
我々のチームでは検索基盤としてElasticsearchクラスタをKubernetes上で多数運用しています。これらのElasticsearchクラスタを管理しているnamespaceはマルチテナントな我々のKubernetesクラスタの中で最大のリソースを要求しているnamespaceです。
一方でクラスタのサイズをピークタイムに合わせて固定していたため、そのリソース利用率は非常に低いという問題がありました。Elasticsearch EnterpriseやElastic Cloudにはオートスケーリング機能が存在するのですが、これはスケールイン/アウトのためのものではなく、ディスクサイズに関するスケールアップ/ダウンを提供するもので我々の要求を満たすものではありませんでした。
そこで今回は、HPAを用いたスケールイン/アウトのためのオートスケーリングの仕組みを開発しました。これによってリソース利用率を向上させ、約40%のコスト削減を達成できたので、その詳細について説明します。
ElasticsearchとECK
メルカリではElasticsearchをECK(https://github.com/elastic/cloud-on-k8s) を用いてKubernetes上で管理しています。ECKはElasticsearchというCustom Resourceとそのcontrollerであり、以下のようなリソースを作成すると対応したStatefuleSetやService、ConfigMapおよびSecretなどのリソースが自動で作成されます。
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: example
spec:
version: 8.8.1
nodeSets:
- name: coordinating
count: 2
- name: master
count: 3
- name: data
count: 6この定義からcoordinating、master、dataの3つのStatefulSetが作成されます。
Horizontal Pod Autoscaler(HPA)を使ってこれらのStatefulSetをオートスケーリングさせたいのですが、以下のような課題があります。
- Elasticsearchリソース自体をHPAの対象とはできない。なぜならscale subresource(後述)が定義されていないため、複数あるnodeSetのどれを増減させれば良いのかわからない。
- Elasticsearchをスケーリングする際はPod数の増減だけではなく、そのPodに配置されるElasticsearchのindexもレプリカ数を変更して増減させなければならない。つまりスケーリングの単位は (indexのshard数 / Podあたりのshard数)となる。下図の場合は (3 / 1) = 3。
 一方HPAはminReplicasからmaxReplicasまでの間の任意の値を指定する可能性がある。この場合、Elasticsearchのauto_expand_replicasオプションはPodあたりのshard数 = indexのshard数となり、1Podあたり3つのshardが乗ってしまうので我々のユースケースには合わないため、自分でレプリカ数を変更する必要がある。
一方HPAはminReplicasからmaxReplicasまでの間の任意の値を指定する可能性がある。この場合、Elasticsearchのauto_expand_replicasオプションはPodあたりのshard数 = indexのshard数となり、1Podあたり3つのshardが乗ってしまうので我々のユースケースには合わないため、自分でレプリカ数を変更する必要がある。 - Elasticsearchリソースの管理下のStatefulSetを直接HPAの対象とした場合、2の問題に加え、親リソースであるElasticsearchを更新した場合にHPAによって調整されていたPod数が親リソースの値にリセットされてしまう。
これらの問題を解決するために新しくKubernetesのCustom Resourceとcontrollerを作成しました。
Custom Resourceとcontroller
以下が新たに導入したCustom Resourceの例です。
apiVersion: search.mercari.in/v1alpha1
kind: ScalableElasticsearchNodeSet
metadata:
name: example
spec:
clusterName: example
count: 6
index:
name: index1
shardsPerNode: 1
nodeSetName: dataこれは先ほどのElasticsearchリソースのdataという名前のnodeSetに対応します。このリソースは直接Elasticsearchリソースとの親子関係はなく、scale subresourceを提供しており、 kubectl scaleコマンドやHPAの対象とすることができます。Custom Resourceの定義はkubebuilderを用いて生成しているのですが、以下のようなコメントを追加することでscale subresourceを提供できるようになります。
//+kubebuilder:subresource:scale:specpath=.spec.count,statuspath=.status.count,selectorpath=.status.selectorこれは上記のScalableElasticsearchNodeSetの.spec.countがHPAやkubectl scaleコマンドの操作対象であることを示し、.status.countに現在のcount数が記録されることを意味します。さらに.status.selectorにこのリソースの管理対象、すなわち対象のStatefulSetの管理対象を選択するためのselectorが記録されます。これらは勿論自動で記録されるわけではなく、そうなるように自分でcontrollerを実装しなければなりません。
また、このCustom Resourceのspec内のcount、shardsPerNodeおよび対象となるindexのshard数から実際のStatefulSetのレプリカ数を以下のように算出します。
ceil(ceil(count * shardsPerNode / shard数) * shard数 / shardsPerNode)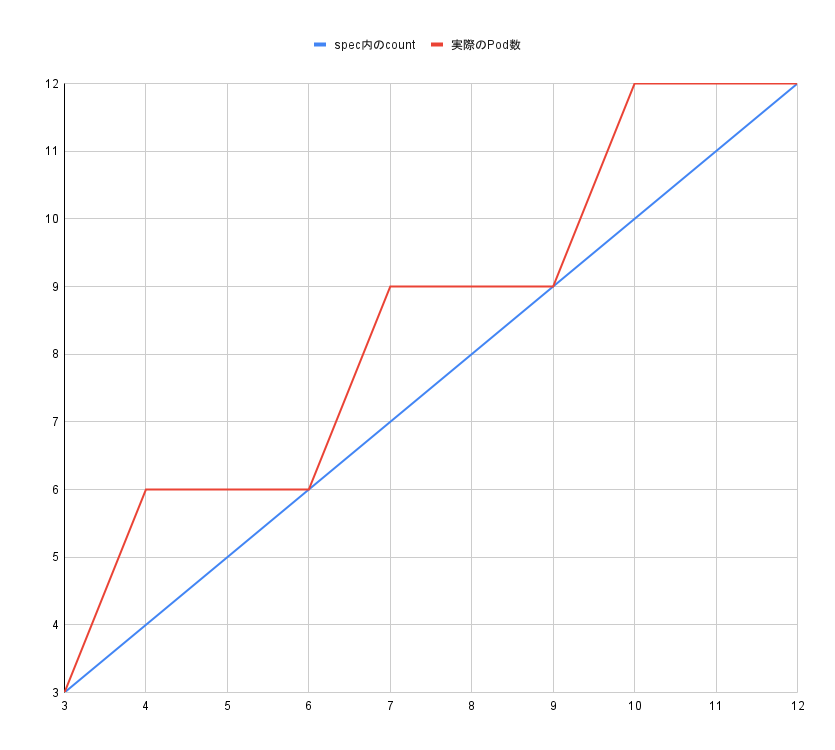
Scale subresourceの.spec.countと実際のcountが一致していなくても(少なくともtype: Resourceの場合)HPAの挙動に問題がないことは、HPAのソースコードを読んで確認済みです。HPAで設定すべきレプリカ数を計算する際に用いられる現在のレプリカ数は.status.selectorで選択されたPodの数となります。
スケールアウト時にはまずElasticsearchリソースの該当のnodeSetのcountを上記の計算式から算出された値に設定し、すべてのPodがReadyになった後、ElasticsearchのAPIを用いてindexのレプリカ数を増やします。スケールインする場合は逆にindexのレプリカ数を減らした後にElasticsearchリソースのcountを変更します。
これで先ほど挙げた課題の1と2については解決できました。3に関してはMutatingWebhookConfigurationを用いて解決します。これはElasticsearchリソースが更新された際に呼び出されるhookを指定する仕組みで、そのhookの中で search.mercari.in/ignore-count-change”: “data,coordinatingのようなannotationが指定されていた場合、そのannotationに対応するnodeSetのcount数を現在のcount数に上書きします。これによりHPAの対象となっている状態でElasticsearchリソースの変更をGitOps等で行っても、countがリセットされることがなくなります。
導入に際しての問題と解決
以上の方針で実装したcontrollerを実際に導入してみたところ、いくつかの課題がわかったのでそれらについて紹介します。
- スケールアウト直後にlatencyが増加する
- Force mergeによりHPAのmetricをCPU利用率にできない
- トラフィックが少ない時間ではボトルネックとなるmetricsが変化する
スケールアウト直後にlatencyが増加する
この課題は元々rolling updateを行うときなどでも観測できていたのですが、Dataノードが起動し、shardが配置され、検索リクエストを受け付け始めた直後のlatencyが非常に高くなっていました。これはDataノードに限った話ではなくElasticsearchにリクエストを送るmicroserviceにIstioを導入した際に、Coordinatingノード (shardを持たずに最初にリクエストを受け付けてroutingとmerge処理を行うだけのノード)でも発生していました。
原因はおそらくJVMのコールドスタート問題によるもので、Istioの場合sidecarが新しく追加されたPodに即座に均等にリクエストを送ろうとすることが問題でした。この点については、Istio導入以前はHTTPのkeep aliveにより、新しく追加されたPodに緩やかにトラフィックが移行していくため問題となっていませんでした。
この課題を解決するためにpassthrough(Istioのservice discoveryに頼らずそのまま通す)やDestinationRuleのwarmupDurationSecs(指定の秒数をかけて新しいPodに徐々にトラフィックを増やしていく)を使いました。ただDataノードの場合は、routingは完全にElasticsearch依存となり、外部からどうにかできる余地がなかったためElasticsearch自体を修正することにしました。これはupstreamにPull Requestとしてあげています。https://github.com/elastic/elasticsearch/pull/90897
Force mergeによりHPAのmetricをCPU利用率にできない
我々のindexはドキュメントの削除,更新(Elasticsearchが利用している検索ライブラリであるLuceneにおける更新は、内部的には削除+追加という処理をおこないます)の頻度が高いため毎日トラフィックの少ない時間帯にforce mergeを行って論理的に削除済みのドキュメントを削除していました。このforce mergeを忘れると数日後にトラフィックを捌けなくなるということが過去発生していました。
しかしForce mergeはCPUに負荷のかかる処理であり、またその性質上同じタイミングでスケールアウトを行うべきものでもないため、HPAのmetricをCPU利用率にすることができませんでした。そのため初期は検索リクエスト数をDatadog経由でexternal metricとして利用しようと考えていましたが、新しいmicroserviceから呼び出される際にクエリのパターンが変化し負荷のパターンも変わるため本質的にはCPU利用率をHPAのmetricにすることが望ましいです。
そこでLuceneのソースコードを読んでいると、deletes_pct_allowedというオプションを見つけました。これは論理的に削除済みのドキュメントの割合を指定するためのもので、デフォルト値は33でした。この値を変更しながらパフォーマンステストを実施すると30%付近から急激にlatencyが悪化することがわかりました。そのためこの値を最小値である20 (最新のElasticsearchではデフォルト20、最小値は5 https://github.com/elastic/elasticsearch/pull/93188
)に設定することでForce merge処理を削除することができました。これによりHPAのmetricにCPU利用率を指定することができています。
トラフィックが少ない時間ではボトルネックとなるmetricsが変化する
Elasticsearchではindexの中身をファイルシステムキャッシュに載せることで低latencyを実現します。我々も必要な情報はすべてファイルシステムキャッシュに載せることを目指しているため、巨大なindexでは多くのmemoryを使用します。トラフィックがある程度存在する時間帯ではボトルネックがCPUであり、CPU利用率をHPAのmetricにすることでうまくオートスケールします。
しかしトラフィックが極端に少ない時間帯であっても可用性のために最低限のレプリカは確保しなくてはなりません。そのためその時間帯ではボトルネックはmemoryとなり、必要なCPUに対して無駄に多くのCPUを割り当ててしまうことになります。
元々の構成はmemoryの量がdisk上のindexサイズの2倍となるよう設定されており、memory.usageも高い値を示していましたが、memory.working_setを見るとまだまだ余裕がありそうでした。Kubernetesにおいて memory.working_setとは memory.usageからinactive filesを引いた値となります。inactive filesはざっくりいうとほとんど参照されていないファイルシステムキャッシュのサイズとなります。Kubernetesではcontainerのmemory limitに達する前にこれらのファイルシステムキャッシュはevictされるため、割り当てるmemoryはもっと少なくても良いことがわかります。
勿論inactive filesではないファイルシステムキャッシュも必要ならばevictされるのですが、こちらはevictしすぎるとパフォーマンスの劣化につながります。難しいことにinactiveでなくなる条件が意外と緩いのでどこまでevict可能なのかが明示的にはわからないため、memory requestをあまり攻めた値にはできていませんが、これによりmemoryがボトルネックになっている時間帯に合計CPU requestを減らすことができました。
ElasticsearchはstatefulなアプリケーションなのでPodの再起動が必要なVPAを適用するのが難しいですがIn-place Update of Pod Resources (https://kubernetes.io/blog/2023/05/12/in-place-pod-resize-alpha/) が利用可能になるとCPU requestを再起動なしにスケールダウンできるようになるため、この問題が緩和されることを期待しています。
さいごに
この記事では、ECKでKubernetes上で動かしているElasticsearchクラスタに対してHPAを用いてCPU利用率を基にオートスケーリングする方法について述べました。これによりElasticsearchの運用に関わるKubernetesのコストが約40%削減できました。おそらく今後Elastic CloudにはServerlessの一環としてこの辺りのオートスケーリング機能が提供されることになると予想しますが、我々の今の状況下においては効果的な手法だと感じています。
search infraチームでは現在ともに働く仲間を募集しています。もし興味がありましたらご気軽にお問合せください。




