
こんにちは。メルペイ 機械学習エンジニアの @rio です。
この記事は、Merpay & Mercoin Advent Calendar 2024 の記事です。
本記事では、メルペイの機械学習エンジニアチームで今年取り組んだ、MLOps の省力化および品質向上についてご紹介します。
目次
メルペイの機械学習システムの概要
メルペイでは、毎月の与信枠更新ロジックの一部に機械学習システムを採用しています。
そのため、機械学習エンジニアチームでは毎月リリース作業が発生します。
本記事では、リリース作業のうち、以下の作業に関して品質を担保しながら省力化を目指した取り組みをご紹介します。
- 開発ブランチのマージ
- 各種マスタデータの更新
- 機械学習パイプラインの実行
1. 開発ブランチのマージ
開発ブランチでのさまざまな変更内容を main ブランチに反映させます。
その中でも、毎月必ず発生するのが config ファイルの更新です。
config ファイルでは、機械学習モデルの学習や推論、後処理などで必要な設定をしています。
以下は config で指定している項目の例です。
- 学習、評価データの期間
- 推論対象月
- ハイパーパラメータ探索に関する設定
- モデルやデータセットなどのバージョン
- 各種 I/O のパス など
問題点
config ファイルの更新時に、設定漏れや設定の不備など人為的ミスが起きてしまうことが問題でした。複数の機械学習モデルがあることや、各モデルごとの設定項目が多いことが要因としてあげられます。
解決策
config ファイルの設定の不備を機械的に検知してユーザに通知する仕組みを導入しました。
ワークフローは以下のとおりです。
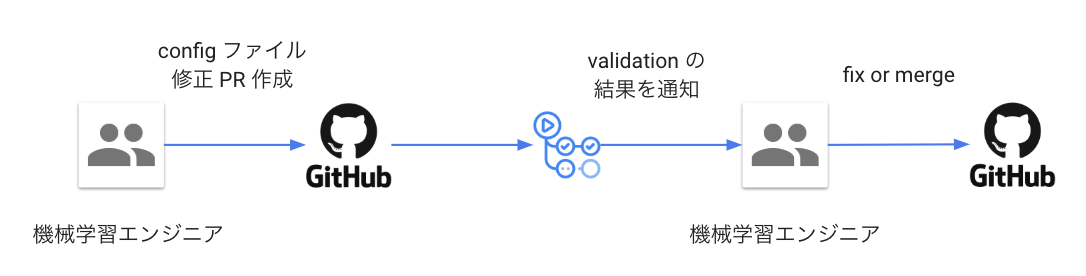
ロゴ出典: GitHub
config の修正を以下のケースで分類しています。
- モデルの推論のみを行うための修正
- モデルの再学習を行うための修正
- リリースに関係のない修正
3.については validatioin は実施しません。
1.2. に関しては、それぞれ一般的な型 validation に加えて、機械学習モデルの要件に紐づく以下のような validation を行っています。
- 作業月と推論対象月が矛盾していないか
- 先月リリース時の config と比較して矛盾がないか
- 作業月のNヶ月前の日付が指定されているか など
この仕組みの導入により、config ファイル更新時に不備があった場合、PR のマージ前に低コストで気づけるようになりました。
2. 各種マスタデータの更新
メルペイの機械学習システムには、さまざまなマスタデータが存在します。
マスタデータの更新は、基本的に PdM や Biz の方が行うため、運用観点で現状は Google スプレッドシートでの管理に落ち着いています。
問題点
システム上の管理は GitHub と BigQuery で行っているため、スプレッドシートのデータを テキストファイルに変換する作業が必要になります。この作業で人為的ミスが起きることと、作業が非効率であることが問題でした。
解決策
ワークフローは以下のとおりです。

ロゴ出典:GitHub, Google スプレッドシート
スプレッドシートの validation では、機械学習特有のものはありません。
データ型や入力値の範囲、ヘッダの数や名称など、一般的な項目をチェックしています。
複数のマスタデータや、その他のスプレッドシートで管理されているデータにおいて、品質担保および効率化できるよう、この仕組みを使いまわして運用しています。
3. 機械学習パイプラインの実行
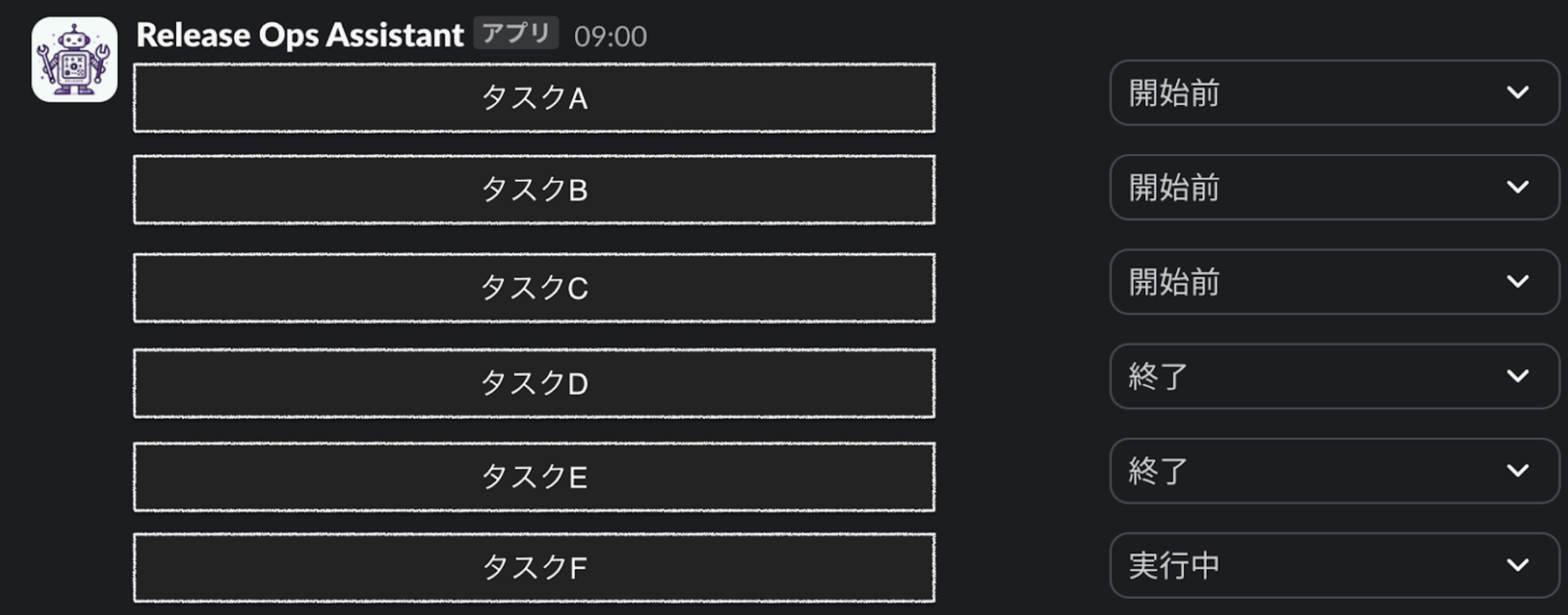
毎月のリリース作業には約50個のタスクがあります。
そのうちのいくつかは、AirFlow の DAG を用いて実装されている機械学習パイプラインを実行するタスクです。
問題点
以下の問題がありました。
- 実行日とタスクが一覧になっているスプレッドシートでタスクを管理しているが、いつどの DAG を実行するかを確認する認知コストがかかる
- リリースタスクの数が多いこともあり、ミスや手戻りが発生し得る
- リリース作業のオンボーディングが非効率で、新規メンバーのキャッチアップに時間がかかる
解決策
リリース作業をアシストしてくれる Slack bot、”Release Ops Assistant”(以降 ROA)を導入しました。ワークフローは以下のとおりです。
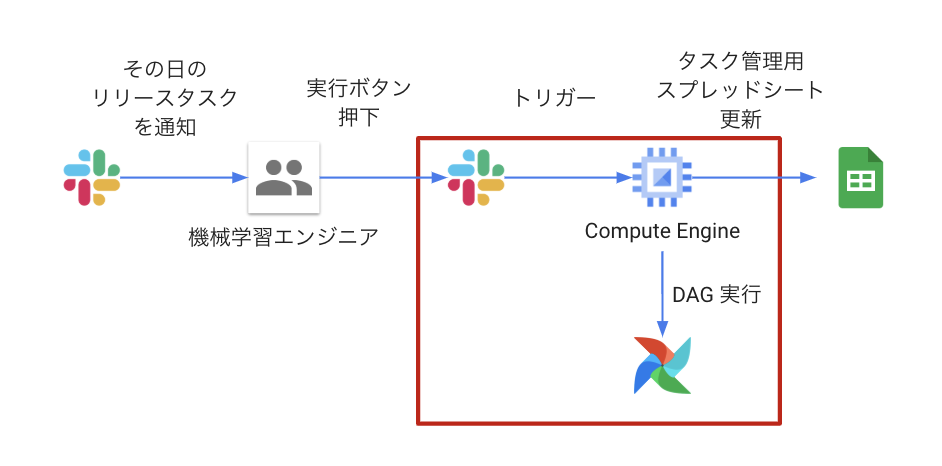
ロゴ出典:Slack, Google スプレッドシート, Google Compute Engine, Apache Airflow
ROA を実装する際に、下記の要件を満たしたいと考えていました。
- Slack からの DAGトリガー要求にリアルタイムで対応できること
- 実装及び運用コストが低いこと
検討したアーキテクチャには、Cloud Functions や Cloud Run などありましたが、最終的には Socket Mode が使えるという理由で Google Compute Engine(以降 GCE)を採用しました。Socket Mode は、WebSocket を使用してリアルタイムでイベントを受信できる接続方式で、ファイアウォールを気にせず簡単にアプリ開発ができるという特徴があるため、上記の要件を満たすことができます。
また、ジョブスケジューラーも Cloud Scheduler や Cloud Tasks などを検討しましたが、最終的には Slack との親和性が最も高いという理由で Slack ワークフローを採用しました。
図3 のワークフロー内赤枠の部分では、Slack Bolt が Socket Mode で GCE のプログラムをトリガーし、GCE が Airflow REST API を叩いて DAG を実行しています。
ROA の導入により、いつどのタスクをやるべきか Bot が通知してくれるので認知コストが下がり、リアルタイムにタスクの実行やステータスの変更が可能となったためミスや手戻りも発生しづらくなりました。
まとめ
本番稼働中の機械学習モデルの運用について、品質を担保しながら省力化することで、生産性をあげる工夫をご紹介しました。
生産性向上はどうしても後回しにしてしまいがちですが、一度腰を据えてまとめて見直しができて非常に良かったと思います。
次の記事は @komatsu さんです。引き続きお楽しみください。




