こんにちは。メルカリのPlatform Infraチーム所属の @sanposhiho です。
11月にアメリカのデトロイトで KubeCon + CloudNative North America 2022 が行われ、メルカリからも数名が現地にて参加をしてきました。
僕は個人的に Kubernetes の主にスケジューラーに対してコントリビュートをしていて、SIG-SchedulingのReviewerをやっています。今回SIG-SchedulingのメンテナセッションであるSIG-Scheduling Deep Diveというセッションにて登壇させていただく機会を頂きました。
セッションでは、スケジューラーに対して直近で入った機能を初め、SIG-Schedulingがサブプロジェクトとして管理しているいくつかのプロジェクトの紹介や直近の更新などに対して紹介を行いました。
この記事では、SIG-Scheduling Deep Diveにて紹介された内容に関して、時間が足りず説明できなかった部分を含めて紹介していくことを目標としています。
全く関与していないサブプロジェクトに関しては、浅い紹介になることをご容赦ください。また、この記事執筆段階ではKubernetes v1.26はリリースされていません。導入予定となっている機能が実際にはv1.26に間に合わなかったり、デザインの変更になっている可能性もあるので、使用する際は最新の情報をご確認ください。
動画アーカイブや用いられたスライドが以下に公開されています。英語が下手なのはご愛嬌です。

Kubernetes Scheduler とは
スケジューラーはPodをどのNodeで実行するかを決定しているコンポーネントです。
その時の様々なリソースの状況を見たり、ユーザーが指定したPodのスケジュールの制約を鑑みたりしつつ、Podに最適なNodeを決定しています。NodeAffinityや比較的新しいものだとPod Topology Spread Constraintsなど、Podのスケジュールの制約を指定できる機能も基本的にスケジューラーに実装されています。
また、スケジューラーは以下のScheduling Frameworkというものに沿ってスケジュールを行なっており、様々な役割を持つ拡張点に分かれています。
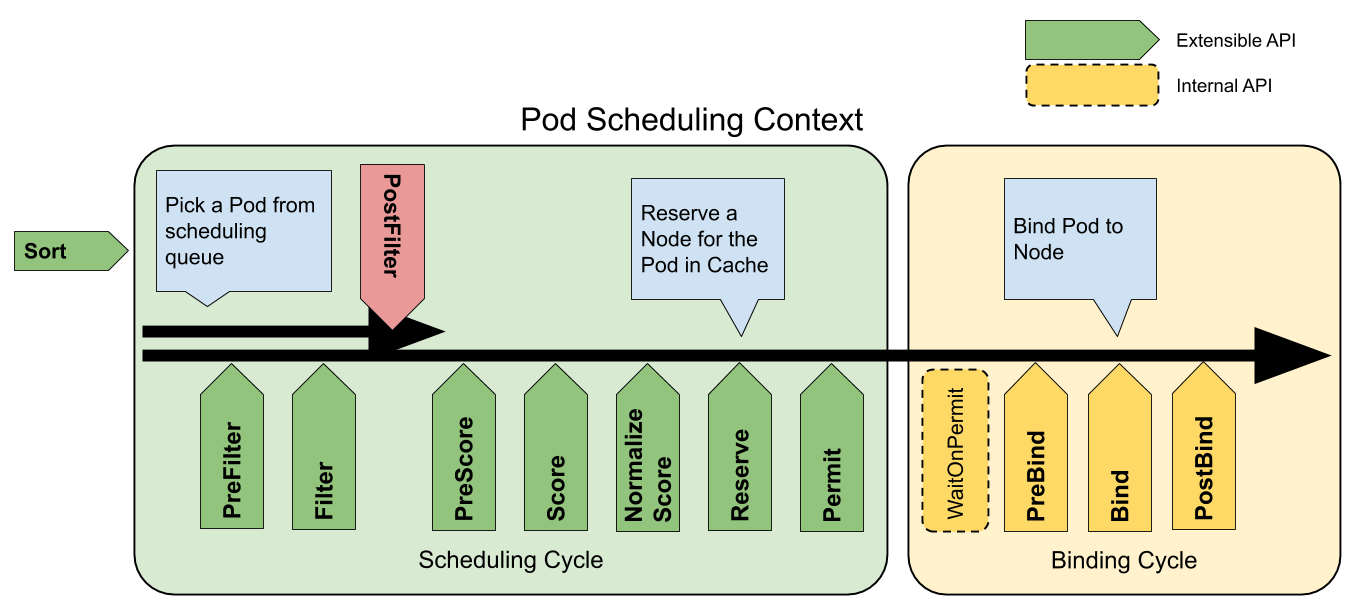
(公式のドキュメントから引用)
Scheduling Framework | Kubernetes
この内、Nodeの決定には大きく二つの拡張点が関わっています。
不適当なNodeを除外するフェーズ(Filter)と、残ったNodeから最も好ましいNodeを選択するフェーズ(Score)です。
例えば、Filterでは、Podのリソース要求(request)に対して、リソースの空き容量が足りないNodeや、PodのrequiredなNodeAffinity(requiredDuringSchedulingIgnoredDuringExecution) に対して適していないNodeなどが除外されます。
その後、Scoreにて、全体のNodeのリソースの使用量のバランスがちょうど良くなるNode、PodのrequiredではないNodeAffinity(preferredDuringSchedulingIgnoredDuringExecution) に対して適しているNode、など様々な項目でスコアリングされた上で、最適なNodeが決定されます。
また、スケジューラーの各機能はScheduling Framework上でそれぞれプラグインという形で実装されています。
上記の図でExtensible APIとされて列挙されているのが、プラグインが実行可能な拡張点で、プラグインはそれぞれ一つ以上の拡張点で動作します。
例えばPod Topology Spread Constraintsはv1.25現在、PreFilter、Filter、PreScore、Scoreの拡張点で動作することで機能を提供しています。
ここでは、この記事をある程度理解するために必要な概要のみを紹介しました。
さらに詳しくスケジューラーに関して学びたい方は、昨年僕が書いた 自作して学ぶKubernetes Scheduler という記事を参照してみてください。
かなり長い記事になっていますが、最初の「kube-schedulerとは」の章を読むだけでもう少し理解が深まると思います。
では、ここからKEPを中心にスケジューラーの直近のアップデートを見ていきましょう。
KEPとはKubernetes Enhancement Proposalsの略称です。大きな機能の導入や振る舞いの変更が行われる際に記述されます。
https://github.com/kubernetes/enhancements/tree/master/keps
KEP-2891: Simplified Scheduler Config
KEP-2891: Simplified Scheduler Config
スケジューラーにはKubeSchedulerConfigurationと呼ばれる設定が使用できます。
Scheduler Configuration | Kubernetes
先ほど、スケジューラーの各機能はScheduling Framework上でそれぞれプラグインという形で実装されていることを軽く紹介しましたが、KubeSchedulerConfigurationでは以下のようにどのプラグインを使用するかを設定することができます。デフォルトでは全てのUpstreamのプラグインが有効化されるようになっています。(Feature Gateの有効化を必要とする機能を提供するプラグイン等、特殊な場合を除く)
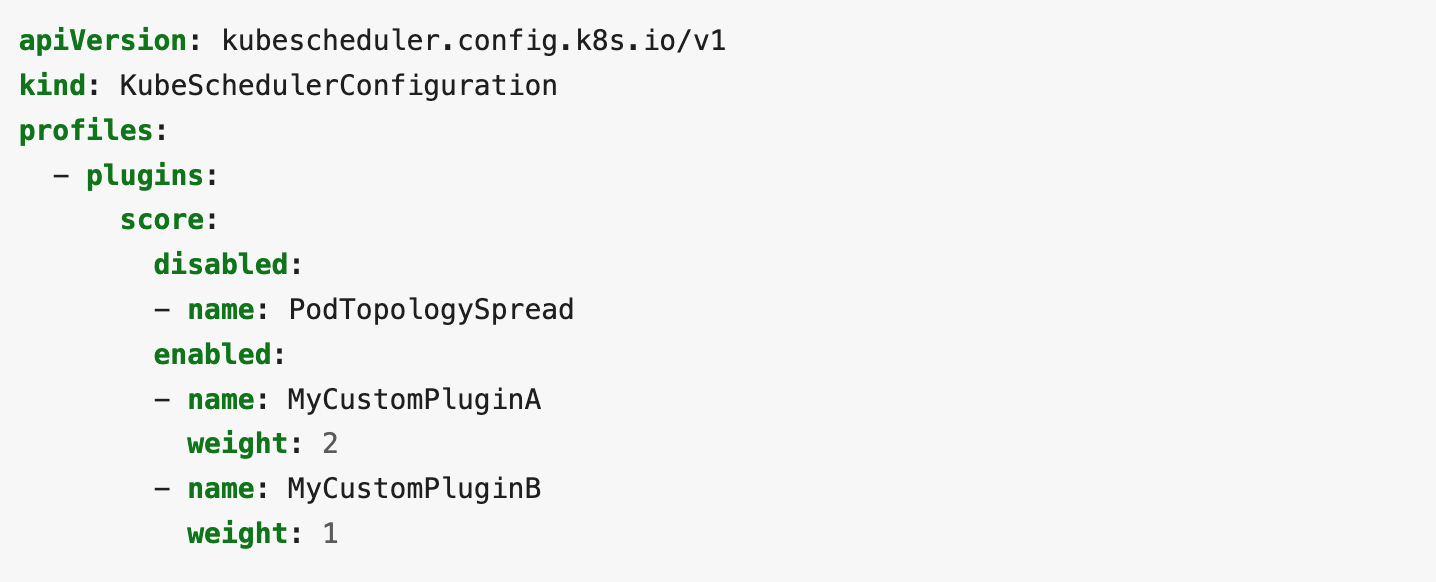
(公式ドキュメントから引用)
しかし、この指定方法には一点問題がありました。
それは、例えばPodTopologySpreadを無効にしたい場合、PodTopologySpreadが動作するPreFilter、Filter、PreScore、Scoreの拡張点全てのdisableにPodTopologySpreadと記載する必要があることです。
例えば、PodTopologySpreadが新しいKubernetesのバージョン(v1.X.0)でPermit拡張点でも動作するようになったとします。その場合、ユーザーはPodTopologySpreadを完全に無効にするために、Kubernetesのバージョンをv1.X.0に上げるタイミングで、Permit拡張点にPodTopologySpreadと記載をする必要があります。
同様に、In-Treeのプラグインではない、カスタムプラグインを使用していた場合、そのプラグインが新たにPermit拡張点で動作するようになった場合、ユーザーはPermitにMyCustomPluginAと追記する必要があります。
このように「プラグインがどの拡張点で動作するのかを、ユーザーが意識する必要がある」ということは、明確に意図せぬ挙動を引き起こしやすい点で問題でした。

そこでKubernetes v1.23にてmultiPointという新たなフィールドが追加されました。これを使用することで、プラグインを拡張点に関わらず有効化/無効化することができるようになります。
上記では、”foo”プラグインと”bar”プラグインがmultiPointにて有効化されており、それぞれのプラグインが動作する全ての拡張点で有効化されます。
これにより、先ほどのようにKubernetesやカスタムプラグインのバージョンを変更する際に、拡張点のことを気にする必要がなく、ただmultiPointに記載しておけば良いということになります。
KEP-3521: Pod Scheduling Readiness (WIP)
KEP-3521: Pod Scheduling Readiness
こちらのKEPには大きく分けて二つの内容が含まれています。
- Podに.spec.schedulingGates のフィールドの追加
- PreEnqueue 拡張点の追加
こちらは、v1.26でリリース予定の機能になります。(執筆段階ではv1.26はまだリリースされていません。)
Podに.spec.schedulingGates のフィールドの追加
v1.25以前のスケジューラーはPodが作成されると、Podのスケジュールをすぐに開始します。
Podがスケジュール不可能と判断されると、その後も何らかのクラスター内の状態変化などをきっかけに、度々スケジューラーのキューに戻されてはスケジュールが試行されます。
これらのことから分かるようにスケジューラーは、スケジュール不可能と判断されたPodを持ち続けるので、そのPodへのスケジュール試行を無駄に行うことになるため、効率が悪いです。
この.spec.schedulingGatesは、他のコントローラー等からPodがスケジュール不可能であることがわかる場合、そしてスケジュール可能になるタイミングがわかる場合に、スケジューラーにそのことを知らせることで、スケジューラーの無駄な試行を減らし、パフォーマンスを向上させるために導入されました。
そのPodがスケジュールされる準備がされているかどうかを表すschedulingGatesというフィールド(型: []string))が追加されます。
このフィールドが空ではないPodはスケジューリングの準備が整っていないPodとして扱われ、スケジューラーはそのPodのスケジュールを試みません。
schedulingGatesは減らす操作のみが許可されており、schedulingGatesが空になると、スケジューラーはそのPodがスケジュール可能になったと判断し、スケジュールの試行を始めます。
PreEnqueue 拡張点の追加
スケジューラーのキューに追加される前に常に実行されるPreEnqueueという拡張点が追加されます(詳細に言うと、SchedulingQueueの内activeQの追加前に実行されることになります)。
PreEnqueue プラグインがSuccessではないステータスを返すと、そのPodはスケジュール不可能なPodとして置いておかれることになり、結果としてスケジューリングが試みられません。
前述の.spec.schedulingGatesはPreEnqueue拡張点で実行されるSchedulingGatesプラグインとして実装されています。
KEP-3022: min domains in Pod Topology Spread
KEP-3022: min domains in Pod Topology Spread
Pod Topology Spreadに対して、最小のドメイン数を意味するminDomainsと言うフィールドが追加されます。v1.24にalpha、v1.25でbetaとなりました。
Pod Topology SpreadはNode、Zone、RegionなどのNodeの集合(= ドメイン)に対して、Podを均等に分散させて配置するためのスケジューリング制約です。
https://kubernetes.io/docs/concepts/scheduling-eviction/topology-spread-constraints/
minDomainsの導入以前、Pod Topology SpreadはmaxSkewを用いてドメイン間のlabelSelectorにマッチするPodの数の差を定義することしかできませんでした。
このminDomainsは、Podの数ではなくドメインの数自体を調整しようという試みになります。この機能はCluster Autoscalerとの併用を前提に考えられた機能です。
minDomainsよりもドメインの数が少ない場合、Podはスケジュールに失敗します。Podがスケジュールに失敗すると、Cluster Autoscalerはスケジュールに失敗したPodがスケジュール可能になるようなNodeを追加します。それによって、ドメインの数が結果的に増えるといったシナリオを期待しています。
具体的な例を通して見ていきましょう。以下のtopologySpreadConstraintsを持つレプリカ数2のDeploymentが存在するとします。
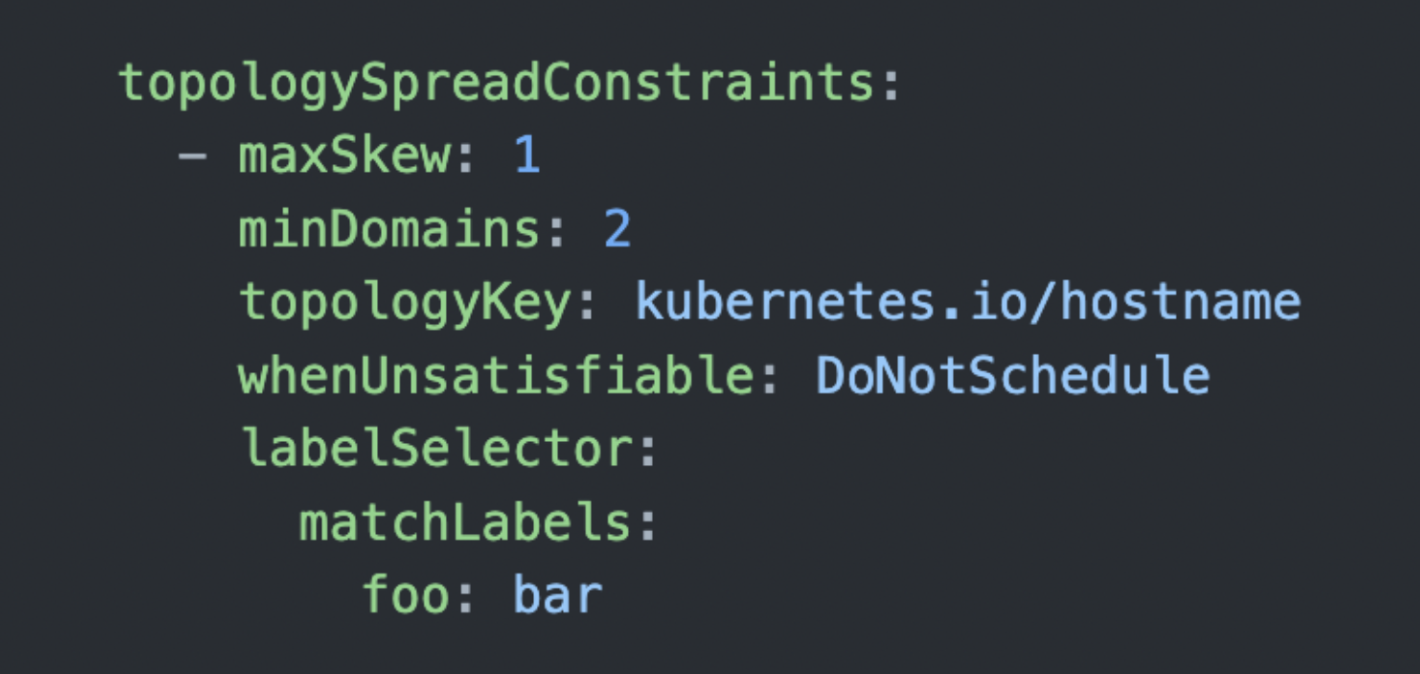
topologyKeyにkubernetes.io/hostnameの指定があるため、1つのNodeが1つのドメインとなります。
つまりこのtopologySpreadConstraintsは「2つ以上のNodeにlabelSelectorにマッチするPodをなるべく均等に配置していってくれ。Node間では、最大で1つのPodの数の差を許可する」と言う状態を表しています。
では、クラスターにそもそもNodeが1つしか存在せず、minDomainsの制約を満たすことができない場合を考えてみましょう。その場合、スケジューラーは1つ目のレプリカを現在存在するNodeにスケジュールしますが、もう一方のレプリカをスケジュール不可能と判断します。
Cluster AutoscalerはPodがスケジュール不可能となっていることに気がついて、Nodeを新たに作成します。
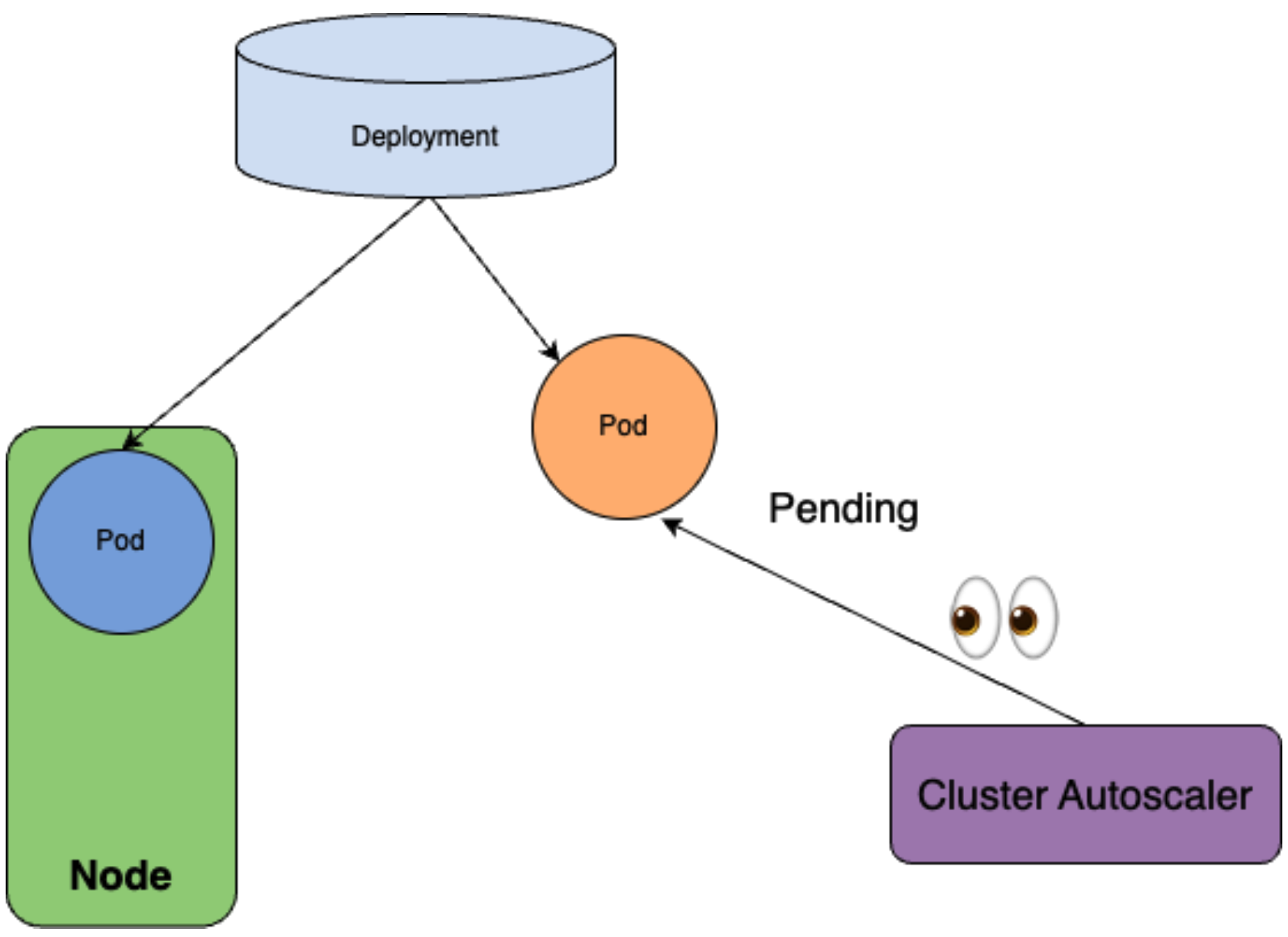
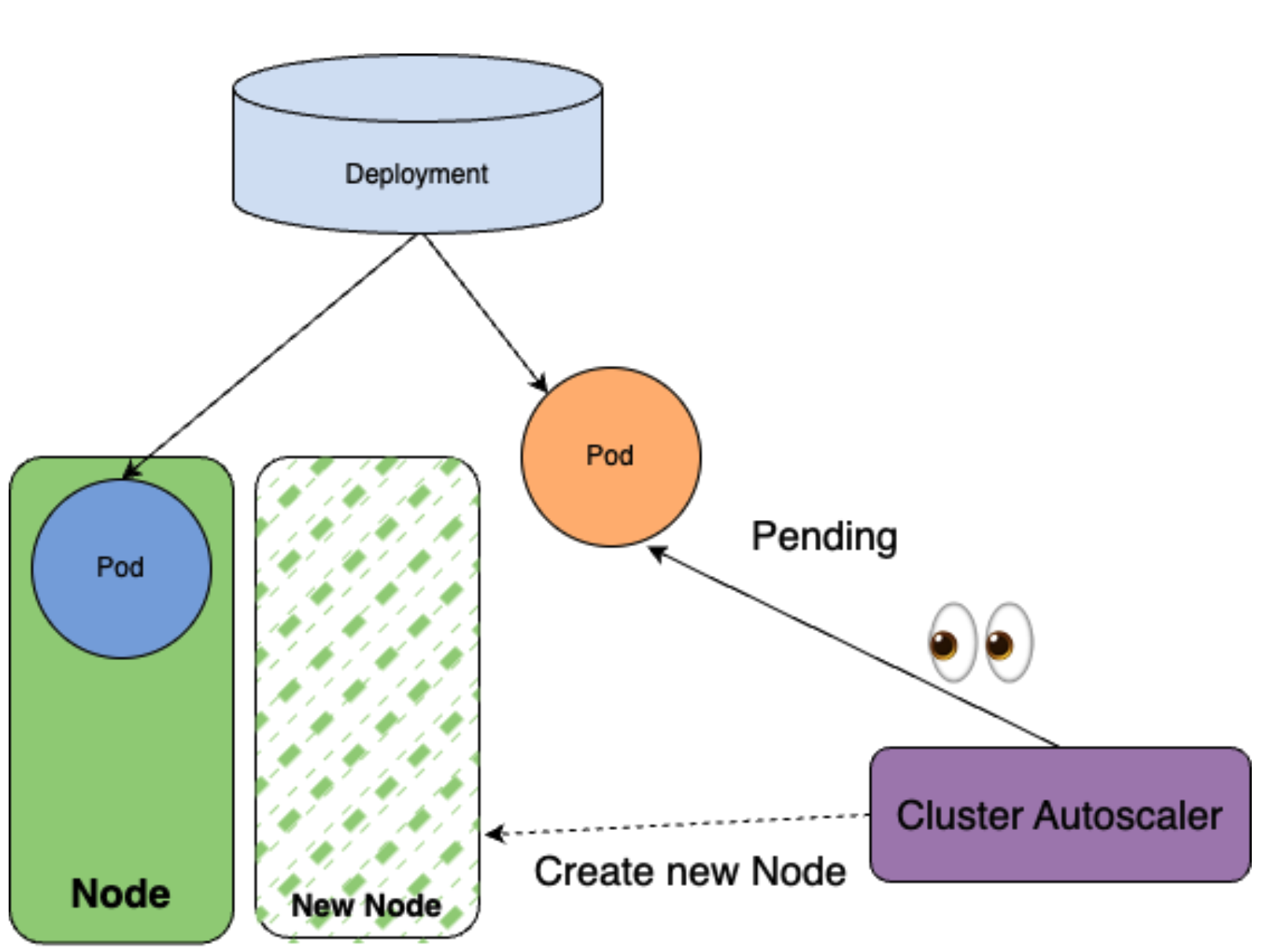
それによって、新たに作成されたNodeに2つ目のレプリカがスケジュールされます。
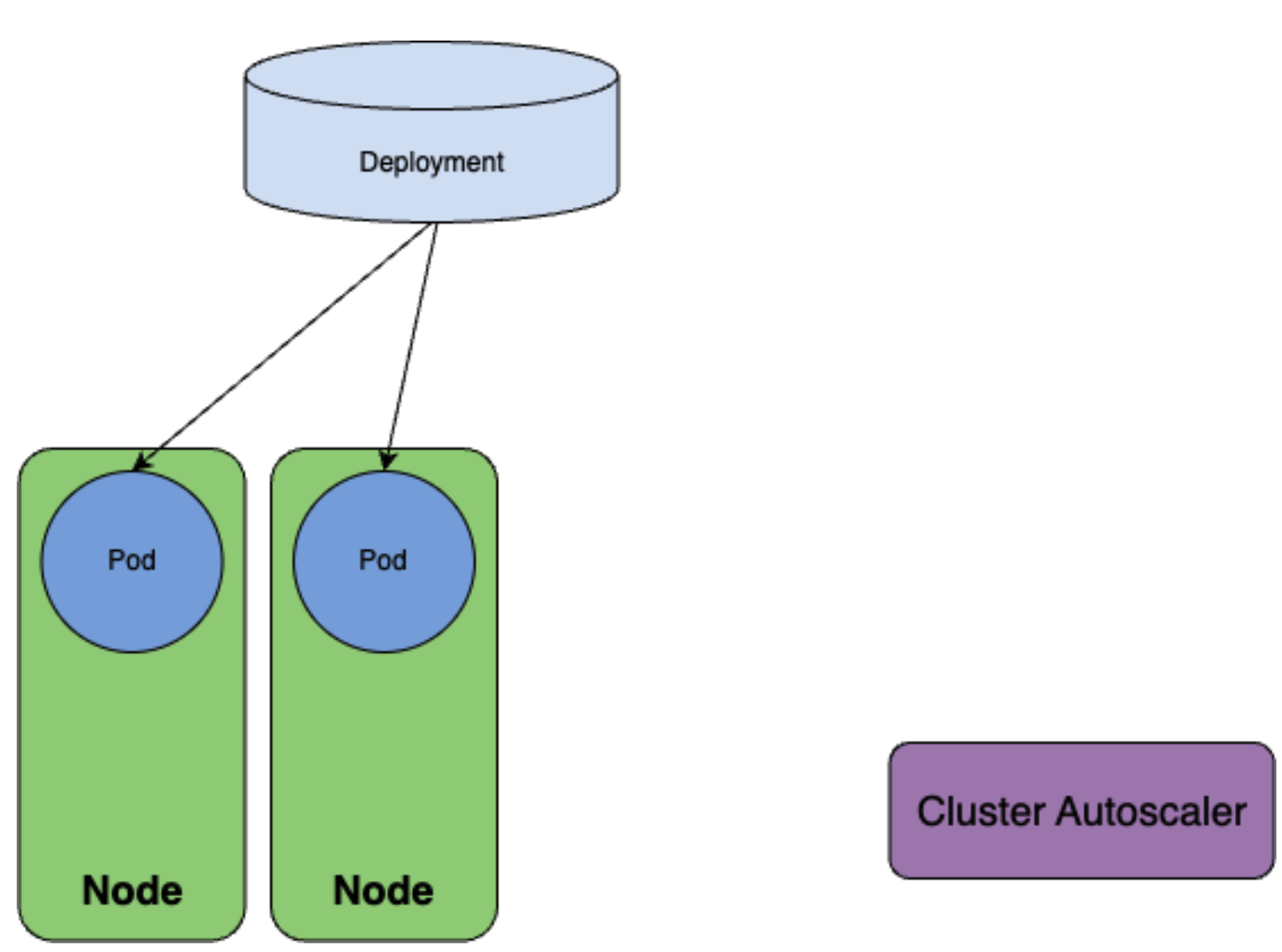
結果として、minDomainsに指定の通りに、Cluster Autoscalerを通してドメインの数を増やすことができたことが理解できると思います。
さらにPod Topology Spreadの実装面からこの機能を深掘りしてみていきましょう。
Pod Topology Spreadは以下のような計算を行ってmaxSkewを元にNodeのフィルタリングを行います。
('existing matching num' + 'if self-match (1 or 0)' - 'global min matching num') <= 'maxSkew'- existing matching num: そのNodeが存在するドメインに現在いくつ対象となるPodが存在するか
- self-match: そのPodのlabelがPod Topology Spreadの対象であるか
- global min matching num: 全てのドメインのうち、最も対象となるPodを持っている数が少ないドメインの、対象となるPodの数
簡単に言えば、「PodをこのNodeにおいた時に、maxSkewに違反する状態にならないかどうか」をみているわけです。
また、Pod Topology Spreadでは後述のnodeAffinityPolicyとnodeTaintsPolicyによって、対象とするNodeを制限することができ、「PodのnodeAffinityにマッチするNodeのみを対象にする」「PodがTolerationsを持たないNodeを除外する」といった条件付けをすることができます。
ここで例えば、Pod Topology Spreadを用いて、複数のzone(zone1 – zone3)にPodsを分散させたいとします。しかし、zone3にPod Topology Spreadの対象となるNodeがなかった場合、どうなるでしょうか。この場合、Pod Topology Spreadはそのドメインの存在自体に気がつくことができません。上記計算式で言うと、global min matching numを算出する際に、zone3が考慮に入れられないことになります。
つまり、簡単に言うと、zone3が存在するということをPod Topology Spreadは気がつくことができず、zone1とzone2のみにPodを分散させようとしてしまうと言うイメージです。
実装面からすると、minDomainsは、このような「見えないけど存在するドメインをPod Topology Spreadに認識させる」ための機能と見做すことができ、minDomainsに違反する状況の場合Pod Topology Spreadはglobal min matching numを常に0として、maxSkewの計算を行います。
例の場合、minDomainsに3を指定していたとして、現在zone1とzone2しかPod Topology Spreadは認識していないため、global min matching numは常に0と見做され計算されることになります。すると、Podはzone1とzone2にmaxSkewに違反しない範囲でスケジュールされていくのですが、global min matching numは0のままなので、どこかでPod Topology Spreadがzone1とzone2の全てのNodeを拒否するタイミングが訪れます。例えば、maxSkewが1の場合は、zone1とzone2にPodが一つずつ置かれた時点で、他のPodはスケジュール不能になります。
Cluster Autoscalerは内部でスケジューラーのスケジューリングをシミュレートして、スケジュールが不能となっているPodがスケジュール可能となるNodeを新たに作成します。そのため、この場合、zone3にPod Topology Spreadの対象となるNodeを追加してくれます。
この例から、Pod Topology Spreadを通して、複数のドメインに確実にPodを分散させて、障害に本当に強くするためには、minDomainsが強い味方になると言うことが、理解してもらえたでしょうか。
実際に弊社は複数のzoneの上でクラスターを構成しているため、全てのマイクロサービスが複数のzoneにPodを持つ状況を強制できれば、zoneの障害に対してサービス全体が強くなることから、minDomainsの使用を検討していきたいと考えています。
KEP-3094: Take taints/tolerations into consideration when calculating PodTopologySpread skew
KEP-3094: Take taints/tolerations into consideration when calculating PodTopologySpread skew
Pod Topology Spreadに対して、nodeAffinityPolicyとnodeTaintsPolicyと言う2つのフィールドが追加されます。v1.25にalpha機能として追加され、v1.26でbetaとなる予定です。
この機能以前はPod Topology Spreadは、NodeAffinityは考慮に入れるが、Nodeについているtaintsは考慮に入れないという状態でしたが、この機能を通してそれらの個別の設定が可能になります。
背景として、Pod Topology Spreadはドメイン間のPodの数がmaxSkew以下になるようにスケジュールを行うため、taintによってPodがスケジュールされてないNodeがあると、Pod Topology SpreadはそのNodeにPodをスケジュールしようとしてしまい、結果としてPodがどこにもスケジュールできなくなるという問題点がありました。
以下の例を見ていきましょう。
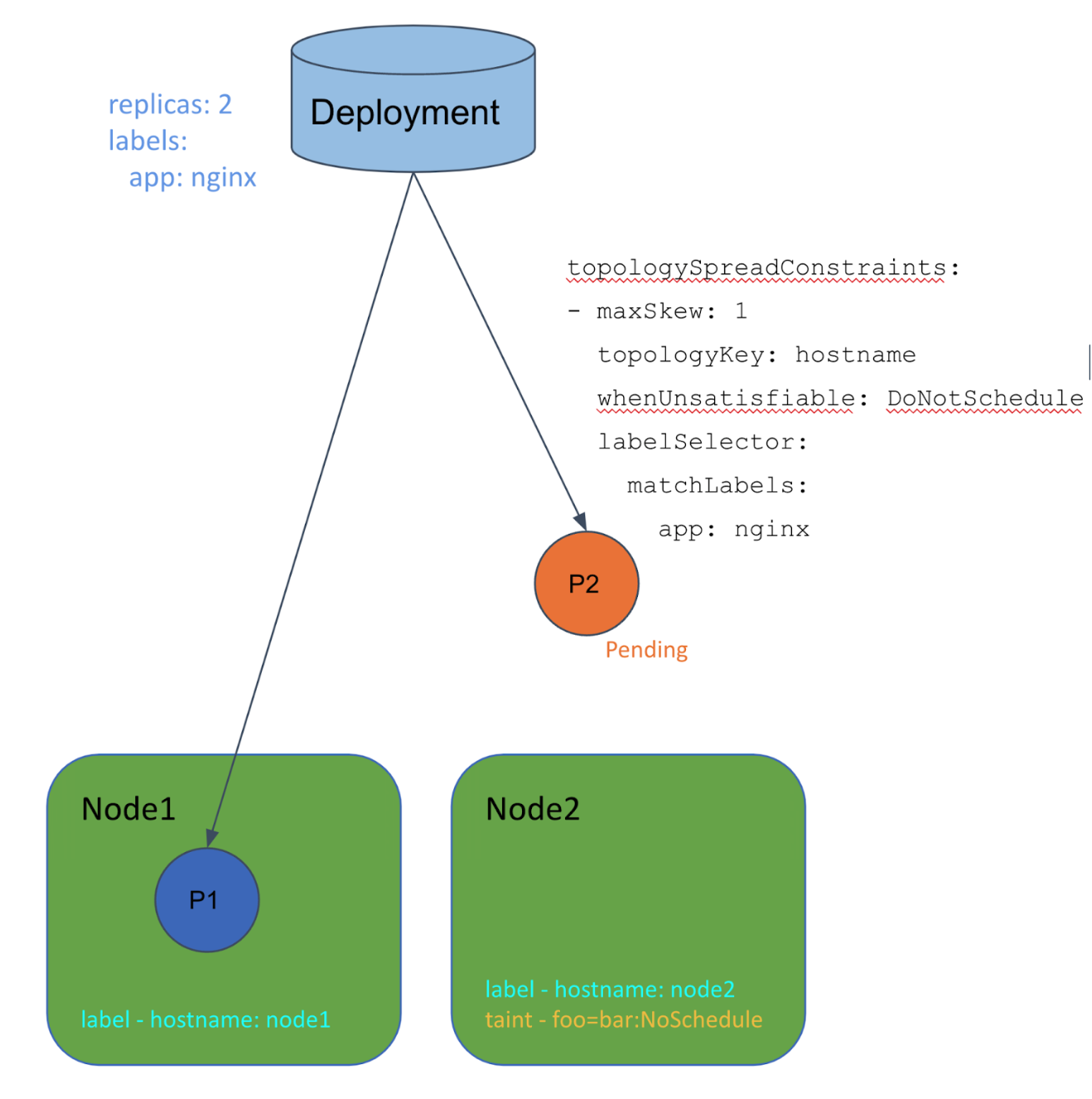
この例では、whenUnsatisfiable: DoNotScheduleとtopologyKey: hostnameが指定されたtopologySpreadConstraintsを持つDeploymentと、taintを持っているNode、持っていないNodeが一つずつ存在します。
前述のように、Pod Topology Spreadではtaintを考慮に入れません。すなわち、taintを持っているNodeをPod Topology Spreadは通常のNodeと同様に扱います。
すると、例のように、Pod Topology SpreadはNode2にPodをスケジュールしたいが、許可されていないtaintがNode2に付いているため、スケジュールできないと言う場合が発生します。この問題はNode2が削除されたり、taintが外れるまで解決しません。
taintは常にどのNodeに対しても使用される可能性があることを考慮すると、上記のような意図しないUnschedulableなPodに繋がりかねないtopologyKey: hostname + whenUnsatisfiable: DoNotScheduleの使用は避けざるを得ないような状況でした。
そこで以下のようにnodeTaintsPolicyにHonorを設定します
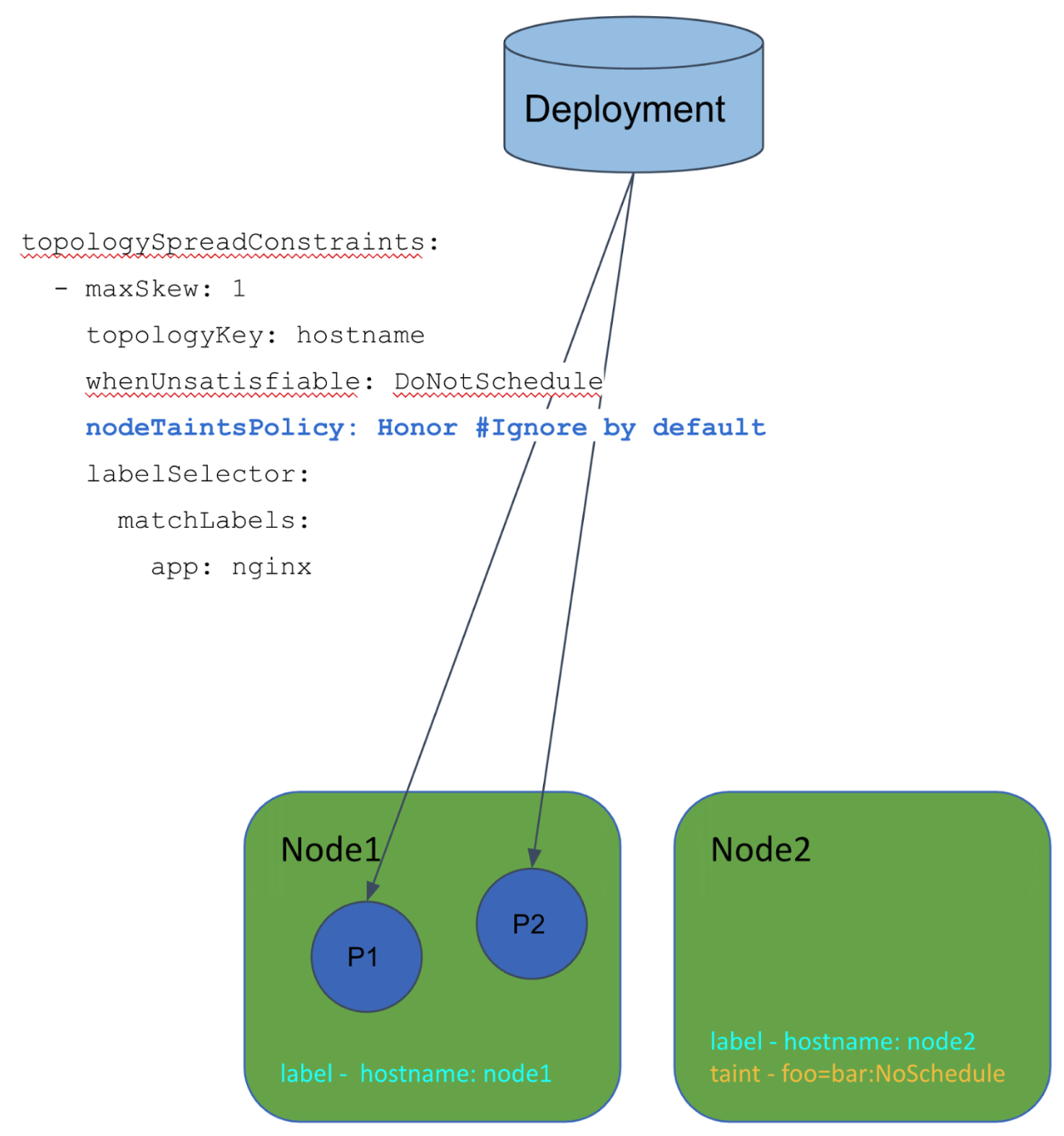
これにより、Pod Topology Spreadはtaintが付いているNodeを無視するようになるため、Node1へのPodのスケジュールが可能になります。
KEP-3243: Respect PodTopologySpread after rolling upgrades
KEP-3243: Respect PodTopologySpread after rolling upgrades
Pod Topology Spreadに対して、matchLabelKeysと言うフィールドが追加されます。v1.25にalpha機能として追加されました。
この機能の背景には、DeploymentのRolling Upgradeが関係しています。DeploymentのRolling Upgradeの最中、Pod Topology Spreadは古いバージョンのPodと新しいバージョンのPodを区別しません。
そのため、Rolling Upgradeを経て最終的に全ての古いバージョンのPodが削除された後に、topologySpreadConstraintsに指定した状態から離れた状態になってしまう可能性があります。
matchLabelKeysに指定されたLabelのKeyは、PodのLabelから値を取得するのに使用されます。取得された値はtopologySpreadConstraints内のLabelSelectorと共にPodのグループを認識するのに使用されます。
DeploymentのPodはpod-template-hashというラベルを持っており、どのReplicaSetから作成されたPodなのかを識別できるようになっています。このラベルを LabelSelectorに含めることで同じpod-template-hashの値を持つPodのみをPod Topology Spreadは認識することになり、結果として上記のRolling Upgrade時の問題を解決することができます。
Worth noting features/fixes
ここまではKEPになるようなレベルの大きな変更を紹介してきましたが、他にもいくつか興味深い変更が入っているので紹介します。
Performance improvement on DaemonSet Pod’s scheduling latency
Update PreFilter interface to return a PreFilterResult #108648
このPull Requestは大きく二つの変更を含んでいます。
まず、PreFilter プラグインがPreFilterResultと呼ばれる構造体を返却するように変更されました。このPreFilterResultのなかには下流の拡張点で評価されるべきNodeのリストを含むようになっており、下流での無駄なプラグインの実行を減らすことができます。
2つ目にDaemonSetのPodのためのNodeAffinityのPreFilterの変更です。
DaemonSetのPodはNodeAffinityを通して特定のNodeにそれぞれスケジュールされるように作成されます。NodeAffinityのPreFilterでそのような特定のNodeのみが許可されるようなNodeAffinityが指定されていることを検知し、PreFilterResultでそのNodeのみを返すことで、下流の拡張点でそれ以外のNodeへのプラグインの実行を減らすことができるようになりました。これによってDaemonSetのPodのスケジュールのパフォーマンスが改善されました。
Fix memory leak on kube-scheduler preemption
Fix memory leak on kube-scheduler preemption #111773
こちらはPreemption時のメモリリークの修正です。
スケジューラーは基本的にはループのような形で、常にSchedulingQueueからPodをPopして、スケジュールしてを繰り返しています。そして、スケジューラーが実行されている間常に生存し続けるcontextが存在していました。このメモリリークではそのcontextからcontext.WithCancel(ctx)を使用した子contextが作成されており、その子contextがcancelされていなかったことにより発生していました。
以下に記載のあるように、cancelを実行し忘れていた場合は、親contextは自身がcancelされるまで、子contextを持ち続けるため、子contextはGCされません。
Calling the CancelFunc cancels the child and its children, removes the parent’s reference to the child, and stops any associated timers. Failing to call the CancelFunc leaks the child and its children until the parent is canceled or the timer fires.
https://pkg.go.dev/context
この修正のPull Requestは他のバージョンへも取り込まれました。また、現在はスケジューラーは同じミスを防ぐために、別のPull Requestにて、スケジューラーが実行されている間常に生存し続けるcontextを下流の関数に渡さないようにリファクタリングされました。
fix(scheduler): split scheduleOne into two functions for schedulingCycle and bindingCycle #111775
Flush internal unschedulablePods pool every 5m (from 60s)
Set PodMaxUnschedulableQDuration as 5 min #108761
現状SchedulingQueueの中には2種類のキューと1つのPod poolが存在します。activeQ、backoffQ、Unschedulable Pod poolです。
一度スケジュールが試みられて、スケジュール不可能と判定されたPodはUnschedulable Pod poolに移動されます。そこからスケジューラーは、Podをスケジュール可能にするかもしれない事象が発生した場合(Nodeの作成等)に、再度PodをactiveQやbackoffQに移動し、再度スケジュールを試みます。
また、定期的に全てのUnschedulable Pod poolのPodをactiveQやbackoffQに移動させることもしています。
このPull Requestは定期的な移動のデフォルトの時間を60秒から5分に延長するという変更です。そして、将来的にはこの定期的な移動を削除しようということを計画しています。
これは、理想的にはPodをスケジュール可能にするかもしれない事象が発生した場合の移動のみでPodの移動は十分なはずであるためです。(ただし、実際にはいくつか細かな問題が見つかっているため、本当に削除されるのは先になると思われます。)
Component Config in kube-scheduler is stable now
Graduate component config to stable in kube-scheduler #110534
スケジューラーにはKubeSchedulerConfigurationと呼ばれる設定が存在することを、先の章で紹介しましたが、それがv1.25でGAになりv1となりました。
The legacy scheduler policy config is removed in v1.23
remove scheduler policy config #105424
KubeSchedulerConfigurationのGAに先立ち、legacyなscheduler policyの設定がv1.23にて削除されました。KubeSchedulerConfigurationへの移行の必要があります。
Kube-scheduler-simulator
この章からはSIG/Schedulingのサブプロジェクトの紹介を行います。
kubernetes-sigs/kube-scheduler-simulator
スケジューラーは内部に存在する多くのプラグインから成っており、一つのPodのスケジュールには全てのプラグインの結果が影響するため、「Podの行き先」というスケジューラー全体としての決断だけを見た時に、その理由が見えにくい場合があります。
現状のスケジューラーにおいては、ログレベルをかなり上げた場合に出力されるログのみが、スケジューラーのプラグインごとの結果の詳細を見ることができる方法です。ログを見るには強い権限が必要ですし、そもそもログレベルを上げることはスケジューラーのパフォーマンスの悪化に繋がり、正直本番運用中のクラスターで行うことは現実的ではないでしょう。
Kube-scheduler-simulatorは一年前の夏に始まったプロジェクトで、その名の通り、スケジューラーのSimulatorです。簡単にスケジューラーのプラグインレベルのスケジュールの結果を見ることができるという特徴があり、Simulatorの実行にはKubernetesクラスターすら必要がありません。
Simulatorにはkube-apiserver、スケジューラー、いくつかのcontrollerが内包されており、そのkube-apiserverに対してリソースを作成したりすることでスケジューラーの振る舞いを見ることができます。
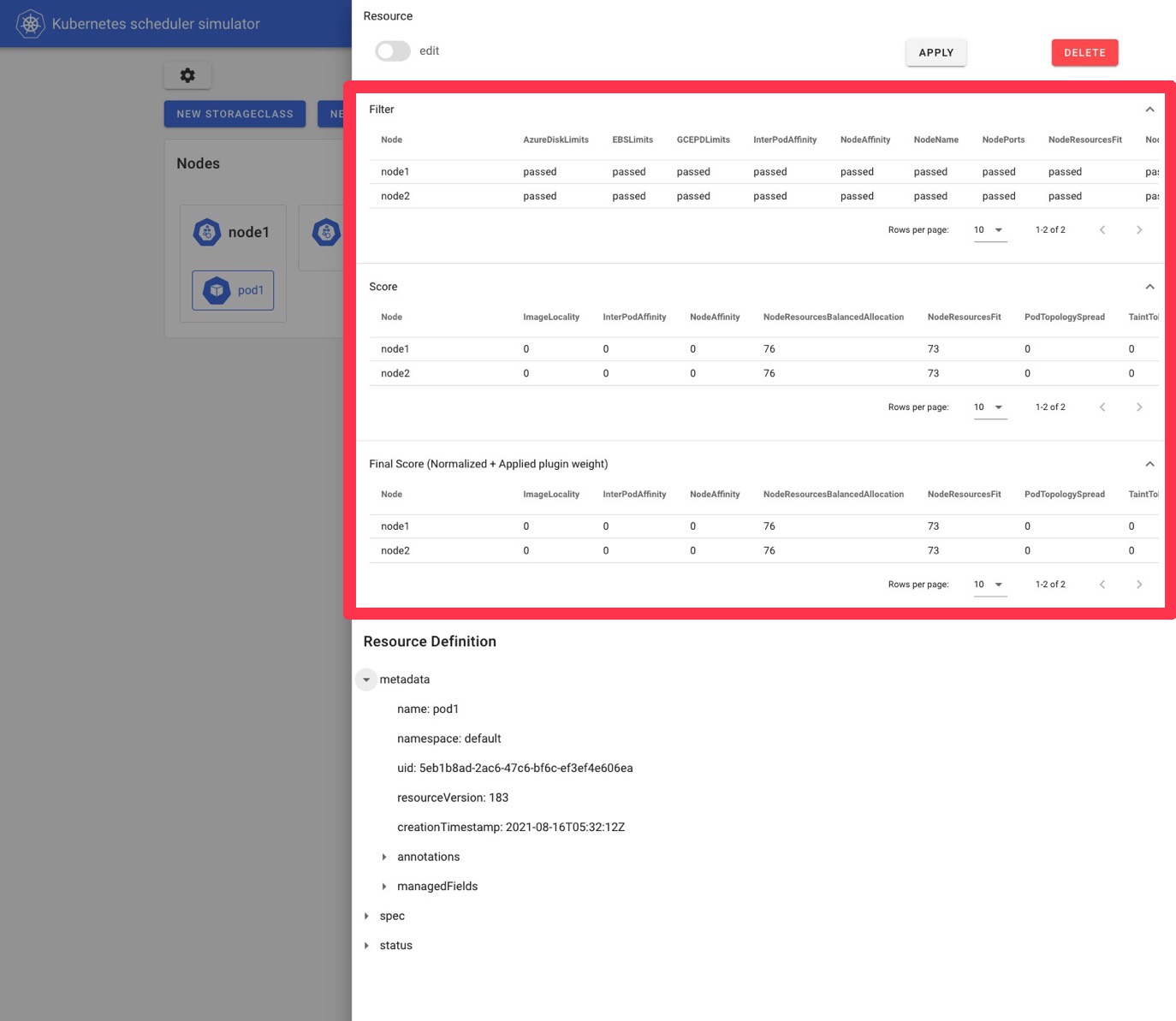
このように、Podを作成した時に、そのPodのスケジュールの際のFilter, Scoreなどのプラグインの結果を見ることができると言うのが基本的な機能になります。(Filter, Score以外のプラグインへのサポートの動きもあります)
また、このようにWebUIを使う必要は必ずしもありません。Simulator内部のkube-apiserverには、kubectlやclient-goなど、任意のKubernetes clientを使用してやりとりできます。上記に表示されているスケジュールの結果はPodのannotationから読み取ることができます。
現在Simulatorはファーストリリース(v0.1.0)に向かって開発が進んでおり、また、Scenario-based simulationの機能など、いくつかの大きな機能も議論されています。
Kueue
Kueueは比較的新しいプロジェクトで、Batch jobを単位とするJobのキューイングをするコントローラーを中心とするものです。wg-batchによって開発されています。
主に以下の機能があります。
リソースの割り当て管理: 誰がどのリソースを最大どれだけ使用できるのかを管理する
テナント間での公平なリソース共有: クラスター全体としてリソースを公平に使用するために、活発でないテナントに割り当てられている使用されていないリソースは、活発なテナント間で公平に共有される
様々なリソース対応: GPU, CPUなどのアーキテクチャや、spot, on-demandなどのプロビジョニングモデルなど、様々なリソースに対応する
キューイング戦略:
StrictFIFO: First In First Outです。
BestEffortFIFO: 基本的にはFirst in First outですが、古いworkloadは実行できないけど、新しworkloadが実行可能な場合そちらを先に実行する。
以下のドキュメントにKueue内のそれぞれのAPIの説明があるので参照してください。
https://github.com/kubernetes-sigs/kueue/tree/main/docs/concepts
Descheduler
スケジューラーはPodの作成時にどのNodeで実行するかを決定しますが、Kubernetesのクラスターは非常に動的であり、状況は刻一刻と変化していきます。
例えば、PodAffinityを指定して作成したPodも、スケジュール時は指定したPodと共に同じドメインに存在することが保証されますが、それだけです。数秒後にはその指定したPodが削除されている可能性もあります。
そこで登場するのがDeschedulerです。Deschedulerは現在のクラスターの状態を参照して、不適当な場所に存在するPodをevictすることを目的としており、スケジューラーによってそのようなPodが再度適当な場所にスケジュールし直されることを期待しています。(ReplicasetなどによってPodが管理されていることを前提としています)
どのようなPodを不適当な場所に存在するPodと見做すかはDeschedulerPolicyという設定を通して変更ができます。
では、いくつかDeschedulerの主な最新アップデートを見ていきましょう。
Descheduler Framework Proposal #753
こちらは、内部的なアーキテクチャの大きな変更になります。この提案はDeschedulerをDescheduler Frameworkと呼ばれる拡張点を複数持ったアーキテクチャに変更し、Scheduling Frameworkのようにプラグインの形で各戦略を実装する試みになります。
現在内部的な変更が続々と進んでおり、将来的にはこれによってまさにスケジューラーのようにプラグインの形で独自のロジックを実装したりすることができるようになります。
feat(leaderelection): impl leader election for HA Deployment #722
こちらはHigh AvailabilityのためにDeploymentを使用する際のleader election機能の追加です。
Limit the maximum number of pods to be evicted per Namespace #656
DeschedulerにはNode内のどれだけの数のPodを同時にEvictして良いのかを定義するmaxNoOfPodsToEvictPerNodeという設定が存在しました。このPRでは新たにNamespace内のどれだけの数のPodを同時にEvictして良いのかを定義するmaxNoOfPodsToEvictPerNamespaceが実装されました。
Kwok (Kubernetes WithOut Kubelet)
Kwokもかなり新しいプロジェクトで、本物のように振る舞う偽物のNodeを作成することができます。
実際に本物のNodeを立ち上げることなく、Nodeを使ったテストや動作確認などを行いたい時に使用することができます。Podも同様に実際にNode上で動作しているかのように振る舞います。
Scheduler-plugins
kubernetes-sigs/scheduler-plugins
スケジューラーのロジックはそれぞれプラグインという形で実装されていることを最初に紹介しました。プラグインはスケジューラー内部にデフォルトで存在するものの他にも、独自のプラグインを実装し外部から簡単に組み込むことができるようになっています。(ただし、スケジューラーのコードの一部の変更が必要なため、スケジューラーをビルドし直す必要があります)
このscheduler-pluginsには、コミュニティとしてメンテナンスしているデフォルトでupstreamのスケジューラーに組み込まれていないプラグインが置かれています。
それぞれのプラグインの紹介をここで行うとすごく時間がかかるので割愛しますが、もし「自分の欲しい機能がスケジューラーに存在しない」という場合は、このリポジトリを覗いてみると、要件に見合ったものが存在したり、解決に繋がるアイデアが見つかるかもしれません。
セッション全体に対する感想
ここまででセッション中に紹介された内容の全ての説明が終了しました。ここからは少し個人的な見解を含めて軽く総括をしたいと思います。
まず、Upstreamの変更に関しては、スケジューラーはPod Topology Spreadに関連する機能の追加が目立ちました。NodeAffinityPolicyやNodeTaintsPolicy、MatchLabelKeysは広く影響のあるPod Topology Spreadの喜ばしくない振る舞いを修正するために必要な変更であり、Pod Topology Spreadを使用する際にはこれらを使用することを考慮することが必須となるでしょう。
その他の変更の中だと、SchedulingGatesと共に導入されたPreEnqueueプラグインには個人的に大きな可能性を感じています。これまで、プラグインがScheduling Queueの振る舞いを細かく制御するようなことはできなかったので、このPreEnqueueを使用してスケジューラーのパフォーマンス等を向上させるような施策が可能な場合があると思います。
Sub Projectsの中で最も今活発と言えるのはKueueではないでしょうか。
Kubernetes を機械学習等batch jobs向けのクラスターで使用しようという試みは国内外でいくつか存在し、スケジューラーの拡張しどのようにbatch jobを効率的にスケジュールしていくかというのは興味深い課題です。
Kubernetesでもそのようなbatchのワークロードに対応していこうという試みを持って、wg-batchが誕生し、Kueueが開発されています。
現状は執筆段階でv0.2系が最新であり、まだまだ若いプロジェクトですが、今後の動向が楽しみです。
Kubernetes contributer award
Contributor summitでは、Kubernetes contributer awardという章を頂きました、光栄です。
https://www.kubernetes.dev/community/awards/2022/#scheduling
Wow, I got Kubernetes contributor award this year!
I'm beyond honored to receive it! Thanks #KubeCon pic.twitter.com/L8ikZU58SQ— さんぽし/sanposhiho (@sanpo_shiho) October 25, 2022



