こんにちは、メルカリのレコメンデーションチームで Software Engineer をしている @yaginuuun です。主に推薦を通じたホーム画面における体験改善に取り組んでいます。
元々はデータアナリストとしてデータ分析関連の業務を担う傍らA/Bテストのワークフロー改善にも取り組んできました。
Mercari Advent Calendar 2022 の12日目では、去年から今年にかけて取り組んできたA/Bテスト分析の自動化について、課題感や実際の実装などについて触れていきます。
背景
A/Bテストは世界中の企業で導入されている効果検証のゴールドスタンダードとも呼べる手法であり、メルカリでも毎日のようにA/Bテストを用いた改善活動が行われています。
A/Bテストは一見とてもシンプルな効果検証手法ですが、それを適切に使用するためにはさまざまな統計的事項やアンチパターンを考慮する必要があります。そのため評価担当者の理解度によって効果検証の質にばらつきが生じやすく、過去メルカリでも課題の一つとなっていました。
この課題に対して、メルカリでは Experiment Design Doc (社内ではEDDと呼ばれています) というA/Bテストの設計テンプレートを導入することによってアプローチしてきました。
メルカリにおけるA/Bテスト標準化への取り組み|Mercari Analytics Blog|note
EDDの導入から時間がたち、A/Bテスト設計の標準的なフローが確立したことによって一定上述の課題は解決に向かっている認識ですが、その中で次のステージの課題が見えてきました。それは本記事のテーマでもある、A/Bテスト分析の自動化です。
A/Bテスト分析の自動化の必要性
各々の分析者が一定以上の知識をつけ、効果検証の質が担保できたとしても手動での分析には必ず限界があります。もしかしたらSQLの中にバグを埋め込んでしまうかもしれませんし、スプレッドシートやPythonなどでの統計値計算に間違いがあるかもしれません。また、同時に走るA/Bテストの量が増えてきた時に、分析者のリソースがA/Bテストの評価だけで逼迫してしまい、他の改善のための分析に費やすことができなくなってしまうという問題も起こり得ます。
この課題に対して、先進的な企業では Experimentation Platform と呼ばれる基盤をそれぞれ開発、運用しA/Bテストの半自動的な分析を可能にしています。
・It’s All A/Bout Testing: The Netflix Experimentation Platform | by Netflix Technology Blog
・Under the Hood of Uber’s Experimentation Platform
・Scaling Airbnb’s Experimentation Platform | by Jonathan Parks | The Airbnb Tech Blog
そこで我々も他社の事例を参考にさせていただきつつ、試験的にA/Bテスト分析プラットフォームを開発、導入しました。
もう一つの狙い:Institutional memory の蓄積
Institutional memory とは、もはや仕事でA/Bテストに関わる方のバイブルとも呼べるであろう「A/Bテスト実践ガイド」の中で触れられているもので、過去に実行されたA/Bテストの結果やリリース判断など、つまりは組織としてのA/Bテストからの学びを指します。
EDDはA/Bテストの行われた背景や評価設計を簡潔に残すのには適していますが、そのような結果の蓄積に関して弱いという欠点がありました。
A/Bテスト結果を集積して参照しやすくするという取り組みは非常に重要です。過去にどんな取り組みを行ってきたのか、新しく参画したメンバーのオンボーディングを助けることは間違い無いですし、会社のあらゆるメンバーがそれぞれのチームで行ってきた取り組みから学ぶことができるようになります。その結果、会社として過去に失敗した施策と似たコンセプトの施策を防ぐことにも繋がりますし、逆に成功したコンセプトを他の分野に活用したりと施策の成功確率の底上げが期待できます。
中央的なプラットフォームを作ることで、自動的にA/Bテストの結果を一箇所にまとめることができ、EDDでは対応できなかった Institutional memory の蓄積という課題に対してもアプローチできるのではないか、というのも今回の取り組みの期待としてありました。
A/B test auto-analysis tool
ここからは実際に運用しているものの実装について触れていきます。前提として統計値の計算を定期的に行うためのワークフローエンジンとして Airflow を採用しているため、DAG を中心としたワークフローになっています。
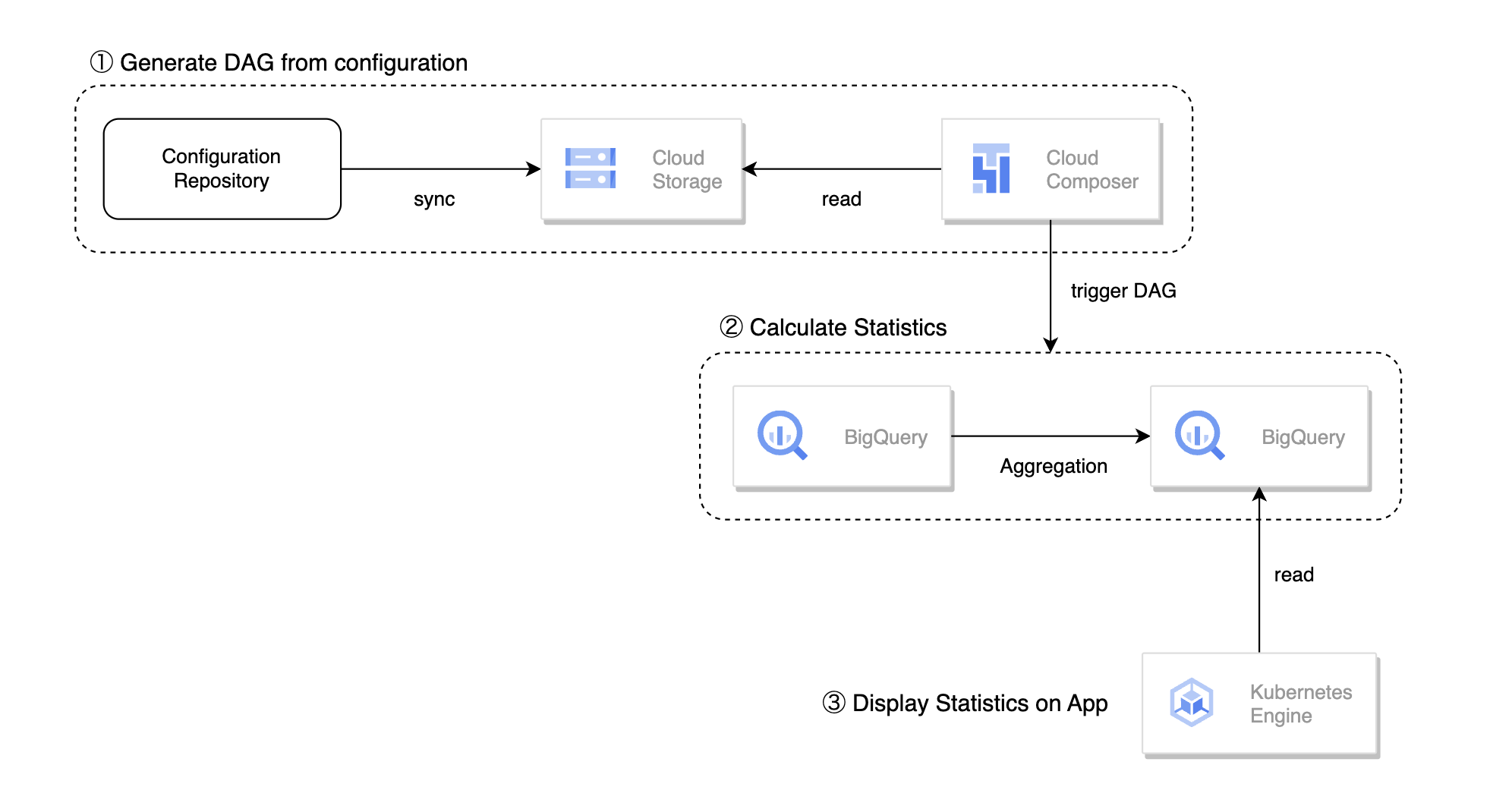
全体の設計は上の図のようになっており、大きく以下の処理で構成されています。
- 設定ファイルからのDAG生成
- DAGによるA/Bテストの統計値計算
- アプリケーション上での統計値表示
設定ファイルからのDAG生成
上図の Configuration Repository には以下の二種類のファイルが含まれています。
- 測定設定ファイル:A/Bテストの測定設定が記載されたyaml形式のファイル
- メトリクス定義:メトリクスの計算過程が記述されたSQLファイル
測定設定ファイル
以下のようなファイルをA/Bテストごとに作成しています。
test_settings:
test_name: sample_test
friendly_test_name: Sample A/B test
assignment_table: ab_assignment_log
target_os:
ios:
android:
period:
start_date: 2022-01-03
end_date: 2022-01-16
EDD_link: link_to_document
metrics:
subsets:
- purchases
- listings
- ...
goal:
purchase_rate_total:
…
guardrail:
list_count_total:
…
debugging:
access_users:
others:
search_count_total:
purchase_count_fashion:
…大きくは test_settings というテストのメタデータを記述する場所と metrics という評価指標を記述する場所に別れています。
test_settings には、例えば社内におけるテストの判別IDや各テストパターンへの割り当て情報が格納されるテーブルはどこか、測定期間はいつからいつまでかといった情報を記述されます。metrics に記述するメトリクスの種類はEDDと対応しており、それぞれの種類で分けて定義することができます。(詳細はEDDについてのブログをご参照ください)
メトリクス定義
類似するメトリクスをまとめた subset と呼ばれる粒度で以下のように定義しています。
-- constants
create temp function start_date() returns date as (date('{start_date}'));
create temp function end_date() returns date as (date('{end_date}'));
create temp function target_os() as ({target_os});
with raw_events as (
select
user_id,
client_type,
timestamp,
item_id,
source as purchase_source
from
client_logs
where
date(timestamp) between start_date() and end_date()
and client_type in unnest(target_os())
and event_type = "purchase"
)
select
user_id,
client_type,
variant,
count(distinct user_id) as buy_users_total, -- this value is always 1.
count(distinct item_id) as buy_count_total,
from
raw_events
inner join
`{assignment_table}` as assignments
using(user_id, client_type)
group by
1, 2, 3このようにSQLベースで定義されていますが一部がパラメータ化されており、先ほどの測定設定ファイルからA/Bテストの設定によって必要な箇所を変化させられるようになっています。
他の設計としてSQLファイル一つに付き一つのメトリクスを定義するという設計も考えられますが、それだと重複部分の多い定義ファイルが乱立することによるメンテナンスコストの増大や、類似するメトリクスにおいては同じ処理をメトリクスの分だけ繰り返す必要があり、計算上のオーバーヘッドが大きくなってしまうという問題があるため、このようにある程度まとまった単位で定義できる設計を採用しています。
Configuration Repository に含まれる設定ファイルはCIによってCloud Composer (Airflow) が参照するCloud Storageと同期されています。DAGの生成にあたっては Dynamic DAG Generation を利用しており、Cloud ComposerからCloud Storageをスキャンするタイミングで設定ファイルを元にDAGがそれぞれ生成されるようになっています。
DAGによるA/Bテストの統計値計算
上述した設定ファイルによって生成されるDAGでは下図のようにいくつかのステップを経て最終的な統計値が算出されるようになっています。

上の図の中にある番号ごとに以下のようなことが行われています。
- 各テストパターンへの割り当て情報を計算
- 指定されたsubsetごとにuser粒度の統計値を計算
- 前ステップで得られたsubsetを結合
- テストパターンごとの統計値を計算
4は実際にアプリケーションから読み取られるテーブルで、バージョニング処理が行われており過去の統計値も参照可能になっています。また、3で得られるテーブルはA/Bテストに割り当てられたuser_idごとに期間中の統計値が格納されており、セグメントを切った分析に便利に使うことができるので別途保存されています。
アプリケーション上での統計値表示
Streamlit を用いて構成されたWebアプリケーションでブラウザからA/Bテスト結果が確認できるようになっています。アプリケーション上では指定されたメトリクスにおける統計的有意性や統計量の差分の確認ができる他、いくつかの追加分析機能が提供されています。
A/Bテストを運用していく中では、仮説の立てづらいメトリクスの動きに遭遇することは少なくありません。そこで、単に期間通した統計値を確認できるだけでなく、そういった不可解な結果が得られた時にヒントを得るためによく行われる分析をツールとしてサポートできていると価値がより高まると感じています。
現状、auto-analysis tool では以下のような追加の分析機能がサポートされています。
- Sample Ratio Mismatch (SRM) の検知
- 日別のインパクト推移の確認
- セグメント別の統計値の確認

上の図はダミーのA/Bテストを元にした実際のツールのスクリーンショットです。設定されたメトリクスにおいて、平均効果の他に信頼区間、統計的有意性の有無がテストパターンごとに表示されています。
導入の効果
局所的な導入ではありつつも、複数回のアップデートを経つつ1年半程度ツールの運用を行ってきました。これまでのところ、ツール開発のモチベーションとなった効果は十分に感じており、分析者のA/Bテスト評価、分析に割く工数はかなり削減できた実感があります。
また、もう一つの狙いとしてあった Institutional memory の蓄積についても、やはり結果が自動的に一箇所にまとまるということの威力はすごく、こちらについてもニーズを満たせつつある感覚があります。個人としても過去に行った施策と類似したアイデアが上がった際に過去の実験結果をツール上から探して共有するという行動をしやすくなったと思います。
今後の課題
局所的にでもこのような仕組みを導入できたのはとても大きいことだと思いつつ、次の課題として最も大きいのは適用範囲の拡大だと思っています。
現状は試験的な導入ということもあり、敢えて提供範囲を絞っています。そして、そうすることによって考えずに済んでいるさまざまな要件があります。しかし、適用範囲の拡大を考えた時にはそうした要件にも一つ一つ対処できるように設計を変化させていく必要があります。
一例を挙げるとすると、スケーラビリティの課題があります。提供範囲を拡大した際には同時に評価しなければならないA/Bテストの数が一気に増えることが考えられますが、そうなった時にも計算リソースを効率に使いつつ遅延なくテスト結果を計算できている必要があります。また、利用者の広がりに応じて、サポートに割く工数も一定確保する必要があると想定されます。
最後に
本記事では、メルカリにおけるA/Bテスト分析自動化の取り組みについて紹介しました。もしも本記事が関連する課題感を持っている方の一つのヒントになることができたらとても嬉しく思います。
また、この取り組みは Experiment Design Doc の運用から始まり、ツールの設計や実装に対するレビュー、コントリビューション等多くの方に支えられています。特にアナリティクスチームの方々、レコメンデーションチームの方々にこの場を借りて感謝の意を伝えられればと思います。
明日はネットワークチームの @raphael さんによる記事です、引き続きお楽しみください!
We’re hiring!
もしこのような課題に興味を持っていただける方がいらっしゃれば、メルカリではメンバーを募集中ですのでぜひ以下のページをご覧ください!
参考文献
- Scaling Airbnb’s Experimentation Platform | by Jonathan Parks
- 今回のツールを設計するにあたって、Airbnb における Experimentation Platform を多く参考にしています。
- メルカリにおけるA/Bテストワークフローの改善 これまでとこれから – Speaker Deck
- 2022/1/14 PyData.Tokyo Meetup #25における発表です。
- A/Bテスト実践ガイド 真のデータドリブンへ至る信用できる実験とは




