
Mercari Search Infra Teamのmrkm4ntrです。
Elasticsearchは1ノードに載り切らない量のデータも複数のshardに分割し、複数のノードに載せることで検索が可能になります。shard数を増やすことで並列にスキャンするドキュメントの数が増えるためlatencyが改善します。ではshard数はいくらでも増やせるのでしょうか?もちろんそのようなことはなく、Elastic社の公式ブログ(https://www.elastic.co/jp/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster )にもあるようにshard数を増やすことによるオーバーヘッドが存在します。ただしそのオーバーヘッドが具体的に何を指すのかは、先ほどの記事では明らかにされていません。本記事ではそのオーバーヘッドの正体を明らかにするとともに、実際にコストの削減を達成したことについて説明します。
背景
我々の運用するindexはmulti-tierと呼称する構成をとっています。multi-tier構成で直近x日分の商品が入っているindexを1st index、全ての商品が入っているindexを2nd indexと呼びます。新しいもの順で商品を取得する場合はまず1st indexにリクエストし、検索結果が不足していた場合は2nd indexにリクエストします。このような構成により2nd indexに来るリクエスト量を減らすことができます。同時に、2nd indexに来るクエリは1st indexでは十分な数の結果を得ることのできなかった珍しいtermを含むことが多いため、スキャンするposting list(termを含むドキュメントのidのリスト)は短くなることが期待できます。1st indexに比べて2nd indexの1クエリ当たりのコストは10倍程度かかるため、これによりコストの削減を実現しています。
2nd indexは24個のshardに分割されています。元々ファイルシステムキャッシュに載るようにshardサイズの2倍(最悪のmergeの場合を考えたらしい)が空きメモリ量よりも小さくなるようにshard数を決めたらしいですが、実際にmemoryのworking setなどを調査し、1ノードに2つのshard載せることができることが発覚しました。その結果全体24 shard、1ノードあたり2つのshardを載せる構成に変更しました。
2nd indexはmulti-tier構成でかなりコストを削減しているものも、今なお最大のリソースが必要なindexでした。そこでこのコストをさらに削減するために調査を行うことにしました。
CPU proflierでflame graphを取得し眺めていたところ、posting listをスキャンする処理(下図の赤枠)には検索処理において半分以下のCPUしか使われていないことがわかりました。

確かにスキャンすべきposting listが短くなるのでこのことはある程度予期していましたが、検索エンジンの処理のメインはposting listのスキャンのはずです。このスキャンを効率化するために様々な工夫がされています。例えばこの記事(https://engineering.mercari.com/blog/entry/20240424-6f298aa43b/ )もスキャン対象を効率的にスキップする話です。では他は何にCPUを使っているのでしょうか。残りの部分について調べると、ほとんどがスキャン対象のposting listをterm dictionaryから取得する処理(以下term lookupと呼ぶ)であることがわかりました。
term lookup
Luceneではposting listはfieldとtermの組み合わせごとに存在します。簡単のため今は一つのfieldについて考えます。termをキーとし、posting listの場所をvalueとするhashmapを用意すればposting listの位置の取得は一瞬で終わるのですが、termの数は非常に大きいためJVMのheapに収めるのは現実的ではありません。
そのためLuceneはFSTというデータ構造を使い省メモリ化を実現しています。FSTとはFinite State Transducerの略称で、有限オートマトンの受理状態に値がつくことで入力をその値に変換することができるというものです。FSTはfield毎に存在し、termを入力、postling listの場所を出力(実際はtermとposting listの対応ではなく、termのprefixとprefixを共有するtermのposting listのアドレスをまとめたブロックのアドレスらしい https://github.com/apache/lucene/issues/12513 )とすることでpostling listの取得を実現しています。
この計算量は入力文字列の長さのオーダーですが、データ自体はファイルに保存する形式でmmapされているため、毎回そこから計算するのはそれなりにCPUを使うようです。
term lookup回数の削減
term lookupにCPUを使っているのなら、term lookupの回数を減らせばコスト削減ができるはずです。今2nd indexは24 shardあるので一つのクエリのterm lookup回数は1 termあたり24回必要になります(実際は違うのですが詳細は後ほど)。2nd indexを12 shardに変更すればterm lookup回数は1クエリあたり12回となるため、その分CPU消費が少なくなるはずです。もちろんshardあたりのスキャンするposting listは長くなるためlatencyが悪化する可能性がありますが、先述のとおり2nd indexにはposting listのスキャンが長いクエリがくる可能性は低いため、latencyの悪化の可能性も低いと考えました。また、term数が増加しますがFSTによるlookupの計算量はterm数には比例しないので問題ないはずです。
パフォーマンスを検証するために、まずは開発環境で本番のデータを使って検証しました。Elasticsearchのshrink APIを使って24 shardのindexから12 shardのindexを作成することにします。shrink APIは書き込み禁止にしたindexのshardをコピーしてまとめることで、shard数が元のindexのshard数の約数となるindexを作成する仕組みです。
リアルタイムのデータ更新がなくても先ほどの想定からパフォーマンスは向上すると見込んでいましたが、実際には全く変化がありませんでした。実はそれは当然で、FSTはshard毎に存在するのではなくsegment毎に存在するため、term lookup回数はshard数に直接比例するのではなくsegment数に比例するからでした。shardは内部的には複数のLuceneのsegmentからなるのですが、shrink API実行直後はあくまでもsegmentのグルーピング単位を変更しただけです。そのため全体のsegment数は変わらないためパフォーマンスに変化が見られませんでした。

そこでリアルタイムの更新を一定期間実施したところ、新しいsegmentの追加、mergeが繰り返され1 shardあたりのsegment数は元よりやや大きいくらいの値で収束しました。segment数はLuceneのTiered Merge Policyやドキュメントのサイズ、追加速度などによって決まり、shardあたりのドキュメント数が倍になってもsegment数は単純に倍にはなりません。再度パフォーマンスを測ったところ無事にパフォーマンスの改善が確認できました。
以下が本番環境に適用した結果です。薄い線が一週間前のもので濃い線が適用後のノード数の遷移を表します。
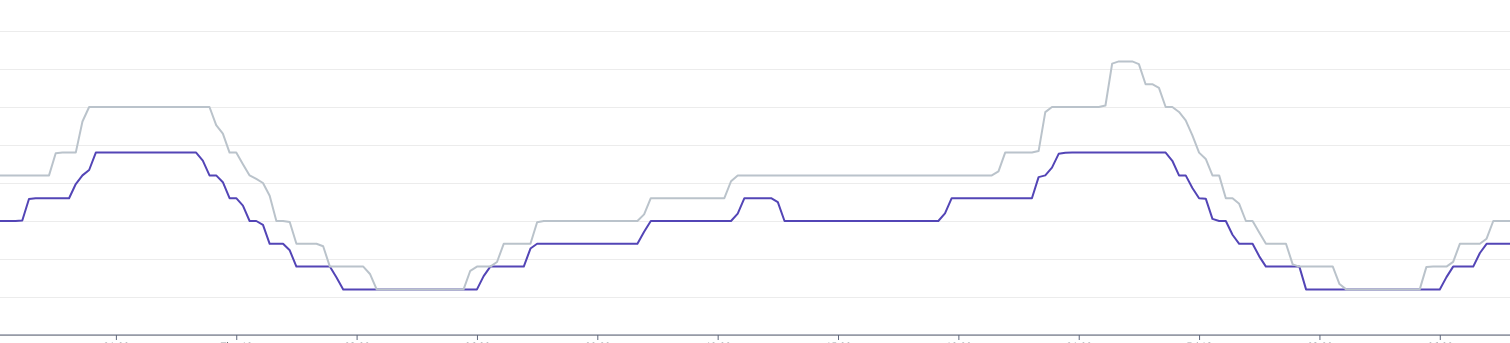
我々のクラスタはこの記事(https://engineering.mercari.com/blog/entry/20230620-f0782fd75f/ )にあるようにCPU使用量でオートスケールするようになっていますが、明らかに必要なノード数が減少したことが見てとれます。latencyに悪影響も見られませんでした。
こちらが適用後のflame graphです。別要因でクエリのパターンが適用前後で変化したため単純比較はできませんが、term lookupの占める割合が小さくなることでposting listのスキャンが占める割合が相対的に大きくなっています。

さらにsegement数を減らせばよりコストが削減できるはずです。segment数はLuceneのTiered Merge Policyのパラメータを変更することにより調整できます。よりsegment数を減らすためにindex.merge.policy.segments_per_tierを減らしましたが、segment数は思ったほど減少しなかったと同時に、mergeのためのCPU使用量が上がったのでこちらは期待ほど有効ではありませんでした。
まとめ
この記事では、shard数の増加によるオーバーヘッドの一つはsegment数が増えることによるterm lookupの回数が増加であることを示しました。同じノードに複数のshardをおいている場合はshardをまとめた方がCPU負荷が低くなります(もちろんlatencyが上がる場合がありますが)。我々のindexは基本的にリアルタイムのデータ更新がありますが、データ更新がないような静的なindexにおいては、force mergeでsegement数を1にしておくとterm lookup回数が最小となりパフォーマンスが改善することが期待できるでしょう。

