
この記事は、Merpay Advent Calendar 2022 の4日目の記事 メルカードの舞台裏編 です。
こんにちは。メルペイでバックエンドエンジニアをしている @hiroebe です。
メルペイのバックエンドではマイクロサービスアーキテクチャを採用していて、今回のメルカード開発でも新たに専用のマイクロサービス (メルカードマイクロサービス) を開発しました。この記事では、現在のメルペイにおいて新たにマイクロサービスを開発する際のプロセスについて、チーム内での取り組みや実際にやってみた感想を交えて紹介します。
なおメルカードマイクロサービスの役割については、2日目の記事「メルカードのマイクロサービスとカード利用開始まで」および3日目の記事「クレジットカード取引とメルカードマイクロサービスについて」をご覧ください。
Design Doc
新しいサービスをつくるにあたって最初に行うのが Design Doc の作成です。実際に開発を始める前に、背景や目的、システムの設計などをドキュメントにまとめ、必要なチームにレビューを依頼します。
社内では Design Doc は対象サービスに対して1人の担当者が1つにまとめて作成することが多い印象ですが、今回のメルカード開発ではサービスの規模を考慮して、決済や申し込みといった機能ごとに担当者をわけて Design Doc を作成しました。特にカード情報の取り扱いについては、Security チームから手厚くレビューを受けて実装方針を決定しました。
マイクロサービスの立ち上げ
社内にある多くのマイクロサービスと同様、実装には Go 言語を用いました。社内には mercari-echo-jp というテンプレートプロジェクトが用意されており、これをもとにすることで、マイクロサービスのベースとなる実装や基本的な CI の設定、デプロイ用の Dockerfile などが揃った状態から開発を始めることができます。
また、同じくマイクロサービスの立ち上げをサポートする社内ツールとして、Microservice Starter-Kit という Terraform Module があります。これを利用することで、マイクロサービスとして必要な GCP プロジェクトや Kubernetes namespace といったインフラリソースをまとめて作成することができます。チームの管理には、同じく社内製 Terraform Module の Microservice Team-Kit を使用しています。これを用いることで、チームメンバーに付与する GCP や Kubernetes などの権限を管理したり、対応する GitHub team や PagerDuty team などを一括で作成したりすることができます。
基本的に新しいマイクロサービスを1から作るのは非常に労力のかかる作業なので、その立ち上げをサポートするこれらのツールは欠かせないものだと感じています。
コードレビュー
コードレビューについては、最低1人のチームメンバーからのレビューを必須とするルールにしています。開発初期はコードの追加量が多く Pull Request が肥大化しがちなので、レビューのしやすさの観点から、できるだけ Pull Request は分割することを推奨していました。もちろん、まとめて見ないと逆にわかりづらいような追加・修正もあるので、あくまで「Reviewer がレビューしやすいと思う粒度」を Author が考えて Pull Request を作成するよう、チーム内で認識合わせをしました。
一方で、Pull Request 単位の差分としてコードレビューを実施していると、あとから全体のコードを眺めたときに初めてリファクタリングが必要なことに気づく、ということがあります。感覚的には「1つや2つならこの書き方でいいけど、それが10個になるなら別の構成を考えたい」みたいなものです。もちろん各 Pull Request をレビューする段階でコードの全体像を見られるのが理想ですが、細かな差分が積もっていくとどうしてもこのような現象は避けられないと感じています。
これに対するチームでの取り組みとして、ある程度機能の実装が落ち着いたころに、既に実装されたコードを読んで実装に問題がないかレビューしていく時間を用意しました。機能開発が概ね完了したタイミングで実施したため、観点は上に書いたリファクタリング関連以外にも、
- 改めて見てロジック的にまずい箇所はないか
- ログ出力やエラーハンドリングの処理は一貫しているか
- TODO コメントはまだ TODO のままでよいか
といった部分を見ていきました。実際にレビューを実施してみると、
- リトライ処理がうまく実装できていない箇所が見つかったり
- 開発初期のコードでは適切にログが吐かれていなかったり (あるいは過剰だったり)
- TODO としてコメントを残していたが実際には不要だったものが残っていたり
といった大小さまざまな修正点が見つかりました。これらの修正点はチーム内で持ち寄り、いつまでに修正すべきものかを分類していく作業を行いました。
自動テスト
メルペイでは自動テストとして、Scenarigo を用いて記述したシナリオテストを定期的に自動実行しているケースが多く、メルカードサービスでも同じ仕組みに載せて自動テストを構築しています。ここの仕組みについては Scenario-Based Integration Testing Platform for Microservices で発表されています。テストが失敗した際は以下のような通知が Slack に送られるようになっていて、これが出たらその失敗原因を調査することになります。

今回の開発では、できるだけ早い段階から自動テストを動かすように取り組みました。開発初期からこのようなテストを用意すると、仕様変更が発生した際にテストケースを修正するコストが発生しますが、それ以上に次のようなメリットがあると感じています。
- 機能のデグレに気づくことができる
- 機能の追加に対してシナリオテストを追加・修正する習慣がつく
- 定期的に実行しておくことによって発見しやすくなる問題がある
1つ目が自動テストを走らせておく主要な目的かと思いますが、2つ目と3つ目にあげた点についても同じく重要であると感じています。
3つ目にあげた「定期的に実行しておくことによって発見しやすくなる問題」というのは、例えば他マイクロサービスへのリクエストがタイムアウトした際の処理などです。タイムアウトエラーは意図的に引き起こすのが難しく、自マイクロサービスの QA としてリクエストのタイムアウトを模擬的に再現したとしても、「こちら側で想定どおりのハンドリングができていること」までの確認になるケースが多いように思います。しかし実際の環境では、エラー時の処理が正しくないとマイクロサービス間で不整合が発生する可能性があり、それが発生しないことの確認 (= エラー時のハンドリングが適切であることの確認) はできるだけ本番に近い環境で実施したいです。このようなエラーは End-to-End の自動テストをある程度の期間実行し続けていると時々発生することがあるので、それを精査することでエラー時の処理が正しいことを確認することができます。
似たような話はエラー時のリトライ処理などでもあると思っていて、例えば「やたら特定の API 呼び出しで失敗しやすいと思ったら、リトライ処理が正しく実装されていなかった」という問題があるとしたら、それに気づくのにも自動テストを長期間走らせておくのは役立ちそうです。
ブランチ運用と QA 環境
複数機能の開発が並行で進んでいる場合、QA をどの環境で実施するかという問題があります。
開発初期の段階では、Pull Request はコードレビューが完了したものからメインブランチにマージし、メインブランチをテスト環境に出しておくような運用をしていました。考えていた Pros/Cons は以下です。
- Pros
- 単一のテスト環境で QA を実施するので、接続先を切り替える必要がない
- ソースコードのコンフリクトが起きづらい
- Cons
- テスト環境が壊れる可能性がある
この運用を選択した最も大きな理由は、ソースコードのコンフリクトをできるだけ避けたいというものです。開発初期の実装が活発なフェーズでは、QA のために Pull Request をマージせずに置いておくと、あっという間にメインブランチから取り残されてコンフリクトが発生してしまいます。これを都度解消するのは開発スピードを落とす一因になってしまうため、できるだけ Pull Request は早いタイミングでマージする運用としました。こうすると QA 未実施の変更が反映されることによってテスト環境が一時的に壊れる可能性がありますが、開発初期の段階ではこれは許容することにしました。

一方で、開発がある程度落ち着いてきてからは、Pull Request はコードレビューが完了し、かつ QA が完了してからマージする運用に変更しました。これによってメインブランチに QA 未実施の変更が入ることはなくなり、メインのテスト環境が壊れることは少なくなります。この運用では、QA はマージ前の Pull Request 上で実施することになります。社内には Pull Request ごとに複製環境を自動で作成し、そこに動的にリクエストをルーティングできるような仕組みが存在しており、今回の開発でもそれを利用して複数の QA を並行で進められるようにしました。ここの仕組みについては The World Is at Your Pull Request! – How to Make a Dynamic QA Environment on Kubernetes and Istio で詳しく発表されています。

Production Readiness Check
サービスを本番にリリースする前には、社内の Production Readiness Check を通す必要があります。本番環境で動くマイクロサービスが満たすべき項目がチェックリストとしてまとめられていて、例えばエラーを検知するためのモニター設定や、データベースのバックアップに関する項目なども含まれます。これらの項目がすべて満たされているのを確認することで、サービスは Production Ready な状態であると判断されます。この仕組みによって、本番環境で稼働するサービスが一定の水準に達していることを担保すると同時に、十分に準備ができていないサービスが本番環境に投入されるのを防ぐことができます。
項目は一部異なりますが、メルカリの Production Readiness Checklist は https://github.com/mercari/production-readiness-checklist で公開されています。満たすべき項目は自分たちのサービスの Production Readiness Level によって異なるので、まずはこの Level を決定してから具体的に各項目を見ていくことになります。
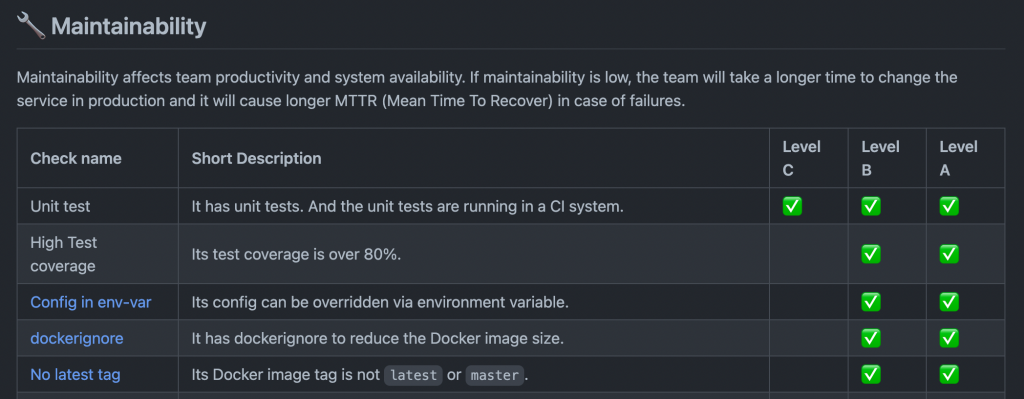
GitHub で公開している項目の一部
項目数がかなり多いため、今回はチーム内で各項目ごとに担当者を決めて作業を進めていきました。1マイクロサービスに対して1つの GitHub Issue を立てておいて、各メンバーはそれぞれ自分の担当するチェック項目を確認し、満たしていない場合は項目を満たせるように作業を、満たしている場合はそのエビデンスを貼っていきます。メルペイではこれらのチェック作業自体は開発チームが行い、チェックが完了したら SRE にレビューを依頼するというルールになっています。
また、今回新規サービスに対して Production Readiness Check を実施してみて、これらのチェック項目は開発初期の早い段階から意識しておくべきものだと感じました。Production Readiness Check 自体は、すべての開発が完了して実際に本番環境で稼働し始める前の「最終確認」のようなかたちで実施するものですが、そのタイミングで初めて項目に目を通すのでは遅い場合があります。
例えば Maintainability の1つとして「テストカバレッジが80%以上であること」という項目が含まれていますが、もしこの項目を意識せず、かつテストに対する意識が薄い状態で開発を進めてしまった場合、あとからテストカバレッジを上げるのはかなり労力のいる作業になります。また Reliability として負荷の見積もりに関する項目がありますが、負荷テストの実施にはある程度の時間がかかるので、これも早い段階から計画的にスケジュールを組んで実施する必要があります。
このように、Production Readiness Checklist は開発初期の段階から意識して見ておき、必要に応じて実装時のフローや開発スケジュールに反映させておくべきものであると思います。今回の開発でもある程度早い段階から目を通してはいましたが、それでも後になってからチェック項目を満たすための細かなタスクがポツポツと出てくることがありました。「これから開発を始める」というタイミングで、開発チーム内で一度読み合わせをするような取り組みもよさそうです。
おわりに
この記事ではメルカードマイクロサービスの開発プロセスについて紹介しました。これが開発プロセスのすべてではありませんが、マイクロサービスの開発を支えるための仕組みや、その他開発を進める中でのチーム内での取り組みについて、少しでも参考になれば幸いです。
明日の記事は、メルペイ バックエンドエンジニア hiraku さんの「決済システムを壊さずに拡張した話」です。引き続きお楽しみください。




