2022年4月21日に、『Mercari ML&Search Talk #3 ~MLOps & Platform ~』 を開催しました。
この記事はイベントレポートです。配信当日の内容を簡単に紹介します! 詳しくはYouTube上にある配信アーカイブ動画をご視聴ください(一部セッションは英語になります)。
イベント概要
メルカリのミッションを実現するため、複数のチームがMLを応用したプロダクトの企画、開発、分析を進めています。「Mercari ML&Search Talk」と題した一連のイベントでは、PMやMLエンジニアがメルカリで使われている技術やその応用について発表します。また、その後の質疑応答で発表の内容やみなさまから事前に頂いた質問について深堀りしていきます!
第3回は、MLやSearchに関係する基盤をメインテーマとして紹介させていただきます。メルカリでは、様々なチームがMLやSearchを用いてサービスの改善を進めています。その裏側では、基盤が各チームをサポートしているからこそ、それらの機能を簡単に提供することが実現できています。その一端をご紹介できればと思っています。
イベント詳細はイベントページを参照してください。
Mercari ML&Search Talk #3 ~MLOps & Platform ~ – connpass
登壇者
今回の登壇者は、以下の4名です。
Subodh Pushkar (@subodh101)
2018年にメルカリへ入社し、技術やフレームワークの熱狂的な支持者で、MLとその運用に関する様々な分野に携わり、時にはOSSに貢献しています。
Aman Kumar Singh (@aman)
2018年10月にメルカリへ入社。現在は主に機械学習プラットフォームとインフラストラクチャーを担当しています。
shinpei (@shinpei)
2018年にメルカリへ入社。検索プラットフォームチームのリーダーです。1年以上、検索エンジンに携わってきました。
Tomohiro Kato (@tkato)
2021年3月、メルカリに入社。前職では精密機器や車載機器のソフトウェア開発に従事してきました。現在はEdge AIを用いたWebアプリケーション開発をリードしています。
オープンソースを利用したMLプラットフォームの構築(@subodh101 & @aman)
YouTubeの動画は9:34からになります。
@subodh101 & @amanから、オープンソース・ソフトウェアを用いたMLプラットフォームの構築についてお話ししました。
このセッションでは、下記のアジェンダに沿ってメルカリのMLプラットフォームを紹介しました。
- メルカリのML活用について
- メルカリのMLプラットフォーム
メルカリのML活用について
2018年に入社した当時、AIチームは8名ほどでした。現在は60人以上、MLプロジェクトは20以上になっています。一部として、次のようなサービスがあります。
- 出品時に商品のカテゴリー、ブランド、価格、配送方法等の推薦
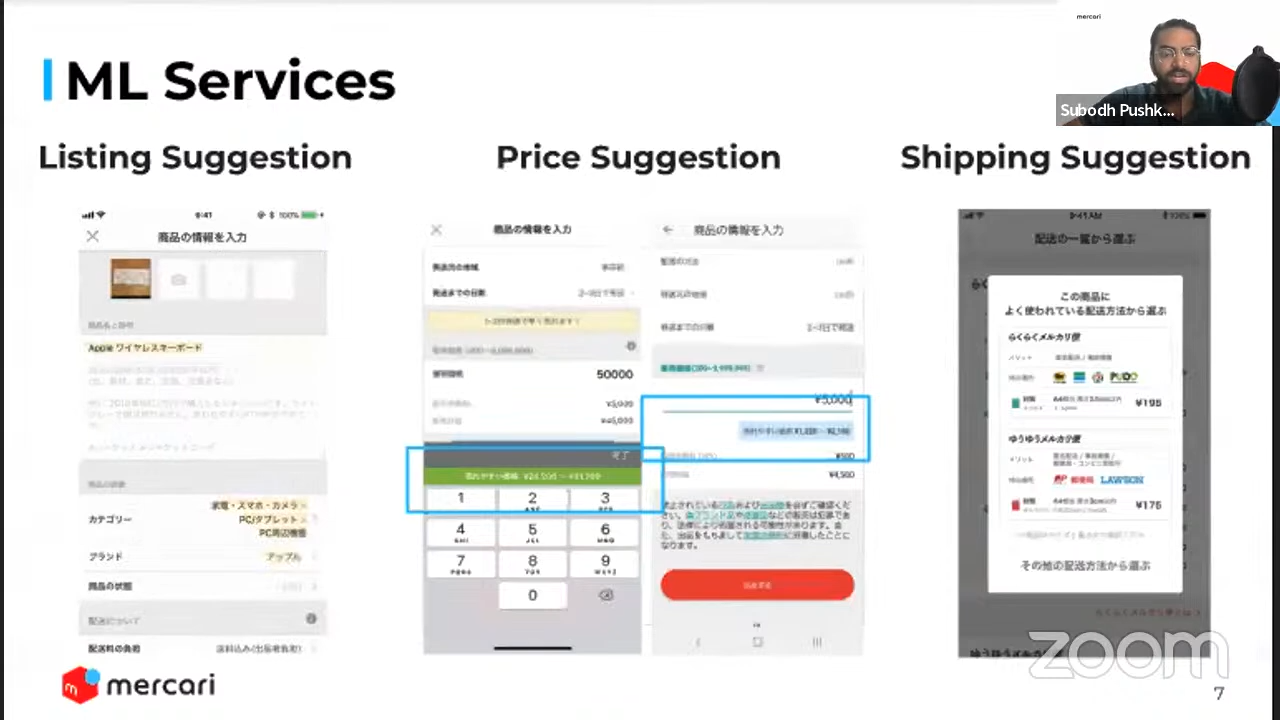
メルカリのMLプラットフォーム
メルカリにおけるMLプラットフォームとは、機械学習システムを構築・管理するための技術やインフラ全体を指します。データ探索とモデルのトレーニング管理、推論を実行するためのエンドツーエンドのシステムと定義します。MLプラットフォームによって、MLエンジニアはインフラを気にすることなく、性能の良いモデル開発に集中できます。
MLプラットフォームでは以下のようなソフトウェア・ライブラリを活用しています。
- Kubeflow
- mlflow
- polyaxon

各種クラウドベンダーもMLプラットフォームを提供していますが、私たちの選定する際の基準は以下のようになっています。こうした観点により、メルカリでは独自のMLプラットフォームを構築しています。
- 使い勝手の良さ
- ドキュメントの充実
- エンドユーザーの要件
- セットアップや将来的なアップグレードの容易性
- 柔軟性と外部ツールとの統合容易性
メルカリのMLトレーニングプラットフォームのアーキテクチャは以下のようになります。インフラのライフサイクル全体はTerraFormによって管理しています。
| ソフトウェア | 用途 |
|---|---|
| ArgoCD | Kubeflowのデプロイ |
| mlflow | トレーニングのトラッキング |
| kubecost | コスト管理 |
| cluster node scaler | ノードの自動スケーリング |

プラットフォームの動作デモを25:59から行っていますので、動画でご覧ください。
トレーニングワークフローのサポートでは、次のようなソフトウェア・ライブラリが使われています。
- ユーザーがKubeflow pipelineを作成
- ローカルまたはCircle CI経由でデプロイ
- チームのGCPプロジェクトからDockerイメージなどを取得
- トレーニングの結果をSlackで通知
- トレーニング終了後、モデルのパラメーターと精度をmlflowに格納
- モデルをチームのGCPプロジェクトにプッシュ
- 結果が悪い場合には再トレーニング

MLプラットフォームの特徴
メルカリのMLプラットフォームは次のような特徴を持っています。
- プロファイルは独立し、ユーザーは自分の作業しているプロジェクトのデータのみにアクセス可能
- CPU/GPU/TPUなどのリソースはオンデマンドに提供
- PrometheusとGrafanaを使用したコンポーネントの監視
- Argoワークフローを使用したSlackへの通知
- Kubecostを用いたコスト追跡
MLモデルのサービング
以下はサービングパイプラインの一例です。KubernetesサービスからgRPCで動作しているPodを呼び出します。アセットはGCS(Google Cloud Storage)からPodにロードされ、サービングパイプラインはSpinnakerによってデプロイ、管理されます。

外部サービスとしては以下のようなサービスを利用・連携しています。
- DataDog
- SENTRY
- PagerDuty
- Slack
将来的な計画として、以下を挙げています。
- トレーニング・サービングにおける特徴抽出ロジックを簡単に共有できるようにしたい
- MLエンジニア以外にとっても使いやすいUIにしたい
- サービングのさらなる自動化
- リアルタイムでのモデルパフォーマンスモニタリング
- 非同期gPRCサービング
メルカリの検索システムはどのように進化しているか(@shinpei)
YouTubeの動画は38:25からになります。
メルカリの検索機能について
メルカリの検索は次のような特徴があります。
- 10億規模の商品が対象
- 売り切れの商品も対象
- 1万クエリ/秒で稼働
- 商品の出品後、すぐに検索対象になる
- Recommendationなど、他の機能でも活用されている

これを踏まえ、次のようなアジェンダでお話ししました。
- どのような検索システムだったのか
- 現在はどのようになっているのか
- 今後どうしていきたいのか
どのような検索システムだったのか
過去の検索システムには次のような特徴がありました。
- ベアメタル上で動くSolr
- リフレッシュレートが高速
- スケールアップ重視
- SREチームが管理
- シングルな巨大インデックス
そうした中、マイクロサービス化を進める中で変更が行われています。ポイントは次の通りです。
- クラウド上のElasticsearchに移行
- リフレッシュレートが十分に高速
- スケールアウト重視
- サーチチームが管理
- 分散インデックス

現在はどのようになっているのか
世代ごとにアーキテクチャは、次のような変遷があります。
- 1世代(2019年〜)
独自のKubernetesクラスターで構成 - 2世代(2020年〜)
社内共通基盤のKubernetesクラスターで構成 - 3世代(2021年〜)
サーチチームが使っている基盤を他のチームで使える構成に

今後どうしていきたいのか
今後の展望として、次の3つを紹介しました。
- さらなる自動化
- MLとの統合
- マルチテナントクラスター

EdgeAIプロダクトを育てていくには(@tkato)
YouTubeの動画は1:03:49からになります。
@tkatoからは以下のトピックでお話しました。
- EdgeAIとは?
- メルカリのEdgeAIプロダクト
- EdgeAIプロダクトを育てていくには
EdgeAIとは?
EdgeAIとは、クライアントサイド(iOS/Androd/Webブラウザなど)で動作するAIを指します。バーチャル背景や写真からの検索、Webページの先読み、日本語の改行箇所を決めるといった事例などを紹介しました。
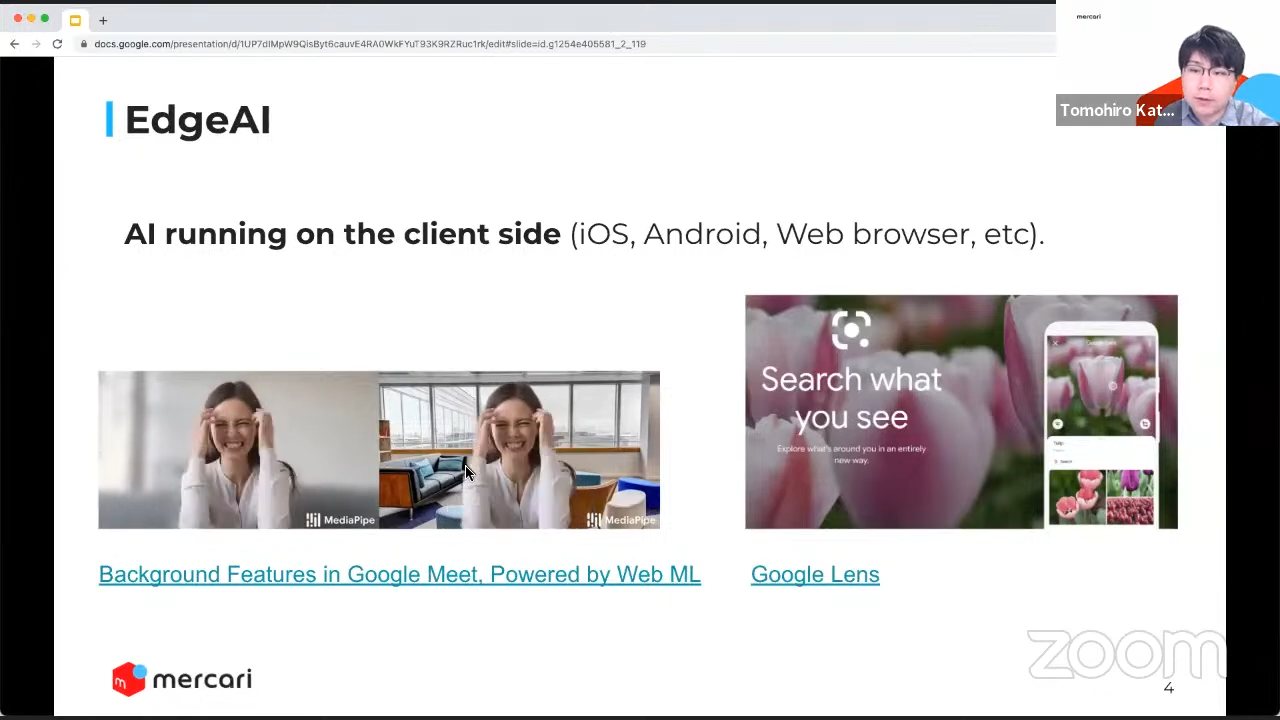
EdgeAIの利点として以下の5点を挙げています。
- 帯域節約(Bandwidth)
- 低遅延(Latency)
- 経済的(Economics)
- 信頼性(Reliability)
- プライバシー(Privacy)

メルカリのEdgeAIプロダクト
メルカリでのEdgeAI活用例として、メルカリレンズβを紹介しました。メルカリレンズβは持っているアイテムをスマートフォンのカメラにかざすだけで、その製品の類似商品の検索結果やメルカリでいくらくらいで売れているのかを提示します。メルカリのアカウント不要で体験できます。

Webブラウザで動作するオブジェクト検出とトラッキング、サーバーサイドの類似画像検索を組み合わせたプロダクトになります。
EdgeAIプロダクトを育てていくには

EdgeAIプロダクトを成長させるために大事なポイントは以下の2点になります。
- 定性的なユーザーフィードバックを早く得ること
- それを評価可能なプラットフォームを作ること
定性的なユーザーフィードバックを早く得ること、についてはリリース前の段階から社内外のユーザーテストを通じてフィードバックを得ています。特にEdgeAIの観点では、以下のようなフィードバックに対して対応することがUXを良くする上で重要でした。
- UIが使いにくい
- 初期化時間が長い
- 検出精度が悪い
このような観点でプロダクトを評価するために、メルカリでは独自のEdgeAI評価プラットフォームを開発しています。この時にキーになったのは「多種多様な実デバイス」で「UXを定性的、定量的」に評価できることでした。

このプラットフォームによって評価した複数の観点でのレポートを用いて、下記のような項目を開発中に行うことができるようになりました。
- デバイス依存の問題の発見
- 社内のステークホルダーの期待値コントロール
- ソフトウェアの変更がエンドユーザーに価値があるかの評価
セッションに関していただいた質問は次のようになっています(動画は〜1:29:33)。
- モデルはどれくらいの頻度で作成されていますか?
- 色々なデバイスがある中で、どのようなアプローチをしていますか?(デバイスごとにモデルを変えるなど)
- 撮影する角度によって精度が異なる問題はありましたか?あればどのように解決しましたか?
質問

全セッションが終わった後に質疑応答を行いました。いただいた質問の中で、動画中で答えているものは以下になります(動画は1:37:18〜)。
- HelmとTeraformの組み合わせが良くないということでしたが、詳しく教えてください
- MLプラットフォームを使う利点は何ですか?
- Kubeflowを使う時に問題になることはありますか?
最後に
メルカリグループはTech Talk をはじめとしたエンジニア向けのイベントを定期的に開催しています。イベント開催案内を受け取りたい方は、connpassグループのメンバーになってくださいね!




