaled, and maintained independently. Many leading tech companies like Amazon, Netflix, Uber, Spotify have adopted the microservice architecture. You can read Understanding basics of what/why/how in microservices blog post to understand how we use microservices in Mercari.
Since microservices are distributed in nature, various things can go wrong. The network over which we access services or services themselves can fail. There can be intermittent network connectivity errors. Service can fail due to pod evictions, out of memory errors, temporary unavailability of dependencies, deployment environment failure, hardware failure, etc. To make our services resilient to these failures, we adopt the retry pattern.
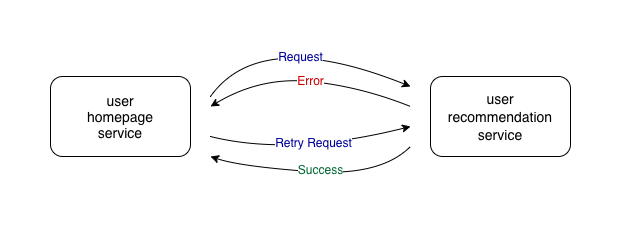
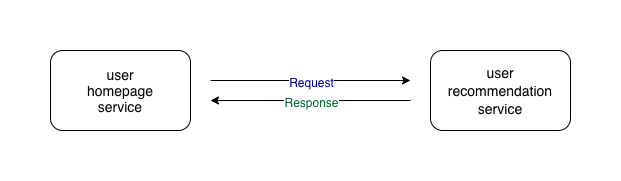
Before we go ahead and understand the retry pattern, let’s go over some terminologies. A service that calls another service is the caller service and the service that is called by the caller service is the callee service. In the following example, the user homepage service is the caller service and the user recommendation service is the callee service.
Retry pattern
The idea behind the retry pattern is quite simple. If the caller service receives an unexpected response for a request, the caller service sends the request to the callee service again.
If the request failed due to some transient faults, e.g. network issues, database connection issues, etc., retrying can be very useful.
Considerations
We will go over a few considerations while using the retry pattern. We will also see how to use it in Python.
We will be using tenacity library, originated from a fork of retrying library, to implement the retry pattern. We are not using the retrying library as it is no longer maintained.
We will add the retry decorator from the tenacity library to the function in which we call another service. If you are unfamiliar with decorators, you can read the Primer on Python Decorators
blog post.
Immediate retry
The most obvious thing to do when a request fails is to send it again and again without waiting until we receive an expected response. For example, if a request fails due to some rare error like packet loss, there is a high probability that the request will succeed if we just send the request again without waiting. We can achieve this when we are calling another service by adding the retry decorator.
from tenacity import retry
@retry
def call_user_recommendation_service():
...In this example, if an exception is raised while executing call_user_recommendation_service, this function will keep executing again and again without any delay between the retries until no exception is encountered while executing it.
Limiting the number of retries
Continuously retrying until we get an expected response is not a very good idea. The retries from all the failed requests will keep getting accumulated and can cause a high load (high QPS) on callee service. If the callee also depends on other services, a huge number of requests might be triggered and can result in a cascading effect. If the callee service is in the failed state and later it recovers, the huge number of accumulated requests can overwhelm the system and can result in the failure of the service again. If the callee service is in the failed state due to overload itself, the huge number of accumulated requests can prevent the service from recovering.
Another side effect of a huge number of accumulated requests is that they can also clog the network and can affect the performance of other services.
So, while using the retry pattern, we should limit the number of retry attempts. In the following example, we use an upper bound of 3 for the number of retry attempts.
from tenacity import retry
from tenacity.stop import stop_after_attempt
@retry(stop=stop_after_attempt(3))
def call_user_recommendation_service():
...
Adding delays between retries
Adding delays between retries can help in making our services tolerant to transient faults. We add delays in the hope that by the time we make the next retry attempt, the fault is rectified.
There are various strategies for determining the interval between retry attempts like
- exponential back-off: exponentially increase interval after each attempt,
- incremental interval: incrementally increase interval after each attempt,
- regular interval: wait for a fixed interval between each attempt.
Let’s look into one of the most commonly used strategies – exponential back-off and jitter. We will look into the Full Jitter algorithm described in this AWS blog post.
In this approach, we make each retry attempt at a random time in a geometrically expanding interval with an upper limit for the random interval.
The wait time between retry attempts in the “Full Jitter” algorithm is given by
wait_time = random_between(0, min(cap, multiplier * (2 ^ attempt)))The following example shows how we can use this strategy in Python:
from tenacity import retry
from tenacity.wait import wait_random_exponential
@retry(wait=wait_random_exponential(multiplier=1, max=60))
def call_user_recommendation_service():
...
In the above example, caller service will wait randomly between 0 and 2 seconds before starting attempt 2.
wait_after_attempt_1 = random_between(0, min(60, 1*(2^1)))
= random_between(0, 2)Similarly, after attempt 2, caller service will wait randomly between 0 and 4 seconds. After attempt 6 and onwards, caller service will wait randomly between 0 and 60 seconds because here, 60 is the upper limit for the random interval.
wait_after_attempt_6 = random_between(0, min(60, 1*(2^6)))
= random_between(0, min(60, 64))
= random_between(0, 60)Retrying only on certain exceptions
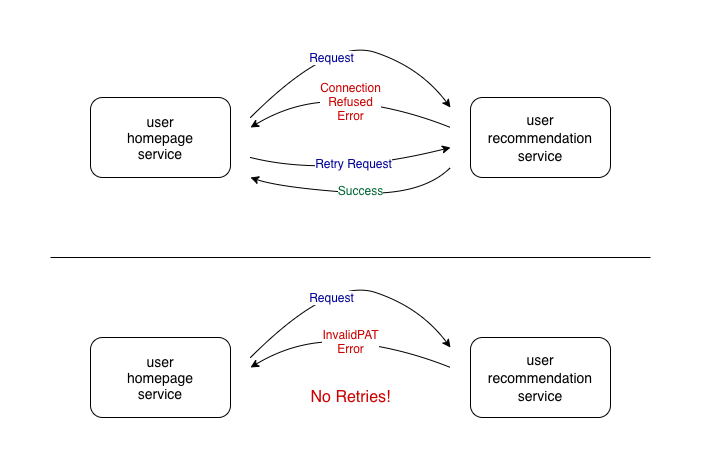
We should only perform retries if there is some chance that the request will succeed when reattempted. For example, if the access token associated with the request is invalid, there is no point in retrying it. So, we should retry only if certain types of exceptions are raised.
In the following example, retries are performed only if the ConnectionRefusedError exception is raised.
from tenacity import retry
from tenacity.retry import retry_if_exception_type
@retry(retry=retry_if_exception_type(ConnectionRefusedError))
def call_user_recommendation_service():
...
Few other considerations
- If the operations provided by the service are not idempotent, retrying might cause inconsistencies in data. To avoid this issue, we should design the services such that the operations provided by them are idempotent. However, some operations require state change. We should make these operations idempotent by detecting duplicate requests.
- We should make sure that retry count and interval are optimized for our particular use case. Not retrying a sufficient number of times can result in frequent failures. Retrying too many times or very small intervals between retries can result in system overload, high resource usage, and network congestion. We should also consider how critical a particular operation is and whether it is a part of a resource-intensive multi-step operation to determine optimal retry count and interval.
Conclusion
We learned about retry pattern, why it should be used and how it can make our services more resilient. We saw examples of how we can use the tenacity library to limit the number of retry attempts, to add delays between retry attempts, and to perform retries only for certain types of exceptions. We can combine all these in a single example as follow:
from tenacity import retry
from tenacity.retry import retry_if_exception_type
from tenacity.stop import stop_after_attempt
from tenacity.wait import wait_random_exponential
@retry(
stop=stop_after_attempt(3),
wait=wait_random_exponential(multiplier=1, max=60),
retry=retry_if_exception_type(ConnectionRefusedError),
)
def call_user_recommendation_service():
...There is much more that we can do with the tenacity library including using callbacks to execute certain actions before and/or after retry attempts, collecting retry statistics, etc. Check out tenacity documentation for more details.
In summary, if you want to go ahead and add the retry pattern in your microservices, please keep the following points in mind:
- limit the number of retries,
- add delays between retries,
- optimize retry count and interval for a particular use case,
- design idempotent services,
- perform retries only on certain exceptions and error codes.




