こんにちは。株式会社メルペイのSolutionsチームのデータエンジニアの@orfeonです。
この記事は、Merpay Advent Calendar 2023 の22日目の記事です。
Solutionsチームは、社内向けの技術コンサルや技術研修、部門を跨いだ共通の問題を発見して解決するソリューションの提供などを行っています。
私は主に社内のデータ周りの課題を解決するソリューションを提供しており、一部の成果はOSSとして公開しています。
過去の記事では全文検索OSSであるApache SolrをCloud Run上で利用して手軽に検索APIを構築する構成を紹介しました。
社内向けのソリューションの一つとして社内向けの検索APIを使ったサービスなど小規模な検索システムの構成に役立てています。
前回の記事の時点では、検索対象として搭載できるデータサイズなどにいくつかの制約がありました。
今回の記事では、構成をブラッシュアップすることで機能を追加したり、制約を一部克服できるようになりましたので、その実現方法と構成を紹介します。
はじめに
新しい構成を紹介するにあたって、まずは過去の記事で紹介したSolr検索サーバをCloud Runにデプロイする構成をおさらいします。
この構成を大雑把に説明すると、事前に作成した検索インデックスをSolrのコンテナイメージに直接同梱してそのままCloud Runにデプロイしてしまうというアイデアになります。
以下、定期的にデータソースからインデックスを生成して同梱したSolrコンテナをCloud Runにデプロイする構成図の例です。

大きく分けて、検索インデックスファイルを指定したデータソースから生成するバッチジョブと、Solrのコンテナイメージに完成した検索インデックスを追加したイメージを作成し、Cloud Runにデプロイする2つのステップから構成されます。
検索インデックスファイルの生成にはCloud Dataflowを、コンテナイメージの生成とCloud RunへのデプロイにはCloud Buildを利用しています。
Cloud DataflowとCloud BuildをCloud Schedulerから定期実行することで、指定したデータソースを元に検索インデックスをビルドし、Solr検索APIサーバとしてCloud Run上に自動的に反映される仕組みが構築できます。
Cloud Run上で動いているSolrサーバでの逐次的な検索インデックスの更新は行わない想定のため、同一で不変のインスタンスが負荷に応じてスケールするというとてもシンプルな構成になります。
一方で以下のような制約があります。
- 検索インデックスのサイズがコンテナイメージに載せられる量に制限される
- データの更新頻度はそれほど高くはできない(1日数回程度)
今回の記事ではこの構成をベースとして追加した新しい機能や、上に挙げた制約を回避するための構成として次の項目について紹介します。
- 複数コア検索対応
- ベクトル検索インデックス構築支援
- 分散検索対応
複数コア検索
最初に紹介するのは複数コア検索対応です。
Apache Solrでは検索対象となるデータセットをコアという単位で管理しています。
コアは検索データセットのインデックス、スキーマ、設定情報を管理しており、RDBにおけるテーブルのような位置付けになります。
検索時に複数のコアを利用することで異なるデータセットを横断した検索を手軽にできるようになります。
例えばECマーケットで自分がお気に入りに登録したショップの商品だけ検索したい場合を考えます。
お気に入りのショップの数が少ない場合は、Solr APIを呼び出すアプリケーション側でお客さまのお気に入りショップを取得して、検索時のフィルタ条件に追加することで実現することもできます。
しかし、フィルタ条件を動的に組み立てる仕組みをアプリケーション側が管理しないといけません(お気に入りショップをDBから取得しORのフィルタ条件を組み立てるなど)。またショップの数が多いとリクエストサイズの制限に引っかかる可能性も出てきます。
そこで商品検索用のコア(Items)とは別に、お客さまのお気に入りショップ情報を管理するコア(FavoriteStores)を用意しておきます。
商品検索用のコアとお気に入りショップのコアを検索時にショップIDで結合することで、検索結果をお気に入りショップのみを対象に絞り込んだ上で該当するショップの取り扱っている商品だけを検索することができます。
Solrでは検索時にコア間の関係を正規化するためのクエリパーサーとしてJoin Query Parserが提供されています。
以下はJoin Query Parserを利用した検索リクエストの例です。
https://{solr url}/solr/Items/select?q=GCP&fq={!join from=ShopID fromIndex=FavoriteStores to=ShopID}UserID:0123456789上記の検索リクエストは以下のようなSQLクエリと同等のものになります。
SELECT *
FROM Items
WHERE ShopID IN (
SELECT ShopID
FROM FavoriteStores
WHERE UserID = "0123456789"
)過去に紹介した記事では単一のCloud Dataflowパイプラインでは単一のコアのインデックスのみ生成することができました。
そこでSolrのインデックスを生成するMercari Dataflow Templateのlocalsolr sinkモジュールを機能拡張して、複数のコアを一度に作成できるように対応しました。
これにより異なるデータセットを横断検索できるSolrサーバを手軽に構築できるようになりました。
以下はMercari Dataflow Templateで2つのBigQueryデータソースからそれぞれ対応する2つのコアの検索インデックスファイルを生成するsinkモジュールの設定の例になります。
コアごとに入力とスキーマ等の設定ファイルを指定します。
"sinks": [
{
"name": "LocalSolr",
"module": "localSolr",
"inputs": ["BigQueryItems", "BigQueryFavoriteStores"],
"parameters": {
"output": "gs://${bucket}/output/index.zip",
"cores": [
{
"name": "Items",
"input": "BigQueryItems",
"schema": "gs://${xxx}/Items/schema.xml"
},
{
"name": "FavoriteStores",
"input": "BigQueryFavoriteStores",
"schema": "gs://${xxx}/FavoriteStores/schema.xml"
}
]
}
}Mercari Dataflow Templateのlocalsolr sinkモジュールは生成したSolrのインデックスファイルをzipファイルとしてoutputで指定されたCloud Storageのパスに保存します。
複数のコアをコンテナイメージに同梱するDockerfileは以下のようになります。
インデックスファイルはコアごとにディレクトリが分かれています。
zipを解凍してコアごとのインデックスのディレクトリをSolrのデータディレクトリにそれぞれコピーします。
FROM solr:9.4.0
USER solr
COPY --chown=solr:solr Items/ /var/solr/data/Items/
COPY --chown=solr:solr FavoriteStores/ /var/solr/data/FavoriteStores/
ENV SOLR_PORT=80ベクトル検索インデックス構築支援
次に紹介するのはベクトル検索インデックスの構築支援についてです。
Solr 9.0からベクトル検索がサポートされました。
ベクトル検索により検索キーワードが含まれているコンテンツだけでなく、検索キーワードに意味的に似ているコンテンツを検索することができるようになります。
しかし、コンテンツの内容を表すベクトルは検索インデックス構築時に自分で用意する必要があります。
テキストや画像などのコンテンツからベクトルを生成するには、自前のembeddingモデルを用意して推論したり、embedding用のAPIを利用するなどいくつか方法があります。
しかし検索インデックス構築パイプラインに案件ごとでこうしたコンテンツのベクトル化の処理を挟み込むのは少し面倒です。
そこで検索インデックスを生成するCloud Dataflowで、あらかじめデータをベクトル化するために作成したONNXモデルを使って、入力データをベクトル化するためのonnx transformモジュールを開発しました。
これにより、データ取得からベクトル化、検索インデックス構築を一筆書きのパイプラインで実現できるようになりました。
以下、Mercari Dataflow Templateで入力データの指定したフィールドをベクトル化するonnx transformモジュールの設定の例になります。
あらかじめ作成してGCSに保存しておいたONNXファイルをモデルとして指定して、入力データのフィールドやベクトル化出力とONNXモデルの入出力のマッピングを指定しています。
"transforms": [
{
"name": "OnnxInference",
"module": "onnx",
"inputs": [
"BigQueryContentInput"
],
"parameters": {
"model": {
"path": "gs://example-bucket/multilingual_v3.onnx",
"outputSchemaFields": [
{ "name": "outputs", "type": "float", "mode": "repeated" }
]
},
"inferences": [
{
"input": "BigQueryContentInput",
"mappings": [
{
"inputs": {
"inputs": "Content"
},
"outputs": {
"outputs": "EmbeddingContent"
}
}
]
}
]
}
}
]検証では、TensorFlow Hubで公開されている universal-sentence-encoder-multilingual/v3 モデルをONNX化して、Solr検索インデックス構築時のテキストデータのベクトル化に利用しました。
2,000 程度の日本語のPDFファイル(250MB)のベクトル化を6vCPU程度のリソースコストで完了することができました。
現状ではONNX推論はCPU環境のみ対応ですが、今後はGPU環境対応なども検討していきたいと思っています。
※ちなみにこの機能を追加した後に、BigQueryの機能追加によりSQLでテキストデータから手軽にベクトルを生成できるようになりました。
BigQueryではGoogleが構築済みのembeddingモデルをすぐに利用することができます。
手軽にベクトル検索を試してみたい方はまずこちらの機能を利用してみると良さそうです。
分散検索
最後に紹介するのは分散検索対応です。
過去の記事ではSolrのスタンドアロンモードでの起動を前提としていました。
スタンドアロンモードの通常の検索だと、検索インデックスは単一の検索ノード上に閉じるため、検索インデックスのサイズにはCloud Runインスタンスに載せられるだけという上限があります。
しかしSolrではスタンドアロンモードでも複数ノードにまたがった分散検索に対応しています。
そこでCloud RunでもSolr分散検索に対応した構成にすることで、単一のCloud Runインスタンスに載らない大規模なデータセットも検索できるようにしました。
Solrの分散検索
まず前提となるSolrのスタンドアロンモードでの分散検索機能を紹介します。
Solrでは1つの巨大なインデックスをシャードと呼ばれる小さなインデックスに分割して、複数のノードに分散配置することができます。
分散検索では、これらの複数のノードに分散配置されたシャードに対して一括検索することができます。
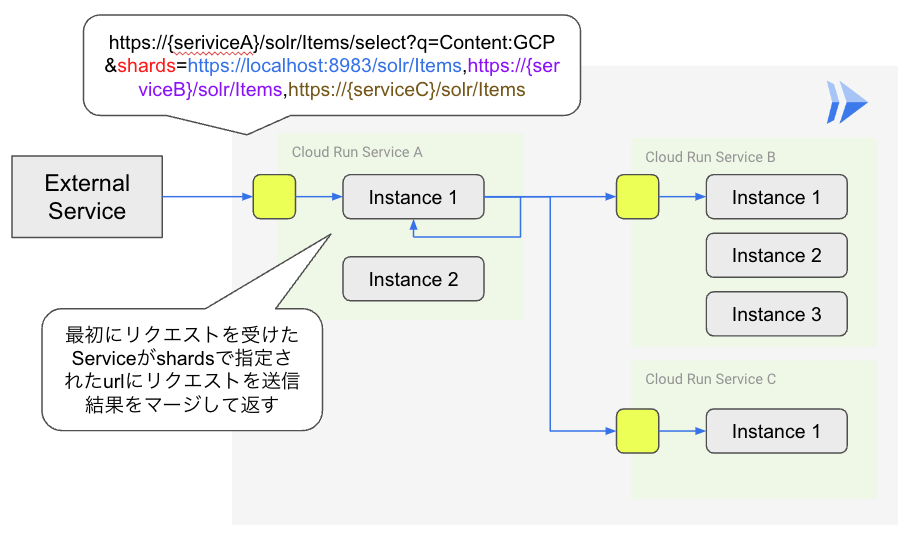
分散検索の実行には特別な設定は必要なく、検索対象としたいシャードを持つノードのエンドポイントを検索リクエストのshardsパラメータで指定することで実現します(複数ノード指定も可)。
分散検索では最初に検索リクエストを受け付けたノードが、shardsパラメータで指定されたノードに対して同じ検索リクエストを発行して検索結果を受け取り、マージして最終的な検索結果として返す仕組みになっています。
以下、3つのエンドポイントへの分散検索リクエストの例です。
https://{solrShardA}/solr/Items/select?q=GCP&shards=https://localhost:8983/solr/Items,https://{solrShardB}/solr/Items,https://{solrShardC}/solr/ItemsCloud Runへの分散検索の適用
Solrの分散検索の仕組みをCloud Run上で実現する構成を考えます。
先に紹介した通り、Solrの分散検索ではシャードごとに異なるエンドポイントを持つ必要があります。
Cloud Runでは役割に応じてサービスという単位でエンドポイントを分けることができます。
そこでシャードごとにサービスを分割して、リクエスト時にこれらのシャードに対応するサービスのエンドポイントをshardsパラメータで指定することで分散検索を実現しました。
Cloud Runではサービスごとにノード数をスケールさせることができます。
そのためデータセットが不均衡で一部検索処理が重いシャードがあっても、そのサービスのノードだけ自動でスケールさせることができます。
Solr分散検索をCloud Run上で運用するに当たって、検索インデックスの生成ステップでは追加の開発は特に必要ありません。
Cloud Runのサービスをシャードごとにデプロイするようにするだけです。
そのためにCloud Dataflowによるインデックスの生成をシャードごとに生成するように変更します。
Cloud BuildによるCloud Runへのデプロイもシャードごとにサービスを分けてデプロイするようにします。
Solrの分散検索の注意点ですが、検索結果のX件目から10件取得するといったオフセットを指定して取得する場合、オフセットに比例して消費メモリや処理が重くなることが挙げられます。
これは複数ノードから取得した検索結果を一箇所に集めてソートするために起こります。
分散検索はなるべくこうした問題が顕在化しない、トップX件のみ利用するようなケースに適用するのが望ましいでしょう。
別の注意点としては、検索リクエストを送る側や各サービスはシャードごとのエンドポイントを把握しておく必要があることが挙げられます。
データセットを分割するシャードが変わらない場合は問題にならないのですが、頻繁にシャードが追加されたり変更されるような場合は、シャードと紐づくエンドポイントの情報をサービスやアプリケーション間で共有するための工夫が必要になります。
おわりに
今回の記事では、Cloud Run上で手軽に検索APIを構築するための構成について、前回の記事から新しく追加した機能や構成を紹介しました。
過去の他の記事でもCloud RunでNeo4jを動かす構成を紹介しました。
Cloud Runはフルマネージドなサービスであり、比較的小規模なデータを扱うAPI手軽に構築するにはとても便利なサービスだと思っています。
今後もCloud Runなどを通じて様々なデータを手軽に扱う仕組みを検証して、社内のデータ活用に役立てていきたいと思います。
今回紹介したSolrの検索インデックスの生成に用いたMercari Dataflow Template はOSSとして公開しており、技術書典の全文検索にも活用されています。
もしCloud RunでSolrを使った検索APIを手軽に構築してみたい方はぜひお試しもらえればと思います。
また今回の記事に向けて、データの更新頻度をニアリアルタイムに近づけるための仕組みも検証中だったのですが、残念ながら間に合いませんでした。
次回の記事でニアリアルタイム検索の仕組みについても紹介できればと思います。
明日の記事は @iwata さんによるGitHub Actionsを使った自動化です。引き続きお楽しみください。




