こんにちは、メルカリのレコメンドチームで ML Engineer をしている ML_Bear です。
普段はメルカリのホーム画面などに表示されるレコメンドパーツの改善を担当しています。今回はメルカリの莫大なユーザーログデータと、出品された商品に付与されているメタデータ(詳細後述)を活用したレコメンドロジック改善事例をご紹介します。
商品メタデータについて
メルカリではユーザーの商品検索体験を向上させるため、出品された商品に対して様々なメタデータを付与しています。ファッションアイテムだと色や生地感、家電だと型番といった、主として商品の属性をあらわす様々なデータをメタデータと呼称しています。
今回、私は本やマンガに紐づいているメタデータ (以下、タイトルデータと記載) に着目しました。
メルカリアプリ内では、本やマンガに商品が属するシリーズを表現するメタデータが付与されています。例えば「キングダム 1巻」「キングダム 2巻」「キングダム 25-50巻」「キングダム 全巻」といった商品には全て “キングダム“ というタイトルデータが付与されています。
他方、メルカリではユーザーが閲覧した商品のログは全て記録されています。
そして、そのログとタイトルデータを突き合わせつつ、Item2Vecというレコメンドの手法を利用することでユーザーの興味にあった本やマンガのレコメンドができないかと考え、改善を試みました。
Item2Vecの活用
自然言語処理で有名な手法の一つにWord2Vec[1]というものがあります。単語をベクトル化することで様々な処理を行えることを提唱した手法で、比較的枯れた技術であるものの、その汎用性の高さからか、現在も様々な研究や機械学習コンペティション等で利用されています。
それを商品のレコメンドに利用できるように転用したものがItem2Vec[2]という手法です。
実装も学習も比較的簡単なのですがそれなりの精度も出る、非常に使い勝手のいい手法のため、他社さんでも利用事例が紹介されています。ユーザーログが多くない場合は利用が難しいこともありますが、メルカリのように、莫大なユーザー数を抱え、膨大なログが日々蓄積されるサービスとは非常に相性がいいと個人的に思っております。
今回は以下のような方法を用いてレコメンドロジックを作りました。
-
作品ごとの類似度関係性の算出 (過去Nヶ月のデータを用いて月次でPython処理する)
a. 過去Nヶ月で本やマンガの商品を閲覧したユーザーを抽出
b. ユーザーの過去Nヶ月の商品閲覧履歴を収集
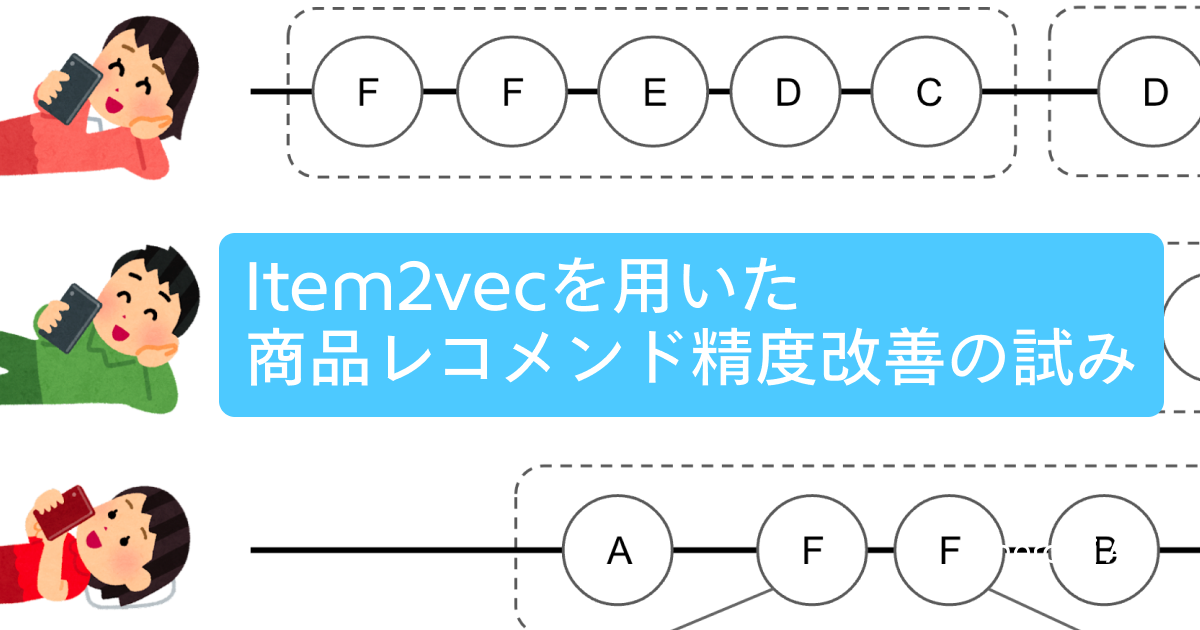
c.セッションごとに分割し、タイトルの羅列を抽出する
d.タイトルの羅列を文章、各タイトルを単語とみなして Item2Vec でタイトルのベクトルを算出
e.タイトルのベクトルを利用し、タイトル同士の関係性 (cos類似度) を算出
f.タイトル同士の関係性データをBigQueryに保管 -
ユーザーへのレコメンドの生成 (過去N時間のデータを用いて毎時BigQuery処理)
a. ユーザーの過去N時間の商品閲覧履歴のうちタイトルデータが紐づけられるものを抽出
b. 「ユーザーが閲覧した商品のタイトルに似ているタイトル」を算出
c. ↑で算出したものを「ユーザーへレコメンドするタイトル一覧」としてBigtableに格納
d. ユーザーがホーム画面来訪時、Bigtable内にレコメンドするタイトル一覧があればそのタイトルを検索してレコメンド商品リストとして表示

Fig1. 商品閲覧ログにタイトルを割り振りセッションに分割するイメージ図
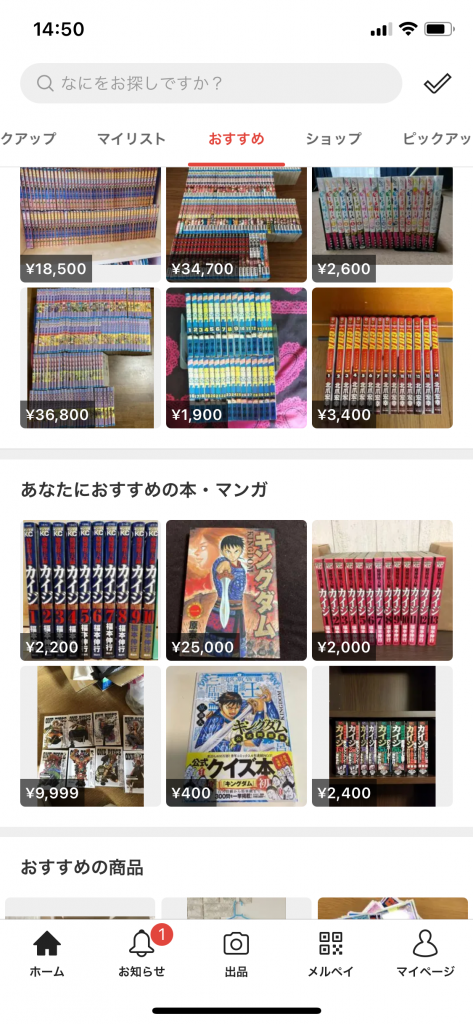
Fig2. 今回作成したレコメンドパーツ「あなたにおすすめの本・マンガ」
レコメンドデータの生成や、アプリで表示する際のシステムについて詳細は述べませんが、概要は以下の通りです。全てGCP上で処理しており、Googleさまさまという感じです。
- 商品閲覧ログ周りのデータ処理はほぼ BigQuery で実行 (数億行のログデータを処理するのはBigQueryを利用するのがお手軽簡単)
- Item2Vec の計算は Colab 上で Gensim を利用して処理
- データパイプラインは Cloud Composer (Airflow) を利用し、毎時 / 月次のデータ処理を実行する
- プロダクション環境でのデータストアはBigtableを利用
Item2Vecの結果について
Item2Vecで計算した結果をいくつかご紹介します。
以下、Gensim で計算したモデルの most_similar 関数を叩いた結果を表示しています。(数値は類似度です)
マンガ「ドラゴン桜」に似ているタイトル
1[('ドラゴン桜2 17 ', 0.8193),
2 ('エンゼルバンク : ドラゴン桜外伝', 0.6674),
3 ('東大へ行こう : ドラゴン桜公式ガイドブック', 0.628),
4 ('ドラゴン桜わが子の 東大合格力 を引き出す7つの親力 : 龍山高校 親力 特別...', 0.5366),
5 ('ドラゴン桜公式副読本 16歳の教科書2 勉強 と 仕事 はどこでつながるのか', 0.5265),
6 ('銀のアンカー : 内定請負漫画', 0.5145),
7 ('アルキメデスの大戦 ', 0.5118),
8 ('部長島耕作 : バイリンガル版', 0.5098),
9 ('インベスターz 全巻', 0.5034),
10 ('ドラゴン桜公式副読本 16歳の教科書 なぜ学び なにを学ぶのか', 0.4913),
11...三田紀房先生の作品が並ぶ中、入試関係の副読本が混ざっていたりしますね。私としても予期せぬ結果で非常に面白く思いました。
マンガ「正直不動産」に似ているタイトル
1[('不動産業者に負けない24の神知識', 0.5547),
2 ('初心者から経験者まですべての段階で差がつく 不動産投資 最強の教科書 投資家1...', 0.493),
3 ('クロサギ', 0.4731),
4 ('世界一やさしい不動産投資の教科書1年生 : 再入門にも最適 ', 0.4692),
5 ('業界で噂の劇薬裏技集 不動産大技林', 0.4675),
6 ('相続探偵', 0.4628),
7 ('不動産の未来 マイホーム大転換時代に備えよ', 0.4405),
8 ('クソ物件オブザイヤー', 0.4351),
9 ('やってはいけない不動産投資', 0.4313),
10 ('モンキーピーク', 0.4291),
11...(正直不動産でも原作を手掛けられている) 夏原武先生が同じく原作を手がけられているクロサギが出てきました。やはり同じ作者というのは関連性が高いんですね。また、こちらもマンガが並ぶ中に不動産関係の普通の本が並んでいて面白いです。
ちなみに相続探偵というマンガはこのテックブログを書いている今まさにこの瞬間に初めて知ったので、執筆を一旦止めて電子版を買って読んでみましたが、まぁまぁ面白かったです。正直不動産と作風が似ている感じも確かにしました。
小説「坂の上の雲」に似ているタイトル
2 ('世に棲む日日 全巻', 0.7067),
3 ('夏草の賦 上下', 0.6681),
4 ('梟の城', 0.6624),
5 ('壬生義士伝 上下', 0.6594),
6 ('花神 上中下', 0.653),
7 ('関ヶ原 上巻 中巻', 0.6471),
8 (' 織田信長 ', 0.647),
9 ('功名が辻 ', 0.6468),
10 ('徳川慶喜 最後の将軍', 0.6324),
11...司馬遼太郎先生の作品がずらっと並んでいますね
小説「下町ロケット」に似ているタイトル
1[('下町ロケット ゴースト ヤタガラス', 0.9246),
2 ('下町ロケット ヤタガラス ゴースト', 0.9115),
3 ('株価暴落', 0.8829),
4 ('新装版 銀行総務特命', 0.8819),
5 ('花咲舞が黙ってない', 0.8758),
6 ('仇敵', 0.8756),
7 ('新装版 不祥事 ', 0.8702),
8 ('鉄の骨', 0.8686),
9 ('金融探偵', 0.8614),
10 ('銀行仕置人', 0.8589),
11...こちらも池井戸潤先生の作品が並んでいます。メルカリで小説を探される方は、同じ作者のいろいろな商品をご覧になることが多いのかもしれません。
レコメンドロジックのABテスト
さて、Item2Vecが完成したので、(Book2Vecという名前もちゃっかりつけて) ABテストを回しました。
メルカリではあらゆる改善をABテストで定量的に評価する文化が根付いています。ABテスト標準化の試みについては、同チームの yaginuuun が発表した資料もあるのでそちらも参考にしてください。(Slides)
結論としては、(具体的な数値は伏せますが) それなりに良い結果を出すことができ、自分の作ったレコメンドロジックは無事採用となりました。現在はホーム画面以外でも同じロジックを活用するべく、鋭意開発を行っているところです。
自分が考えて実装したロジックが、数千万人が使うサービス上で動き続けることが決まった時の喜びは、メルカリのエンジニアとして働く醍醐味だと思っています。
We’re Hiring!
今後も引き続き、本やマンガ以外のメタデータや、その他にメルカリが抱えている膨大なデータを使ってレコメンドロジックの改善を行っていく予定です。
普段からメルカリアプリを使ってくださっている方は薄々感じていらっしゃるかもしれませんが、メルカリのレコメンドロジックにはまだまだ手をつけられてないところがたくさんあり、改善の余地だらけです。
莫大なアクセス量があるがゆえに、複雑なロジックは本番環境で利用できないと言った難しさがあるのも事実ですが、その反面、一発当てればものすごく大きな経済的価値を生み出したりもできます。これからもユーザーが良い商品に出会える仕掛けづくりをやっていきたいと思っています。
少しでも興味を持っていただいた方は、僕にでも、周りのメルカリの知り合いにでも、お気軽にお声がけいただければ幸いです。ではまた。
Software Engineer, Machine Learning & Search – Mercari
参考文献
[1] Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J. Distributed representations of words and phrases and their compositionality. In Proceedings of NIPS 2013 (pp. 3111-3119).
[2] Oren Barkan and Noam Koenigstein. 2016. Item2vec: Neural item embedding for collaborative filtering. arXiv preprint arXiv:1603.04259.




