
Merpay & Mercoin Tech Fest 2023 は、事業との関わりから技術への興味を深め、プロダクトやサービスを支えるエンジニアリングを知ることができるお祭りで、2023年8月22日(火)からの3日間、開催しました。セッションでは、事業を支える組織・技術・課題などへの試行錯誤やアプローチを紹介していきました。
この記事は、「メルペイMLにおける品質保証とリスク管理」の書き起こしです。
@shuuk:みなさんこんにちは。それでは「メルペイMLにおける品質保証とリスク管理」の発表を始めます。よろしくお願いいたします。

それではまず、私たちの自己紹介をします。まず私は、Shu Kojimaといいまして、Slacknameは@shuukとなっております。元々は受託開発でWebエンジニアをしておりましてその後、株式会社ALBERTというところで、データサイエンティストを経て、データアナリストとしてメルペイに入社しました。
その後は、MLエンジニアにジョブチェンジをして、現在は不正検知のMLを扱うFraud Prevention Teamでマネージャーをしています。本日はよろしくお願いいたします。
@yukis:Yuki Saitoと申します。メルペイでシステムリスクセキュリティのDivisionのディレクターを務めております。私自身はもともと新卒で大手の精密機器メーカーでネットワークエンジニアとして働いていました。
あまりにも金融事業をやりたくて、金融ベンチャーに飛び込んでそこからは金融事業をやっていく上でのIT周りだとかリスク管理を責任者としてやっていました。システムコンサルも挟んで現職に至ります。よろしくお願いします。
@haruki:Haruki Kanekoと申します。メルペイではリスク管理チームのマネージャーをやっております。キャリアとしては信用リスク管理一筋で、最初の頃は銀行系のカードローン会社、それからベトナムのハノイに駐在して、ノンバンクでリスク管理をやっていたり、直近ですとドイツ車メーカーの個人向けローンに関するスコアリングモデルの開発や与信戦略の立案、規制対応を経て、2021年からメルペイのリスクチームにジョインしています。本日はよろしくお願いいたします。

@shuuk:それでは早速始めていきます。まず、概要を説明させてください。私たちメルペイでは、与信と不正検知の領域でMLを活用しております。Fintechでは求めるリスク管理の基準も非常に高いので、品質を担保するためにルールやフローの整備を今まで進めてきました。
中でも現場のスピード感と品質を両立するなど、いろいろと悩みがあったので、そこにどう折り合いをつけたのかを今日はお話できればいいかなと思っております。

ではまず、最初冒頭数分程度で前提となる知識をご紹介して、その後パネルディスカッション形式でお話しします。まずは弊社のMLシステムの紹介を簡単にします。
一つ目が、与信のMLのシステムで、こちらは過去のお客さまの取引の情報から将来の貸し倒れの確立を予測して、メルカードなどの後払い系のサービスの利用限度額を決定することをミッションにしたものになっています。

そしてもう一つの柱が不正検知です。こちらは不正な動きをしている人とかトランザクションを検知することに機械学習を用いております。

ではここからメルペイにおけるリスク管理の全体像に関して@harukiさんから説明をお願いいたします。
@haruki:まず、メルペイにおけるリスク管理の全体像について説明します。お客さまのお金を取り扱うFintechでは、プロダクトにも当然高い品質が求められます。またインシデントや障害を起こしてしまうと、監督官庁、具体的には経済産業省や、金融庁への説明責任も発生してしまうという背景がございます。
特に当社メルペイの強みの一つでもあるのですが、メルペイは認定包括信用購入あっせん業の認定を日本で初めて獲得、これによって、MLモデルによって、分割払いやクレジットカードにおけるお客さまの利用限度額を算出することができております。
その分このMLシステムが想定外の挙動を起こさないように、きちんとリスク管理を行う必要性があります。
参考記事:メルペイ、事業者として第1号となる「認定包括信用購入あっせん業者」の認定を取得

金融機関における一般的なガバナンスの体制についてご説明したいと思います。こちらをThree Lines Modelと呼んでいます。
一番左側のプロダクトマネージャーやエンジニアなど、お客さまに対して製品やサービスを提供する部署を第1線とし、真ん中のリスク管理の立場から客観的に第1線を支援する部署を第2線としています。社内の最後の砦として、内部監査室を第3線としています。社内の役割を分けることで、ガバナンス体制を強化するという目的があります。
真ん中の第2線ですと、リスク、リーガル、コンプライアンスなどのチームがあり、私のリスク管理の立場からでは、信用リスク管理上の観点からMLチームのエンジニアの検証結果に関してダブルチェックを行ったり、第2線の立場から異なる視点で検証してみたりと、第1線部署と綿密にコミュニケーションしつつ多角的に評価して、安心安全なプロダクトを世の中に送り出すというのがミッションになります。
第2線はリスクを軽減するために、そのルールや社内規定、マニュアル、ポリシーといったドキュメント類を第1線と共同で作っていくというのが重要なミッションでございます。
本日お話したいのが、メルペイのML領域において、このルールがあまり明確には存在していなかったので、これを作りました。

@shuuk:私の方からMLにおけるリスクが2種類あるというお話をさせていただきます。
MLには「システムリスク」と「モデルリスク」という大きく二つのリスク管理の考え方が並列して存在しております。システムリスクとは、システムの想定外の挙動によるリスクで、例えばアプリが停止したり第三者にのっとられたりといったものを想定しています。
モデルリスクはモデルの想定外の挙動によるリスクで、貸倒率や不正な取引の確率の予測精度が下がって結果的に事業損失が出ることを想定してます。
想定しているロジックも違っていて、システムリスクは基本ルールベースを想定していますが、モデルリスクはブラックボックスアルゴリズム(AI)を想定しています。
リスクを低減する具体的な方法も違っていて、システムリスクの場合は開発チームから独立したQAチームが、QAを実施することが基本的な方法の一つになります。モデルリスクの方は、どちらかというとビジネス指標の確認やML精度指標の確認、リリース前後のバックテストモニタリングなどを手法としております。

ここからディスカッションパートに入ります。
@haruki:メルペイでどういったモデルを使っているかや、ガバナンスの体制、システムリスク・モデルリスクについてご説明させていただきましたが、私からシステムリスクについていろいろお伺いしたいです。ですけれども、このMLのシステムリスクを考える上で、QAをどうするかが問題としては大きかったと思います。当時はどういった議論があったのでしょうか?
@yukis:QAに限らずシステムリスクの規定というと堅いのですが、ポリシーを考える上でI TGCと言われるIT全般統制の中で、特にQAの領域は、開発者とは独立した組織によってクオリティアシュアランスをするという組織上の権限分離が行われたもので、統制・ルール整備をするのが正攻法です。メルペイももちろんそういうポリシーとして定めています。
一方でそれは、開発者と違ったナレッジを持っている組織であったとしても、ルールベースのロジックをベースにして、クオリティアシュアランスが可能であることを前提としたルール・統制となっています。
ここはMLの領域にまるっと適用するのはあまり現実的ではないということが、課題としては大きかったです。
@shuuk:MLはルールベースみたいにテストケースを作成するのは難しくて、一応不確実性のあるものをQAする方法もいろいろ提案されてはいるものの、まだまだ発展途上の段階だと思います。しかもそれをQAチームに第三者としてやってもらうのは、現実的ではないとは思っていました。
@haruki:そういった難しさがある中で、社内で合意形成していくのは大変だと思うのですが、当時はどのようにして合意形成したのですか。
@shuuk:最初は無邪気に「モデル部分のQAが難しいので除外できませんか」と経営陣にも提案をしていましたね。ただ、「品質保証を何もやらなくていいんですか」という話は当然ありまして、回答に悩みました。
@yukis:僕も同じで、モデルの部分の正しさや、間違い・不正が介在した場合というときの事業インパクトを考えると、誰も「品質保証をしなくていい」とは経営陣は言わないということは、おっしゃる通りだと思います。
でも、それを汎用的なルールとしてあてがうより、例外的にどのようなポリシーで進めるのが良いかを考えました。
そもそも独立したQA組織による品質保証をなぜ正攻法でやりがちなのかというと、原点に立ち返ったときに、基本的には開発者自らが品質保証をやってもいいのですが、組織として見たときに、開発者自らが品質保証を怠ってしまったり、脆弱性や不正なソースコードを埋め込んでしまうリスクがあります。第三者的にそのリスクがないことを説明しなければならないとき、開発者とは独立した部隊(QA)がアシュアランスをしているのは効率的なんです。
必ずしも第三者がやる必要がない一方で、第三者による品質保証が困難となった場合、それでも第三者がやらなきゃいけないとなると、それ自体がそもそも品質保証低下につながってしまう可能性があるので、そういったポリシーはむしろ不適当です。
代替的なガバナンスは、今のメルペイのプロダクトの性質や組織の性質を考えたときにどうすべきかを柔軟に検討する必要性があったと思います。そこをMLチーム・ITリスクチームと試行錯誤してきました。
@shuuk:代替的なガバナンスという考え方はすごい鍵だったと思います。当時はまだモデルリスクという考え方を社内でそこまで持ってなくて、システムリスクだけが先にありましたが、システムリスクで保証しきれないときに、モデルリスクという新しい品質保証の柱を立ち上げて、ブラックボックス的なものはモデルリスクで見ましょうという線引きがなされました。
具体的には、バグを全部片っ端からQAするより、結果として出てくる事業KPI影響のバックテストやモニタリングを事業リスクをみている第2線の方と一緒に指差し確認することをルール化することで、変なモデルが世の中に出ないことを、担保できるという結論になりました。
@yukis:マクロ的にそう見たときにも違和感はなくて、世の中的にもグローバルな標準規格では代替的なコントロールをどう定義するかは世の中のポリシー的にも結構出てきています。
QAって大量のシステム分岐をあらゆる観点をチェックして問題がないかを確認すること自体が目的ではなく、クリティカルなバグを見つけ出すことができていれば良いと思っています。事業サイドとの合意形成によってクリティカルなバグを見つけて修正するプロセス自体は、良いアプローチの一つだったんじゃないかなと個人的には思っております。
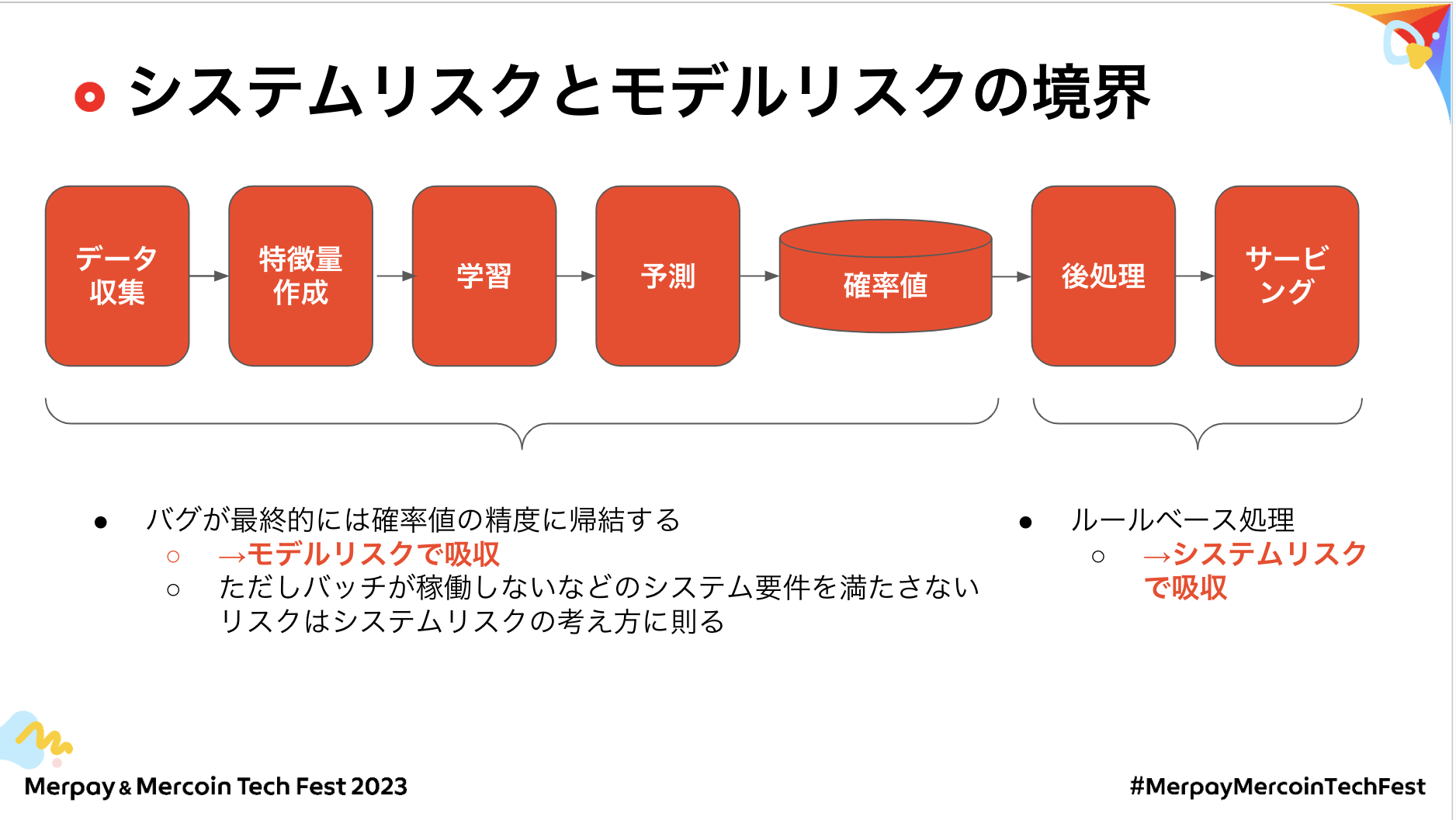
@haruki:従来の品質保証の定義ややり方では対応できず、モデルリスク・システムリスクと切り分けて対応しました。いろいろあったと思うのですが、他にはどんな課題がありましたか。
@shuuk:もうひとつの論点として、ブラックボックスは杓子定規にQAをしないと決まったとして、ルールベースの処理を全部QAするのかという話はありました。
MLシステムといってもブラックボックスのアルゴリズムって実はほんの一部で、ルールベースの処理の方がむしろたくさんあります。それを全部QAチームに依頼するのかと考えたときに、開発スピードは正直当然落ちてしまいます。
また、コストと効果が見合うのかも考えなければなりませんでした。例えば特徴量重要度が最下位の特徴量の品質保証を第三者がめちゃくちゃ頑張ったとして、大幅にリスクが減るのかという話があがりました。
@haruki:そうですよね。MLモデルだと多量の特徴量を使って、判別力や頑健性を上げていこうというものですので、網羅的に一つ一つやっていたらきりがなくなってしまいますよね。その辺りはどのように折り合いをつけたのでしょうか?
@shuuk:モデルリスクとシステムリスクの境界を工程別に分けました。スライドの通り、私たちの利用している教師あり学習は基本的には何らかの確率値を出しています。確率値の後処理を誤ると、例えば利用限度額を誤ってしまうなどの直接的にプロダクトに影響があります。そのため、ここはQAをしようという話になりました。
一方、前処理や特徴量がバグっていたとして、最終的には確率値の精度に吸収されます。よってここはモデルリスクで吸収をして、事業KPIの影響を見た上で品質を保証する形になりました。
ただそもそも、バッチが動いてないとか、システムとして何も動いてないという話は普通にシステムリスクでやるという線引きをして、QAの負担を最小限にしつつ品質保証する形にしました。
@yukis:かなりいろいろ考えさせられたトピックでした。モデルリスクとシステムリスクそれぞれ定義にまで立ち戻って考えました。
システムリスクは予期せぬコンピューターダウンや不正によってコンピュータが誤作動してしまうことをいいます。一方でモデルリスクはシステムリスクとは違うような特性を持っています。
この場合、それぞれのリスクを担保するための保証が何かというと、システムリスクは同じテストケースと同じアプローチで品質保証すると、何度やっても同じ結果になりますが、一方でモデルリスクにおける品質保証はアノマリーを検知してそこから改善してビジネスとして適切なモデルとしていくことだと個人的に感じています。
「一定の理論・法則に基づいて合理的に説明できないけど何かおかしい結果である」という状態を改善するのが、モデルリスク上の品質保証だと思います。一般的な他のドメインでしているようなQAという考え方に当てはめるのは違うと個人的には思っています。
セキュリティの振る舞い検知的な話にも近いと思います、特定の挙動的にはOKだけど、特定の挙動がある時間帯で連続したり、特定の挙動の後にこの挙動が起こると明らかにおかしくなるといったことと似ていると思います。

@yukis:続いて、メルペイでのモデルのリスク管理をきちんと定めるようになったきっかけについて聞かせてください。
@haruki:まず、メルペイが置かれてる状況として、業界として歴史あるクレジットカードた分割払いといった社会的な重要性が高く、割賦販売法という厳格な法律に基づいて、与信管理が求められているというのがあります。
一方で、我々のAI与信ライセンスを、国内で唯一経産省から認められてまして、MLのモデルでお客さまの利用限度額を独自にモデルで算出できる点で、非常に柔軟性高い一方で、品質には配慮しなきゃいけないという背景があります。
@shuuk:MLの出力によって自由に決められることは、責任が増えるということでもあります。MLエンジニアとしても、基準を満たしていく必要があるので、変な精度のモデルをデプロイしてお客さまを混乱させないように、緊張感のある開発を行っています。

@yukis:高い要求水準の中で実際には当初からその要求水準を満たせていたんですよね。
@haruki:数年前はいろいろと難しい局面もありました。例えば与信戦略の変更で、当時は意思決定が属人的で、一部のお客さまの与信を上げた際に、スコアの想定値を上回る延滞率なってしまって、これで追加調査を求められたり、与信戦略を戻さないといけないといったことがありました。
常にバッファを設けて貸倒率・延滞率はコントロールしていますが、モデルの挙動が想定外になると財務的な損失が一気に出てしまうので、非常にセンシティブだと思います。
@shuuk:当時もビジネスサイドと会話しながら要求品質と決めてたのですが、ポリシーとして明文化されてないので意思決定が属人的になっていたことは、当時振り返ると否めないです。
また、見る指標もいわゆるAUCといったMLエンジニアが見るような人が中心だったので、それが具体的にビジネスにどれぐらい影響があるのかがわかりづらいということもありました。
@yukis:その後、より品質高く与信を運用していくためにどういうフローを構築していったのかを聞きたいです。
@haruki:モデルの整理やトリガーになるイベント、開発の工数、モニタリング項目、有識者が会議体で決議できるように可視化することが必要でした。
お客さまの与信という社会の生活を密接に関わるものを取り扱っておますので、MLモデル実装後、AUCだけでなく、ビジネス上のKPI、例えば、想定延滞率と実績延滞率の乖離をきちんと見るように意識したというのが大きいです。
なお、整備したルールは、作って終わりではなく、MLチームと一緒にどうしたらこれを浸透させられるかを考えたり、チェックリストを作ってガバナンスを浸透させていくことは、今も継続議論しています。引き続き安心安全なプロダクトをリリースするために、一緒に頑張っていきたいなと思っています。
参考記事:与信モデル更新マニュアルを作成した話

それでは、ご視聴ありがとうございました。




