Cloud Spanner の実行計画の活用に関する取り組み
Merpay Advent Calendar 2020 の11日目は、メルペイ Solutions Team の apstndb がお送りします。
色々な場所で既に書かれている通り、メルペイはサービス開始当初から主要なデータベースとして Google Cloud Platform(GCP) の DBaaS である Cloud Spanner を使っています。
この記事ではメルペイにおける Cloud Spanner の実行計画の活用のために取り組んだことについて紹介します。
Cloud Spanner の特性である外部一貫性による強い一貫性保証、レプリケーションによる高い可用性、水平分散による高いスケーラビリティ、リレーショナルデータモデルによるスキーマ、フルマネージドなことによる低い運用負荷などは多くの業界にとってメリットがあるものですが、金融サービスであるメルペイも例外ではありません。
しかし、どのようなデータベースも謳っているメリットを得るには、その特性を理解して使う必要があります。従来のデータベースは多くのユーザが長い年月を掛けてチューニングのノウハウを蓄積してきましたが、Cloud Spanner は2017年に公開され Generally Available になったばかりと、他のデータベースと比べるとプロダクトとしての歴史が浅いため、十分に語られている領域とそうではない領域があるように私は感じます。
日本においては、ゲーム データベースとして Cloud Spanner を使用する場合のベスト プラクティスのソリューション記事をはじめとして、大規模・多人数のプレイヤーからの同時アクセスを捌く必要があるゲーム業界で得られたの課題に答えるための設計についての情報が多いという特徴があります。
プレイヤーに関するインベントリデータを保存するデータベースインスタンスを複数に分け、プレイヤー ID を使って振り分けるシャーディングをすることでデータベースアクセスをスケールするという設計がソーシャルゲームでは行われていました。このような設計は Cloud Spanner で関連する行のデータ配置を局所化するインターリーブ機能と相性がよく、ゲーム業界の課題と Cloud Spanner の特性もマッチしていたことから採用を検討する企業が多かったため、Google もゲーム業界を主要なターゲットとして力を入れていたことが伺えます。
ゲーム業界向けの情報が先行して増えたことで Cloud Spanner をスケールさせるための分散 KVS 的な側面についてはノウハウが集まっていますが、一方でまだ情報が蓄積されていない領域として SQL クエリのパフォーマンスチューニングがあります。
公式ドキュメントにも概念としての実行計画を説明する Query execution plans や Query execution operators についてのドキュメントはありますが、 SQL best practices のドキュメントでも変更前後の実行計画は載っていないなど、実際に取得できる実行計画や実行時プロファイル情報を見ながらクエリもしくはスキーマを変更してチューニングをするような例はまだ用意されていません。
金融サービスであるメルペイでは必ずしもユーザーの下にぶら下げられるとは限らないデータも多く、サービス開始から1年以上を経てマイクロサービスのアクセスパターンも多様になり、 SQL クエリのパフォーマンスに関する問題を経験することが多くなりました。私もソリューションチームとして社内の多くのパフォーマンス問題の解決に参加・アドバイスする機会がありました。
ここからパフォーマンス改善に関係して実行計画を活用するために行った取り組みについて紹介します。
実行計画の詳細なレビューの推奨
アラートなどでパフォーマンス問題が発覚した際に、該当するクエリの実行計画を確認して遅くなる理由が見つかるということが多くありました。これでは事後対応になってしまうため、本番環境のパフォーマンス問題を防ぐことは困難です。
SQL は宣言的で抽象度の高い高級言語であり、クエリのテキストから実際に実行エンジンで実行される処理を正確に予想することは難しいという問題があります。よって、プログラムのソースコードに組み込まれたクエリそのものをレビューするのでは不十分です。
実行計画を確認することで予想ではなく、現実の処理を確認できます。Cloud Spanner もコストベースのクエリオプティマイザであるため、データの分布を元に処理を選択するため、本番環境で実際に作られるデータがなければ完全に同じにはならない可能性がありますが、少なくともレビュー時点で実行計画を見て高速に実行することが難しいクエリは本番環境でも高速に実行されることはまずありません。実行計画のレビューを日常的に行うことで、実行計画が身近なものとなり複雑なクエリにも対応可能になっていくため、新しいクエリの導入時には可能な限りコードレビュー時に実行計画も確認することを推奨しています。
今まで他の SQL データベースのように Cloud Spanner の実行計画のレビューが広く行われていなかったことには、 Cloud Spanner の実行計画が扱いづらいことと実行計画の情報が少ないこととが原因としてあるという仮説を立てていたため、その問題を解決するためにいくつかの施策を行いました。
GCPコンソールによる実行計画の扱いづらさ
Cloud Spanner のドキュメントで実行計画を確認するために公式に提供されている唯一の選択肢は GCP コンソール上の Web UI からの取得です。それは、次のような問題を抱えています。
- Web UI から得られる実行計画を共有するにはスクリーンショットを取る必要があるが、複雑な実行計画では1画面に収まらない。
- Query execution operators のドキュメントに書かれているフィルタ述語が表示されないなど、必要にも関わらず省略されてしまう情報が多い。
WebUIのスクリーンショットを共有することで詳細にレビューしようとしても、実行計画の全体を共有することが難しくて一部しか共有されなかったり、詳細な情報も不足したりしているので、大まかな形状しか見ることができません。結果として、他の SQL データベースの実行計画ほどは役に立たなくなっています。
実行計画の可視化方法の検討
本来 Cloud Spanner 自身は非常に多くの情報を返していることが、下記のコマンドなどで API の実行結果の生データを読むことで確認できます。
$ gcloud spanner databases execute-sql ${DATABASE_ID}
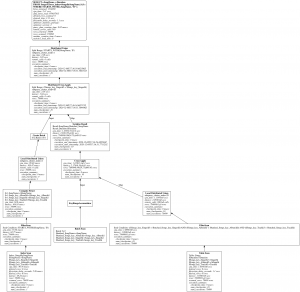
--sql="$(cat back_join.sql)" --format=yaml --query-mode=PROFILEこれらの情報を活用するため、実行計画に含まれる全ての情報を可視化する手段として、 apstndb/spannerplanviz を開発しました。
$ gcloud spanner databases execute-sql ${DATABASE_ID}
--sql="$(cat back_join.sql)" --format=yaml --query-mode=PROFILE |
spannerplanviz --full --show-query-stats --type=dot | dot -Tpng -o back_join.pngのように QueryMode=PROFILE もしくは QueryMode=PLAN の結果を ResultSet 型 の JSON/YAML 表現で受け取り、実行計画のツリーを SVG もしくは GraphViz が処理可能な dot ファイルとして出力することができます。
出力は下図のように Query execution operators のドキュメントの図を詳細にした形式で出力されます。

各ノードごとに Web UI では表示されないフィルタ述語の Condition や詳細な実行時統計情報が含まれていることが分かります。この形式は詳細すぎるため普段使うにはあまり向いていませんが、実行計画と実行統計情報を精査する時に有用です。
普段使いのための spanner-cli
Web UI も spannerplanviz も普段使いには一長一短な部分があるため、通常の利用にはトライアンドエラーをしやすい対話的でありながら、テキスト形式の出力で扱いやすい CLI ツールである spanner-cli を推奨しています。前述の spannerplanviz や社内でのクエリチューニングでの経験から実行計画ツリーの表示内容の改善やフィルタ述語の表示、実行計画を取得する EXPLAIN ANALYZE の実装などのコントリビューションをしたことで、私が最低限ほしい情報を気軽にレンダリングできるツールとしておすすめできるものになっています。
例として、上の例と同じ実行統計付きの実行計画が下のようにフィルタ述語も含めて共有しやすい形で表示されます。
> EXPLAIN ANALYZE
-> SELECT s.SongName, s.Duration
-> FROM Songs@{force_index=SongsBySongName} AS s
-> WHERE STARTS_WITH(s.SongName, "B");
+-----+-------------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+-----+-------------------------------------------------------+---------------+------------+---------------+
| *0 | Distributed Union | 78499 | 1 | 1.84 secs |
| *1 | +- Distributed Cross Apply | 78499 | 1 | 1.83 secs |
| 2 | +- [Input] Create Batch | | | |
| 3 | | +- Local Distributed Union | 78499 | 1 | 103.44 msecs |
| 4 | | +- Compute Struct | 78499 | 1 | 99.8 msecs |
| *5 | | +- FilterScan | 78499 | 1 | 59.79 msecs |
| 6 | | +- Index Scan (Index: SongsBySongName) | 78499 | 1 | 47.37 msecs |
| 20 | +- [Map] Serialize Result | 78499 | 4 | 1.22 secs |
| 21 | +- Cross Apply | 78499 | 4 | 1.18 secs |
| 22 | +- [Input] KeyRangeAccumulator | | | |
| 23 | | +- Batch Scan (Batch: $v2) | | | |
| 28 | +- [Map] Local Distributed Union | 78499 | 78499 | 1.05 secs |
| *29 | +- FilterScan | 78499 | 78499 | 991.52 msecs |
| 30 | +- Table Scan (Table: Songs) | 78499 | 78499 | 924.32 msecs |
+-----+-------------------------------------------------------+---------------+------------+---------------+
Predicates(identified by ID):
0: Split Range: STARTS_WITH($SongName, 'B')
1: Split Range: ($Songs_key_SingerId' = $Songs_key_SingerId)
5: Seek Condition: STARTS_WITH($SongName, 'B')
29: Seek Condition: (($Songs_key_SingerId' = $batched_Songs_key_SingerId) AND ($Songs_key_AlbumId' = $batched_Songs_key_AlbumId)) AND ($Songs_key_TrackId' = $batched_Songs_key_TrackId)
78499 rows in set (1.92 secs)
timestamp: 2020-12-09T02:59:36.228203+09:00
cpu: 1.67 secs
scanned: 156998 rows
optimizer: 2より柔軟な可視化
spanner-cli のような対話的なツールだけでなく、一度保存した実行計画を別の形式で表示するような形のツールも必要です。例えば、Advent Calendar 2日目のSpanner にクエリをレビューして実行する gchammer では本番環境の Cloud Spanner データベースに対してクエリを行うための社内サービスです。gchammerではクエリのレビュー時に実行計画を、クエリの実行後に実行統計付きの実行計画を生データで取得できるようになっています。このような保存済の生データを spanner-cli と似たテキストベースの形式で描画するためのツールとして、 rendertree を用意しています。
また、上の spannerplanviz の例ではクエリ結果の生データを取得するために gcloud spanner databases execute-sql を使いましたが、実行計画の生データを取得することに特化したクライアントとして apstndb/execspansql も開発しています。
execspansql の特徴的な機能として、クエリパラメータのサポートがあります。
既存のクライアントツールはクエリパラメータのあるクエリの実行統計を取得することができないため、クエリの書き換えを必要とします。実行計画はクエリのテキストに対して決定されるため、クエリを書き換えた場合は最適化が働くなどの要因で実行計画が変わってしまう場合があることが SQL best practices にも書かれています。
execspansql では Working with STRUCT objects ドキュメントに書かれた高度な例である STRUCT の ARRAY をクエリパラメータとして受け取るようなクエリであっても実行計画及び実行統計を取得でき、 rendertree と組み合わせることで描画することができます。
$ execspansql ${DATABASE_ID} --query-mode=PROFILE --filter=.stats.queryPlan
--sql='SELECT SingerId, @songinfo.SongName
FROM Singers
WHERE STRUCT<FirstName STRING, LastName STRING>(FirstName, LastName) IN UNNEST(@songinfo.ArtistNames)'
--param='songinfo:STRUCT<SongName STRING, ArtistNames ARRAY<STRUCT<FirstName STRING, LastName STRING>>>("Imagination", [("Elena", "Campbell"), ("Hannah", "Harris")])' | rendertree --mode=PROFILE
+-----+----------------------------------------------------------------------------+------+-------+------------+
| ID | Operator | Rows | Exec. | Latency |
+-----+----------------------------------------------------------------------------+------+-------+------------+
| 0 | Distributed Union | 0 | 1 | 9.27 msecs |
| 1 | +- Local Distributed Union | 0 | 1 | 9.25 msecs |
| 2 | +- Serialize Result | 0 | 1 | 9.24 msecs |
| 3 | +- Semi Apply | 0 | 1 | 9.24 msecs |
| 4 | +- Compute | 1000 | 1 | 0.77 msecs |
| 5 | | +- Index Scan (Full scan: true, Index: SingersByFirstLastName) | 1000 | 1 | 0.73 msecs |
| *12 | +- [Map] Filter | 0 | 1000 | 8.15 msecs |
| 13 | +- Array Unnest | 2000 | 1000 | 6.99 msecs |
| 18 | +- [Scalar] Array Subquery | | | |
| 19 | +- Array Unnest | 2000 | 1000 | 1.18 msecs |
+-----+----------------------------------------------------------------------------+------+-------+------------+
Predicates(identified by ID):
12: Condition: (($FirstName = $v7.FirstName) AND ($LastName = $v7.LastName))また、 rendertree では出力のカスタマイズもサポートしています。
例えばこのクエリの実行計画を Web UI で見てみましょう。
SELECT SongName
FROM Songs@{FORCE_INDEX=SongsBySongName}
WHERE SongName LIKE "A%z"
UNION ALL
SELECT SongName
FROM Songs@{FORCE_INDEX=SongsBySongName}
WHERE SongName LIKE "Thi%"
Rows scanned は各 UNION ALL の枝が返す行の合計よりも多くの行をスキャンしていることを示していますが、どこでどれだけの行をスキャンしているのかは自明ではありません。実際のクエリでも JOIN などのために複数のインデックスやテーブルをスキャンする必要がある場合にスキャンの内訳を知りたくなるケースがあります。
スキャンされた行数は Web UI 等では表示されないだけで、各 Scan オペレータごとの実行統計情報として取得することができます。下記の例では生データに含まれる Scanned を表示することで、どの Scan オペレータが実際に余分にスキャンしてフィルタで読み捨てているのかを確認しています。
+-----+-------------------------------------------------------+------+---------+
| ID | Operator | Rows | Scanned |
+-----+-------------------------------------------------------+------+---------+
| 0 | Serialize Result | 2960 | |
| 1 | +- Union All | 2960 | |
| 2 | +- Union Input | | |
| *3 | | +- Distributed Union | 84 | |
| 4 | | +- Local Distributed Union | 84 | |
| *5 | | +- FilterScan | 84 | |
| 6 | | +- Index Scan (Index: SongsBySongName) | 84 | 16942 |
| 24 | +- Union Input | | |
| *25 | +- Distributed Union | 2876 | |
| 26 | +- Local Distributed Union | 2876 | |
| *27 | +- FilterScan | 2876 | |
| 28 | +- Index Scan (Index: SongsBySongName) | 2876 | 2876 |
+-----+-------------------------------------------------------+------+---------+
Predicates(identified by ID):
3: Split Range: (STARTS_WITH($SongName, 'A') AND ($SongName LIKE 'A%z'))
5: Seek Condition: STARTS_WITH($SongName, 'A')
Residual Condition: ($SongName LIKE 'A%z')
25: Split Range: STARTS_WITH($SongName_1, 'Thi')
27: Seek Condition: STARTS_WITH($SongName_1, 'Thi')この出力であれば、 ID 6 の Index Scan の方が ID 28 の Index Scan よりも大量の行をスキャンしており、 ID 5 の Predicates を読むことで、 SongName LIKE “A%z” は Seek Condition: STARTS_WITH($SongName, 'A') でスキャンした後に Residual Condition: ($SongName LIKE 'A%z') で読み捨てる形で処理されるため、最終的に得られる結果よりも多くの行をスキャンすると理解することができます。
このように、 Cloud Spanner から得られる情報は標準では表示されないものでも有用であり、特定のクエリのパフォーマンスチューニングだけでなく Cloud Spanner のクエリ実行そのものを理解する助けとなります。実行計画の解析や表示方法の検討にはまだまだ多くの可能性があると言えるでしょう。
実行計画についての非公式情報の公開
Cloud Spanner の実行計画の解析及び活用についてあまり情報がないことを解決するため、実行計画を中心とした Cloud Spanner の tips を Cloud Spanner Unofficial Hacks として公開しています。例をあげると Seek Condition と Residual Condition の見分け方 のページではクエリフィルタが実行計画上どのように扱われるかと、クエリ改善に役立てる方法を説明しています。また、Operators のページでは実行計画オペレータの入力やメタデータ、実行統計情報のようなドキュメントに書かれていないが実行計画を解析する上で必要になる情報について網羅することを目指しています。
最後に
Cloud Spanner は新しいデータベースであるだけでなく、 LSM ツリーベースのストレージでキー範囲ベースでシャーディングされるなど、従来の SQL データベースでは主流な B+Tree ベースのストレージとはまた違う特性を持っています。そのため、SQL クエリチューニングや実行計画の活用のノウハウについてもまだ他の SQL データベースのように詳細に議論されているわけではないというのが現状です。他の SQL データベースもそうであるように、 Cloud Spanner がそのデータベース設計では効率的に実行することが不可能な SQL クエリでも実行しようとしてしまい、大きな負荷が発生しパフォーマンス問題を起こす危険はありますし、どんな SQL でも気にせず実行できるようになることはないでしょう。
それでも、分散性能を妨げずに SQL クエリのメリットを享受できる場所では積極的に SQL を使い、場合によってはデータに近い場所で処理することで RPC の数やノード間やクライアントとの通信量を減らすことができるスイートスポットについてより考えられるようになることに期待しています。
明日の Merpay Advent Calendar 2020 執筆担当は、 Software Engineer の Mai Nakagawa さんです。引き続きお楽しみください。




