こんにちは、メルカリの検索チームで機械学習エンジニアとしてインターンをしていた塚越駿 ( @hpp_ricecake ) です。インターンでは、メルカリのログデータと言語モデルを用いて同義語辞書を自動構築するというタスクに取り組みました。
メルカリではすでに同義語辞書を用いた検索システムの改善が行われていますが、定期的なアップデートに課題が存在したため、今回は日々自動で蓄積される検索クエリと商品データから自動で辞書を構築できる手法を実装しました。本記事では、その結果についてご紹介いたします。
同義語辞書について
同義語(synonym)とは、ある語に対して、表層的には異なるものの本質的に同じものを表している語のことを表します。検索システムを構築するにあたって、適切な同義語辞書を用いれば検索システムの再現率(recall)を向上させることができるため、質の高い同義語辞書を整備することは非常に重要です。
なぜ同義語辞書を整備すると検索の再現性(または、網羅性)が向上するのか、例として、あるお客さまがメルカリで「靴」というキーワードを用いて、商品を検索する場合を考えてみましょう。
この場合、検索システムはあらかじめ保存されている商品テキストから「靴」という単語を含む商品を見つけ出してきて、なんらかのスコアに基づいてそれらの商品を並べ替えてお客さまに提示します。しかし、この場合、検索システムは単純な文字列マッチングを用いて商品の検索を行っているため、「靴」という語を含む商品しか提示することができません。
メルカリでは、お客さまが様々な表記で商品を出品する可能性があります。商品登録の際に、「靴」と同じ意味の語の別表記である「くつ」「クツ」という語が使われていた場合、単純に検索しただけだと、それらの別表記は検索時に無視されてしまいます。これらは表記方法こそ違いますが、本質的に同じ物を表しているので、「靴」の検索時に「くつ」や「クツ」の検索結果も合わせて表示したほうが、お客さまに提示できる商品の数が増え、検索の網羅性が向上し、お客さまが求める商品と出会える可能性がより高くなると考えられます。同義語辞書は、こういった場面で力を発揮します。先ほどの例を用いると、同義語辞書に「靴 ⇆ クツ」「靴 ⇆ くつ」といった関係性を記述しておくことで、お客さまが「靴」と検索した際にその別表記も含めて同時に検索することが可能になります。
本記事では、上記のような別表記の組や意味的に同じ語の組の他に、例えば「シミュレーション ⇆ シュミレーション」のような誤表記や表記揺れも含めて、広義の同義語として扱います。ミススペルを同義語辞書によるアプローチで補うか否かには議論の余地がありますが、既存の検索システムがこの方針をとっていたため、今回の手法でも同様の立場をとります。
では、このような同義語辞書をどのように整備すればいいでしょうか。まず考えられる手段として、既存の同義語辞書を使用することが挙げられます。これらの辞書は高品質な一方で、対象となっている語が一般のドメインに限定されてしまうという欠点があります。ここでドメインとは、"データの集まり"のことを指します。すなわち、"同義語の対象となる語が一般のドメインに限定される"とは、一般的な単語についての同義語しか得ることができないということです。
メルカリでは、検索対象となる商品の名前に、固有名詞が用いられていることが多いという特徴があります(それぞれの商品・ブランド名や、作品・キャラクター名など)。したがって、一般の同義語辞書だけでは、メルカリの商品検索という、非常に広大なドメインのテキストを扱う必要のあるシステムの全てをカバーすることは困難です。
そこで、今回のインターンでは、メルカリに蓄積されている商品データとお客さまの行動ログを用いて同義語辞書を自動で構築することを考えました。メルカリ自体に存在するデータを有効に活用することで、既存の辞書では問題になる固有名詞などのデータの不足を解消し、よりメルカリというサービスおよびメルカリの検索システムに適した同義語辞書を構築することができると考えられます。
同義語辞書の自動構築については、いくつかの研究が存在しますが、今回はAmazonのLuら[1]の手法をベースに、簡略化や変更を加えて実装を行いました。
同義語に関する教師データを用いて分類モデルを構築することも考えられますが、以下の運用上の問題があります。
- 教師データの収集がコストがかかる
- 教師あり学習による分類モデルを運用すると、サービスが続く限りそのモデルに入力されるテキストのドメインが変化しうるので分類モデルのメンテナンスが必要になる
上記を考慮して、教師なし手法により自動的に同義語辞書を作成できる手法を実装しました。
手法
今回実装した手法について述べます。先述したLuら[1]の手法では、まずWikipediaやその他の辞書のリダイレクトとサービスのログデータから同義語ペアの候補を選出します。次に、それらの同義語ペアをBERT[2]を用いてそれぞれベクトルのペアに変換し、そのベクトルのコサイン類似度が閾値より高い同義語ペアを残す、という流れで自動的に適切な同義語ペアを獲得します。
今回実装したものとLuら[1]の手法は、大枠は同じですが部分的に異なっています。同義語辞書の自動構築手法の流れを以下に示します。
- お客さまが検索結果に表示されている商品をタップした時に得られる、その検索キーワードと商品タイトルの組のデータを抽出する。
- 検索キーワードと商品タイトルをそれぞれ分かち書きする。
- 検索キーワード中の語と商品タイトル中の語の出現回数と共起回数を計算する。
- それぞれの語の出現回数と共起回数をもとにNormalized PMI (NPMI) [3]の値を計算する。
- NPMIの値をもとに大量に存在する同義語ペアの候補を並びかえ、上位100万ペアを抽出する。
- BERT[2]を用いて同義語ペアをそれぞれベクトル表現に変換する。
- コサイン類似度の高い上位15万ペアを最終的に抽出された同義語として出力する。
全体の流れとしては、お客さまの行動ログから共起関係として使えそうなデータを用いて、検索キーワード内の単語と商品タイトル内の単語のペアを同義語ペアの候補として、それらの共起を測り、共起の傾向が強いペアのうちベクトル表現の類似度が高い物を同義語とする、というものです。
「お客さまが商品をタップした」という選択選好を信号として用いることで、人間からみて意味的に同一である同義語ペアを抽出できると考えられます。この選択選好は、検索キーワード内の単語と、商品タイトル内の単語の共起関係を用いて捉えることができると考えられるため、ベクトルの類似度によるフィルタリングの前処理として、共起関係を用いてフィルタリングを行っています。
BERTは単語を入力として、その単語の意味を表現した実数値のベクトル表現を出力することができます。したがって、ある単語のペアについて、それらのベクトル表現の類似度が高ければ、それらの意味も近いと考えることができます。今回は、ベクトルのコサイン類似度を、同義語の候補が近い意味を持っているか判定するために用いました。
以下に、それぞれの手順をより詳細に説明します。
1. 検索キーワードと商品タイトルのペアデータを抽出
まず、ログから同義語関係を抽出できそうな関係をお客さまの行動から考えると、検索キーワードと、その検索キーワードでお客さまがタップした(商品の詳細画面に遷移した)商品タイトルの関係が考えられます。これは、Luら[1]のログデータを用いる部分と類似しています。
2. 検索キーワードと商品タイトルをそれぞれ分かち書き
次に、事前に同義語ペアの候補を共起関係の強さを用いてフィルタリングするために、単語レベルの生起/共起回数が欲しいので、得られた検索キーワードと商品タイトルに対して分かち書きを適用します。
今回は同義語ペアという単語レベルの同義語関係が欲しいので、英語の場合、キーワードと商品タイトルという文字列を単純に空白区切りすればよいですが、日本語の場合、事前に分かち書き器を用いて単語レベルに分けておく必要があります。今回は、分かち書き器にはMeCab[4]を用い、辞書にNEologd[5]を用いました。
3. 検索キーワード中の語と商品タイトル中の語の出現回数と共起回数を計算
2021年4月のログデータを用いて共起回数を計算し、最終的に64億ペアの同義語候補が算出されました。
4. NPMI の計算
さらに、共起関係が強い順に同義語ペアを並び替え、上位100万ペアを候補として残しました。
共起関係の強さの指標としては、PMI(Pointwise Mutual Information; 自己相互情報量)およびその値を-1~1の範囲に正規化したNPMIを用いました。これは、共起の回数自体ではなく、検索キーワード中の単語と商品タイトル中の単語との共起の強さに興味があるためです。ただ、PMIはそもそもの頻度が小さい単語ペアについて、そのPMIの値が不正確になりがち(過剰に大きい値を見積もりやすい)という欠点があるので、共起の回数がある程度以上の同義語ペアの候補のみを残す、といった工夫をしています。
PMIではなくNPMIを用いたのは、異なる期間のログデータを用いて計算されたPMIの値を、それぞれ比較できるようにするためです。例えば2021年4月1日のログデータのみを用いて計算したある単語vとwのPMIの値と、2021年4月全体のログデータを用いて計算したPMIの値とは、データの総数が異なるので、PMIの値も大きく異なってしまうと考えられます。
上記の問題点を解消し、異なるコーパス(異なる期間のログデータ)を用いても、統一的に扱うことができるのがNPMIです。NPMIを用いることで、例えば2021年4月と5月それぞれでNPMIの値を計算して、大雑把にではありますが、それらを比較することができます。
メルカリにおけるログデータは非常に膨大で、かつ一定期間あたりのログの量も常に変化することを考えると、ログの量によらない指標を用いて、別の期間のデータを用いた場合の比較を公平にできるようにすることには、一定の価値があると考えられるため、今回はNPMIを採用しました。
5. NPMIの値を元に上位100万ペアを抽出
NPMIの値が高い順に同義語ペアの並び替える際は、GCPのBigQuery上で、共起の回数がある回数以上のもののうち、簡単な表記揺れ(スペースの有無など)のみを含むペアを無視したペアを並び替えに用いました。
これにより、64億ペアから100万ペアまで同義語の候補が絞り込まれました。事前に絞り込みを行ったのは、全ての同義語ペアに対してベクトルの計算を行うのは、コストがかかりすぎるためです。
この時点で、ある程度共起関係が強い同義語ペアしか残っていないので、同義語に見えるものも多く含まれていましたが、意味的には異なるペアも多く混ざっていたことを確認しています。
6. BERTを用いたフィルタリング
最後に、ベクトルの類似度による並べ替え(フィルタリング)を行いました。
先ほどまでで計算された同義語の候補100万ペアに対して、それぞれBERTを用いた同義語のベクトルへの変換とコサイン類似度の算出を行い、類似度が高い上位15万ペアを最終的な同義語ペアとしました。
BERTは、文脈に従ったベクトル表現を生成できる言語モデルです。例えば、単語とベクトルが1対1対応しているようなモデルでは、同じ語の中に異なる意味を持つ多義語などの単語をうまく扱うことができませんが、BERTであればその単語の周囲の単語に従って意味ごとに異なるベクトルを出力することができます。
今回は、東北大学が公開する日本語BERT[6]をベースに、メルカリの商品の説明文テキストを元にさらに追加で学習を行ったモデルを利用しました(Domain adaptationと呼ばれます)。事前学習済みの日本語BERTは、日本語Wikipedia上で学習が行われており、メルカリのテキストドメインとは異なるドメインを持っていることが予想されます。そこで、よりメルカリに適したモデルを得るために、メルカリの商品テキストを用いて追加の学習を行いました。
結果
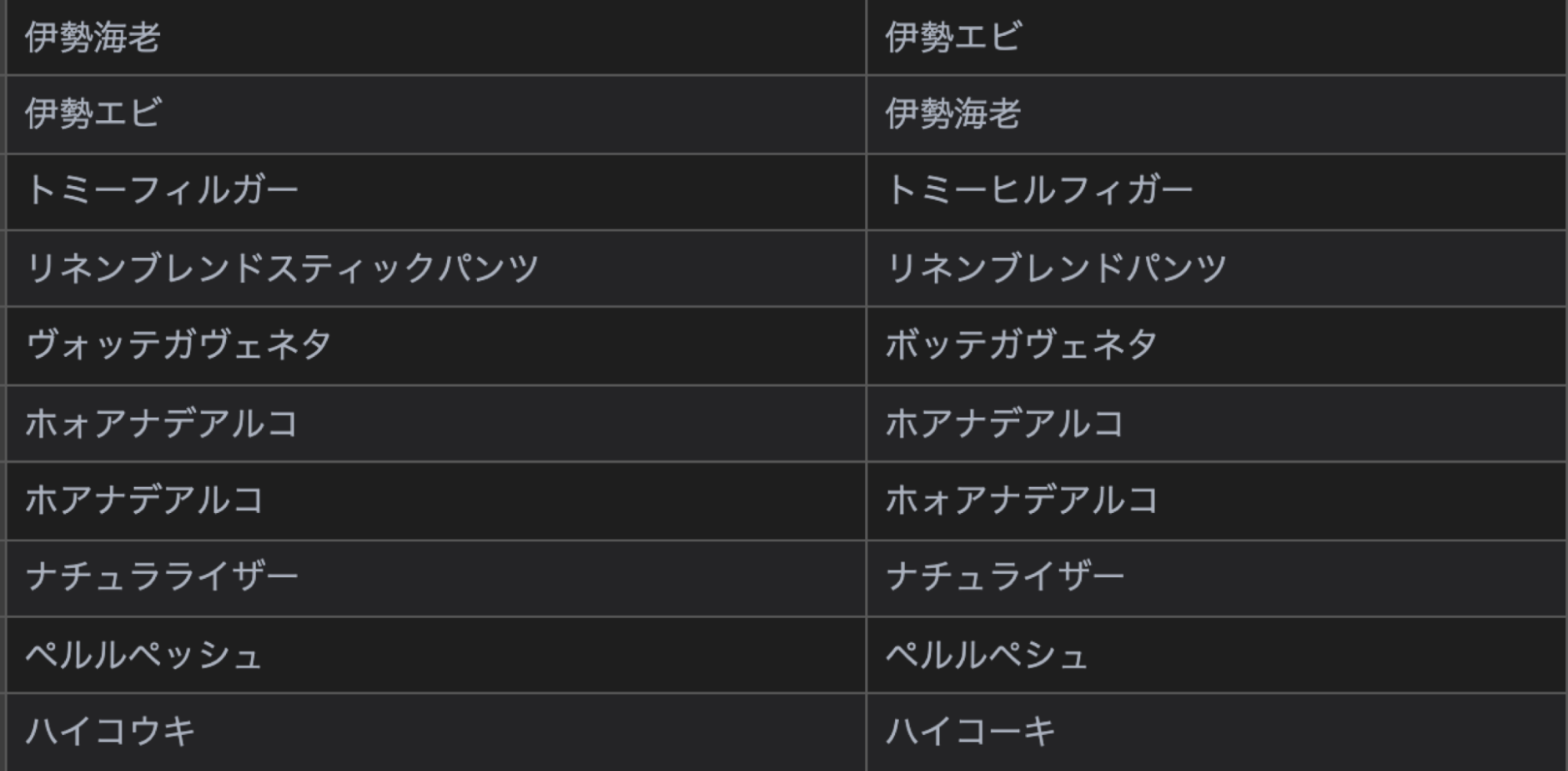
以上の手続きによって、実際にログデータから自動的に生成された同義語を以下に示します。
漢字の読みや、ブランド名の異表記、誤表記を吸収するような同義語が生成されていることがわかります。
さらに、メルカリの実際のサービス上で生成された同義語辞書を導入した際に、検索結果によい影響が発生するかを、いくつかの同義語を用いて検証しました。
例として、”aviici → avicii” という同義語ペアを用いた場合の検索結果の比較をします。左が “aviici” という誤ったスペルで検索された際の結果、右が ”avicii” という正しいスペルで検索した際の結果です。

“aviici” という誤ったスペルで検索された時は、十分な検索結果を提供できていないことがわかります。一方で、”avicii” という正しいスペルで検索された時は、十分な件数(100件以上)の検索結果を提供できていることがわかります。
この場合、誤ったスペルで検索された際の結果に、正しいスペルでの検索結果を加えることで、お客さまにとってよりよい検索結果を提供できると考えられます(※1)。
おわりに
本記事では、今回のインターンで取り組んだ、ログデータと言語モデルを用いた同義語辞書の自動構築についてご紹介しました。
今回実装した手法は、運用コストを低く抑えつつ、メルカリのテキストドメインに合った同義語辞書をメンテナンス可能です。さらに、既存の同義語辞書との組み合わせを模索したり、フィルタリング手法を洗練させたりすることで、検索体験を継続的に改善できる可能性があると考えています。
インターンでは、オンボーディングからタスクの選定、実装と検証まで、非常に密にコミュニケーションを取りながら進めていくことができ、とても楽しく業務に取り組むことができました。
本記事をお読みいただいているみなさんも、この記事を楽しんでいただければ幸いです。
参考文献
- Hanqing Lu, Yunwen Xu, Qingyu Yin, Tianyu Cao, Boris Aleksandrovsky, Yiwei Song, Xianlong Fan, Bing Yin. Unsupervised synonym extraction for document enhancement in e-commerce search, 2021.
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL, 2019.
- Gerlof Bouma. Normalized (Pointwise) Mutual Information in Collocation Extraction.
- https://github.com/taku910/mecab
- https://github.com/neologd/mecab-ipadic-neologd
- https://github.com/cl-tohoku/bert-japanese




