こんにちは、メルカリMicroservices SREチームの藤本(@jimo1001)です。
私は現在、Embedded SRE として サーチインフラチームに入り活動しています。このサーチインフラチームは、Elasticsearchを使用した検索基盤を管理し、様々なマイクロサービスに検索機能を提供するチームです。この検索基盤は非常に巨大なプラットフォームで、メルカリ全体のマシンリソースの高い割合を占めており、メルカリの検索を支える非常に重要なものです。私の Embedded SRE としてのミッションは検索基盤の信頼性の向上と自動化を推進することです。 今回は、メルカリの検索基盤で利用している Elasticsearch における運用のノウハウを紹介したいと思います。
Elasticsearch とは
Elasticsearch は、Elastic社が開発する Apache Lucene を基盤とした検索エンジンです。高速な全文検索や多くの分析機能に加え、プラグインによって機能を拡張することもできます。複数のノードで分散して動作し、検索性能をスケールさせることができ、Elastic Cloud on Kubernetes (ECK) を使用して Kubernetes 基盤上に構築することで、そのスケーラビリティをさらに発揮させ、柔軟な運用が可能になります。 また Elasticsearch は大きく分類するとデータストアに該当するソフトウェアですが、一般的な RDB とは構成要素が大きく異なりますので、まずは Elasticsearch の構成要素を確認していきます。
Elasticsearch の物理的な構成要素
まず、Elasticsearch を構成するクラスタやノードなどの物理的な構成要素を紹介します。
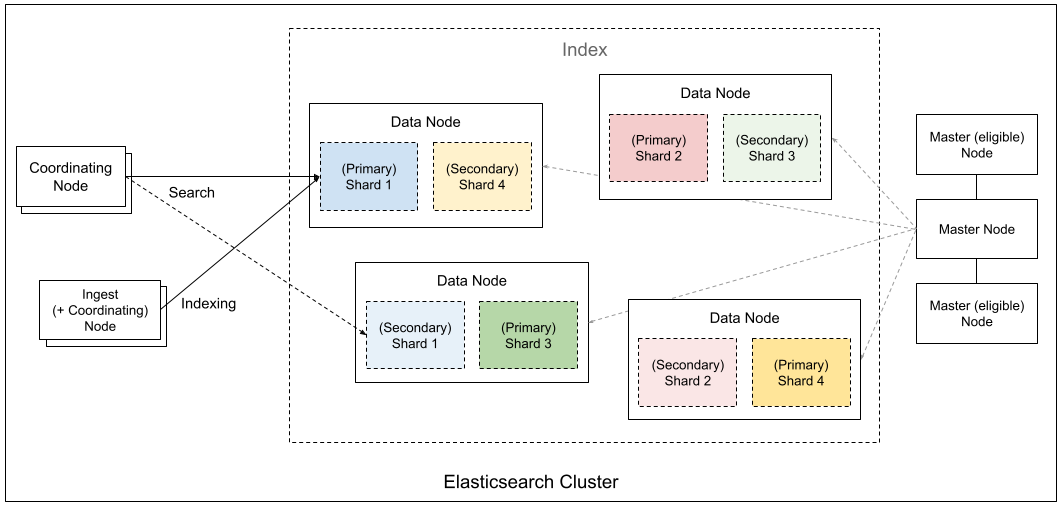
Elasticsearch Cluster
Elasticsearch の構成要素の中で最も大きな概念で、Elasticsearch の検索や管理機能などを提供する分散システムです。以下に説明する複数の Node から構成されています。
Elasticsearch Node
Elasticsearch のプロセスが動作する単一のサーバ(Kubernetes基盤の場合は Pod)です。Elasticsearch ではノードに複数の役割(ロール)を持たせ管理します。以下、代表的なロールを紹介します。
Master
Master はクラスタを制御するノードのロールです。この Master ノードは3台以上で構成する必要があります[1] 。 1台が Master となり、残りのノードが Master-eligible として Master ノードの障害時に Master へ昇格するための予備ノードになります。
[1]: Master ノードが2台の場合は、ネットワーク分断などが発生した時にもう一方も Master へ昇格し、それぞれが Elasitcsearch Cluster を構成してデータの不整合を引き起こす Split Brain が発生するため。
Data
Data は名前の通りデータを扱うロールで、検索対象となるデータを Shard という単位で保持し、検索(search) や集計(aggregation) などの処理を行います。この処理には以下のように非常に多くのマシンリソースが必要となります。
- ローカルストレージ
- 検索対象のデータはローカルストレージに永続化するため、SSD のような高速なストレージが必要となります。RAIDを組む場合は Elasticsearch には Replica の機能があるため、パフォーマンスのみを考慮した RAID 0(ストライピング)にすると良いと思います。
- CPU
- 検索や集計処理には多くの計算リソースが必要となるため、十分な CPU を割り当てる必要があります。
- メモリ
- 高速にデータにアクセスするためのファイルシステムのキャッシュであるページキャッシュと Elasticsearch の JVM に割り当てるヒープサイズを考慮してメモリサイズを決定する必要があります。
Ingest
Ingest 検索データの Indexing の際に Document の変換を行います。
Coordinating
検索 (search) や Indexing などのリクエストを受け付けるノードのロールです。 検索の場合は、各 Shard の Data ノードにリクエストし、それらの結果をマージして最終的な検索結果のレスポンスを返します。 インデキシングの場合は、格納する Shard を決定し、Primary Shard の Data ノードにリクエストします。
論理的な構成要素
次に、Elasticsearch のデータ(Document)を保持する Index の内部構成について紹介します。

Elasticsearch Index
Elasticsearch Index は Elasticsearch Cluster 内の Document の集合のような概念です。Elasticsearch Cluster に複数の Index を作成し、Document を管理することができます。
Shard
Shard は Index を指定した数に分割したものです。Shard の数は Index を定義する時に決定し、後から変更するには制約があります。内部的には Lucene Index(Apache Lucene のデータ構造)でデータを管理しています。
Replica
Shard の複製です。更新が直接入ってくる Shard を Primary Shard と呼び、その複製は Replica Shard と呼びます。Replicaの数は、可用性と検索性能に影響し、いつでも変更することができます。Primary Shard が何らかの理由で消失した場合、Replica Shard の一つが Primary Shard に昇格します。
Segment
Shard で管理されている Lucene Index は Segment という単位でドキュメント群を管理しています。この Segment は基本的に Immutable ですので、Document が削除された時には、Segment 内のドキュメントは削除されず、削除されたことのみが記録されます(つまり論理削除の状態となります)。この状態のままではデータサイズが増える一方なので、削除した Document を除外して Segment を統合するマージ処理を定期的に行います。
Document
Document は、1件のデータを表します。
メルカリ検索基盤の Elasticsearch の構成
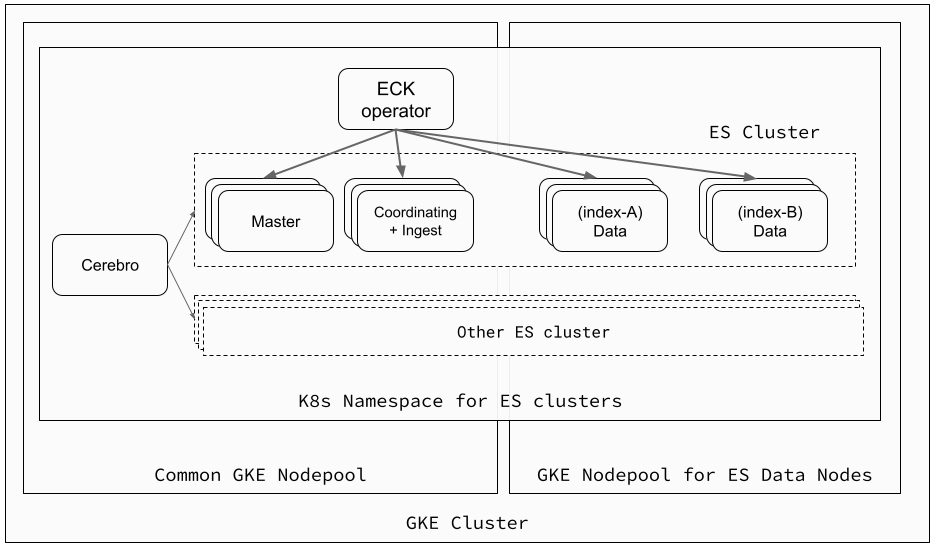 メルカリの検索基盤は、マイクロサービス共通のKubernetesクラスタ上で複数の Elasticsearch クラスタを構成しており、Elastic Cloud on Kubernetes (ECK) を用いて全ての Elasticsearch クラスタを管理しています。各Elasticsearchクラスタは、主に Master、Coordinating (client)、インデックス毎の Data のノードセットで構成し、ECK が提供する Kubernetes の Elasticsearch リソースを Manifest ファイルで定義してコードで管理しています。
メルカリの検索基盤は、マイクロサービス共通のKubernetesクラスタ上で複数の Elasticsearch クラスタを構成しており、Elastic Cloud on Kubernetes (ECK) を用いて全ての Elasticsearch クラスタを管理しています。各Elasticsearchクラスタは、主に Master、Coordinating (client)、インデックス毎の Data のノードセットで構成し、ECK が提供する Kubernetes の Elasticsearch リソースを Manifest ファイルで定義してコードで管理しています。
検索基盤の構成はさまざまな試行錯誤を行いながら今の形に変化しています。その変遷については以下の記事をご覧ください。
マシンリソースの最適化
Master と Coordinating 用の Pod は共通のノードプールのノードを使用していますが、Data 用の Pod は CPU とメモリを多く使用するため、最適なマシンタイプのノードプールを用意して構成しています。これは余分なリソースを削減することもできるため、コスト削減にも寄与しています。
Elasticsearchクラスタの管理
Elasticsearchクラスタの構築や Replica 数の変更などのオペレーションを行う際は、Elasticsearch の REST API も使用しますが、Cerebro というWeb管理ツールを使用することが多いです。このツールは、Elasticsearch クラスタにアクセス可能な場所にデプロイするだけで利用することができ、ドキュメント数やデータサイズなどの統計情報の確認、クラスタやインデックスの設定の変更、Shard の再配置、スナップショットの管理およびリストアなどあらゆることが GUI で直感的に操作できるため非常に便利です。
Shard 数の決定方法
Shard の数は、Index を作成する際に決定するため、後から変更することは難しいです。そのため、データの増加量を予測し、最終的にどのくらいのサイズになるかを見積もります。Data ノードのマシンスペックからどのくらいのデータを管理できるか逆算し、上のデータサイズから割り返して、Shard 数を決定します。検索基盤の場合は、検索の実行速度を重視しているため、全てのデータがRAMにキャッシュできるように調整しています。
可用性とスケーラビリティ
基本的に Replica の数が可用性に比例し、スケール可能なノード数の上限を引き上げることができます(たとえば、Shard数が 5 で、1ノードに1 Shardを配置する場合、1 → 2 Replica に変更すると、構成可能なノード数は 10 から 15 に増えます)。 可用性の観点では少なくとも 1 つ以上の Replica を設定する必要があります。もし、一から復旧する手段がない場合は、2~3 以上の Replica を設定した方が良いと思われます。 スケーラビリティに関しては、CPU 使用率やレイテンシを確認し、性能要件を満たせていない場合は Dataノードと Replica を増やすことで対応することができます。スケールアウトで注意する点としては、Replica を増やした時に ネットワーク越しにデータのコピーが行われるためトラフィクが急増し、既存ノードの高負荷やネットワーク帯域の逼迫が発生する可能性があります。したがって、ピークタイムを避けて事前にスケールアウトさせるような対応が必要です。
インデキシング
メルカリでは商品情報をインデキシングする方法として以下の2通りを用意しています。
Online Indexing

Online Indexing はメルカリの商品情報の追加や変更、削除をリアルタイムにストリーミング処理するインデキシングです。 これら商品情報は Google Cloud Pub/Sub をのメッセージとして送信し、Dataflow で検索に最適化したデータ構成に加工して、最終的に Elasticsearch Index に保存します。Online Indexing は複数の情報ソースがあり、それぞれ並行してインデキシングを行っています。
Offline Indexing

Cloud Bigtable に保管している商品の全件情報からインデキシングするバッチ処理です。こちらは Elasitcsearch Index を再構成する時などに使用します。
Offline Indexing の実行中は検索に反映する必要がないため、Index 設定の refresh_interval を -1 にセットすることで高速化しています。インデキシング完了後は refresh_interval を元に戻すことを忘れないように注意が必要です。
PUT /myindex/_settings
{
"index" : {
"refresh_interval" : "-1"
}
}監視
Elasticsearch の検索性能を維持するためには、様々な角度から監視を行い問題を検出する必要があります。以下に私たちが Elasticsearch を運用する際に使用している監視の一部を紹介します。
Cluster Status
まずは、Elasticsearch Cluster が健全性を保つために Cluster Status を監視します。 ステータスが green の場合は正常、yellow の場合は注意が必要なため Slack へ通知のみ行い、red の場合は即座に対応が必要となります。
レイテンシ

Elasticsearch Cluster 毎に検索リクエストの95パーセンタイルおよび99パーセンタイルのレイテンシを監視し、閾値を超える場合に通知しています。
これらのレイテンシの指標はレイテンシSLOのSLIとして使用しており、このSLOのエラーバジェット消費量も合わせて監視しています。

CPU 使用率の外れ値の検出

メルカリで使用している Elasticsearch Cluster は多くの Data ノードで構成されており、中には不安定になり、CPU使用率の高くなることもあります。このようなノードが存在することで、Elasticsearch Cluster 全体の性能を引き下げる要因にもなっているため、他とは異なる CPU 使用率のノードを検出しています。ただし、単純に外れ値として監視してしまうと、投入直後の使用していない Data ノードも検出してしまうため、CPU 使用率の監視と組み合わせて監視するようにしています。
オペレーション
検索基盤の運用に関するオペレーションで気付きの多かったものを紹介したいと思います。
GKE のアップグレード
先述の通り、検索基盤の Data ノードは専用のGKE ノードプールで管理しており、このノードプールはサーチインフラチームで管理しているため、GKE のバージョンアップ作業は共通ノードプールのアップグレードのタイミングに合わせて作業を行う必要があります。
アップグレードの方法としては、gcloud コマンドを用いた手動アップグレード(サージアップグレード)と、新しくノードプールを作成して移行する方法を考えましたが、前者は Pod の再起動の際に時間がかかった場合、強制的に終了する可能性があったため、後者の方法で行うことにしました。
作業としては非常にシンプルで、
- 既存と同じラベルの 新しいノードプールを作成
- 古いノードプールの Auto-Scaling を無効化(切り戻しに必要な GKE のノードを確保するため)
- 古いノードプールに新しい Pod がスケジュールされないように cordon を実行
- Elasticsearch の Dataノードを再起動
- 古いノードプールを削除
Dataノードの再起動後は新しいノードプールにスケジュールされるため、Dataノードの再起動を繰り返すことで移行を行うことができます。
この移行作業で注意する点として、この移行作業で一時的にDataノードの数が増えるため、 GCP のインスタンスグループのVM数の上限に達してしまわないように気を付けることです。(実際に上限になってしまい、Podが作成できない状態になりました…)。この上限値は、GCP管理画面の「IAM」→「割り当て」から確認することができますので、このようなリソースを一時的に大量に利用するような作業を行う場合は、定期的に確認した方が良いです。もし上限になりそうな場合は、サポートに上限緩和の申請をして上限値を引き上げてもらいましょう。
Elasticsearch のバージョンアップ
検索基盤では 6.x 系の Elasticsearch を長らく使っていましたが、つい先日 7.x 系にバージョンアップを行いましたのでその作業を紹介します。 今回はメジャーバージョンが変わるため、ローリングアップデートのようなことはできず、以下の手順で実施しました。
- 新しいバージョンの Elasticsearch Cluster を新たに作成
- Offline Indexing を使用して再インデックス
- トラフィックを少しずつ新しい Elasticsearch Cluster に移す
- 旧バージョンの Elasticsearch Cluster の削除 このように再インデックスの方法があれば、新しく構築して移行することができるため、メジャーバージョンのバージョンアップも簡単に行うことができます。
さいごに
今回はメルカリの検索基盤の構成や監視、運用のノウハウの一部を紹介しました。私たちは Elasticsearch の管理、運用を通して様々な問題に直面し、解決方法を模索し続けています。Elasticsearch を運用されている方に少しでも参考になれば幸いです。
また、先日投稿いたしました検索の応答性能を維持するための Benchmarking Automation という取り組みも行っていますので興味がありましたらご覧ください。
メルカリでは現在 Microservices SRE の採用やカジュアル面談を積極的に行っています。もし興味がありましたらお気軽にお問い合わせください。




