
こんにちは。メルペイのMachine Learningチームの@hiroです。Merpay Advent Calendar 2021 の18日目の記事をお届けします。
機械学習の社会的重要性の高まり
近年、機械学習という技術領域が人口に膾炙し、多くの産業やプロダクトに用いられるようになってきています。機械学習は、アルゴリズムによって、蓄積されたデータのパターンを学習し、従来ひとの判断やルールベースで行ってきた意思決定を自動化、高精度化することで、様々な産業の生産性向上に寄与し、私達の生活を豊かにしてきました。私達の社会にとってなくてはならない技術領域のひとつになっています。
一方、そうした機械学習の自動判断において、結果的に差別的な振る舞いをしてしまったり、お客さまに不愉快な体験をさせてしまったりといった、社会にネガティブな影響を与えてしまう事案も発生しています。この記事で具体的な事例をとりあげることは控えますが、多くのメディアに掲載された事例もありますので、記憶にある方も多いのではないかと想像します。
機械学習の社会的な重要性が高まる一方、その社会適用におけるリスクも広く認知されるようになってきたといえるでしょう。
機械学習に求められること
こうしたリスクが認識されるにつれ、当然の反応として、機械学習の責任ある利用を求める動きが出てきています。企業が公開している倫理ガイドラインのほか、政府機関が公開している文書もあります。[1][2]
また、昨今、公平性に配慮した機械学習技術の研究がなされています。2008年頃にはすでにこうした研究はされていたようですが [3]、昨今の機械学習の普及とともに世界的に興味関心を引く領域になってきています。
本稿では、機械学習に求められつつあるガバナンスや倫理等のなかから、特に、データにもとづく公平性指標や、公平性に配慮した機械学習モデルの学習についていくつか紹介します。
機械学習エンジニアにできること
機械学習エンジニアはプロダクトを通じて機械学習のアウトプットを社会に届けます。当然のことながらプロダクトには多くの役割の人たちが関わりますので、全員で、All for Oneで公平性に配慮する必要があります。また、公平性に対する考えは社会や時代によって変わり得るものですし、技術だけで解決できるものではありません。社会と技術の関わりのなかで考えるべき事柄であるという意味で、socio-technicalな領域であるという言い方をすることもあります。
複雑で丁寧な議論が必要なトピックですが、機械学習エンジニアの参画なしに解決できる課題ではなく、一人ひとりが知識を身につけ、出来ることを見つけ、提案していくことが必要になるでしょう。
以降のセクションでは、機械学習における公平性について、技術的な側面から紹介したいと思います。
公平性の指標
公平性を機械学習で扱うためには、公平性の数学的な表現が必要になります。以下では、代表的な指標をいくつか提示します。
Equalized Odds
Equalized Odds [4] は以下の数式で表現されます。
$$P(\hat{Y}=1|A=0,Y =y)=P(\hat{Y}=1|A=1,Y =y)$$
ここで、\(Y\)はターゲット(実際にあるイベントが起きたか否か)、\(\hat{Y}\)は機械学習モデルによる予測値、Aはセンシティブ属性を表します。\(y\)は0か1の想定です。つまり、\(y∈\lbrace{0,1}\rbrace\)です。これはつまり、センシティブ属性によらず、true positive rateとfalse positive rateは等しくありなさい、ということになります。
Demographic Parity
Demographic Parity [5] は以下の数式で表現されます。
$$P(\hat{Y}|A=0)=P(\hat{Y}|A=1)$$
ここで、\(\hat{Y}\)は機械学習モデルによる予測値、Aはセンシティブ属性を表します。つまり、センシティブ属性によらず、同じ予測分布でありなさい、ということになります。
Equal Opportunity
Equal Opportunity [4] は以下の数式で表現されます。
$$P(\hat{Y}=1|A=0,Y=1) = P(\hat{Y}=1|A=1,Y=1)$$
記号の定義は上述の指標と同じです。センシティブ属性によらず、true positive rateが等しくありなさい、ということになります。Equal OpportunityはEqualized Oddsより数学的な意味で緩い条件であるといえます。
以上の指標のほかにも、「似た個人同士は近い予測値を得られる」べきであるとするFairness Through Awareness、「センシティブ属性を明示的に用いないとしても公平である」べきとするFairness Through Unawareness等があります。
Fairlearnによる実装
このセクションではクレジットカードの貸倒れデータを用いて、公平性指標を考慮した機械学習モデルの学習をしていみたいと思います。また、PythonパッケージのFairlearnを用います。以降のサンプルコードはFairlearnのチュートリアル [6] 等を参考にしています。
pip install fairlearn使用するデータはUCI default of credit card clients Data Setです。ターゲット変数はデフォルトしたか否かの二値、そのほか、説明変数の候補となる変数は23個あります。
なお、今回使用する特徴量は、メルペイの与信モデルで使用している特徴量とは異なります。あくまでもデモンストレーション用である点はご承知おきください。
import numpy as np
import pandas as pd
# データの読み込み
data_url = "http://archive.ics.uci.edu/ml/machine-learning-databases/00350/default%20of%20credit%20card%20clients.xls"
dataset = pd.read_excel(io=data_url, header=1).rename(columns={'PAY_0':'PAY_1'})
# 今回使用しないカラムを削除する
dataset.drop(['ID', 'EDUCATION', 'MARRIAGE', 'AGE'], axis=1, inplace=True)
# センシティブ属性
A = dataset["SEX"]
A_str = A.map({ 2:"female", 1:"male"})
# ターゲット変数
Y = dataset["default payment next month"]
# カテゴリ変数の処理
categorical_features = ['PAY_1', 'PAY_2', 'PAY_3', 'PAY_4', 'PAY_5', 'PAY_6']
for col in categorical_features:
dataset[col] = dataset[col].astype('category')
# デモンストレーションのため、あえて不公平性が高まるような新しい変数を作成する
np.random.seed(12345)
dataset['new_feature'] = Y + np.random.normal(scale=0.5, size=dataset.shape[0])
dataset.loc[A==1, 'new_feature'] = np.random.normal(scale=0.5, size=dataset[A==1].shape[0])まず、普段どおりLightGBMで学習して結果を確認します。
import lightgbm as lgb
from sklearn.metrics import roc_auc_score
lgb_params = {
'objective' : 'binary',
'metric' : 'auc',
'learning_rate': 0.03,
'num_leaves' : 10,
'max_depth' : 3
}
model = lgb.LGBMClassifier(**lgb_params)
model.fit(df_train, Y_train)
# TrainデータのAUC
print(roc_auc_score(Y_train, model.predict_proba(df_train)[:, 1]))
# TestデータのAUC
print(roc_auc_score(Y_test, model.predict_proba(df_test)[:, 1]))学習結果は以下のようになりました。
Train AUC: 0.8519331542909458
Test AUC: 0.8539748600475574
次に公平性指標を確認します。本稿ではtrue_positive_rateとfalse_positive_rateの比較およびEqualized Oddsを確認します。
from fairlearn.metrics import (
MetricFrame,
false_positive_rate,
false_negative_rate)
mf = MetricFrame({
'FPR': false_positive_rate,
'FNR': false_negative_rate},
Y_test, test_preds, sensitive_features=A_str_test)
mf.by_group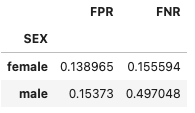
次にEqualized Oddsを確認します。ここではfairlearn.metricsのequalized_odds_differenceを用います。この指標はセンシティブ属性の各値間のtrue positive rateの差とfalse positive rateの差のうち、大きい方の値を返します。つまり、この値が小さいほうが公平性が高いと考えることができます。
from fairlearn.metrics import equalized_odds_difference
equalized_odds_difference(Y_test, test_preds, sensitive_features=A_str_test)結果は0.3414540005449096となりました。
では次に、Equalized Oddsの不公平性を低減しながらモデル学習を行います。前述のモデル学習部分を以下のように書き換えます。Equalized Oddsの考慮をモデル学習の制約として与え、学習データにfitします。また、そのときにセンシティブ属性を引数として与えます。
from fairlearn.reductions import EqualizedOdds, ExponentiatedGradient
constraint = EqualizedOdds()
model = lgb.LGBMClassifier(**lgb_params)
mitigator = ExponentiatedGradient(model, constraint)
mitigator.fit(df_train, Y_train, sensitive_features=A_str_train)このモデルは以下のような学習結果となりました。
train AUC: 0.6707452285620544
test AUC: 0.6703938947979562
また、公平性指標は以下のような結果となりました。
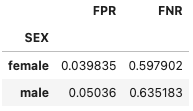
Equalized Odds Differenceは0.03728090091726455でした。
Fairlearnを用いてモデル学習をすることで、Equalized Odds Differenceが大幅に改善することが確認できました。
一方、精度指標であるAUCが悪化したことも確認できます。一般的に機械学習モデルの精度と公平性指標が同時に良い結果をもたらすとは限りません。トレードオフがあることを念頭におきながら適切なモデルの探索をする必要があります。
まとめ
代表的な公平性指標と、Fairlearnを用いて公平性に配慮した機械学習モデルの学習について紹介しました。本稿前半部分でも記載した通り、公平性は機械学習技術だけで実現可能なものではないものの、データを扱う我々機械学習エンジニアが、関連する知識と技術を習得し、公平性に配慮していく機会は今後増えていくのではないでしょうか。
参考文献
[1] 人間中心のAI社会原則
[2] AI利活用ガイドライン
[3] Dino Pedreshi, Salvatore Ruggieri, Franco Turini “Discrimination-aware data mining” KDD ’08: Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining (2008)
[4] Moritz Hardt, Eric Price, Eric Price, Nati Srebro “Equality of Opportunity in Supervised Learning” Advances in Neural Information Processing Systems. 3315-3323 (2016)
[5] Matt J Kusner, Joshua Loftus, Chris Russell, Ricardo Silva “Counterfactual Fairness” Advances in Neural Information Processing Systems, 4066-4076 (2017)
[6] Fairlearn Quickstart




