
Merpay Tech Fest 2021は、事業との関わりから技術への興味を深め、プロダクトやサービスを支えるエンジニアリングを知れるお祭りで、2021年7月26日(月)からの5日間、開催しました。セッションでは、事業を支える組織・技術・課題などへの試行錯誤やアプローチを紹介していきました。
この記事は、「Scenario-Based Integration Testing Platform for Microservices」の書き起こしです。
森健太氏:それでは、始めさせていただきます。「Scenario-Based Integration Testing Platform for Microservices」というタイトルで発表します。よろしくお願いします。

株式会社メルペイの森健太と申します。Twitterや、GitHubのIDは、@zoncoenでやっています。メルペイリリース前の2018年に入社しまして、今はアーキテクトチームに所属しています。本発表では、私が開発しているマイクロサービスのインテグレーションテストを行うための仕組みについてお話します。

こちらがアジェンダになります。
Introduction

それではまず、イントロダクションということで、なぜ、社内向けのインテグレーションテストプラットフォームをつくっているのか、その背景についてお話させていただきます。

まず最初に、メルペイのアーキテクチャについて簡単にご紹介します。メルペイは、開発当初からマイクロサービスアーキテクチャを採用していて、複数のチームがそれぞれ別のサービスを並行して開発・運用してきました。アプリケーションの実行環境にはフルマネージドのKubernetes環境であるGoogle Cloud PlatformのGoogle Kubernetes Engineを利用しており、そのKubernetesクラスタ上にネームスペースを切って、各マイクロサービスをデプロイしています。ほぼすべてのサービスはGoで実装されていて、基本的にはProtocol Buffersで定義したスキーマをもとにgRPCで通信しています。クライアントとなるメルカリアプリや、メルカリのウェブサイトからはHTTPでリクエストされるので、API GatewayでgRPCに変換したうえで各マイクロサービスにリクエストが送信されます。データストアとしては、おもにCloud Spannerを利用しており、ほかにもCloud Storageや、Cloud Pub/Subなど、GCPのサービスを利用しています。

マイクロサービスアーキテクチャを採用したときのメリットとしては、次のようなものがあります。1つ目は、より良いメンテナビリティ、テスタビリティ、デプロイアビリティです。ドメインごとに小さなサービスに分割することで見通しが良くなり、独立したリリースサイクルで開発することができます。また、関心事が分離されていることで、1つのサービスに対するテストもしやすくなります。2つ目は、スケーラビリティです。サービスが分割されているので、必要なサービスのみスケーリングすることで効率良くリソースを使うことができます。3つ目は、fault isolationの向上です。例えばメモリリークのような問題がシステム全体に影響を与えるといったことがありません。モノリシックなアプリケーションの場合は、サービス全体が1つのサーバー上で動いていることが多いと思うので全体が影響を受けてしまいますが、マイクロサービスではその影響を局所的なものにとどめることができます。4つ目は、Technology lock-inの排除です。マイクロサービスではアプリケーションの実装が分離されているので、各サービスは、それぞれのサービスに適切な言語や技術スタックを自由に選択することができます。これらのメリットは、メルペイがマイクロサービスアーキテクチャを採用することで実際に得られているメリットになります。

一方で、マイクロサービスアーキテクチャでの開発には困難な点もあります。1つ目は、コミュニケーションの複雑さです。モノリシックなアプリケーションではただの関数呼び出しだったものが、マイクロサービスではネットワークを経由した通信になったりします。ネットワークを介するということは、その通信に失敗することもあるので必然的に複雑なものになりがちです。2つ目は、デバッグの難しさです。複雑な依存関係を持つマイクロサービスで問題が起きた場合、その問題の原因を特定することは難しいことが多々あります。場合によってはほかのチームと連携して、ほかのチームが開発しているマイクロサービスのソースコードを読むことになるかもしれません。3つ目は、デプロイの難しさです。メリットを紹介した際に、独立したリリースサイクルでデプロイできると話しましたが、機能によっては、依存しているマイクロサービスと同時にリリースする必要があったり、リリースする順番に制約がある場合があります。そのような場合、デプロイの手順は複雑なものになるかもしれません。4つ目は、グローバルなテストの難しさです。複数のサービスがそれぞれ独立したチームによって開発されて独立してリリースされるので、複数のサービスに依存した機能テストというものは難しいものになりがちです。

これらは、メルペイで実際に体験している難しさ、困難性になります。それぞれの難しさを軽減するために、メルペイではいろいろな工夫をしていますが、本発表でお話しするintegration testingプラットフォームは、この4つ目に当たるテストの難しさというものを緩和するためのアイデアになります。

ここで、integration testingの定義をはっきりさせておくために、マイクロサービスのテスト戦略について触れておきます。マイクロサービスにおけるテストは、粒度や目的によっていくつかのテスト戦略があります。ここに挙げている5つの定義は、マイクロサービスアーキテクチャを提唱したうちの1人であるMartin Fowler氏のウェブサイト、martinfowler.comで紹介されているものになります。

それぞれの戦略の違いについて説明するために、ここではこのようなアーキテクチャを例にとって説明します。
この例では、クライアントからリクエストがまず1つ目のエクスターナルサービスを通って、テスト対象の真ん中のサービスに来て、そのサービスがエクスターナルデータストアに加えて、もう1つのエクスターナルサービスに依存しているというようなものになります。

まず1つ目は、ユニットテストです。ユニットテストはいわゆる単体テストです。例えば1つの関数単体など、テスト可能な最小単位のコードに対するテストを指します。ユニットテストは、シンプルで高速にテストができることがほとんどかと思います。
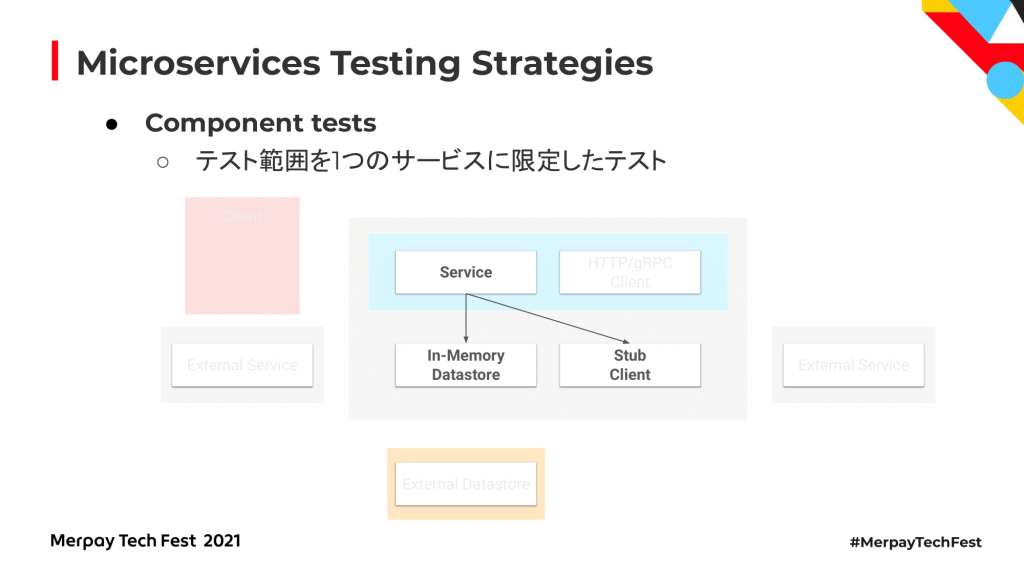
次が、コンポーネントテストです。コンポーネントテストは、外部のデータストアやほかのマイクロサービスへの通信は実際には行わず、テスト範囲を1つのマイクロサービスに限定してテストを行います。外部のコンポーネントに依存している部分は、データストアであればIn-Memoryのデータストアを使ったり、通信部分に関してはモックやスタブを使うことでテストを行います。実際にはネットワークを介した通信は発生しないため、こちらも比較的簡単で高速にテストすることが可能です。

3つ目の戦略は、コントラクトテストです。コントラクトテストは、ほかのテストと少し毛色が違いますが、あるサービスに依存しているサービスであるコンシューマが期待しているAPIの仕様を、依存先であるプロバイダが満たしているかどうかというものをテストするものになります。コンシューマ側は、プロバイダに共有した仕様に沿ったスタブを使うことで、コンポーネントテストでは問題ないのにいざ実際に接続して通信してみるとうまく動かないというような問題を起きにくくすることができます。メルペイの場合はgRPCで通信しているので、APIに関してはProtocol Buffersでスキーマの定義がされています。そのスキーマの定義がコントラクトテストに期待されている役割の一部を担っていると言えるかもしれません。

次が、インテグレーションテストです。これは、実際に外部との通信を行うことで、通信経路や相互作用の検証も行うテストになります。実際に通信を行うため、ネットワークや外部サービスの状態がテストの結果に影響してくるので、テストケースの作成がそもそも難しかったり、失敗したときに複数のサービスの状態が結果に影響してくるので、調査にかかるコストが比較的高くなりがちです。

最後が、End-to-endテストです。これはその名のとおり、端から端までシステム全体を使ったテストになります。入力はアプリやブラウザの操作になるかと思います。インテグレーションテストよりも、さらに関わるコンポーネントが多いので、テストの追加やメンテナンスというのは非常にコストの高いテスト方法になります。

ここまで5つのテスト戦略を紹介したのですが、これらのテストはここに挙げたような手法を使ってそれぞれ行うことができるかと思います。ユニットテストやコンポーネントテストに関しては、1つのサービスのソースコードに閉じたテストなので、Goの場合であれば、標準のGoテストコマンドなどを使ってGoのテストとして単体テストを行うことができるでしょう。コントラクトテストに関しては、さまざまな言語で利用できるフレームワークとしてPactというフレームワークがあるのでそちらを利用すると、先ほど言ったようなコンシューマ側で定義している仕様に沿ってプロバイダ側が動作するかというのをテストすることができます。インテグレーションテストでは、実際の通信経路も確認できるように、実際にサーバーに対してリクエストを送信する必要があります。そのような目的で有名なツールとしてPostmanが挙げられるでしょう。Postmanを使ってリクエストを実際に投げてレスポンスを検証することでテストができるかと思います。最後のEnd-to-endテストに関しては、入力としてアプリやブラウザの操作が必要なので、Appiumだったり、XCUITest、Cypressなどが使われているかと思います。あとは、QAチームの手動操作によるテストなどもこのEnd-to-endテストに含まれるかと思います。

本発表でテーマにしているインテグレーションテストやEnd-to-endテストは、各マイクロサービスが実際に通信する状態でテストをする必要があるため、ほかの3つのテストと比べて、そもそもテストすること自体が難しかったり、テスト自体のメンテナンスもほかと比べてコストは高くなりがちです。この発表でお話しするtestingプラットフォームは、この2つのうちのインテグレーションテストにフォーカスして、コストを抑えながらインテグレーションテストを実際に回して品質を高めることを目的としてつくっているものになります。
Test Runner

次は、実際にそのテストを行うためのテストランナーについてお話しします。

インテグレーションテストで利用するテストランナーには決められたとおりにリクエストを送信して、サーバーから返ってきたレスポンスが期待しているものと一致しているかを確認できる機能が求められます。

そのような機能を持っているツールとして代表的なものの1つが、先ほども触れたPostmanかなと思います。Postmanは、JSON over HTTPなAPIサーバーのテストを行うためのツールです。こちらが公式のウェブサイトへのリンクになります。特徴としては、GUIのアプリケーションが用意されていて、初めて触るときにも結構とっつきやすいかなと思います。あと、既存のCIに組み込みやすいです。基本的に実行は、そのGUIアプリケーション上で行えるのですが、CIとかに組み込むためにNewmanというCLIツールがあって、Newmanを使うとGUIアプリケーションでつくったテストをCLIから実行することができるようになっています。あと、JavaScriptのコードが実行できることも特徴です。例えばリクエストボディの生成にUUIDを生成する処理はJavaScriptのコードとして書けます。レスポンスボディの確認もJavaScriptのコードとして書けるようになっているので、割と柔軟に確認自体はできるかなと思います。

これが、GUIアプリケーションのスクリーンショットです。これは実際に、簡単なメッセージを1個送るだけのもののスクリーンショットになります。

Postmanの苦手な部分というか、うちで使うときにあまり合っていないと思った点として、まず、JavaScriptが使えると言ったのですが、JavaScriptで書けるコードに制約があって、任意のJavaScriptのライブラリを追加することができません。サードパーティーのJavaScriptのライブラリだけでなく、そもそも汎用的な処理を関数化して使い回したくなることがあると思うのですが、そういうことも素直にはできないような仕組みになっています。一応、グローバル変数に関数を突っ込んでevalすればできたりするみたいなのですが、あまりお行儀のいいやり方ではないかなとは思います。もう1つ、これが結構大きい理由なのですが、プルリクエストベースでのメンテナンスが結構難しいと思っています。先ほど話したとおり、基本的にGUIのアプリケーション上でテストを書くのですが、それをソースコードと同じようにプルリクエストベースで管理するためにエクスポートしたテストの定義というのがJSONの結構複雑なファイルになります。なので、プルリクエストベースでGitHub上での差分の確認が難しく、デベロッパーフレンドリーではないかなと個人的には思います。

例えば簡単なメッセージを1個送って、それがそのまま返ってきていることを確認するというテストでも、エクスポートするとこんな感じのJSONになってしまうので、これを手で書いたり、読んだりというのは結構大変そうだと皆さんも感じるかなと思います。

Postmanには、そのような私たちの使い方に合わないところがあったので、今回は新しくツールを自作することにしました。Scenarigoというツールをこのプラットフォーム向けに自作しています。Scenarigoというのは、Postmanと同じようにAPIサーバーのシナリオテストを行うためのツールになっています。ここにリポジトリへのリンクがあるんですけど、こちらはテストシナリオをYAMLで書けるようにしています。特徴としては、書いたテストのシナリオを使い回すことができたり、JavaScriptではなくGoで拡張することができたり、HTTPだけでなくgRPCが使えるという点などがあります。

簡単なテストシナリオの例がこちらになります。なぜYAMLかというと、先ほど見たようなJSONよりYAMLの方が、そもそも手で読み書きしやすいと個人的には思うのでYAMLを採用しています。

この例を実際に実行すると、こんな感じでScenarigoからリクエストをecho-serviceあてに投げて、返ってきたレスポンスをエクスペクトのとおりかどうか確認します。合っていたらテストがパス、期待しているものと異なっていたらテストがfailします。

テストシナリオの再利用ができるという話を先ほどさせていただいたのですが、これの何がうれしいかというと、テストシナリオをどんどん書いていくと、汎用的というか、共通して行いたい処理が出てくると思うんですね。例えばユーザーをつくってログインするだとか、メルペイみたいな決済のサービスだと、つくったユーザーに対して支払い決済が行えるように、例えば残高を付与するとか、そういうどのテストシナリオでも割と使うようなシナリオがいくつも出てくるので、それが再利用できると見通しが良くなるということで、そういうことができるようになっています。

あと、Goで拡張可能と言ったのですが、メルペイでは、ほとんどのアプリケーションがGoで書かれており、エンジニアは基本的にGoを使い慣れている人が多いので、私たちにとってはGoで拡張できることが使いやすさにつながるかなと思って、Goで拡張可能なものにしています。

こんな感じで、Goの標準のプラグインパッケージを使ってプラグインをつくって、つくったプラグインをYAMLから呼び出すことができるというような感じにしています。この例だと、UUIDを生成する関数みたいなものをプラグインで実装して、それを実際に呼び出して使うみたいなシナリオになっています。

このScenarigoを使って、YAMLでテストシナリオを書いて、実際リクエストを投げてレスポンスが正しいかを検証するということがまずできるようになりました。
Continuous Integration

次に、コンテニュアスインテグレーションについてお話します。

Scenarigoを使ってリクエストを投げてレスポンスを検証するというところができるようになったので、次はコンテニュアスインテグレーション、CIについて考えます。例えばGitHubへのプッシュをトリガーにしてテストを実行したり、依存しているサービスも含めたリグレッションテストとして定期的な自動実行などをできるようにする必要がありました。

そのような機能を実現するため、私たちのプラットフォームではProwというツールを使っています。こちらは自作しているものではなく、Kubenetes上で動くオープンソースのCI/CDのシステムになります。Kubernetesのクラスタ上でジョブを実行できるものです。Kubernetes自体のテストにも使われています。GitHubのコミットをトリガーにしたり、指定したスケジュールに合わせてジョブを実行するということもできるようなものになっています。こちらがリポジトリへのリンクです。
なぜ、Prowを選んだかというと、1つ大きな理由があって、それはKubernetesのクラスタ上で実行されるというところです。クラスタ上で実行されるということは、クラスタ外からのアクセスをマイクロサービス側で許可する必要がないため、わたしたちのユースケースにフィットしていました。


これはKubernetesのテストのダッシュボードのスクリーンショットなんですけど、こんな感じでダッシュボードが用意されていて、テスト結果やログが見られるようになっています。

Prowのテストフローですが、こんな感じでWebhooksが来ると、まず、フックコンポーネントというものにリクエストが行きます。

それをトリガーにしてProwJobというカスタムリソースをつくります。このhorologiumというのは、定期的にジョブをトリガーするために使われるコンポーネントです。

フックとかhorologiumがProwJobをつくると、plankというProwJobのコントローラーがリコンサイルしてKubernetesの標準のJobをつくります。

そのあとJobからPodができて、このPodの中でScenarigoを動かすことができれば、Prowの仕組み上でテストをすることができます。
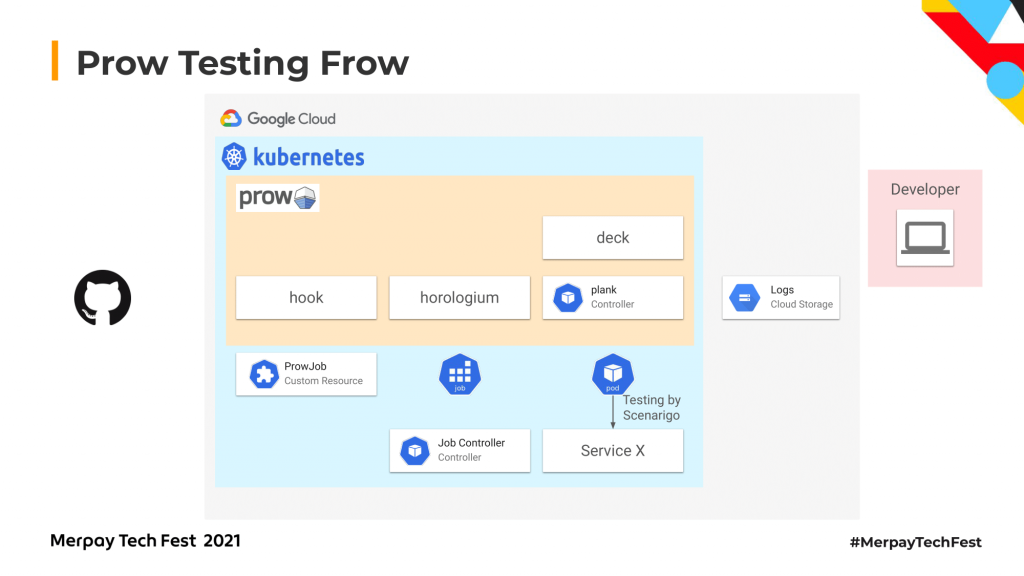
例えばここではService Xの方に矢印が向いていますが、実際にService XのテストをScenarigoを使ってやって、

最終的にその結果はクラウドストレージにログとしてアップロードされます。
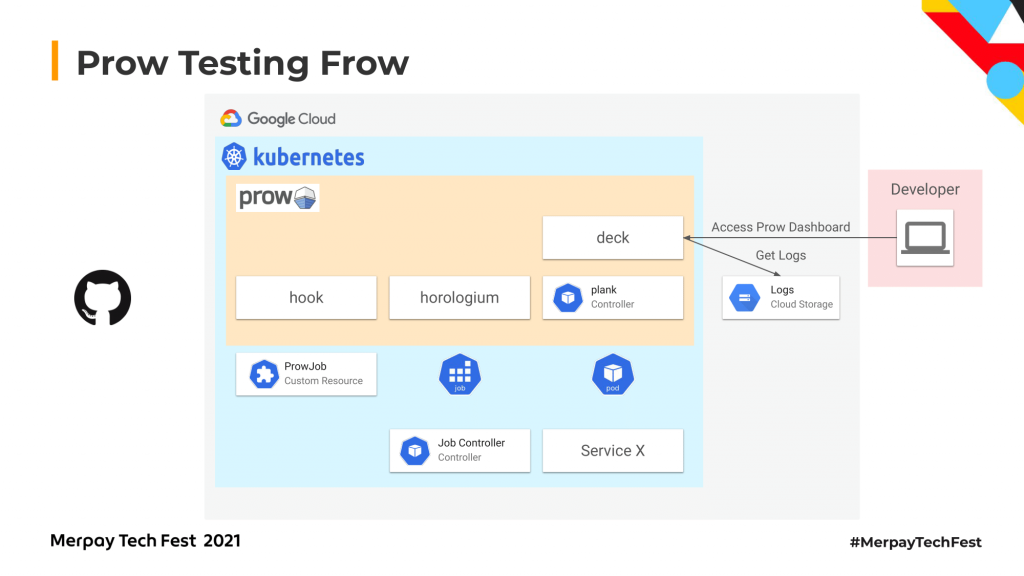
先ほどスクリーンショットで見せたようなダッシュボードにアクセスすると、結果をユーザーが確認できるようになっています。

これによって、ProwとScenarigoを使ってKubernetes上で定期的にインテグレーションテストを実行することができました。
Testing in the Real World

これで終わりかというと、テストというのは実際に動かしてみるといろいろほかにも問題が出てくるもので、現実的にはほかにもいろいろ考えることがありました。

テストを書くときはやはりローカルでテストシナリオを書いて、ローカルから実行したくなると思います。しかし同じクラスタ上で動作するProwJobでの実行とは違い、ローカルからインターネット越しにリクエストを投げることができません。
なので、そこをなんとかする必要がありました。今、私たちのプラットフォームの場合は、telepresenceというツールを使ってリクエストをプロキシできるようにして解決しています。telepresenceというのは、Kubernetes上で動作するアプリケーションを開発するときに、その開発を楽にするためのツールで、そのうちの機能の1つにtelepresenceでクラスタ内にリクエストをプロキシできるようにする機能があるので、ローカルで実行するときはこれを使って実行しています。

Prowで作成されたScenarigoを動かすPod場合はここに書いているとおり、

同じクラスタ上にあるためfoo-serviceにリクエストを送信することができますが、

先ほど話したとおりローカルからはそもそも名前解決もできずアクセスしようがありません。

そんな場合にtelepresenceを使うと、telepresenceでは、トラフィックマネージャーというコンポーネントがKubernetesのNamespace上にできるので、そことローカルで実行したtelepresenceコマンドによってトンネリングがなされます。

ローカルからリクエストを投げるときにクラスタ内へのリクエストに関してはこのトンネルを使ってプロキシされて、このトラフィックマネージャーが実際にfoo-serviceにリクエストを投げるみたいなことができるようになっています。なので、telepresenceを使うと、ローカルからリクエストを投げて実際にテストするということが可能になります。

また、Kubernetes上でテストを実行するときに設定している環境変数をローカルでも参照できるようにしたり、sshfsというものを使ってKubernetes上のSecretをローカルにマウントすることもできるので、手元に手作業でクレデンシャルをコピーしなくてもテストができるというように便利な機能がいろいろあります。

telepresenceによってローカルから実行しにくいという問題は解決できたのですが、現実的にはほかにもいろんな問題があります。例えばテスト用のデータの作成や管理というのはインテグレーションテストに限らずすごく難しいと思います。今、私たちのインテグレーションテストのプラットフォームではどうしているかというと、基本的にデータの作成に関しては、毎回テストを実行する度につくっています。使い回せるものに関しては、使い回せるもののIDとかをシナリオに含めることで再利用していますが、例えばユーザーはどのテストでもほぼすべてで必要なのですが、残高とかの情報があるので使い回すのがなかなか難しいんですね。そんな場合に、社内向けにソリューションチームの人がつくっているuser-tkoolというツールが社内向けにあるんですけど、こちらを使うとテストとか動作確認用に使うユーザーを簡単につくれるようになっているので、私たちのプラットフォームでもuser-tkoolを使っています。このuser-tkoolを使って、あらかじめユーザーを必要になりそうなものは大量につくっておくことで、それを利用するときに新しくつくるのではなくて、プールしてあるユーザーを使うことで高速化ということをやっていたりします。それ以外のデータに関しては、ケース・バイ・ケースなので、マイクロサービスごとに何か考えて対応しているというのが現状です。あと、時間に依存する機能のテストというのが結構大変で、環境を分けたり、リクエストごとに時間を指定してできるようにするということが案として考えているのですが、なかなかマイクロサービスをまたいで特定の時間のリクエストとして扱うというのは、現状はまだきれいに解決できていないので、これはまだ残っている問題としてあります。あと、非同期に処理されるような機能のテストです。間にPub/Subを挟んで、別のバッチか何かで、リクエストでつくられたデータをもとにさらに別のデータをつくるというような機能の場合、バッチが走って処理されたことをScenarigo側が確認することは基本的には難しいので、それを確認できるAPIみたいなものを用意してリトライし続けるしかないというのが現状です。これもあまり良い案が現状はないのですが、何か考えたいということも思っていることの1つです。

あと、開発している機能をプルリクエストの状態、マージしてない状態でもテストでしたいという要望もあって、社内ではその機能を実現するためにダイナミックサービスルーティングという機能が用意されていて、シナリオテストでもこちらを使ってプルリクエストの状態で、シナリオテスト、インテグレーションテストをすることができるようになっていたりします。

このダイナミックサービスルーティングに関しては、このあとの発表で同じアーキテクトチームの伊藤雄貴から発表するので、興味があれば、ぜひ聞いてみてください。
Conclusion

最後にまとめです。

私たちは、インテグレーションテストをするためのプラットフォームというものをここに挙げているScenarigoとか、Prowとか、telepresenceを使ってつくっていて実際に使っています。

このIntegration testingプラットフォームによって、マイクロサービスの品質の向上ができていると思います。今では、40を超えるマイクロサービスに社内では利用されています。先ほど挙げたような問題の解決に加えて、今後考えている追加機能としては、もうちょっとテストの結果を見やすくするビジュアライゼーションを頑張ったり、Protocol Buffersでメソッドの定義を使って、どのメソッドがテストできていて、どのメソッドがテストできていないかというカバレッジを出せるようにしたりということを考えていたり、あと、シナリオテストでは実際にリクエストを投げるので、どうしてもネットワーク越しに通信を行うのでテスト時間が伸びがちなるので、テスト時間を削減するために今も並列でテストを実行するという工夫をしているんですけど、そういうテスト時間削減を、できればテストは早ければ早いほど開発者としてうれしいので、ここも今後は頑張っていきたいなと思っています。
私からの発表は以上になります。ご清聴ありがとうございました。




