Hello, this is @shido from CRE (Customer Reliability Engineering) AI/ML team.
What do you think about writing production code in Python?
I know there are some negative opinions such as "I don’t want to use Python except for research/analytics", "Poor performance", or "I don’t want to use dynamically typed language".
However, if you want to create a machine learning service (or a service for a machine learning service), you might want to use the same Python data pipeline or ML library (or same code) in production. This is one of the motivations to implement the backend in Python.
Today, I would like to talk about basic tips about type hints in Python to write code at the same level of readability, maintainability, and type safety as common server-side languages like Go and Java.
The intended readers are
- People who have never written Python outside of Notebooks
- People who program only for researching and analysis
- People who haven’t touched Python for years
and on the contrary, the content might not be suitable for
- People who can write in a lot of other programming languages
- Senior backend engineers
Background
Microservices and Python in Mercari
As introduced in past entries, Mercari is promoting microservices. As a result, each microservice developer can freely choose the programming language that suits their service. However, Mercari’s current mainstream language is Go and most microservices including the core of the service are written in Go.
However, as mentioned at the beginning, we were motivated to use Python for the machine learning related microservices to use the same libraries and code as the stage of researching or experiment and therefore now Python is increasingly being adopted as the main language for some teams. Libraries we want to use could be a library for writing data preprocessing pipeline, a library for performing natural language and image preprocessing, a Python wrapper for libraries written in C, or a library to serve models in some cases.
Experimental code and production code
In recent years, many people use Python for implementation of machine learning and data mining research and data analysis. I think such people also use Notebooks often. This is just my personal opinion but these personalized codes tend to be focused on short-term experiment and modification, and may not be so good for readability or maintainability.
One of the attractions of Python is that we can easily experiment and analyze it with Notebooks or even raw code. However, in a large company or community, production code must be maintained by many people over the years and therefore it is necessary to ensure the quality. In this post, I would like to share some tips to write clean and readable code with "type hints" at the time of implementing production code from the experimental code.
Main Contents
Python and type
Python is a dynamically typed language. If you write an operation with wrong types, Python raises a TypeError and an Exception will be thrown so it can be said Python is type-safe (there are various opinions about what type safety is. I won’t go into the details here). Since Python checks the type only at the runtime, no compiler can tell you the error due to the type in advance. To make matters worse, readers had to follow the code while imagining the type since the type is changing dynamically.
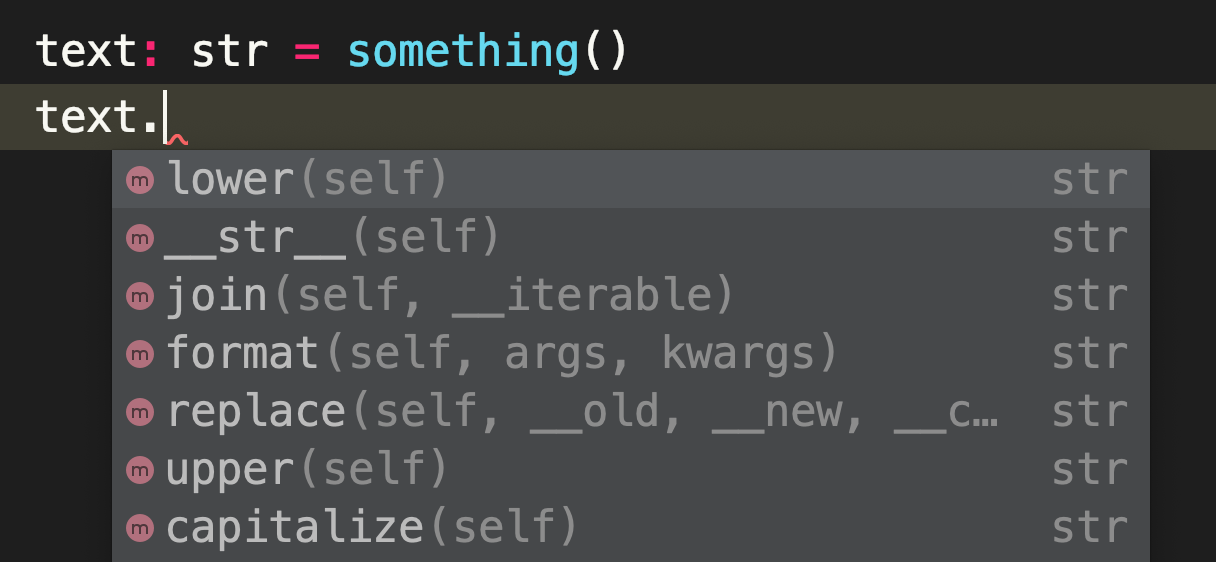
However, the syntax of Python has changed significantly since Python 3.5 and it is now possible to optionally annotate functions with types. By checking types in advance, you can eliminate TypeError or AttributeError that passes the unit test (there may not be many though). In addition, annotations also allow your IDE to complement attributes and methods based on types. This will make your development more comfortable. Also, other developers can read and develop code with type awareness, and it makes maintenance easier.
This is an example of type hints.
ALLOWED_INTEGERS = {1, 2, 3}
def check_integer(x: int) -> bool:
return x in ALLOWED_INTEGERSThe type hints has been continuously improved. In Python3.6, the syntax was changed to support type hints for variables as suggested in PEP 526. In Python3.7, postponed evaluation of annotations was added as suggested in PEP 563 so that Python supports forward references and annotation has less impact on execution speed. Also in Python 3.9, PEP 585 allows you to use standard collection types to annotate generics. It seems that Python 3.10. Will also add some specifications for type hints. It seems that some specification changes related to type hints are planned in Python3.10 as well.
import typing
ALLOWED_INTEGERS: typing.Set[int] = {1, 2, 3} # Python 3.6
ALLOWED_INTEGERS: set[int] = {1, 2, 3} # Python 3.9
def check_integer(x: int) -> bool:
return x in ALLOWED_INTEGERSOf course, we need to use a static type checking tool to prevent errors due to types. Python still throws an exception at runtime just by annotating. You may set up a type check tool in CI or somewhere to prevent incorrect images from being deployed. Well-known tools for type checking include Dropbox’s “mypy”, Google’s "pytype", Microsoft’s "pyrite", and Facebook’s "pyre". The tools other than pyrite can be installed from pypi.
Type hints is an optional syntax in Python and can be executed even if it is undefined, but for example in mypy, we can force developers to annotate types on function definitions with the --disallow-untyped-defs option. In addition to checking types, these tools can also detect unnecessary casts and disallow variable redefinition. I think that the degree of strictness should be decided by the requirements and situation, but in my impression, it will be nice to be strict to internal code even if it’s tolerant to third-party libraries.
type hints Antipattern
I think one of the things that enthusiastic Notebook users tend to do is implementing interfaces by only primitive types. For example, let’s think of the case where you write a function to get a sushi order as follows.
from typing import Dict, List, Tuple
def get_order() -> Tuple[str, List[Tuple[str, str, int, bool]]]:
# Processing
return foo # e.g. "no1234", [("Alice", "tuna", 2, True)]Aside from the data structure of the order, can you use these return values in the other part? In fact, this return value represented an order ID and a list of tuples which stands for (customer’s name, fish type, quantity, need wasabi or not). Even if the comment politely explains the return value, it can get confusing every time you call this function and likely to embed a bug when someone makes changes. Even the person who wrote this function will end up opening the file to see the docstring just a few minutes later.
So next they wrote it using a dictionary like this.
def get_order() -> Tuple[str, List[Dict[str, Union[str, int, bool]]]]:
# Processing
return foo # e.g. "no1234", [{user="Alice", fish="tuna", amount=2, wasabi=True}]Readability may have improved a bit, but using such dictionaries doesn’t make much sense for type hinting. The caller will call this dictionary using an str-type key, but you probably don’t want to do that in a production environment. It’s also unfriendly to the IDE. Even if static analysis shows that a returned dictionary has fixed type objects with fixed multiple keys, few IDEs will go into such a depth and provide complements for the object.
Even if type hints are given in this way, without the appropriate data class, it will be difficult to read and you will not be able to fully benefit from the safety of type hints. From the next section, I would like to introduce the minimum things you need to know in order to write this function neatly while making use of type hints, and other things that are useful to know.
type hints and dataclass
Python has namedtuple class and in this case, we can write above dictionary as
Item = namedtuple("Item", ["user", "fish", "amount", "wasabi"])To annotate it, we need to create a class inherited from typing.NamedTuple like
class Item(typing.NamedTuple):
user: str
fish: str
amount: int
wasabi: boolIn this way, we can define a named tuple while explicitly specifying the type of the contents in the container.
>>> Item.__annotations__
{'user': <class 'str'>, 'fish': <class 'str'>, 'amount': <class 'int'>, 'wasabi': <class 'bool'>}Let’s use this for the function.
def get_order() -> Tuple[str, List(Item)]:
# Processing
return foo # e.g. "no1234", [Item(user="Alice", fish="tuna", amount=2, wasabi=True)]Now it is pretty neat.
If you use Python 3.7 or above, data class is available as a standard library. Just by defining fields, the __init__ function and some comparison functions will be automatically defined.
@dataclass
class Item:
user: str
fish: str
amount: int
wasabi: bool
>>> Item(user="Alice", fish="tuna", amount=1, wasabi=True)
Item(user='Alice', fish='tuna', amount=1, wasabi=True)The data class is mutable by default but you can make it immutable like a named tuple by passing the option frozen = True and you can hash the object in this case. You can also set default values like namedtuple, but the behavior is not exactly the same; the dataclass can have multiple fields of parent classes by inheritance; since dataclass is not a tuple, it is not compared to tuples that happen to have the same value; and unlike namedtuple, it has __dict__ (although it can be omitted by defining __slots__).
Let’s define the original function with the above class.
@dataclass
class Order:
id: str
items: List[items]
def get_order() -> Order:
# Processing
return foo # e.g. Order(id="no1234", items=[Item(user="Alice", fish="tuna", amount=2, wasabi=True)])Now the readability has greatly improved. It’s also IDE friendly. For example, many IDEs understand that get_order().items[-1].wasabi is bool if items are not empty. If you implemented the eat(user: str) method to the Items class, your IDE suggests the eat method when you type get_order().items. Also the IDE warns you about type if you try to pass int type to argument user.
On the other hand, attrs is a library that provides similar functionality to dataclass, which is more complex instead of having other functionality in addition to dataclass. For example, with attrs, __slots__ can be defined automatically by passing arguments without implementing by yourself (You won’t use Python if you mind such a thing though). The attrs is not a standard library so you need to install it with pip to use. The PEP also explains why the dataclass was added to the standard library despite the attrs.
With Notebook, you may use dict as a convenient data class that can be used for anything but in production code, I would recommend you to define the appropriate data class and utilize type hints for readability, safety, and comfortable coding.
Enums
While we used str type for the declaration of fish type, there is in fact only a finite number of sushi varieties we’d like for our function to accept as a valid input. For instance, IDEs will not warn us if we accidentally type "tuna" as "tuba". To assist such cases, the Enum class is useful.
from enum import Enum
class Fish(Enum):
TUNA = 1
SALMON = 2
MACKEREL = 3If you’re not interested in the contents of Enums, you may want to use auto(), which was added in python3.6.
from enum import auto
class Fish(Enum):
TUNA = auto()
SALMON = auto()
MACKEREL = auto()If you use or want to use Item.fish as string type, you can inherit it at the same time as Enum.
class Fish(str, Enum):
TUNA = "tuna"
SALMON = "salmon"
MACKEREL = "mackerel"
MAGURO = "tuna"
>>> Fish.TUNA.split("n")
['tu', 'a']
>>> Fish.MAGURO
<Env.TUNA: 'tuna'>
>>> Fish.TUNA.value
'tuna'Let’s use this in Item class.
@dataclass
class Item:
user: str
fish: Fish
amount: int
wasabi: boolNow the code is more robust.
Parameters and envvar
When passing parameters from the CLI or program, if there are many parameters, it is often better to prepare a class for configuration; code gets clean and it’s easy to handle types. In particular, machine learning related classes for functions tend to have many parameters.
For example, the constructor of sklearn.ensemble.RandomForestClassifier accepts many arguments like this:
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)On the contrary, the constructor of transformers.BertModel is very simple:
class transformers.BertModel(config, add_pooling_layer=True)The constructor accepts the BertConfig class. It may be a difficult debate as to which is better, but personally, I think the latter is better since it’s easy to read the processing and modify the code, and we can implement some logic in the configuration class to make the main class simpler. Not limited to machine learning open source projects, I have the impression that relatively new libraries often adopt such a class.
Let’s specify the type when defining a constant as well.
WASABI_RECOMMEND: Dict[Fish: bool] = {
Fish.TUNA: True,
Fish.SALMON: True,
Fish.MACKEREL: False,
}
TODAYS_RECCOMEND: Fish = Fish.MACKERELAlso, in most production environments, you will want to set constants using environment variables to control their behavior. The config-env is a useful library when you want to create an object that configures such behavior.
import environ
@environ.config()
class SushiConfig:
max_amount: int = environ.var(name="MAX_AMOUNT", converter=int)
todays_recommend: Fish = environ.var(name="TODAYS_RECOMMEND", converter=Fish)
os.environ["MAX_AMOUNT"] = "10"
os.environ["TODAYS_RECOMMEND"] = "mackerel"
>>> environ.to_config(SushiConfig)
SushiConfig(max_amount=10, todays_recommend=<Fish.MACKEREL: 'mackerel'>)You can get objects from environment variables while casting types like this. (Note: at this time, even if __annotation__ and converter do not match, the code will pass the type checker)
Annotation to dependent libraries
Even if you use type hints in your project, not all dependent libraries have type annotations. However, even in such a case, if the return value is specified in a comment or the return value is clear from the code, it may be better to add a hint for the purpose of improving readability or getting completion by the IDE.
# In foobar.py
def fish_for_something():
return random.choice(list(Fish)) if random.random() < 0.5 else None
# In other project
from foobar import fish_for_something # Not annotated function
catch: Optional[Fish] = fish_for_something()Here, even if fish_for_something() is not annotated, the IDE will understand that None or Fish is stored in the variable catch from now on, and will warn about None and complete the Fish class. This also makes it easier for later maintainers to read. (Actually, if you use pycharm, it will understand this function returns Optional [Fish] even if there is no annotation.)
Summary
Python is a dynamically typed language and there are some difficulties derived from the language, so I personally think that it is not necessary to adopt Python unless there is a library dependency of machine learning or its preprocessing. However, adopting type hints helps you to write easy-to-read code comfortably in the IDE, and you can use static analysis tools to perform type checking like Java or C#. Once you get used to it, you’ll definitely not want to write Python without type checking. Why don’t you try writing type-strict Python with type hints?