※この記事は、"Blog Series of Introduction of Developer Productivity Engineering at Mercariの一環で書かれています。
はじめに
こんにちは、メルカリ、サーチインフラチームのshinpeiです。今回はメルカリの検索基盤の裏側について、そのアーキテクチャ変遷について書こうと思います。2018~2021年の4年間で、大きく3回、変化をしました。設計の段階では希望と期待にあふれているアーキテクチャでも、問題は後からやってきます。設計には良し悪しがあり、変化することで知見を得ながら、改善を続けています。え、これだと危ないのでは?、、あぁ、やはりそうなるのね。などと、ご笑覧いただければ幸いです。
前回までのお話
メルカリの検索は、創業時から、Solrをベースにしたシステムで組まれてました。その変遷はこちらのスライドにまとめてあります。一方、弊社では2018年頃からシステムをマイクロサービス化していこうという方針が取られてきました。(メルカリにおけるマイクロサービスマイグレーションの理想と現実)これに伴い、検索基盤もクラウドの上で動かそうということになり、ついでに既存の検索システムのいろんな課題を解決した新しい基盤を作ろう。というプロジェクトが始まりました。
GKE + Elasticsearch
Kubernetesはいまでは当たり前になってしまいましたが、当時は資料も少ない状態からのスタートでした。開発メンバーのほとんどが検索はチョットデキルけど、Kubernetesは触ったことない状態だったので、今振り返れば”興味深い”アーキテクチャになっています。最初期のアーキテクチャは以下のような感じです。

リクエストは図の上から流れてくると考えてください。先のLaiの投稿にあった通り、検索リクエストは、アプリから、Gatewayを通り、Adapterに集約されます。Adapterまでは、メルカリの他のマイクロサービスが動作している共通GKEクラスタに乗っています。(図では、Kubernetesクラスタはロゴ付きの四角い枠で囲ってあります。)当時、検索チームは、この共通クラスタとは別のクラスタでサービスを構築する、と宣言していました。主な理由としては共通クラスタで生まれる制約や他との折衝を行うことなく、自由にスピードを持って開発することを優先した結果だと聞いています。つまり、Adapterまで届いたクエリは再び外にでて、検索チームの運用するGLB(Google Load Balancer)に投げられます。
まず、特筆すべきは、複数のGKEクラスタが立っていたことでしょう。これは、GKEクラスタの安定性を信用してなかったため上げるためにこういう作りになっています。1つ(、Kubernetesクラスタごと)落ちても、動作できるように3つ作ってあります。当時、メルカリのマイクロサービスはほぼ1つのリージョンにあるGKEクラスタで運用されてました。我々が耐障害性を考えていた際に、マルチリージョンにしようというアイディアもでたのですが、メルカリ本体のGKEより可用性をあげても意味がない、という笑い話になったことを覚えています。3つのクラスタ構成は可用性の向上には役に立ちましたが、オペレーションはとても大変でした。
他にも、Podの構成、ノードプールの構成、シャード分割の構成、スキーマの設計などの検討も行いました。たとえば、AdapterがGLB以下からもらう検索結果はドキュメントのIDのみ返ってきます。これは、上の構成だと、他のマイクロサービスへのアクセスは他のマイクロサービスが動いてる共通GKE内部にいるAdapterがやるのが一番効率がいいこと、Elasticsearchでフィールドを保存しなくてもよくなるためインデックスのサイズが減ること、などのメリットがあります。
これならコストパフォーマンスがあまり悪くない、という構成もだいたい絞り込めて、後は走りながら考えましょう。ということで、この構成は無事、検索のトラフィックを受けはじめました。この間、約1年ほどです。
この間、検索チームからすると、新機能は新基盤のリリースまで温めるという状態が続いてました。すぐに問題になったのは、おすすめ順への移行案です。これまで、メルカリの検索では、商品の新着性により注目した検索結果になっていました。”新しい順”がよく使われ(参考)、”おすすめ順”はあまり使われていませんでした。これは、言い換えれば、「検索エンジンがキーワードの頻出度に応じて検索ヒットの順番を並び替える、という機能を使っていない」に近い状態です。パフォーマンス的には、いわゆるTF-IDFのスコアをフィールドごとにごにょごにょする機会は少なく、検索屋からみたときの負荷は軽かったというわけです。
具体的にどのくらい違うかというと、約8倍くらいキャパシティに差がありました。こういった場合、いきなり8倍のインフラを用意することはできないため、おすすめ順のトラフィックはだけ切り分けて、専用のクラスタに流しています。こうすることで、全体のキャパシティが8倍になることはなく、せいぜい数十%くらいの拡張で済んだりします。そもそも検索は使う計算資源が大きいのですが、少しの改善で使う容量がどかっと変わったりしやすいのかなと思います。このため、前段との連携は欠かせません。メリカリではAdapter、LB、middleware、elasticsearchと、全レイヤーで協力しながら捌くように心がけています。
共通GKEへの引っ越し
さて、このような検索基盤拡張の対応を続けている間にも、GKEのリリースバージョンはどんどんでてきます。毎月のようにカンファレンスや勉強会で、新しいGKEの話が流れてきます。最初は楽しみだったアップグレードも、次第に重荷に。
「無理や。。。」
気づいたら、私は社内でマイクロサービスプラットフォームチームに相談をはじめていました。先の投稿でもありましたが、メルカリの共通クラスタは、Multi-tenantに作られています。以下は彼らの運用するGKEに入ったあとの構成です。

見た目はほぼ変わってないですね。笑 図の内側の枠線は、Kubernetesのnamespaceを表しています。検索チームのnamespace内にすべてを詰め込んだ形です。主な変更点は、GLBがいらなくなったことと、DeploymentをStatefulsetに変えたことです。アーキテクチャの変更はこの程度ですが、しかし内部体験は大きく変わってまして、たとえば、彼らの運用するGKEクラスタにはterraformベースのInfrastructure as a Codeな自動化が整えられた形で備わってたり、運用するノードプールにはセキュリティ監査のためのデーモンが動いていたり、、、。今まで荒地に自分たちの城を少人数で築いてましたが、街にでてきてオフィスビルに招かれ、今日からここで働いてもいいんだよ、仲間も大勢いるよ、と言われたような感じでした。(あくまで個人の体験です)
また、Microservice Platform Teamの知見を活かせることも大きな利点となりました。これまで、何度か悩みを相談することはあっても、やはり別クラスタなので、勝手が違うことが多く、なかなかお互いの知見を活かすということは難しかったのです。共通基盤に乗った後で、たとえば、我々の使っていたlocal SSDのI/Oには実は余裕があることを見つけてもらえたりしました。その後、regional local SSDに載せ替えたことで、全体的なコストは下げることができました。懸念だったノードプールの自動アップグレードは、前出のStatefulsetに変えたこと、ある程度作業をスクリプトに起こすことで、なんとかなりました。(ただし、現在は別な理由でまた検索チームが担当することになってますが、、)
共通GKEクラスタに乗ったことで、我々は必要以上にGKEに関わる必要はなくなりました。相談開始から実現まで、やっぱり1年くらいかかりました。それでも、この判断は、初期アーキテクチャ始動から1年ほどでできたので、よかったなぁと思っています。
SaaSスタイルの社内共通検索基盤へ
さて、このころになると、マイクロサービス化がある程度メジャーになったこともあり、各サービスの開発がより活発になってきて、独自に検索エンジンを利用している(したい)、というチームが複数出てきていました。検索チームには検索得意な人が集まってるみたいだよ、と相談される機会もぼちぼちでてきました。我々の使ってる仕組みを、そのまま他のチームがフォークして使ってるような事例もあったのですが、割と変化が早いので、新旧で差分がでてて、もはやフォローできないような事例もありました。で、あれば、我々が面倒をみれるもので、社内の他のチームから利用できる仕組みを作ろうとして始まったのが、現在の形です。そしてタイミング良く、ElasticsがElastic Cloud on Kubernetes (ECK) (ref: https://github.com/elastic/cloud-on-k8s) を公式に組み入れて、SaaSスタイルでElasticsearchを作れるようになる、という噂も流れてきていました。バージョンも1を超えてたので、使ってみようということで、検証し、小規模Elasticsearchクラスタから導入してみた結果、大きな問題もなさそうだったので、現在は全てElastic Operator管理下で運用しています。
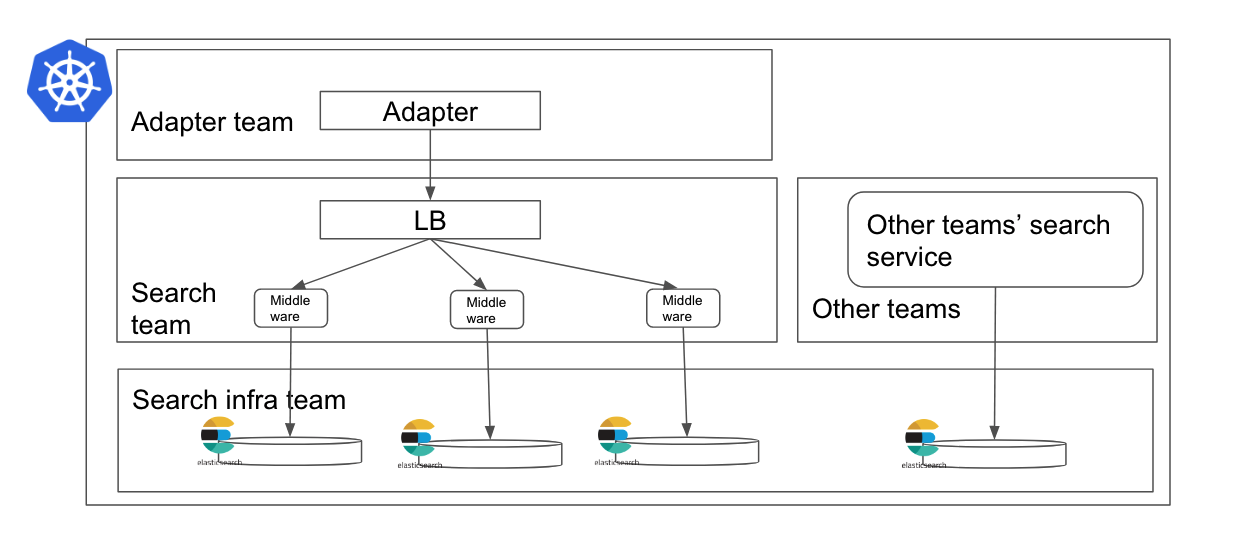
現在のアーキテクチャはこんな感じです。

Elasticsearchを動かせるネームスペースを限定することで、Elastic operatorが権限を持つ範囲を絞っています。同様に、管理するメンバーも集中してます。普段の運用に必要な権限はサーチインフラチームが持ってますが、各チームのElasticsearchごとに異なる、インデックス関連の不具合などは各チームに権限を一時的に渡せる仕組みが社内にはあります。(Shifting to Zero Touch Production
)社内共通基盤化はまだはじまったばかりの試みで、アーキテクチャもまだまだ発展途上です。改善点は山ほどあるのですが。。。また4年後にお会いしましょう!
まとめ
まとめてみます。検索基盤は開発スピードと制約がないことを優先して、独自クラスタで開発がはじまりました。メルカリの検索とKubernetesの最適な組み合わせに集中することができました。しかしやがて独自クラスタの運用が重荷になりはじめ、社内で共通して利用されるGKEに合流することになりました。独自クラスタで得た知見は引き継いだまま、任せられるところは任せる形にできました。現在は、共通GKEの中で構築した検索基盤を他のチームからも使えるようにして、比較的簡便に検索サービスの立ち上げをできるものを目指しています。
サーチインフラチームでは社内でも特に大きなコンピューティングリソースを使う、エキサイティングな検索基盤を運用してます。役割は今後も増え続けますし、より高度な最適化が求められており、これらを一緒にすすめていただけるメンバーを募集中です。ご興味があれば、まずはカジュアルな面談 という形でのご案内もできますので、ご連絡いただければ幸いです。




