こんにちは!SouzohのMLチームでSoftware Engineerをしているwakanaです。
SouzohのMLチームは2021年4月にスタートし、ちょうど2年が経ちます。当時1人だったメンバーも、今では4人になり、レコメンデーションを中心に5, 6個の機能を提供するようになりました。MLOpsも成熟し、より新しく高度なML機能開発に集中して取り組める環境が整ってきていると感じています。
そこでこの記事では、立ち上げから2年たった今SouzohのPython, ML環境がどのようになっているか紹介しようと思います。これからPythonやMLのMonorepoでの開発環境を整えようとしている方、特に少人数での運用を考えてる方の参考になれば嬉しいです。
TL;DR
- SouzohではPoetry, Bazel, VertexAI Pipelinesで快適なMonorepo開発環境を実現
- Monorepoの強み、共通化で個々の開発を加速
- BazelでPythonを扱うのは難ありだが、Kubeflow Pipelinesと相性抜群
MLチーム立ち上げ当初の話に関しては、過去の記事も御覧ください。
SouzohのPython, MLまわりの開発環境
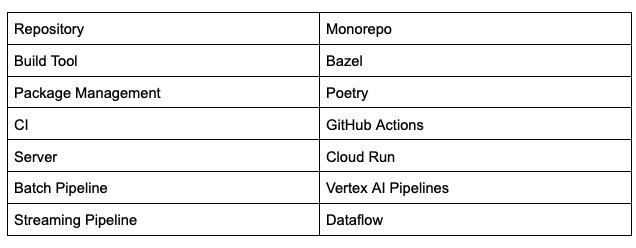
Souzohの開発環境の大きな特徴がMonorepoということです。Goで書かれた数十のサービス、TypeScriptで書かれたBFFとフロントエンド、Javaによるapache-beamのPipeline、PythonによるML Pipelineなどすべてのコードが1つのrepositoryで管理されています。
これらを統合的に実行するBuild ToolとしてBazelを用いています。依存するprotobufのコンパイルや、docker imageの作成までBazelによって行うことができます。
またインフラとしては、サービスはCloud Run上で実行されています。MLの機能に関しても、Goで実装されたサーバーをCloud Run上に立て、データベースやミドルウェアにアクセスすることで実現されています。データベースやミドルウェアの更新は、Pythonで実装されたものがVertex AI PipelinesやDataflowで実行されています。
技術選定と実際
上で紹介した中でもよく考慮して技術選定を行ったものや特徴的だと思われるものに関して、選定過程で考えたことと、実際使ってみた感想について紹介していきます。
Poetry
SouzohではPythonのパッケージ管理としてPoetryを使っています。技術選定の際の候補はPipenv, Poetryでした。その当時、メルカリの他のチームではPipenvを使っていましたが
- ツールとしての使いやすさ(documentの充実度、安定性、速度など)
- Bazelとの相性
を主に考慮してPoetryを採用しました。とくにBazelとの相性に関して、Pipenvの場合はlock fileからrequirements.txtを生成し、Bazelからはそれを使って依存関係を解決する方法しか見つけられなかった一方、Poetryの場合はlock fileを直接読んでくれる rule (rules_poetry) が存在してたことが決め手となりました
Vertex AI Pipelines
Vertex AI Pipelinesの採用に関しては、立ち上げ当時の記事 でも紹介していますが、特にSouzohのように数人規模のチームで持つPipelineの基盤としてはベストな選択だったと思います。Kubernetes基盤の管理コストがないのはやはり大きく、ComponentやPipelineの実装だけ行えば動かすことができるので、開発に集中することができています。
一方でmanagedな分柔軟性がなかったり機能がまだ足りなかったりして不便を感じることもあるので、大人数のチームで基盤の運用に人を割けるのであれば、自前で運用するのも選択肢ではあると思います。
例えば、人数が多くなり走らせるPipelineの数も多くなればnamespaceやexperimentの概念は欲しくなってくると思います。
また、以前のチームでKubeflowを自前で運用していた際には、裏側のArgo workflowsの機能も使うことができ便利だと感じていました。例えば WorkflowTemplateを使って、全てのPipelineに終了ステータスをSlackに通知するExit Handlerを自動でつけるようにしていました。しかし、Vertex AI Pipelinesではそのような機能はないので、Pipelineを定義する際に毎回明示的にExit Handlerを付ける必要があります。
定期実行に関しても、現状ではVertex AI Pipelines単体で実現する方法はなく、Cloud SchedulerやCloud Functionsを組み合わせる必要があります。
この辺りに関しては今後、機能が充実してくることを期待しています。
Monorepo
Monorepoでの開発をスタートするにあたって、かなり設計に悩んだのがrepositoryの構成です。MLチームが始動した時点ですでに第一階層は言語で区切る構成になっていたので、python/というディレクトリを追加することは明らかでしたが、python/以下の構成をどうするかは参考になる例も少なく手探りで決めてきました。
何度か改善を重ねた上で、現状ではこのような構成になっています。
.
├── go/
│ └── services/
│ └── similarSearch/
├── proto/
├── python/
│ ├── components/
│ │ ├── slack_notification/
│ │ └── ...
│ ├── libs/
│ │ ├── slack/
│ │ │ ├── client.py
│ │ │ └── client_test.py
│ │ └── ...
│ ├── projects/
│ │ └── similar_products_search/
│ │ ├── components/
│ │ │ └── ...
│ │ ├── pipelines/
│ │ │ └── ...
│ │ └── dataflow/
│ │ └── ...
│ └── tools/
├── poetry.lock
├── pyproject.toml
└── ...python/components以下には、様々な、projectのPipelineで共通して使うような汎用的なComponentをおいています。例えば、Exit Handlerとして使われる、Pipelineの終了ステータスをSlackに通知するComponentなどがあります。
python/libs以下には、ライブラリとして使われるコードが置かれ、python/tools以下には、projectの雛形を生成するコードやPython内で共通して使われるBazelの関数定義といったツールとして使われるものが置かれています。
そしてpython/projects以下に、各ML projectのコードが置かれています。Souzohで運用しているMLのサービスは全てPythonのPipelineでDBやミドルウェアの更新を行い、Goのサービスからそれにアクセスするという構成になっているので、Pythonのprojectは、Kubeflowのpipelines, components、Dataflowも使用している場合にはdataflowで構成されています。
また、パッケージは一元管理されているので、パッケージ管理のファイルpyproject.toml, poetry.lockはroot直下に置かれています。
この構造は次のような点がポイントとなっています。
-
Testの配置
テストコードの配置として、tests/というディレクトリをつくって、その下に置くケースもあると思います。私が以前に所属していたチームでもそのようにしていたので、はじめはSouzohでもそうしようかとも考えました。しかし、Monorepoの場合repositoryの中に沢山、それもコンテキストが独立したコードが置かれることから、関係するコードはすぐそばに合ったほうが見通しがよいだろうと思い、ソースコードと同じところにxxx_test.pyというファイル名で配置することにしました。
細かい点として、testをprefixでなくsuffixにすることでテスト対象のファイルと並びが連続するようにしています。 -
パッケージは一元管理
これは、途中で変更した点の一つです。これまでの経験からML系のライブラリは後方互換性が担保されていないことも多い印象があったこと、同時に使われるライブラリが増えると相互の依存関係が複雑になり解消が難しくなりそうだと考えたことから、はじめはprojectごとにパッケージを管理していました。しかしながら、projectごとに管理すると、version updateの手間もその分増えるし、Multirepoの場合と変わらないそれぞれのprojectが完全に独立した状態となり、Monorepoの良さを活かせてないと感じました。そこで、途中で一元管理するように変更しました。
パッケージが更新された際には、CIで全てのPythonのテストが走るようになっており、問題がある場合は事前に気づくことができます。そのため一元管理にしても、「他のprojectの影響で更新があったせいで、こっちのprojectのコードが動かなくなった。」ということもこれまで起きていません。
パッケージ管理に限らず、このようにCIなどを使って、全体に関わる変更を入れるときは全てのコードが動くこと確認する仕組みを用意した上で可能なものは一元管理にすると、メンテナンスコストが下がりMonorepoの良さを享受できると思います。
-
構造の対称性
全体的なrepository構造として、どのコードがどこにあるか見つけやすくするため、できるだけ処理を共通化してMonorepoの良さを活かすために、対称性を意識しました。具体的には、
- 各projectが同じ構造になるようにする
python/直下とproject以下で、それぞれのcomponents/以下は同じ構造になるようにするcomponents,dataflow/,pipelines/について、それぞれの中身のディレクトリ構造を全て統一する
というようになっています。これによりライブラリやCIの実装がやりやすくなっていると思います。
このような点に気をつけて設計した結果、現状うまくMonorepoを使えていると思います。特に、以下のような点でメリットを感じています。
-
ライブラリ化の気軽さ
Multirepoで開発していたときも共通して使われる処理はライブラリとして実装していました。しかし、パッケージ化して配布する手間、使う側はそれを認証を含めてインストールする手間などから、本当によく使われる汎用的なもののみをライブラリ化し、基本的にはprojectごとに実装していました。Monorepoの場合は、ライブラリといっても、同じrepository内に置かれているコードでしかないので、パッケージ化、インストールの手間がありません。また、同じrepository内で使われるという前提があるので、ライブラリを実装する際に完全に汎用的にする必要はなく、ある程度コンテキストに依存するものであってもライブラリ化することができます。
そのおかげでMultirepoよりも気軽にライブラリ化することができ、個々のprojectの実装を簡略化することができています。 -
CIの充実
1つ目で述べたライブラリの話とも関連しますが、CIに関しても、Multirepoであれば各々実装する必要があるところを1つ実装すれば済むので、その分充実させることができます。
例えばSouzohでは、Componentの変更を検出し、それに依存するPipelineを抽出し、変更の合ったComponentだけ差し替えたPipelineをテスト実行してくれるCIが実装されています。

Componentの変更を検出し、それに依存するPipelineを抽出し、変更の合ったComponentだけ差し替えたPipelineをテスト実行してくれる もちろんこれ自体はMultirepoでも実装できるものではありますが、Componentが共用されていても全ての依存元を把握でき、また1つ実装すれば全projectに対して使われるため多少実装コストがかかってもそれに見合うMonorepoだからこそ実現できていると思います。
ちなみに、Bazelでは
rdepsという演算子を使って依存関係を逆引きできるので、このCIが簡単に実現できているのはBazelを使っている恩恵でもあります。
Bazel
Souzohでは他の言語でもBazelを使っていること、MLとの相性の観点からPythonでもBazelを使っていますが、MLという要素抜きに純粋にPython✕Bazelということを考えると課題が多いように思います。
特に以下の点に課題を感じています。
-
Bazelが解決した依存関係がBazelから実行しないと読み込まれない
Bazelの役割として、GoやJavaの場合は、Bazelは依存関係を解決し、protobufに依存している場合はprotobufをコンパイルし、最終的に実行形式ファイルを生成してくれます。Pythonにおいても基本的には同じです、依存関係を解決し、protobufに依存している場合はprotobufをコンパイルしてくれます。しかしながら、Pythonの場合は実行形式ファイルないため、代わりに実行用のPythonスクリプトが生成されます。このスクリプトは、Bazelが解決した依存関係にPYTHONPATHを通した後、本来実行したいPythonスクリプトを別プロセスで起動するという処理を行っています。
つまり、BazelでPythonをbuildし、実行する際には、通常pythonコマンドで実行するときとは異なる状況で実行されます。これにより、例えばDataflowのPipelineを実装した際など、main sessionはBazelから実行するため問題なく起動しても、workerを起動する際にBazelの実行用スクリプトから実行されるわけではないので、うまく依存関係が解決できないなどの問題が発生します。
Souzohでは、依存関係をworkerが読める場所にコピーするなどのハックをしてなんとか動かしていますが、動く状態にするまでに余計な労力がかかってしまっています。 -
Namespace packageが解決できない
主にgoogle系のライブラリは、Namespace packageという機能により、別のパッケージでありながらpathが途中まで共通するような実装になっています。(google-cloud-storage: google.cloud.storege, google-cloud-bigtable: google.cloud.bigtable, など)
Bazelがうまくこれらを解釈できないために、複数のgoogle系のライブラリに依存するとimportエラーが発生します。
grpcのrepositoryがやっているのと同様のhackをすることで、一応動かせるようにはできますが、余計な労力がかかってしまうので不満な点です。 -
Gazelleに改善の余地あり
GazelleはBazelのbuildの定義ファイル(BUILD.bazel)を、コードから自動生成してくれるツールです。ネイティブでGoをサポートしており、Goではかなり使い勝手のいいツールになっています。Gazelleのおかげで、SouzohでもGoをメインで書いているエンジニアは、BUILD.bazelを一度も手動で書いたことがない人は多いのではないかと思います。開発が始まった当初は、そもそもPythonのサポートがなかったのでGazelleを使う選択肢はなく全て自力で書いていました。毎回フォーマット的には同じなので、ある程度コピペでき、めちゃくちゃ大変というわけではないのですが、やはり手間だとは感じていました。
2021年11月にPython Gazelle Pluginが追加されて使えるようになったので、早速試して見ましたが以下のような点から最終的には導入を見送り、今でも手作業で書いています。- requirements.txtが必要
- Poetryで管理しているのにrequirements.txtはできれば置きたくない
- Poetryから生成したrequirements.txtはそのままだと、python_versionなどが含まれGazelleが解釈できない
- importの仕方や、file名に制約がある
from google.cloud import storageだとうまく解決できないのでimport google.cloud.storage as storageとする必要がある (現在は解消済み?)- 実行したいファイルは
__main__.pyというファイル名にする必要がある
- requirements.txtが必要
ここまでBazelでPythonを扱う上での課題点を多く書きましたが、それでもBazelを使い続けているのはML、正確に言うとKubeflow Pipelines (Vertex AI Pipelines)との相性が良いからです。
Kubeflow Pipelinesでは、PipelineのComponentごとにdocker imageを用意する必要があります。
そのため、これまでBazelを使わない環境でComponentを実装する際は、以下のようにComponentごとにDockerfileを用意し、Componentごとにパッケージ管理を行っていました。
components/
└── component_a/
├── main.py
├── component.yaml
├── Dockerfile
├── Pipfile
└── Pipfile.lock必要なファイルが多く純粋に面倒なことに加え、パッケージ管理がComponentごとにされるため、Component間のバージョン互換性が保証できず、Pipelineの中で前のstepで生成されたファイルが、後続のstepで開けない、などの問題を引き起こす可能性があります。
Bazelを使うことで、Souzohでは以下のような構成でComponentを実装しています。
components/
└── component_a/
├── main.py
├── component.yaml
└── BUILD.bazel前述の通りパッケージはrepositoryで一括管理されており、各Componentのdocker imageを作成する際には、Bazelによって必要なdependencyだけ抽出されます。これにより、Component同士のバージョンの整合性を確保しつつ、imageには必要なdependencyだけを含めるということが実現できています。
また、コードを実行するだけのdocker imageであれば、Bazelで用意されている関数でbuildできるためDockerfileも書く必要がありません。docker buildの際の処理を多少カスタマイズしたい場合には、それを関数として実装することで使い回すことができます。
Souzohでも、mecabを使うかどうかなどを指定できるようにした自前の関数を作成しています。そのおかげで、たった数行書くだけで簡単にdocker imageを作ることができます。
create_project_component_image(
bin_name = "train",
project = "personalization",
use_mecab = True,
)まとめ
この記事ではほんの一部ですが、SouzohのML開発環境について紹介しました。全体的に見て、比較的いい環境が整えられていると思っています。もし今またゼロから環境構築を行うとしても、同じような技術スタックを選定すると思います。Bazelだけは、docker imageのbuildの手軽さはそのままに、もっとPythonで使いやすいToolがあればそれを採用するかもしれません。
チームの中でも、開発がやりづらいという意見がでることはほぼないですが、もっとよくできると感じた点があった際にはすぐに改善し、メンバー全員で常に「自分たちが思う最高の開発環境」を整えるようにしています。これからももっと開発を加速できるようにML環境の改善をすすめ、よりよいメルカリShopsの体験をお客さまに届けていきたいと思います。




