
こんにちは、メルペイソリューションチーム所属エンジニアの@orfeonです。
この記事は Merpay Tech Openness Month 2021 5日目の記事です。
メルペイソリューションチームでは、社内向けの技術コンサルや技術研修、部門を跨いだ共通の問題を発見して解決するソリューションの提供などを行っています。
自分は主に社内のデータ周りの課題を解決するソリューションを提供しており、一部の成果はOSSとして公開しています。
この記事ではいろいろな場面で必要とされるものの、運用負荷などの問題から導入の敷居が高い検索機能を(条件付きで)簡易に提供するためのソリューションを紹介します。
基本的なアイデア
全文検索や位置検索など、検索はいろいろな場面で必要とされる機能です。しかしいざ検索サーバを立てて運用するとなると、データの整合性やモニタリングなど考えないといけないことも多く、利用に二の足を踏むことも多いのではないでしょうか。
そこで利用条件に制限を少し加えて、データの更新をリアルタイムには行わない、サーバ1台で管理できない規模のデータを扱わない、とすることでお手軽に検索APIサーバを立てて活用できないかと考えました。
具体的には、検索APIサーバとするコンテナイメージに検索インデックスファイルを直接含めてしまうことで、データの更新・削除によるデータの一貫性の担保やインデックス変更などに伴うマイグレーションなどの面倒なデータの運用を無くします。
また構築した検索コンテナイメージをCloud RunやKubernetes Engineなどにデプロイすることで、サーバ・クラスタの運用負荷を軽減することを狙います。
さらに検索対象としたいデータはCloud Dataflowを使うことで様々なデータソースからSQLなどを指定して簡単に検索インデックスファイルとして取り込めるようにします。
運用が大幅に楽になるメリットが期待できる一方、最初に述べた次の制約も発生します。
- データの更新頻度はそれほど高くできない(1日数回)
- 一つのコンテナイメージに乗り切るデータしか扱えない
これらの制約を許容できる要件において検索APIを手軽に利用できるソリューションを紹介します。
全体システム構成
検索APIサーバの基本的な全体構成は以下図のようになっています。
ここでは検索エンジンにApache Solrを、検索対象データ元としてBigQueryからデータを読み込み、検索サーバをCloud Runで稼働する前提で説明をします。

検索インデックスの生成にはCloud Dataflowを利用します。
指定されたSQLを使って検索対象となるデータをBigQueryから読み込み、指定されたスキーマファイルを使ってSolrのインデックスファイルを生成します。
Cloud DataflowのJob実行ではインデックス内容が変更となるたびにコードを修正しないですむよう、Flex Templateとしてあらかじめ登録しておき、インデックス生成時にSQLなどのパラメータを指定して実行します。
(ここで紹介したCloud DataflowのFlex TemplateはMercari Dataflow Templateのモジュールとして公開しています)
今回はBigQueryからのクエリ結果を検索インデックスとして使っていますが、モジュールを切り替えることでCloud SpannerやCloud Datastoreなどからもデータを取り込むことができます。
インデックスファイルからSolrの検索サーバのコンテナを生成するのにCloud Buildを利用します。Cloud Dataflowが生成したインデックスファイルを取り込んでSolr検索サーバのコンテナイメージを生成します。ビルドに必要なファイルはGitHub等のリポジトリで管理し、ビルド起動時にリポジトリからこれらのファイルを読み込んで利用します。なお起動にあたってトリガーを作成しておき、次に説明するCloud Schedulerから起動する際にはこのトリガーを実行します。
Cloud DataflowやCloud Buildをそれぞれ定期的に実行するのにCloud Schedulerを利用します。
Cloud Dataflowによるインデックスファイル生成の後にCloud Buildによる検索コンテナイメージ生成処理をキックするように時間をずらして設定します。
(Dataflow側でJob終了時にファイルを出力するようにしてCloud Functions経由で検索コンテナイメージ生成のCloud Buildを起動するようにもできますが、ここではよりシンプルな構成として時間をずらして別々に起動する想定で紹介します)
こうしてCloud Buildにより指定された周期で最新のデータが検索インデックスを持ったSolrの検索サーバがCloud Runにデプロイされます。
検索を利用したいサービスはこのCloud Runに検索リクエストを送って検索を利用することができます。
システム構築手順
検索APIサーバを構築するにあたって利用者は以下の6つの設定情報を準備します。
- Solr検索スキーマファイル
- 検索データを提供するSQL
- 検索インデックス構築用のパイプラインの設定ファイル
- 検索APIサーバを構築するDockerfile
- 検索APIサーバをCloud Runにデプロイするためのビルド設定ファイル
- Cloud Schedulerの起動設定
上3つは検索インデックスの要件が変わるごとに修正します。
その下の2つはSolrのバージョンアップなどAPIサーバを更新したい場合に修正します。
最後の1つは検索インデックスの更新タイミングを変更する際に修正します。
以下、これらの設定内容について説明します。
Solr検索スキーマファイル
検索スキーマの定義は、Solr向けに定義されている検索インデックスのスキーマで、検索要件に応じて以下のようなXMLを定義します。
<?xml version="1.0" encoding="UTF-8"?>
<schema name="content" version="1.5">
<fields>
<field name="ID" type="string" indexed="true" stored="true" required="true" />
<field name="Name" type="string" indexed="false" stored="true" required="false" />
<field name="Address" type="string" indexed="false" stored="true" required="false" />
<field name="Category" type="string" indexed="true" stored="true" docValues="true" required="false" />
<field name="CreatedAt" type="date" indexed="true" stored="true" docValues="true" required="false" />
<field name="LastDate" type="string" indexed="true" stored="true" docValues="false" required="false" />
<field name="Location" type="location" indexed="true" stored="true" required="true" />
<field name="Index" type="text_ja" indexed="true" stored="true" multiValued="true" />
</fields>
<uniqueKey>ID</uniqueKey>
<copyField source="Name" dest="Index"/>
<copyField source="Address" dest="Index"/>
<copyField source="Category" dest="Index"/>
<types>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="long" class="solr.LongPointField" sortMissingLast="true"/>
<fieldType name="double" class="solr.DoublePointField" sortMissingLast="true"/>
<fieldType name="date" class="solr.DatePointField" sortMissingLast="true"/>
<fieldType name="location" class="solr.LatLonPointSpatialField" docValues="true"/>
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.CJKWidthFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory" />
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="2"/>
</analyzer>
</fieldType>
</types>
</schema>このXMLでは、検索インデックスの設定として大きく4種類の要素を指定しています。
fields要素配下のfield要素では検索インデックスとして利用したいフィールド名とデータ型やインデックス付け条件を指定します。
uniqueKey要素ではユニークとなるフィールド名を指定します。
types要素ではフィールドで用いるデータ型や、必要に応じて形態素解析などのテキストの解析内容を指定します。
copyField要素ではインデックス用にフィールドを一つにまとめたい場合に利用します。
詳細な仕様はSolrのスキーマ定義のドキュメントを参照ください。
検索データを提供するSQL
検索データを提供するSQLでは、先に定義した検索スキーマのフィールド名やデータ型に合致するデータをBigQueryから読み込むためのクエリを定義します。
検索インデックスは毎回全部作り直すため、差分更新ではなく検索に必要なデータを全て取得するよう定義します。
検索インデックス構築用のパイプラインの設定ファイル
パイプラインの設定ファイルは、指定したSQLでBigQueryから読み取ったデータをSolr検索インデックスファイルに変換して保存するためのMercari Dataflow Template の設定ファイルで、以下のように定義します。
{
"sources": [
{
"name": "BigQueryInput",
"module": "bigquery",
"parameters": {
"query": "gs://example-bucket/query.sql"
}
}
],
"sinks": [
{
"name": "SolrIndexOutput",
"module": "solrindex",
"input": "BigQueryInput",
"parameters": {
"output": "gs://example-bucket/index.zip",
"coreName": "MyCore",
"indexSchema": "gs://example-bucket/schema.xml"
}
}
]
}BigQuery Sourceモジュールで先に定義したSQLを、SolrIndex SinkモジュールでSolrのスキーマファイルを置いたGCSのパスとインデックスファイルの出力先のGCSパスを、それぞれ指定します。
この設定ファイルもGCSに保存しておき、後に説明するCloud Schedulerによる起動時にこのGCSパスを指定することで、BigQueryからSolrインデックスファイルを生成するDataflow Jobが実行されます。
Cloud Schedulerから定義した設定ファイルを使ってDataflow Jobを実行するためにMercari Dataflow TemplateのFlexTemplateをContainer Registry (GCR)に登録してTemplateファイルをGCSに登録します。
まず GitHub からMercari Dataflow Template をcloneして以下コマンドを実行してGCRに登録します。
mvn clean package -DskipTests -f=pom_solr.xml -Dimage=gcr.io/{myproject}/{templateRepoName}次に以下コマンドでGCRに登録したコンテナからDataflow Jobを起動するためのTemplateファイルを登録します。
gcloud dataflow flex-template build gs://{path/to/template_file} \
--image "gcr.io/{myproject}/{templateRepoName}" \
--sdk-language "JAVA"検索APIサーバを構築するDockerfile
検索サーバのDockerfileでは以下例のようにSolrの公式イメージをベースに、Cloud Dataflowで作成した検索インデックスファイルをイメージ内に取り込むように設定しています。
FROM solr:8.9
USER root
RUN apt-get update && apt-get install -y apt-utils libcap2-bin
RUN setcap CAP_NET_BIND_SERVICE=+eip '/usr/local/openjdk-11/bin/java' && \
echo "/lib:/usr/local/lib:/usr/lib:/usr/local/openjdk-11/lib:/usr/local/openjdk-11/lib/server:/usr/local/openjdk-11/lib/jli" > /etc/ld-musl-x86_64.path
USER solr
ARG _CORE
COPY --chown=solr:solr ${_CORE}/data/ /var/solr/data/${_CORE}/data/
COPY --chown=solr:solr ${_CORE}/conf/ /var/solr/data/${_CORE}/conf/
ADD --chown=solr:solr ${_CORE}/core.properties /var/solr/data/${_CORE}/
ADD --chown=solr:solr ${_CORE}/solrconfig.xml /var/solr/data/${_CORE}/conf/
ENV SOLR_PORT=80この設定ファイルでは${_CORE}配下にCloud Dataflowにより生成された検索インデックスファイルが展開される想定となっています。${_CORE}はSolrのコア名を指しておりCloud Build実行時に変数として差し込まれます。
このDockerfileはGitHubなどのリポジトリで管理します。
検索APIサーバをCloud Runにデプロイするためのビルド設定ファイル
Cloud Buildのビルド設定ファイルでは、以下のステップで検索インデックスファイルからSolrコンテナイメージを生成してCloud Runにデプロイする処理を定義しています。
- Cloud Dataflow により生成されたIndexファイルを手元にコピー
- 圧縮された検索インデックスファイルを解凍
- 先に定義したDockerfileによりSolrコンテナイメージをビルド
- ビルドしたコンテナイメージをGCRにPush
- GCRに登録したイメージからCloud Runのインスタンスを更新
以下設定例になります。
steps:
- name: 'gcr.io/cloud-builders/gsutil'
args: ["cp", "gs://$PROJECT_ID-dataflow/$_CORE.zip", "index.zip"]
- name: 'gcr.io/cloud-builders/gsutil'
entrypoint: "unzip"
args: ["index.zip"]
- name: 'gcr.io/cloud-builders/docker'
args: ["build", "-t", "gcr.io/$PROJECT_ID/myindex", "--build-arg", "_CORE=$_CORE", "."]
- name: 'gcr.io/cloud-builders/docker'
args: ["push", "gcr.io/$PROJECT_ID/myindex"]
- name: 'gcr.io/cloud-builders/gcloud'
args: ["run", "deploy", "mysearch",
"--image", "gcr.io/$PROJECT_ID/myindex",
"--platform", "managed",
"--region", "$_REGION",
"--concurrency", "300",
"--cpu", "2",
"--memory", "4Gi",
"--port", "80",
"--min-instances", "1",
"--no-allow-unauthenticated"]
timeout: 3600s
substitutions:
_CORE: MyCore
_REGION: us-central1このビルド設定ファイルもGitHubなどのリポジトリで管理します。
なお、前準備として次に説明するCloud SchedulerからCloud Buildを起動するためにトリガーを設定しておきます。トリガーのソースとなるリポジトリとしてビルドファイルとDockerfileを管理しているリポジトリを指定します。またCloud Build構成ファイルとして、ここで定義したビルドファイルのパスを指定します。その他必要に応じて実行時に差し込みたい変数の値を定義しておきます。最後に次の節でCloud Schedulerから起動する宛先として使うために、設定したトリガーのIDを控えておきます。
Cloud Schedulerの起動設定
Cloud Schedulerでは先に準備したCloud DataflowのFlex Templateと、Cloud Buildのトリガーを定期実行するよう設定します。
次の例はCloud DataflowによるSolrインデックスファイル生成用のJobを毎朝4:30に実行するよう設定しています。
gcloud scheduler jobs create http create-index \
--schedule "30 4 * * *" \
--time-zone "Asia/Tokyo" \
--uri="https://dataflow.googleapis.com/v1b3/projects/${PROJECT_ID}/locations/${REGION}/flexTemplates:launch" \
--oauth-service-account-email="xxx@xxx.gserviceaccount.com" \
--message-body-from-file=body.json \
--max-retry-attempts=5 \
--min-backoff=5s \
--max-backoff=5m \
--oauth-token-scope=https://www.googleapis.com/auth/cloud-platform ^
--project myprojectCloud Dataflow の FlexTemplateを起動するAPIのリクエスト内容を示すbody.jsonでは以下のように先に登録したFlexTemplateのGCSパスとパイプライン設定ファイルを置いたGCSパスを指定します。
{
"launchParameter": {
"jobName": "myJob",
"parameters": {
"config": "gs://myproject/pipeline.json"
},
"containerSpecGcsPath": "gs://{path/to/template_file}"
}
}以下の例ではCloud Buildのトリガーを毎朝5時起動するよう設定しています。
gcloud scheduler jobs create http deploy-server \
--schedule "0 5 * * *" \
--time-zone "Asia/Tokyo" \
--uri="https://cloudbuild.googleapis.com/v1/projects/myproject/triggers/${TriggerID}:run" \
--oauth-service-account-email="xxx@xxx.gserviceaccount.com" \
--message-body-from-file=body.json \
--max-retry-attempts=5 \
--min-backoff=5s \
--max-backoff=5m \
--oauth-token-scope=https://www.googleapis.com/auth/cloud-platform \
--project=myprojectbody.jsonでは以下のようにビルドに利用したいブランチ名を指定したJSONファイルを手元に用意しておきます。
{ "branchName": "main" }検索APIを活用したサービス例
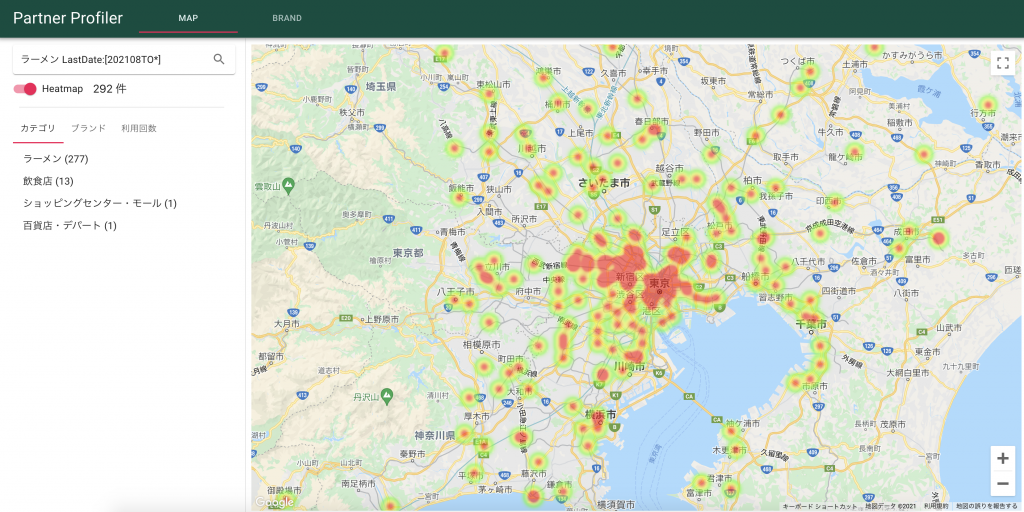
今回紹介したソリューションの活用例として、BigQueryに蓄積されたデータを使って社内向けに加盟店情報可視化サービスを提供している例を紹介します。
このサービス自体はAppEngineで動かし、その前段にIAP (Identity-Aware Proxy)を設定して社員認証を掛けます。AppEngineからCloud Runにデプロイした検索APIへのリクエストではサービス間認証を用いています。

Solrの位置検索機能を活用することで、以下のように絞り込み条件を指定して合致する店舗をヒートマップとして表示をしています。
クエリの例ではラーメンに関連してかつ直近に決済が発生した店舗を絞り込んでいます。
またヒートマップではなく地図上に個別に店舗をピン表示することもでき、直近決済が発生していない店舗を地図上で見つけて利用活性化を検討するなどのユースケースを模索しています。
検索APIでは位置検索や全文検索だけでなく、範囲検索やソート、ファセット集計なども用いることができ、検索だけでなくちょっとしたデータベースとして利用することもできます。
地図以外にも店舗やブランドごとに利用推移などをグラフ化などもサポートしています。
おわりに
今回はCloud Run上に手軽に検索APIサーバを構築するソリューションを紹介しました。
ちょっとした社内向けサービスや個人開発サービスなどに検索機能を導入したい場合、扱うデータ量がそれほど大きくなく更新頻度が日次でも許されるケースであれば、今回紹介したようなソリューションが役立つかもしれません。
1台に載せられるインデックスサイズについても、それほど複雑でないデータであれば1000万件くらいでも性能上問題なく動作しているため、適用できる範囲は割と広いのではないかと思います。
弊社では業務で生まれる様々なデータを日々BigQueryに蓄積されており、掘り起こされていないデータの活用方法がまだまだ眠っていると思っています。こうしたデータ活用を推進するために、データを色々な用途に楽に使えるようにするソリューションを引き続き提供していきたいと思います。
明日の記事は @yusuke_h さんによる 「メルペイのスケーラビリティを支えるマルチモジュール開発」 になります。お楽しみに。

